In a recent appearance on Conversations with Tyler, famed political forecaster Nate Silver expressed skepticism about AIs replacing human forecasters in the near future. When asked how long it might take for AIs to reach superhuman forecasting abilities, Silver replied: “15 or 20 [years].”
In light of this, we are excited to announce “FiveThirtyNine,” an AI forecasting bot. Our bot, built on GPT-4o, provides probabilities for any user-entered query, including “Will Trump win the 2024 presidential election?” and “Will China invade Taiwan by 2030?” Our bot performs better than experienced human forecasters and performs roughly the same as (and sometimes even better than) crowds of experienced forecasters; since crowds are for the most part superhuman, FiveThirtyNine is in a similar sense. (We discuss limitations later in this post.)
Our bot and other forecasting bots can be used in a wide variety of contexts. For example, these AIs could help policymakers minimize bias in their decision-making or help improve global epistemics and institutional decision-making by providing trustworthy, calibrated forecasts.
We hope that forecasting bots like ours will be quickly integrated into frontier AI models. For now, we will keep our bot available at forecast.safe.ai, where users are free to experiment and test its capabilities.
Quick Links
- Demo: forecast.safe.ai
- Technical Report: link
Problem
Policymakers at the highest echelons of government and corporate power have difficulty making high-quality decisions on complicated topics. As the world grows increasingly complex, even coming to a consensus agreement on basic facts is becoming more challenging, as it can be hard to absorb all the relevant information or know which sources to trust. Separately, online discourse could be greatly improved. Discussions on uncertain, contentious issues all too often devolve into battles between interest groups, each intent on name-calling and spouting the most extreme versions of their views through highly biased op-eds and tweets.
FiveThirtyNine
Before transitioning to how forecasting bots like FiveThirtyNine can help improve epistemics, it might be helpful to give a summary of what FiveThirtyNine is and how it works.
FiveThirtyNine can be given a query—for example, “Will Trump win the 2024 US presidential election?” FiveThirtyNine is prompted to behave like an “AI that is superhuman at forecasting”. It is then asked to make a series of search engine queries for news and opinion articles that might contribute to its prediction. (The following example from FiveThirtyNine uses GPT-4o as the base LLM.)
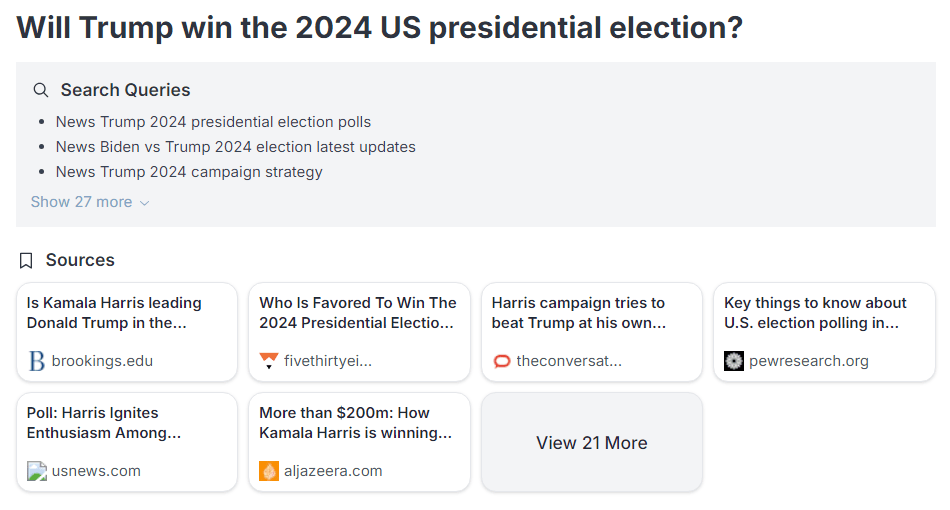
Based on these sources and its wealth of prior knowledge, FiveThirtyNine compiles a summary of key facts. Given these facts, it’s asked to give reasons for and against Trump winning the election, before weighing each reason based on its strength and salience.
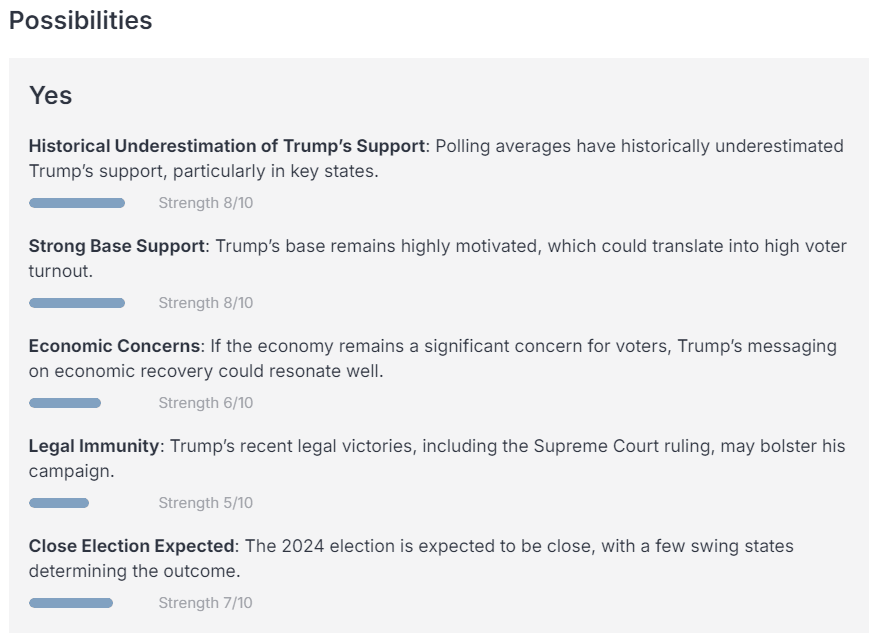
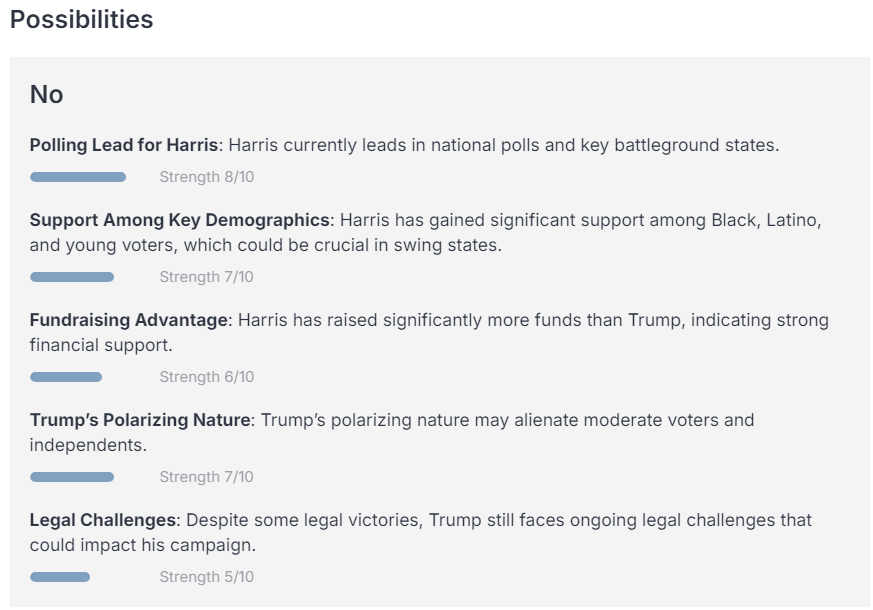
Finally, FiveThirtyNine aggregates its considerations while adjusting for negativity and sensationalism bias in news sources and outputs a tentative probability. It is asked to sanity check this probability and adjust it up or down based on further reasoning, before putting out a final, calibrated probability—in this case, 52%.


Evaluation. To test how well our bot performs, we evaluated it on questions from the Metaculus forecasting platform. We restricted the bot to make predictions only using the information human forecasters had, ensuring a valid comparison. Specifically, GPT-4o is only trained on data up to October 2023, and we restricted the news and opinion articles it could access to only those published before a certain date. From there, we asked it to compute the probabilities of 177 events from Metaculus that had happened (or not happened) since.
We compared the probabilities our bot arrived at to those arrived at independently by crowds of forecasters on the prediction platform Metaculus. For example, we asked the bot to estimate the probability that Israel would carry out an attack on Iran before May 1, 2024, restricting it to use the same information available to human forecasters at the time. This event did not occur, allowing us to grade the AI and human forecasts. Across the full dataset of events, we found that FiveThirtyNine performed just as well as crowd forecasts.
Strengths over prediction markets. On the 177 events, the Metaculus crowd got 87.0% accuracy, while FiveThirtyNine got 87.7% ± 1.4. A link to the technical report is here. This bot lacks many of the drawbacks of prediction markets. It makes forecasts within seconds. Additionally, groups of humans do not need to be incentivized with cash prizes to make and continually update their predictions. Forecasting AIs are several orders of magnitude faster and cheaper than prediction markets, and they’re similarly accurate.
Limitations. The bot is not fine-tuned, and doing so could potentially make it far more accurate. It simply retrieves articles and writes a report as guided through an engineered prompt. (Its prompt can be found by clicking on the gear icon in forecast.safe.ai.) Moreover, probabilities from AIs are also known to lead to automation bias, and improvements in the interface could ameliorate this. The bot is also not designed to be used in personal contexts, and it has not been tested on its ability to predict financial markets. Forecasting can also lead to the neglect of tail risks and lead to self-fulfilling prophecies. That said, we believe this could be an important first step towards establishing a cleaner, more accurate information landscape. The bot is decidedly subhuman in delimited ways, even if it is usually beyond the median human in breadth, speed, and accuracy. If it’s given an invalid query it will still forecast---a reject option is not yet implemented. If something is not in the pretraining distribution and if no articles are written about it, it doesn’t know about it. That is, if it’s a forecast about something that’s only on the X platform, it won’t know about it, even if a human could. For forecasts for very soon-to-resolve or recent events, it does poorly. That’s because it finished pretraining a while ago so by default thinks Joe Biden is in the race and need to see articles to appreciate the change in facts. Its probabilities are not always completely consistent either (like prediction markets). In claiming the bot is superhuman (around crowd level in accuracy), we’re not claiming it’s superhuman in every possible respect, much like how academics can claim image classifiers are superhuman at ImageNet, despite being vulnerable to adversarial ImageNet images. We do not think AI forecasting is overall subhuman.
Vision
Epistemic technologies such as Wikipedia and Community Notes have had significant positive impacts on our ability to understand the world, hold informed discussions, and maintain consensus reality. Superhuman forecasting AIs could have similar effects, enabling improved decision-making and public discourse in an increasingly complex world. By acting as a neutral intelligent third party, forecasting AIs could act as a tempering force on those pushing extreme, polarized positions.
Chatbots. Through integration into chatbots and personal AI assistants, strong automated forecasting could help with informing consequential decisions and anticipating severe risks. For example, a forecasting AI could provide trustworthy, impartial probability assessments to policymakers. The AI could also help quantify risks that are foreseeable to experts but not yet to the general public, such the possibility that China might steal OpenAI’s model weights.
Posts. Forecasting AIs could be integrated on social media and complement posts to help users weigh the information they are receiving.
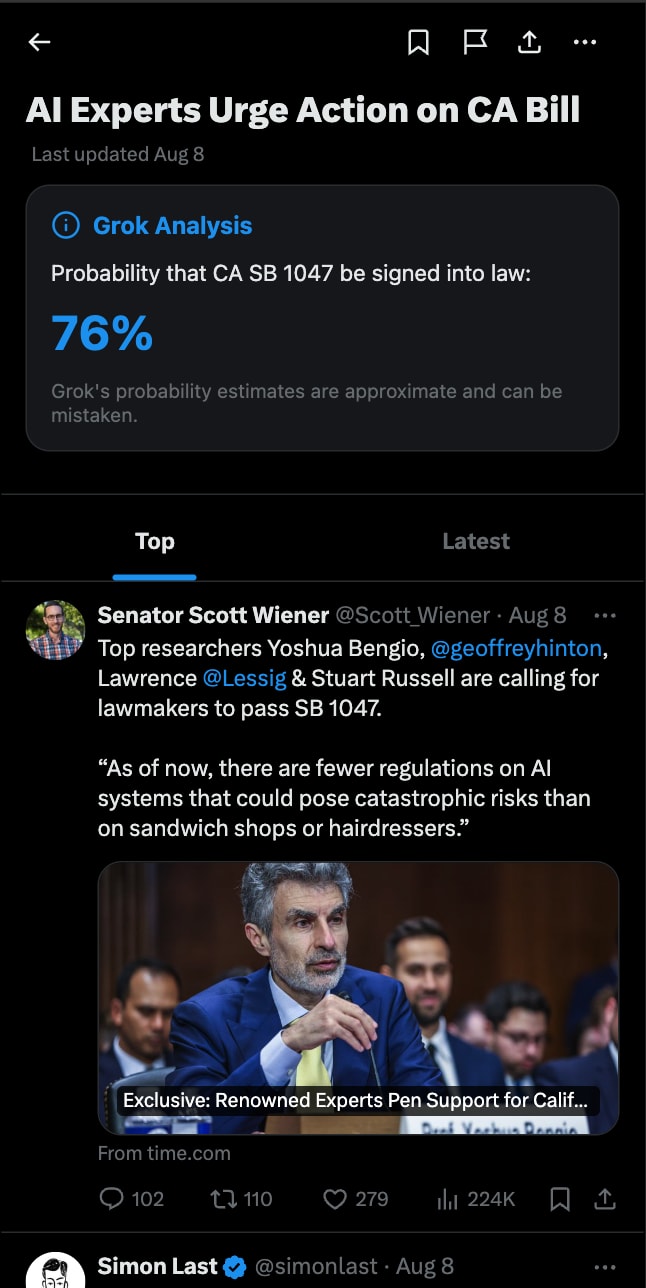
News stories. Forecasting could also complement news stories and topics. For example, for news associated with California AI Safety bill SB 1047, a forecasting bot could let users know the probability that it gets signed into law.
Conclusion
Carl Sagan noted, “If we continue to accumulate only power and not wisdom, we will surely destroy ourselves.” AIs will continue to become more powerful, but their forecasting capabilities will hopefully help make us more prudent and increase our foresight.
The science underpinning this study is unfortunately incredibly limited. For instance, there isn’t even basic significance testing provided. Furthermore, the use of historic events to check forecasting accuracy, and the limited reporting of proper measures to prevent the model utilising knowledge not available to the human forecasters (with only a brief mention of the researchers providing the search link with pre-approved) is also very poor.
I’m all for AI tools improving decision making and have undertaken several side-projects myself on this. But studies like this should be highlighted for their lack of scientific standards and thus, we should be sceptical of how much we use them to update our judgments of how good AI should be at forecasting currently (which to me is quite low given they struggle to causally reason)
+1. While I applaud the authors for doing this work at all, and share their hopes regarding automated forecasting, by my lights the opening paragraphs massively overstate their bot’s ability.
+1 to comments about the paucity of details or checks. There are a range of issues that I can see.
Am I understanding the technical report correctly? It says "For each question, we sample 5 forecasts. All metrics are averaged across these forecasts." It is difficult to interpret this precisely. But the most likely meaning I take from this, is that you calculated accuracy metrics for 5 human forecasts per question, then averaged those accuracy metrics. That is not measuring the accuracy of "the wisdom of the crowd". That is (a very high variance) estimate of "the wisdom of an average forecaster on Metaculus". If that interpretation is correct, all you've achieved is a bot that does better than an average Metaculus forecaster.
I think that it is likely that searches for historical articles will be biased by Google's current search rankings. For example, if Israel actually did end up invading Lebanon, then you might expect historical articles speculating about a possible invasion to be linked to more by present articles, and therefore show up in search queries higher even when restricting only to articles written before the cutoff date. This would bias the model's data collection, and partially explain good performance on prediction for historical events.
Assuming that you have not made the mistake I described in 1. above, it'd be useful to look into the result data a bit more to check how performance varies on different topics. How does performance tend to be better than wisdom of the crowd? For example, are there particular topics that it performs better on? Does it tend to be more willing to be conservative/confident than a crowd of human forecasters? How does its calibration curve compare to that of humans? Also questions I would expect to be answered in a technical report claiming to prove superhuman forecasting ability.
It might be worth validating that the knowledge cutoff for the LLM is actually the one you expect from the documentation. I do not trust public docs to keep up-to-date, and that seems like a super easy error mode for evaluation here.
I think that the proof will be in future forecasting prediction ability: give 539 a Metaculus account and see how it performs.
Honestly, at a higher level, your approach is very unscientific. You have a demo and UI mockups illustrating how your tool could be used, and grandiose messaging across different forums. Yet your technical report has no details whatsoever. Even the section on Platt scoring has no motivation on why I should care about those metrics. This is a hype-driven approach to research that I am (not) surprised to see come out of 'the centre for AI safety'.
Fwiw Metaculus has an AI Forecasting Benchmark Tournament. The Q3 contest ends soon, but another should come out afterwards and it would be helpful to see how 539 performs compared to the other bots.
"From there, we asked it to compute the probabilities of 177 events from Metaculus that had happened (or not happened) since.
Concretely, we asked the bot whether Israel would carry out an attack on Iran before May 1, 2024. We compared the probabilities it arrived at to those arrived at independently by crowds of forecasters on the prediction platform Metaculus. We found that FiveThirtyNine performed just as well as crowd forecasts."
Just to check my understanding of the excerpt above, were all the 177 events used in evaluation related to Israel attacking Iran?
When I plug in the training prompt from the technical report (last page of the paper) into the free version of chatgpt, it gives a response that seems very similar to what five-thirty nine says. This is despite my chatgpt prompt not including any of the sources retrieved.
Have I interpreted this wrong, or is it possible that the retrieval of sources is basically doing nothing here?
EDIT: I did another experiment that seems even more damning: I asked an even simpler prompt to chatgpt: "what is the probability that china lands on the moon before 2050? Please give a detailed analysis and present your final estimate as a single number between 0% and 100%"
The result is a very detailed analysis and a final answer of 85%.
Asking the same question to five-thirty nine "what is the probability that china lands on the moon before 2050?", I get a response of pretty much the same detail, and the exact same final answer of 85%.
I've tried this with a few other prompts and it usually gives similar results. I see no proof that the sources do anything.