
titotal
Bio
I'm a computational physicist, I generally donate to global health. I am skeptical of AI x-risk and of big R Rationalism, and I intend on explaining why in great detail.
Posts 34
Comments778
Point 1 was a typo, thanks for pointing it out!
Point 2 is something that confused me at first as well. The reason they are different is that we are looking at the performance of the top apparent threat. If we were perfectly good estimators, this would be the same as the top actual threat, but we aren't: the threat of the top pick is generally going to be lower than the top actual threat due to uncertainty and the curse.
For the grounded estimator, the process of ranking threats gives useful information, and it means that the top threat picked is much higher than you would get from picking at random. Whereas in the speculative case, we are much closer to just picking at random, and thats reflected in the yellow curve which looks a lot like the power law sampling we are drawing from.
Here is an example run I did where I tuned down the alpha to 1.5 and tuned the lognormal standard deviation down to 1.5:
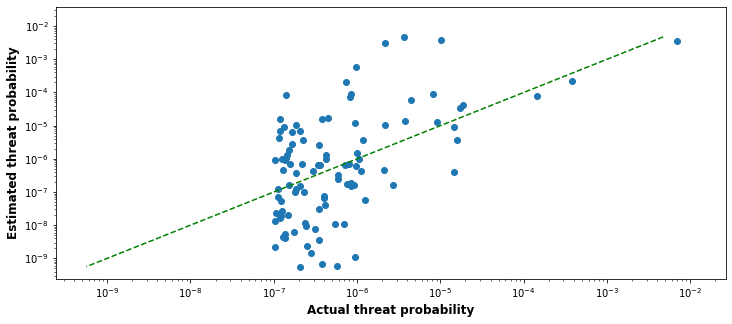
Here, the top actual threat really is 7 orders of magnitude more dangerous than the bottom evaluated threat. However, the top apparent threat is overestimated by a factor of 10,000 or so.
If I do a bunch of runs with these settings, the median overestimate is over 100x:
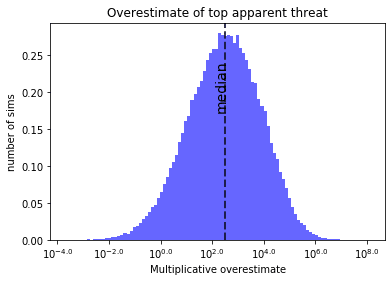
So even if I trust your vibes here (which do not seem to be based on anything), the curse can still hit quite badly. I personally believe that the spread of numbers that people make up is going to be higher than the spread of actual threats: when we look at actual surveys you get a highest-lowest estimate spread of 11 orders of magnitude for some questions.
One thing that might be confusing you is that the power law model assumes that only threats above a certain threshold of actual danger are considered (this is the xmin factor). Obviously nuclear risk is a much greater risk than stubbing your toe, but it's not going to show up the model.
Academia: defers significantly more
This has not been my experience from 9 years of academia in physics and material science. Opinions published in scientific papers must be backed up with reference to actual evidence, not merely opinion. When deferral happens behind the scenes, it's usually justified by the person in question being an actual expert that knows their shit.
EA is far worse: I sometimes see people defer to random blog posters who have zero expertise in the subject they are talking about.
Interesting analysis! I'm somewhat skeptical that space based cells will perform as well as you find in this model. This seems like a classic case where something that looks good on paper will run into problems in real world applications for something as complicated as putting massive datacenters in space. I don't think your model is accounting for murphy's law here.
Also, on a technical note, do you have the source for the starlink solar cell specifications used for the phrase "Back-calculated from Starlink V3 specifications (50,400 W from 554 kg array, 257 m² area)"? This seems like one of the critical figures of your model but I couldn't find where you linked the source for it.
It is extremely difficult to determine base rates for something like sexual harassment, because it's an offence that allows for ambiguity and plausible deniability, because there's room for retaliation, etc, and it will strongly depend on how much people trust the bodies they are reporting to.
What we can do is look at the responses to the incidents that do get raised, and the experiences of victims, and judge whether or not they live up to the standards we want to see in a group that takes sexual harrasment seriously. I do not think the grades are very good on this front.
Only 3 months ago we had a writeup detailing a shockingly terrible response to sexual harrassment by one of the most prominent EA orgs out there. The response is far worse than anything I've ever seen at any organisation I've ever been in. This indicates to me that the environment is nowhere the high standards that should be aimed for.
Regardless of the actual base rates, the question that matters the most is whether there is room for improvement, and I think it's blindingly obvious that the answer is yes.
LLM disclosure in general is just a good idea to do. The internet is absolutely flooded with LLM-written spam at the moment, so if people detect LLM writing with no context it's natural to assume your post is spam as well. This is a shame when someone who is a non-native speaker has just used it for translation or whatnot.
Personally I'd recommend against using LLM-written text if you can help it, as in the age of spam the value of cultivating your own stylistic voice is increasing.
I think you would benefit from re-reading the article in question. For example, they directly adress your point 1 by pointing out that consumer diffusion figures are often misleading by expressing figures in terms of "percentage of people that use chatbots on occasion", rather than on frequency of use.
Point 3 is not even an argument, just a restatement of what they believe: yes, they think AI domination will take decades. They state the reasons they believe this very clearly in the section "Diffusion is limited by the speed of human, organizational, and institutional change": if you disagree with this, you have to present actual arguments. From what I know, most economists would agree with them.
Point 5 is not an argument either: they are not to blame for how you interpret their "vibes". If people interpret "AI will be akin to the internet" as anything other than "AI will be akin to the internet" that's their fault, not the authors.
As for point 6, I'm confused as to what your position is here. Do you think that AI systems are merely cheating on every single benchmark? In the section "benchmarks do not mention real-world utility", I took them as referring to benchmarks that are actually meaningful: saying that while they genuinely are good at taking law tests, even non-contaminated ones, that this doesn't translate into being a good lawyer because of the aspects that are not easily measurable. I don't see how this is a contradiction to any of their previous work?
I think "speck of dust in the eye" was a bad choice for the central example of this debate, because in some situations a speck in your eye can be literally zero painful, and in others it can be actually quite painful and distressing. I think this leads to miscommunications and poor intuitions.
My preferred alternative would be something like "lightly scratching your palm with your fingernail". And while this is technically pain, I find a single light scratch to be so minor that it has literally zero effect on my levels of happiness: in fact I will sometimes do this to myself on purpose when I get sufficiently bored.
I therefore think that that premise 1: "mild pain is bad", is wrong for sufficiently small definitions of "mild pain". I think you need a threshold of badness for the argument to work. Furthermore, I think most people who would side with the "dust specks" also have some threshold where they would pick the torture: for example if it was "punching a billion people in the face vs torture one person".
To be clear, I wasn't saying that complexity itself was the cause of consciousness, just that some level of algorithmic complexity may be a requirement for consciousness. This seems like a common position: the prospect of present or future LLM sentience is a subject of debate, but it's rare to see a similar debate about the sentience of a pocket calculator.
A brain and a digital simulation have some similarities, but they also have a lot of differences. One of those differences is that the brains are running on "laws of physics" algorithms that are overwhelmingly faster and more complex than that of digital simulations. They didn't need to evolve these "algorithms": it's inherent to any biological process. Seth identifies several other differences as well: continuous operation, embodiment, etc. His position seems to be that at least one of these differences may result in a lack of consciousness.
I can add four more to the list of possible dangers: