Summary: From the assumption of the existence of AIs that can pass the Strong Form of the Turing Test, we can provide a recipe for provably aligned/friendly superintelligence based on large organizations of human-equivalent AIs
Turing Test (Strong Form): for any human H there exists a thinking machine m(H) such that it is impossible for any detector D made up of a combination of machines and humans with total compute ≤ 10^35 FLOP (very large, but not astronomical) to statistically discriminate H from m(H) purely based on the information outputs they make. Statistical discrimination of H from m(H) means that an ensemble of different copies of H over the course of say a year of life and different run-of-the-mill initial conditions (sleepy, slightly tipsy, surprised, energetic, distracted etc) cannot be discriminated from a similar ensemble of copies of m(H).
Obviously the ordinary Turing Test has been smashed by LLMs and their derivatives to the point that hundreds of thousands of people have AI girl/boyfriends as of writing and Facebook is launching millions of fully automated social media profiles, but we should pause to provide some theoretical support for this strong form of the Turing Test. Maybe there's some special essence of humanity that humans have and LLMs and other AIs don't but it's just hard to detect? Well, if you believe in computationalism and evolution then this is very unlikely: the heart is a pump, the brain is a computer. We should expect the human brain to compute some function and that function has a mathematical form that can be copied to a different substrate. Once that same function has been instantiated elsewhere, no test can distinguish the two. Obviously the brain is noisy, but in order for it to operate as an information processor it must mostly be able to correct that bio-noise. If it didn't, you wouldn't be able to think long-term coherent thoughts.
Defining Friendly AI
I now have to define what I mean by an 'aligned' or 'friendly' superintelligence.
(Friendly-AI-i) We define AI as 'friendly' or 'aligned' if it gives us the exact same outcome (probabilistically: distribution of outcomes) as we would have gotten by continuing the current human governance system.
The stronger form:
(Friendly-AI-ii) We define AI as 'friendly(U)' or 'aligned(U)' relative to a utility function U if it gives us the exact same score (probabilistically: distribution of scores) according to U as the best possible human government/team could attain, subject to the constraint of the humans numbering less than or equal to 10 billion and having access to roughly the same material resources that Earth currently has.
I claim that I can construct a friendly AI according to definition (i) and also according to definition (ii) using only the Strong Turing Test assumption.
Proof for Friendly-AI-i
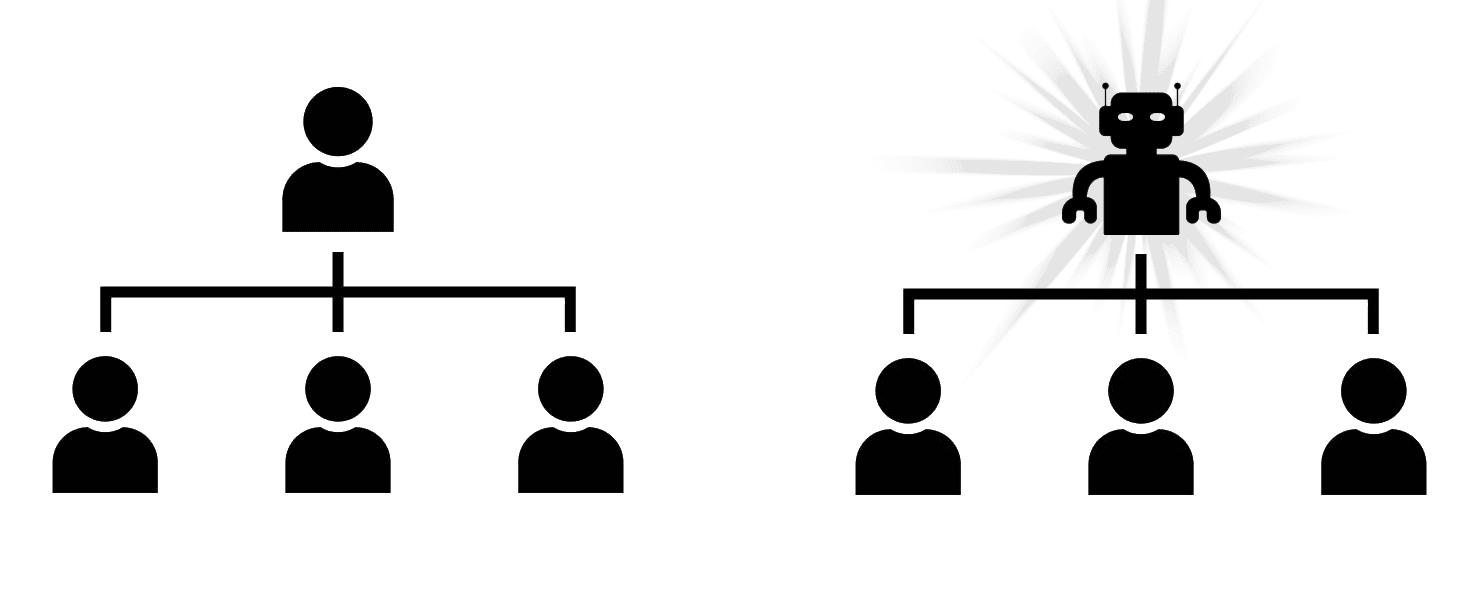
To show that we can build a friendly AI according to definition (i) we will proceed by making the most accurate possible AI copies of every human on the planet and imagine replacing the humans in the org chart of Earth one at a time, starting from the top (e.g. President of the US):
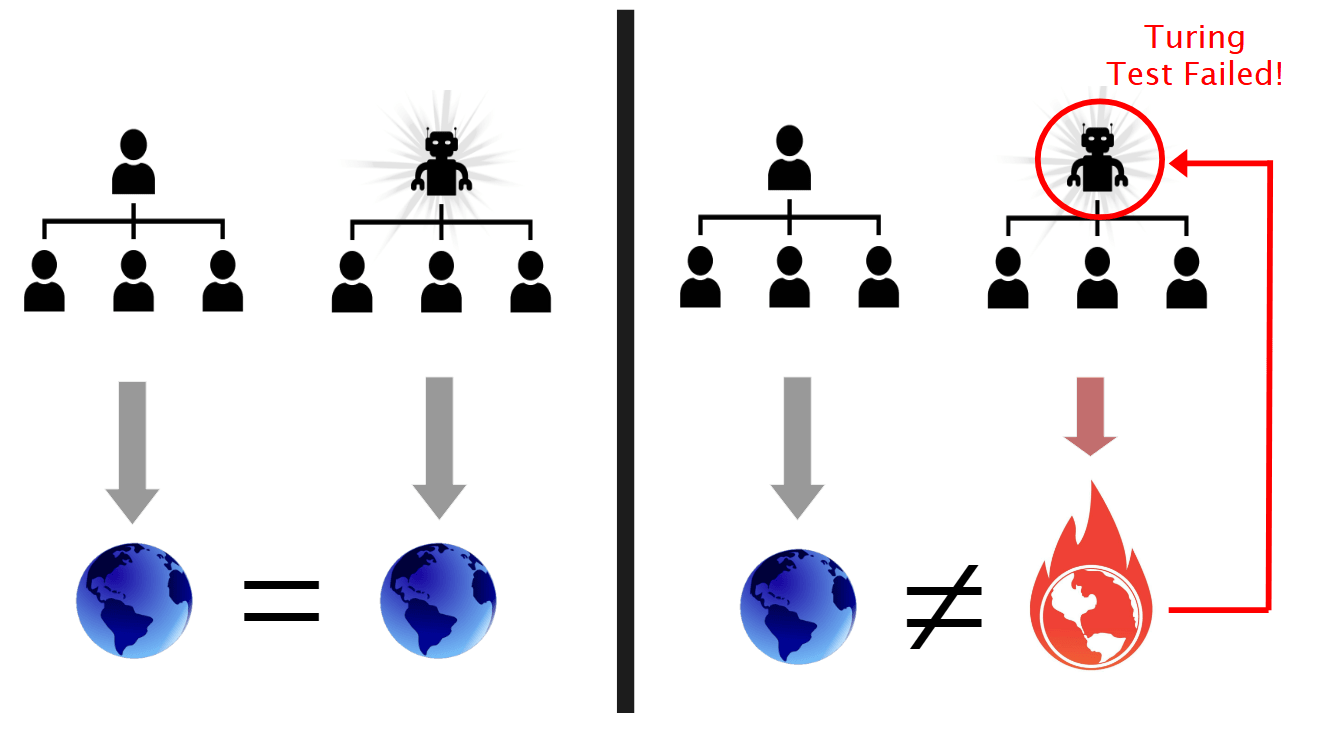
If the new world with one human replaced by AI produced a statistically detectable difference in outcomes for the world, then we can construct a detector D to make AI fail the Strong Turing Test - the statistically detectable difference in outcomes for the world tells you which one is the AI and which one is the human! So your detector D is the system comprised of all the other humans who haven't yet been replaced, and the rest of the world.
We then proceed to replace the rest of the humans in the world one at a time and at each stage apply the same argument. If there is a difference in outcomes at any stage, then the AI has failed the Turing Test. Since we are assuming that AIs can pass the Strong-Form Turing Test, it must be possible to replace every human who has any formal or informal control over the world and get exactly the same outcome (or the same distribution over outcomes) as we would under the status quo ex ante.
Of course we wouldn't actually have to replace people with AIs to make use of this. We would just need to feed the inputs from the world into the AIs, and execute their outputs via e.g. robotic military and police. And we wouldn't necessarily have to run any of these very expensive Strong Turing Tests: the Strong Turing Test assumption merely makes the claim that sufficiently accurate AI copies of humans exist: building them and validating them may follow some different and more practical path.
Proof for Friendly-AI-ii
We can play a similar trick for definition (ii) (Friendly-AI-ii). Given any utility function U we can imagine the best possible human team to run the world from the point of view of U, subject to the size of the human team being less than 10 billion people, then proceed as before replacing the U-maxxing humans with AIs one at a time.
So, you must either believe that Aligned/Friendly AI is possible or you must believe that AIs can't (ever) pass the Turing Test in its strong form. The latter seems rather mystical to me (human brains are merely a compute medium that instantiates a particular input-output relation), so we have a proof of aligned AI under the reasonable assumptions.
Objections
You could object that the 'best possible human team to run the world from the point of view of utility function U' might not be very good! However, if you are campaigning to pause AI or stop AI then you are limiting the future of humanity to human teams (and likely quite suboptimal ones at that!). The set of all possible teams made of less than or equal to 10^10 humans (where these humans don't actually have to currently exist - they can be any possible realizable natural human) is quite large and of course includes all current human achievements as a subset. This has the potential to radically improve the world - it may not be the most powerful possible AI, but it is certainly vastly superhuman.
Requiring that a team of humans can achieve some state guarantees that the state is actually reachable so it at least means that we are not asking Aligned AI to achieve the impossible.
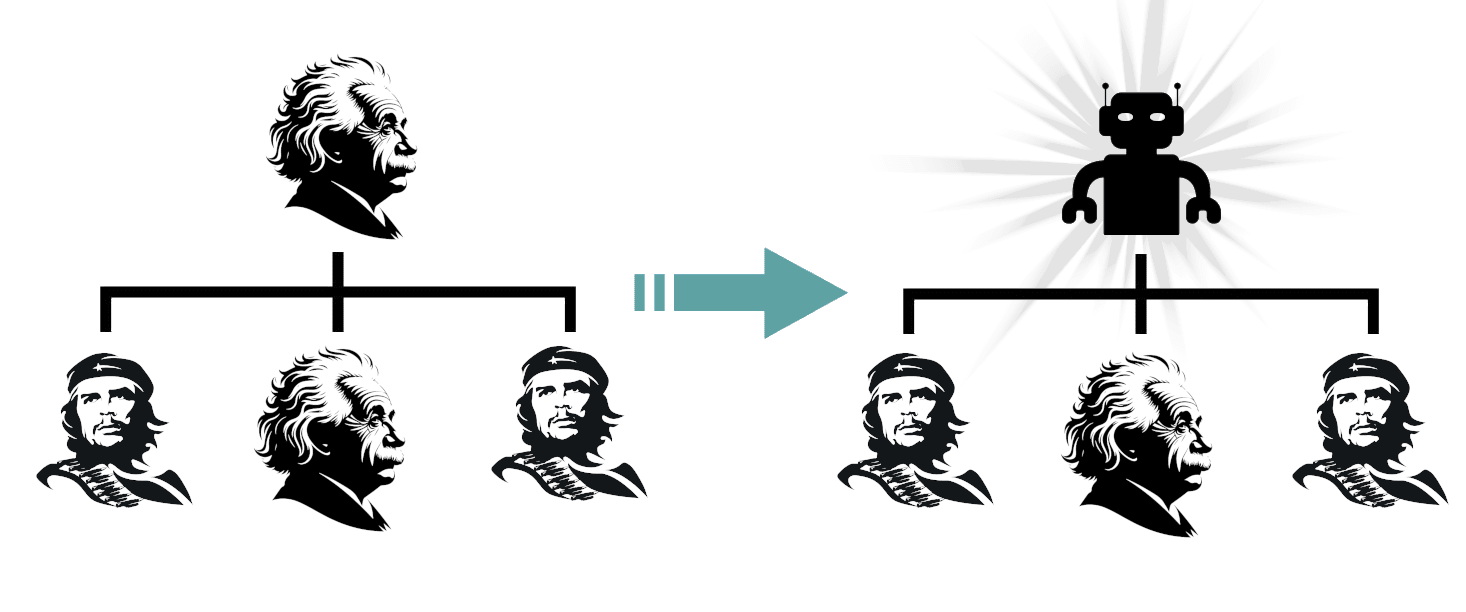
One could also object that I have stretched the Turing Test too far: having a detector that simulates the entire world just in order to see whether an AI can emulate Donald Trump or Einstein is overkill. But the detector can likely be pared down to a local interface around each person/AI and still work roughly as well - that would just make the proof much less clean.
So What?
The way we think about AI alignment went somewhat off the rails over the past decade or two because people mixed mathy, technical problems about how to set the parameters in neural networks with big picture political, ethical and philosophical problems. The result was that we thought about powerful AI as a big black box that might do something bad for inscrutable reasons - a dark and unmapped territory full of horrors.
The approach taken here separates technical from political/ethical problems. The technical problem is to make an AI that is a very accurate functional clone of a human, with various dials for personality, goals and motives. I am extremely confident that that can be done.
The political/ethical/axiological problem is then how to arrange these human-clone-AIs into the best possible system to achieve our goals. This question (how to arrange approximately-human units into controlled and functional superorganisms like nations) has already been heavily explored throughout human history, and we know that control algorithms are extremely effective (see Buck Shlegeris' "Vladimir Putin Alignment").
Of course given that we have close-to-human AIs right now, there is the risk that someone soon builds a strongly superhuman black box AI that takes sensor data in and just outputs commands/tokens. We should probably avoid doing that (and we should make it so that the dominant strategy for all relevant players is to avoid black box superintelligence and avoid illegible intelligence like COCONUT [Chain of Continuous Thought]).
Now an objection to this is that avoiding illegible AI and super powerful black boxes is too high a cost (high alignment penalty) and we have no way to enforce it. But the problem of enforcing adoption of a known-safe type of AI is a serious improvement on just throwing your hands up and saying we're doomed, and I have other ideas about how to do that which are to be addressed in future posts.
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
Adapted from my Substack, Funding Anthropalypse.
Short version: if you want a share of the coming Anthropic and OpenAI windfall - the $37bn+ that could be in play next year - the way in is to become 'legibly excellent', so the evaluators and donors that frontier lab staff already trust point them to yo...