Comments
AI, Cybersecurity, and Malware: A Shallow Report [Technical]

10 min readMar 31, 2023
4


This post summarises recent progress in AI-enabled malware detection for those familiar with applied AI.
Why read a post about AI-enabled malware detection? It's an impactful problem for any cybersecurity application. Also, it has large impacts in protecting biosecurity attribution and screening algorithms; democratic decision-making processes; the weights of sensitive AI algorithms; and more.
P.S. If you're not familiar with applied AI, the general version of this post may be more understandable to you.
Some early malware detection approaches just saved parts of malware files (signatures) to detect later. Ex: an antivirus could save a sequence of bytes or operation codes from a malicious program. These techniques mainly worked to detect known malware multiple times.
But what if a hacker updates an old malware file to change that sequence? Well, the update would still have similar behaviour to older files. Ex: a malware file could record the keys you press on your keyboard. Thus, the behaviour (actions) of malware files can be tracked with less variation than raw bytes.
Note how this new technique must run malware files (to record their actions). Whereas older techniques looking for a 'signature' only read a malware file's content. This difference is known as static analysis (read-only) vs. dynamic analysis (run).
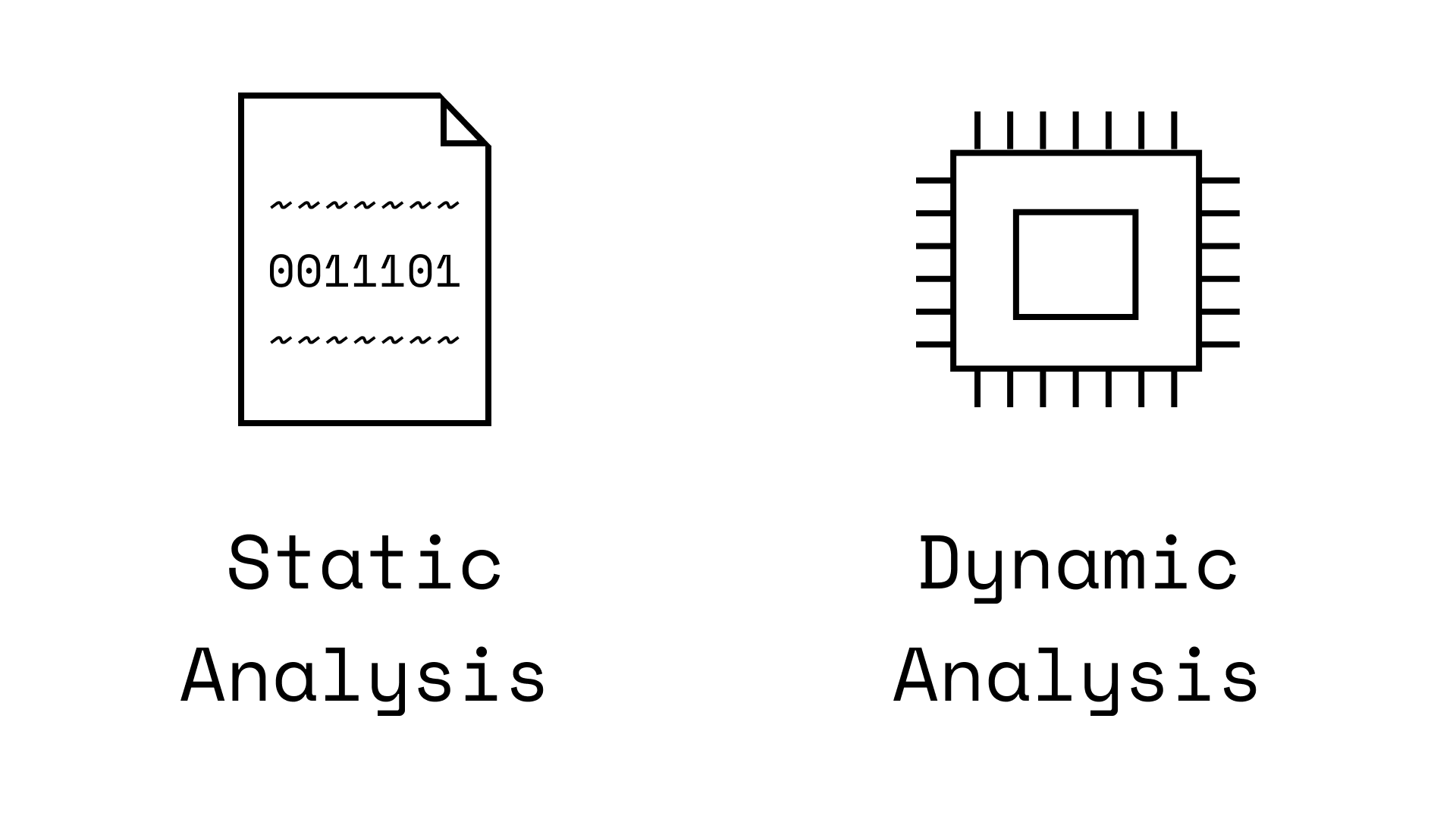
Static analysis techniques need fewer safety precautions since malware isn't run. However, they sift through a lot of information across an entire file (much of which is unrelated to a file's malicious actions). Ex: a hacker may copy a normal mobile app, but launch malicious actions when one specific button is pressed. (Source)
Dynamic analysis techniques require more safety precautions when running malware. Ex: running the malware on a virtual machine sandbox environment. Also, they struggle to analyse all actions of malware. Ex: a hacker could add time delays to malware to only run after two weeks of waiting. So any dynamic analysis that didn't wait two weeks wouldn't detect the malware. (Source)
Due to these different tradeoffs, both techniques are used in practice.
AI algorithms have mainly been used for static (read-only) analysis of malware files. Here are the largest differences in these algorithms: (Source)
Preprocessing: this is how information about malware files is prepared before being sent to an AI algorithm.
Common preprocessing techniques include:
Of these, processing raw binary content is an ideal goal. It requires the least specialised knowledge and is easy to update as hackers change malware. Still, it's hard since you could have million of bytes to process in a malware file.
Data Sources: it's rare for researchers to find high-quality data to train algorithms with. Companies may share their data with a few partners, but not everyone.
Aside box: problems with different data sources (Source)
|
Computational Needs: past researchers have made overly complex AI models. Solutions that can only run on GPUs/TPUs aren't compared to simple algorithms. So, we don't know if the computational cost is worth it. (Source)
Also, we're behind in securing low-power Internet of Things devices. Most deep learning models use too much memory/computational power for them. But they're increasingly common in essential industries. (Source)
Some researchers are trying simple techniques to fix this gap. Here are two case studies that take inspiration from our immune systems and computer vision techniques.
First, let's acknowledge the problem with standard neural networks. Malware files have millions of bytes. An input layer with millions of neurons simply won't work. So standard neural networks would only work on extracted features of malware files like opcode histograms.
What about recurrent neural networks to treat the malware bytes as sequence data? This has definitely been attempted. (Source) Unfortunately, it tends not to be very computationally-efficient. Also, timestep dependencies are challenging when dealing with millions of bytes, most of which aren't related to malicious functionality.
Thus, we turn to convolutional neural networks. Their specialty is breaking images into chunks and the same parameters to process every chunk. This kind of reuse would be great across a file with millions of raw bytes. So what if we could split a large malware file into many smaller chunks, reusing the same parameters to analyse every chunk?
Some researchers just convert bytes from a malware file into images (byte plots). Ex: you could just turn 1s/0s into white and black pixels. This turns a 'sequence of bytes problem' into an 'image processing problem' so convolutional neural networks can be used. (Source)
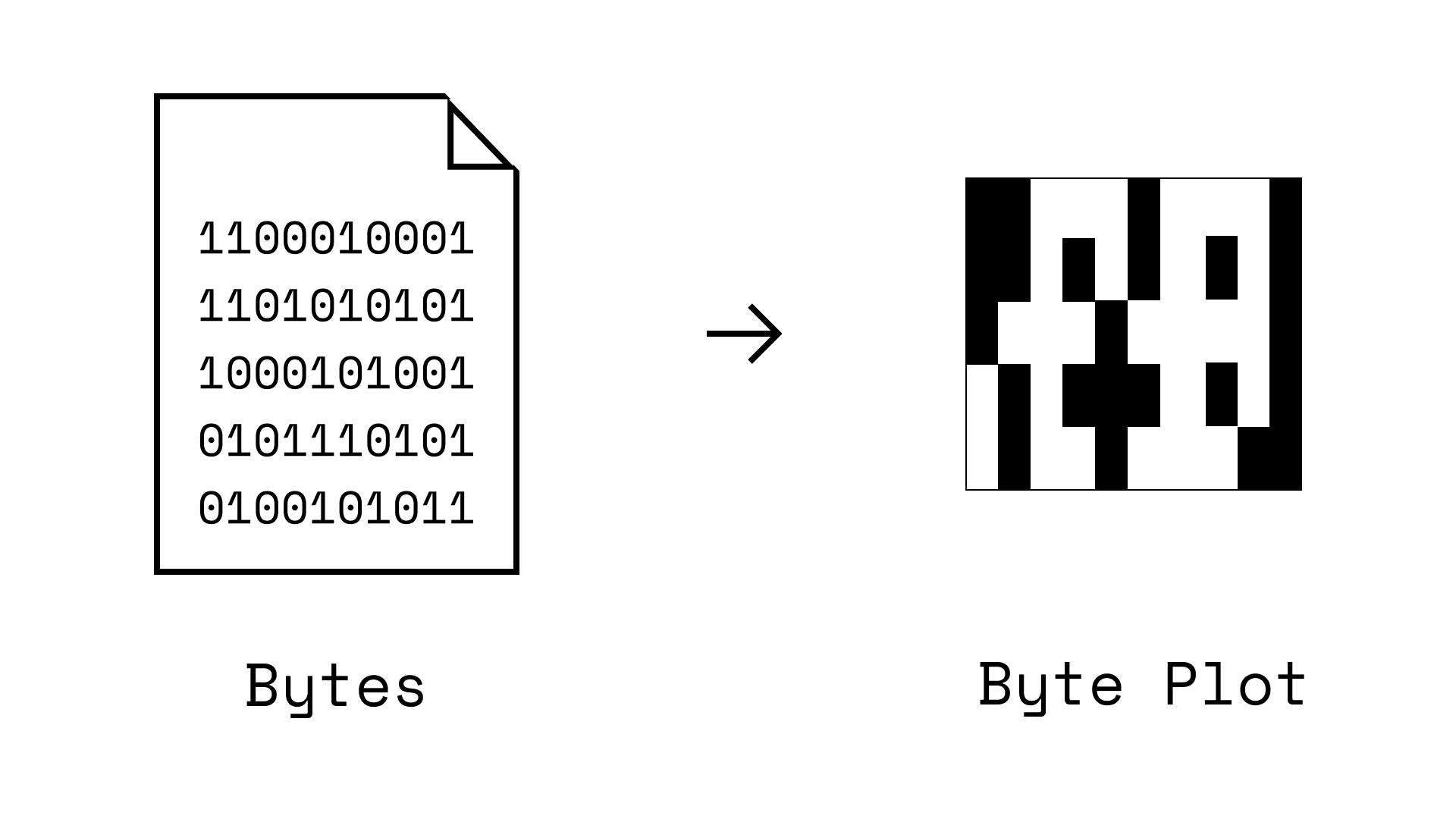
This somewhat works, but it has issues. Specifically, files are one-dimensional code sequences, not a two-dimensional image.
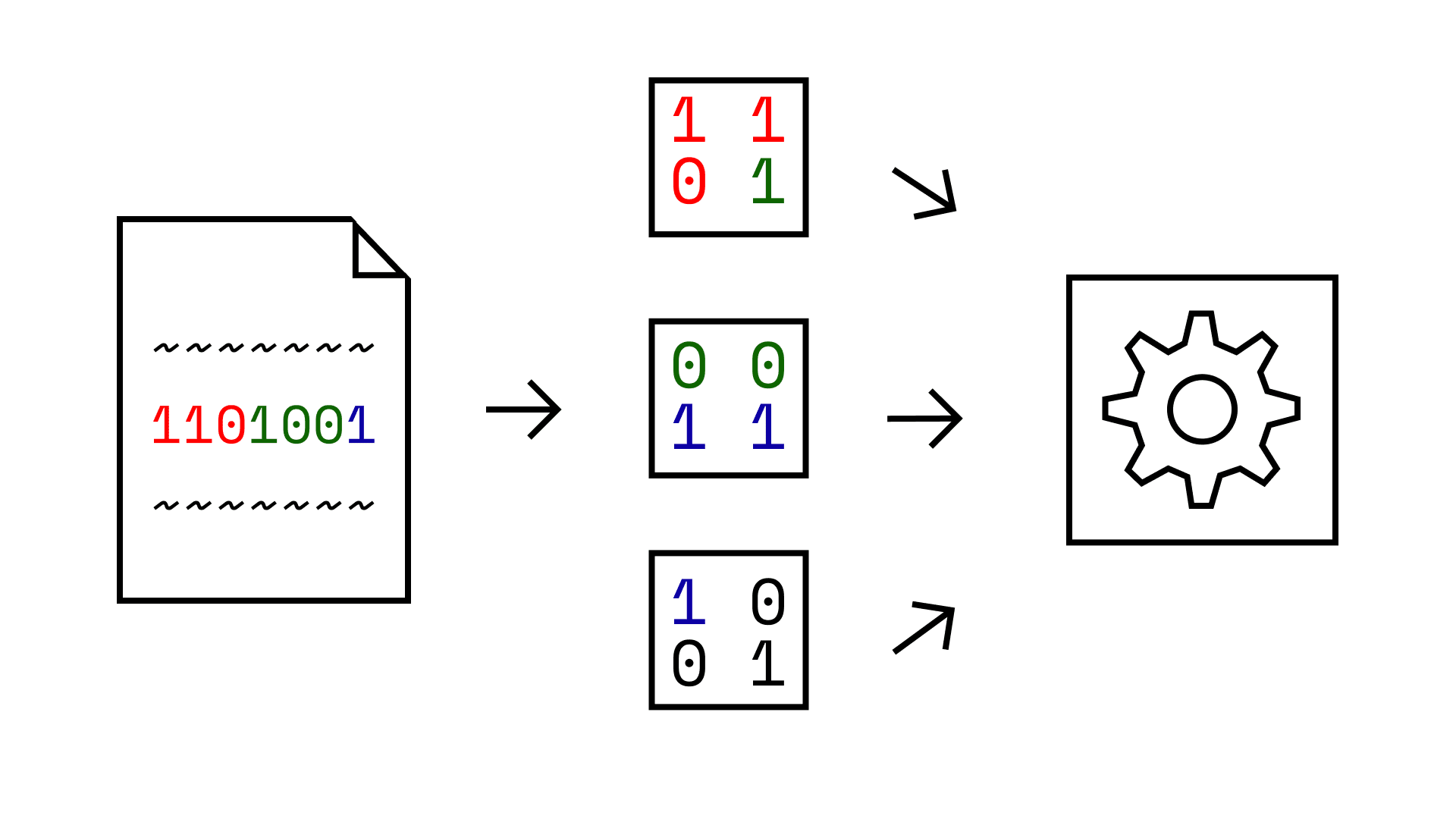
The researchers fixed these issues by just using one dimensional convolutional neural networks. The key idea is still to break up a large sequence of bytes into smaller chunks. But one dimensional chunks in a row instead of two dimensional chunks in a square.
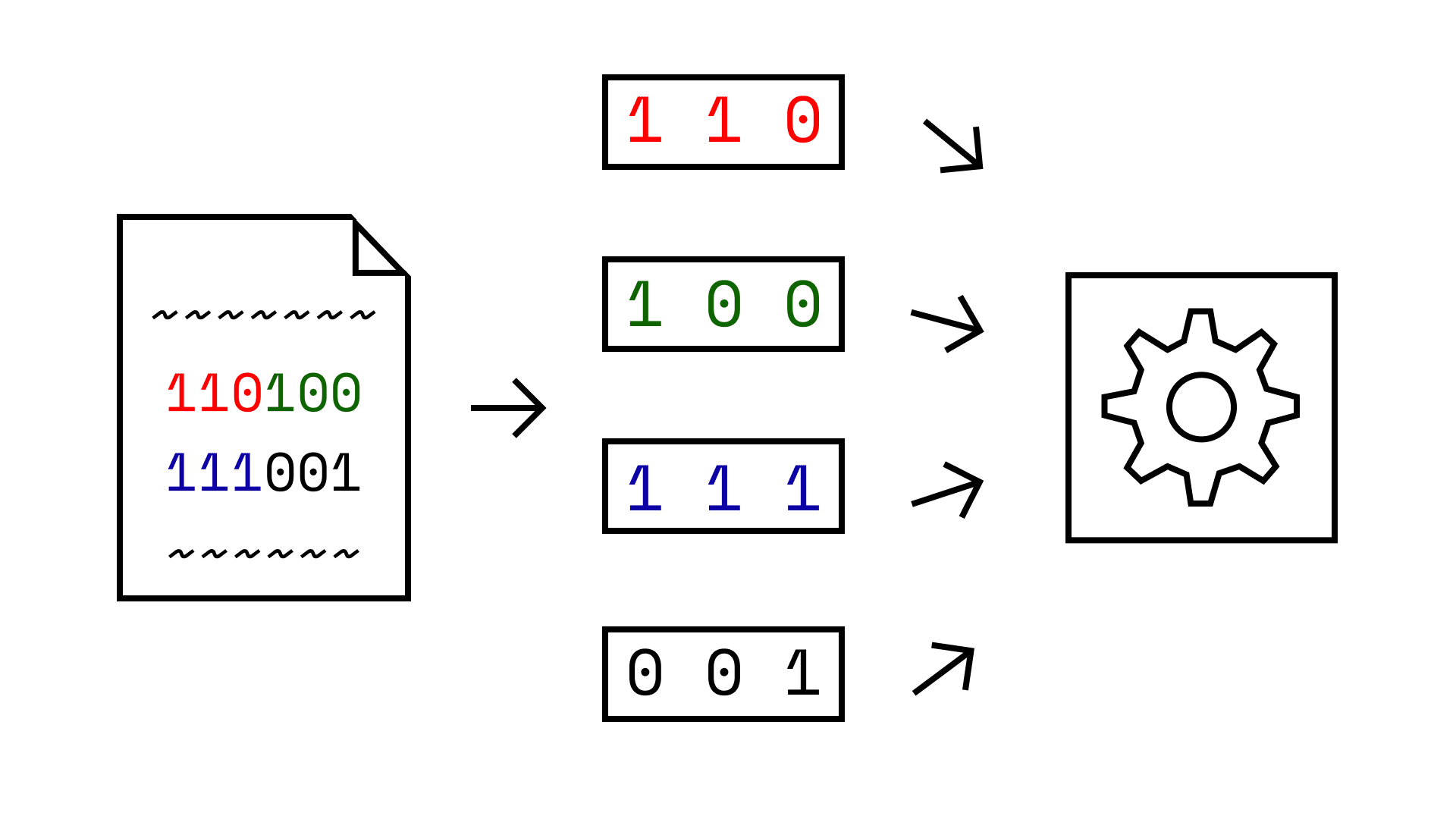
As a technical aside, the researchers also implemented separable depthwise convolution to improve efficiency. Also, they chose a kernel size of three since most opcodes are three bytes long. They called this approach sequence depthwise separable convolution.
All this resulted in 10x fewer parameters than even the most efficient AI models. And 30x faster training times than comparable cybersecurity algorithms. Here are more detailed statistics:
| Model | Parameters | Accuracy (%) | Precision (%) | Recall (%) | Mega FLOPs | Time / Epoch |
| MobileNet | 2.2 M | 96.4±0.1 | 96.6±0.5 | 96.6±0.5 | 333 | 2.6 mins |
| MalConv | 1.2 M | 98.0±0.1 | 97.8±0.5 | 98.3±0.5 | 266 | 72.1 mins |
| MalConv GCT | 1.2 M | 98.0±0.1 | 97.8±0.4 | 98.3±0.5 | 1091 | 158.5 mins |
| SeqNet (New) | 0.1 M | 97.4±0.2 | 97.4±0.8 | 97.5±0.7 | 193 | 2.9 mins |
The last algorithm is efficient enough to run on mobile phones. But it still wouldn't work for low-power Internet of Things devices. The key issue is that any kind of neural network requires new computations to analyse every file.
The opposite approach is to run all computations needed for a malware detection algorithm ahead of time. And then save the results. This requires the low power devices to store the results in memory, but not use any processing power.
One algorithm that does this is an artificial immune system. It copies our bodies' immune systems. Specifically, our immune systems store tools called antibodies to spot harmful microorganisms later. But the artificial version stores a specific pattern (signature) from malware files to match against new files. (Source)
Still, the signature can't simply store some bytes like past algorithms. These bytes vary a lot between malware files, making the signatures unhelpful for detecting new malware. So artificial immune systems model the way that antibodies evolve to generate signatures. These signatures match more kinds of malware.
First, here are the steps to set up the algorithm: (Source)
Next, here are the steps repeated while the algorithm is running: (Source)

Repeating those steps eventually makes signatures that resemble malware file data. We can then save these signatures on low power Internet of Things devices. They can compare the data from any incoming file against these signatures. If the similarity is high enough, they filter those files as malware.
Using a slightly more complex variation, some researchers found they could detect 99 out of a 100 malware samples for Internet of Things devices. (Source)
Having discussed recent advances in the field, where is improvement needed? I see two categories: technical improvements to algorithms and meta improvements to research.
P.S. This section is largely based on my personal opinions after about 100 hours of researching this topic.
The above case studies showed improvements in the efficiency of malware detection algorithms. Unfortunately, hackers still cause large problems when changing malware to create adversarial examples for detection models.
Two factors make adversarial examples in malware detection more challenging than in other AI applications.
AI algorithms can continuously train to detect new malware examples. Still, this is reactive not proactive. Especially if hackers use AI algorithms to generate malware, new malware will spread faster and faster. Thus, a proactive solution is preferable.
Potential next steps for this are to use generative adversarial networks to modify malware examples to simulate what hackers might do. These adversarial examples could train AI algorithms proactively. Though this strategy is already researched, it has high dual use risk. Hackers could use these algorithms to modify their own malware.
Overall, more research is needed on how to keep malware detection algorithms from having low performance after hackers change their techniques (ideally, with few dual use risks).
A secondary problem is ensuring that malware detection algorithms are secured against trojans. (Source) Still, this is a secondary problem. It's currently much easier for hackers to bypass malware detection algorithms by updating malware than creating trojans. (This is because the hackers would have to influence the training process of a malware detection algorithm to create a trojan, not just send it new input.)
Finally, as a technical musing, it may be possible to combine gradient-based optimisation methods with biology-inspired artificial immune systems. Specifically, random mutation is used as the optimisation method for many biology-inspired algorithms. Though this specific step could easily be replaced by a gradient-based optimisation method that relies on a particular objective function (or in the jargon of biological computing, a particular fitness function). Depending on the hyperparameters, this could lead to more computationally efficient training for artificial immune systems. Yet, the advantage of precomputed results would remain.
In addition to the technical points above, there are also more general research practices that would help this field. The most important practices are noted in this paper.
First, more researchers need to compare state of the art algorithms with simple algorithms. This will help determine if the complex models are 'worth it' due to extra performance. For instance, the CNN in the first case study could be compared to a simple decision tree or human-made YARA rules.
Next, research papers need more transparent reports of how sampling bias in datasets was handled (and in general, which preprocessing occurred).
Finally, research on malware detection should report a standard set of evaluation metrics: accuracy, precision, recall, ROC curves, AUC, and the count of data points in various classes. This should just be a given with any imbalanced data problem, but it's surprising how many of the top papers on AI-enabled cybersecurity algorithms neglect it.
Overall, AI-enabled malware detection is an impactful problem that could be called "the ultimate robustness challenge." Personally, I expect the techniques developed in this field will help the general AI safety field to progress.
As outlined above, however, the field is still crippled by the challenge of keeping algorithms effective even as hackers actively work against them. A lot of interesting work remains to be done to fix this. So I hope that the explanations and citations above will help more minds to work on this. If you have any questions or feedback on my writing, please feel free to comment and I will happily explain my reasoning in more depth :-)