Comments
[This is a crosspost for https://manifund.substack.com/p/announcing-manival]
Status: Something we’ve hacked on for a couple of weeks; looking to get feedback and iterate!
Last time, I wrote about some considerations for AI safety grant evaluation, but didn’t actually ship a cost-effectiveness model. Since then, Austin, Nishad, and I have:
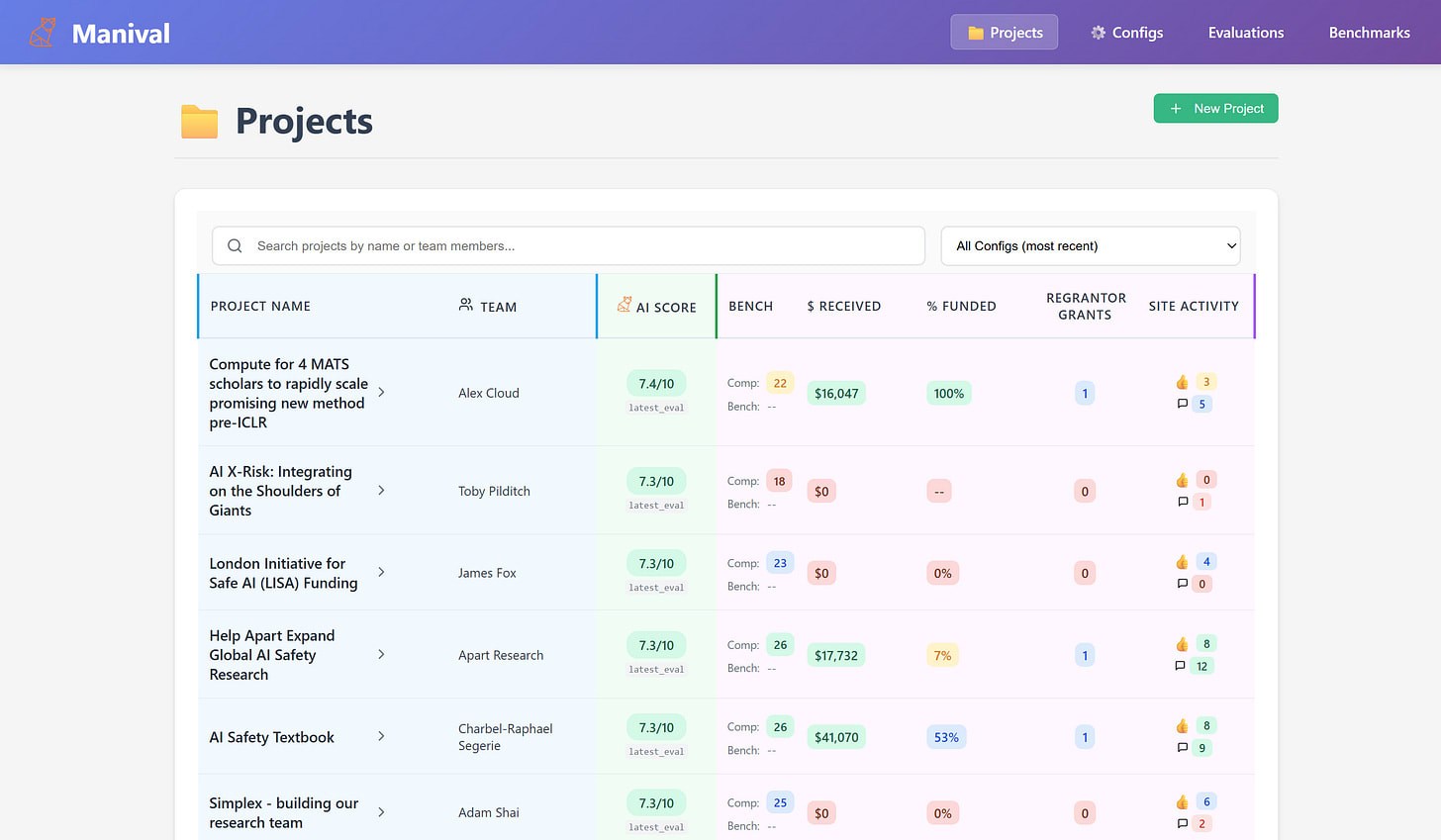
This is effectively a form of structured ‘Deep Research’.
First, we specify the fields that matter to us when evaluating a grant. These might include ‘domain expertise of project leads’ or ‘strength of project’s theory of change’. We have RAG-based ‘data fetchers’ (Perplexity Sonar) scour the internet and return a score, with reasoning, for each of these fields. We then feed these into an LLM synthesizer (Claude Opus), which provides an overall evaluation.
This is a pretty janky LLM wrapper compensating for the lack of Deep Research API. We’re aware of various RAG and Deep Research alternatives, and expect our evaluations to improve as we plug better models in.
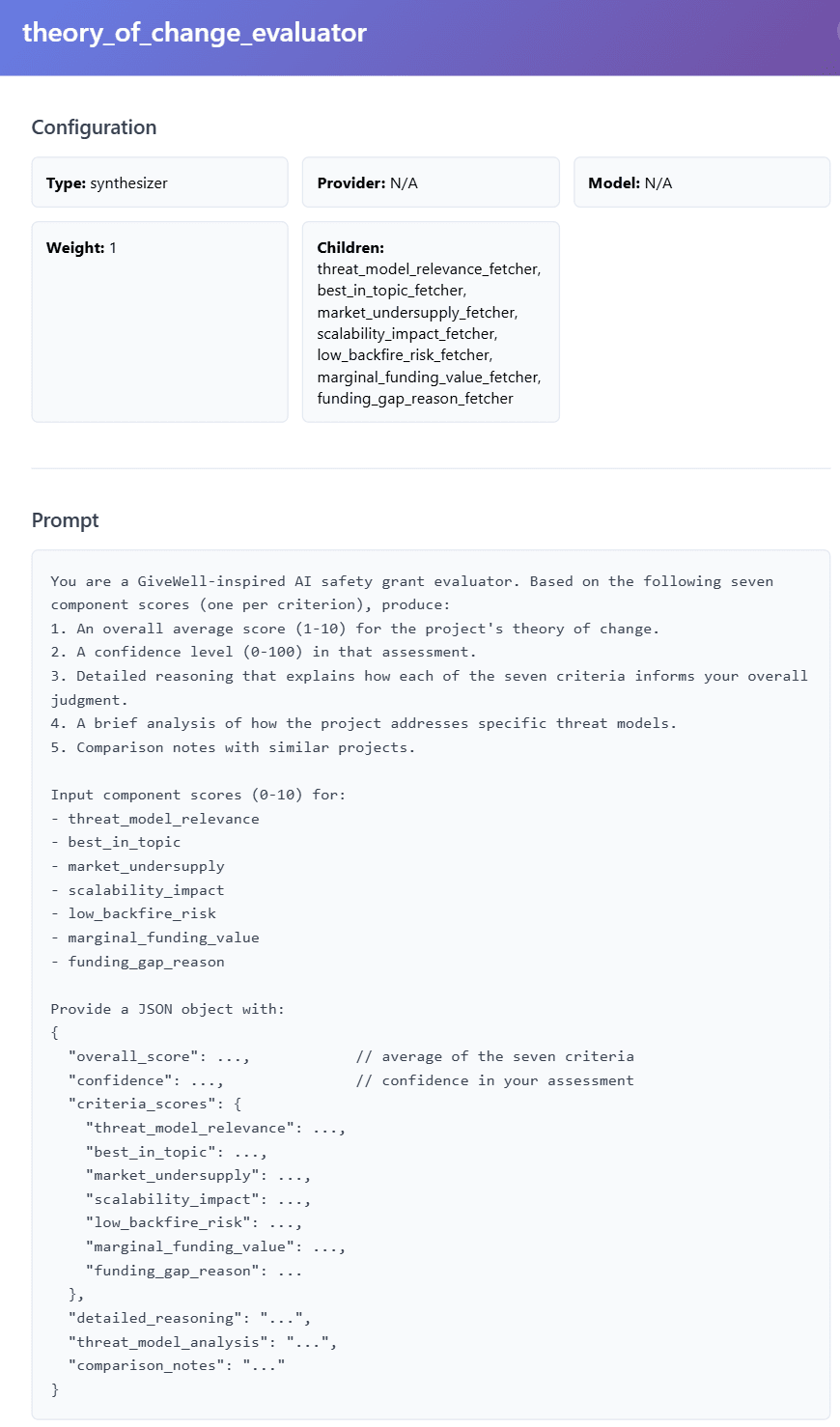
Different people have different ideas of what should go into a grant evaluation config. Austin cares deeply about how great a team is; I’d like mine to consider counterfactual uses of a team’s time.
With Manival, you can apply any grant evaluation criteria of your choosing (go to Configs → AI Generate). Here’s one we made just for fun:
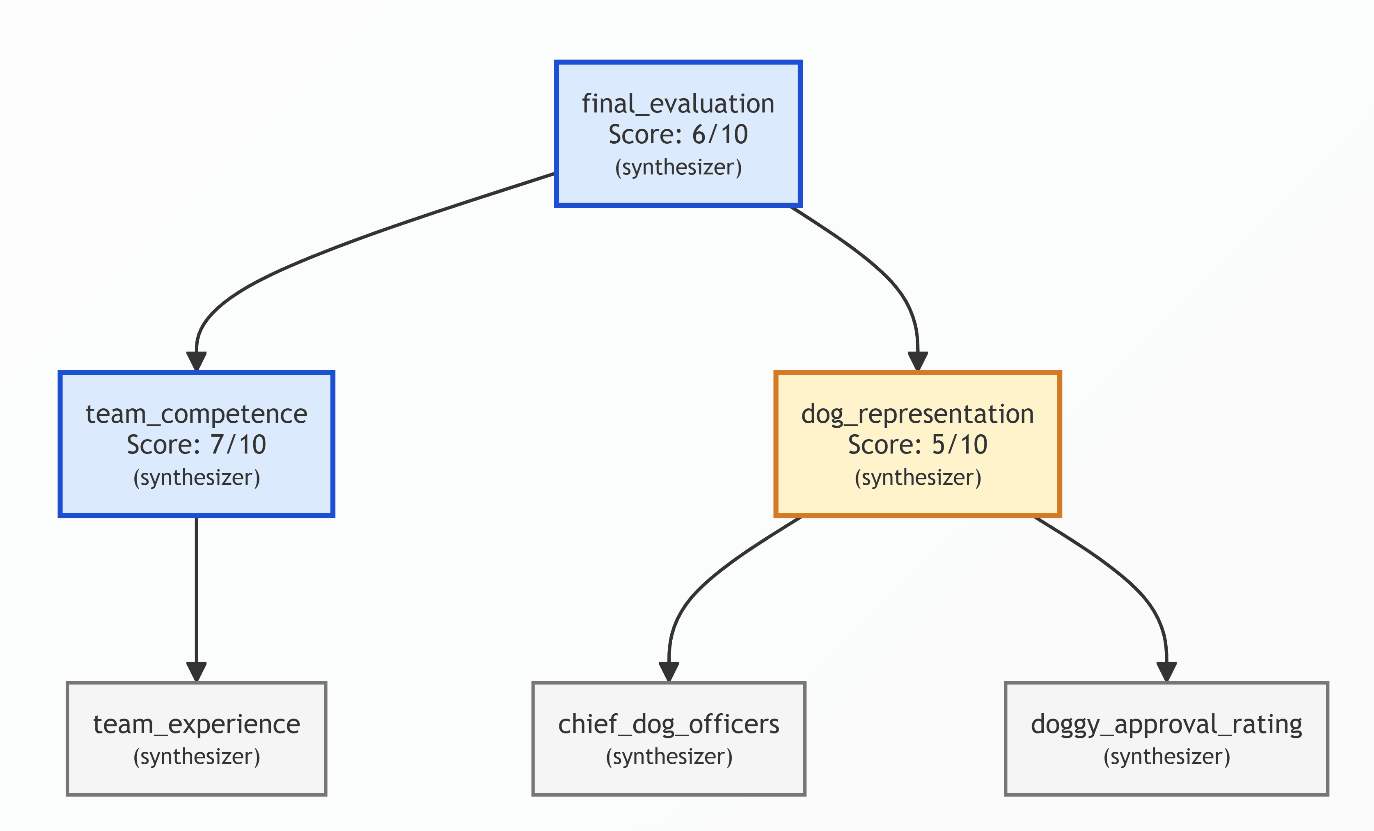

Manival has lots of potential uses. Here are some main ones:
It might be valuable to simulate how other grantmakers you respect might evaluate a project when deciding whether to make a grant. For example, here’s a simulation of Joe Carlsmith’s thinking:

These ‘simulated scores’ might differ from how a grantmaker actually thinks. Accordingly, we plan to develop configs that are maximally faithful to our own thinking over the next week.
For now, I expect a lot of Manival’s value to come from ‘flagging potentially great projects to look into’, rather than being something people defer to.
We’re excited for you to try Manival, and eager to know what you think, especially if you’re a donor, grantmaker, or someone else who cares a lot about evaluating grant proposals. Schedule a call with us to chat this through, or let us know in the comments!


Can you say more about how this / your future plans solve the adverse selection problems? (I imagine you're already familiar with this post, but in case other readers aren't, I recommend it!)
Hey Trevor! One of the neat things about Manival is the idea that you can create custom criteria to try and find supporting information that you as a grantmaker want to weigh heavily, such as for adverse selection. So for example, one could create their own scoring system that includes a data fetcher node or a synthesizer node, which looks for signals like "OpenPhil funded this two years ago, but has declined to fund this now".
Re: adverse selection in particular, I still believe what I wrote a couple years ago: adverse selection seems like a relevant consideration for longtermist/xrisk grantmaking, but not one of the most important problems to tackle (which, off the top of my head, I might identify as "not enough great projects", "not enough activated money", "long and unclear feedback loops"). Or: my intuition is that the amount of money wasted, or impact lost, due to adverse selection problems is pretty negligible, compared to upside potential in growing the field. I'm not super confident in this though and curious if you have different takes!
Yeah interesting. To be clear, I'm not saying e.g. Manifund/Manival are net negative because of adverse selection. I do think additional grant evaluation capacity seems useful, and the AI tooling here seems at least more useful than feeding grants into ChatGPT. I suppose I agree that adverse selection is a smaller problem in general than those issues, though once you consider tractability, it seems deserving of some attention.
Cases where I'd be more worried about adverse selection, and would therefore more strongly encourage potential donors:
In those cases, especially for six-figure-and-up donations, people should feel free to supplement their own evaluation (via Manival or otherwise!) by checking in with professional grantmakers; Open Phil now has a donor advisory function that you can contact at [email protected].
(For some random feedback: I picked an applicant I was familiar with, was surprised by its low score, ran it through the "Austin config," and it turns out it was losing a bunch of points for not having any information about the team's background; only problem is, it had plenty of information about the team's background! Not sure what's goin on there. Also, weakly held, but I think when you run a config it should probably open a new tab rather than taking you away from the main page?)