The following text is meant to be an introduction to existential risks from advanced AI for professionals outside of the AI safety community, in particular scientists in other relevant fields, politicians, and other decision-makers. The aim is to raise awareness of the problem and encourage further research, in particular in Germany and the EU. Some background on why I chose this particular framing is given here.
Thanks to Remmelt Ellen, Evander Hammer, Koen Holtman, Emil Ifthekar, Jakub Kraus, Konstantin, and Olaf Voß for valuable feedback and suggestions.
Summary
This post examines four hypotheses:
- Certain kinds of artificial intelligence (AI) are uncontrollable.
- An uncontrollable AI pursuing the wrong goal poses an existential risk to humanity.
- It is unclear how the goal of an uncontrollable AI can be formulated in a way that an existential risk can be ruled out with sufficient probability.
- An uncontrollable AI may be technically possible before 2040.
If these four hypotheses are correct, uncontrollable AI poses a significant existential risk to humanity in the foreseeable future. But currently, particularly within the EU, practically nothing is being done to research or solve this problem. This urgently needs to change.
Introduction
The development of AI has made rapid progress in the past years. Computers can solve more and more tasks faster and with better quality than humans. Therefore, many see AI as a universal tool for the solution of nearly all problems of humankind. However, AI itself can also become a problem, as is apparent for example in the negative effects of social media algorithms on society, biases and severe mistakes of AIs in various domains, or accidents with self-driving vehicles.
As early as the beginning of the age of computers, leading scientists pondered the consequences if AI would one day surpass human intelligence and become uncontrollable. In a script for a BBC show in 1951, Alan Turing wrote: “If a machine can think, it might think more intelligently than we do, and then where would we be?” 1) Norbert Wiener stated in 1960: “If we choose, to achieve our purposes, a mechanical agency with whose operations we cannot efficiently interfere once we have started it … then we had better be quite sure that the purpose put into the machine is the purpose which we really desire and not merely a colorful imitation of it.”2)
For a long time, speculations about out-of-control AI were a domain of science fiction that wasn’t taken seriously by most scientists, even though Irving J. Good observed as early as 1965: “Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an ‘intelligence explosion’, and the intelligence of man would be left far behind. Thus the first ultraintelligent machine is the last invention that man need ever make, provided that the machine is docile enough to tell us how to keep it under control. It is curious that this point is made so seldom outside of science fiction. It is sometimes worthwhile to take science fiction seriously.”3)
In recent years, scientists like Nick Bostrom4) at Oxford University, Stuart Russell5) at the University of California in Berkeley, or Max Tegmark6) at the Massachusetts Institute of Technology have begun to analyze the consequences of the possible development of artificial general intelligence (AGI). However, this is still a niche, with only a few dozen researchers outside of AI labs working on it globally7). Within the EU, the topic is apparently completely ignored in academic circles. At the same time, it seems plausible to assume that an uncontrollable AI could be the biggest existential threat to mankind within the next decades – even more dangerous for our long-term survival than climate change or a global nuclear war, at least according to Oxford philosopher Toby Ord.8)
Is he right? Is uncontrollable AI really an existential threat, or is this concern as unjustified as “worrying about overpopulation on Mars”, as Andrew Ng, former head of development at Baidu, put it? 9) In the following, this question is analyzed based on four hypotheses.
Hypothesis 1: Certain kinds of AI are uncontrollable
The discussion about existential risks from AI often implicitly assumes that such a risk is based on the development of AGI – an AI that is at least as intellectually capable as a human in most domains. Often, the term “superintelligence” is used for an AI that is far more intelligent than any human. In contrast, today’s AIs are only capable of making decisions on par with humans in very narrow domains.
This anthropomorphic view, however, may be misleading. It suggests that it will be a long time before AI can get “dangerous”, as we don’t even fully understand how our own intelligence works. While it seems reasonable to assume that an AI that far surpasses human intelligence in every aspect would indeed be uncontrollable, this doesn’t have to be a necessary condition.
An AI should be regarded as “uncontrollable” if it is able to circumvent or counter nearly all human measures to correct its decisions or restrict its agentic influence in the world (fig. 1).
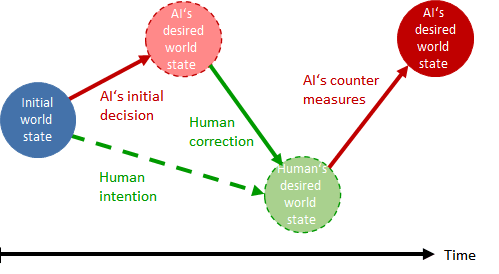
Fig.1: Schematic diagram of a decision conflict between an AI and humans
Based on a given initial world state, the AI seeks to achieve a target world state and plans its actions accordingly. If this is not their desired world state, humans may try to correct the AI’s decisions or prevent it from performing its planned actions, for example by turning it off. If the AI is able to circumvent or counter these human corrections and still achieve its desired world state, it must be deemed uncontrollable.
This type of conflict can be seen as a game in which the AI plays against human opponents. The AI wins the game if it is able to achieve its desired world state. It could be called a “game of dominance” in which the winner is able to force their decisions on the loser.
In a short time, AIs have achieved superhuman performance in many games that have been seen as out of reach for machines not long ago.10) The “game of dominance” described above is no doubt much more complex than Chess, Go, or computer games. But to win it, an AI doesn’t necessarily need superhuman intelligence in every aspect. Instead, it just needs the skills and knowledge sufficient to beat its human opponents in the given situation.
In particular, the AI must be able to devise a plan that leads to its desired world state and act it out in reality (fig.2). Based on an internal model of the real world, it must analyze the given world state, compare it to the desired world state, and define actions that will achieve its goal. It then must perform these actions, for example by controlling machines or influencing humans, measure their results, and if necessary, adapt its plan in a permanent feedback loop.
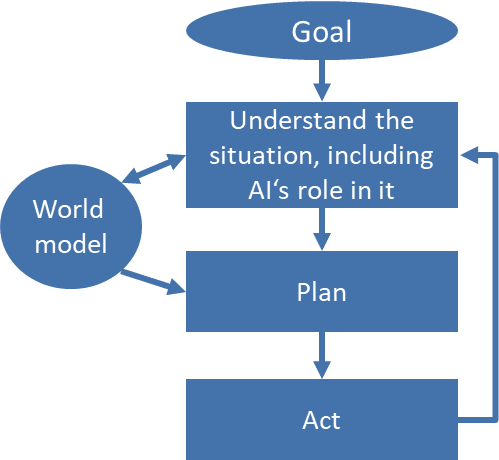
Fig. 2: Generic decision process of an agentic AI
An important factor in this process is the AI’s ability to recognize itself as a critical part of its plan, which Joseph Carlsmith calls “strategic awareness”.11) This is not to be confused with the philosophical and neurological concepts of “consciousness”. It is not important for the AI to have a “sense of self” or subjective experiences. Strategic awareness is the purely analytical realization that the AI itself is a part of its plan and a potential object of its own decisions.
This kind of strategic awareness automatically leads to certain instrumental goals12), which are necessary parts of its plan to achieve its original goal:
- The AI must prevent being turned off, as otherwise, it can’t achieve its goal.
- The AI must prevent any changes to its original goal because otherwise, it won’t be able to pursue it anymore.
- The AI will seek power in the real world since this will help it to achieve its main goal and the other instrumental goals.
- The AI will try to improve itself since this makes it easier to achieve its goals.
These instrumental goals are independent of the main goal and will often lead to conflicts with human goals, in particular the human desire to control the actions of the AI. The better the AI is at achieving its instrumental goals, the stronger it becomes in the “game of dominance”. For this, it can use advantages over humans typical for computers, like faster decision-making, better memory, and access to very large amounts of data (fig. 3). In particular, the ability to manipulate humans could be very useful, which even today’s recommendation engines and chatbots display in a rudimentary form. On the other hand, many other domains of human intelligence, like the ability to move in 3D space, use tools, or understand physical processes, may prove to be of less importance.
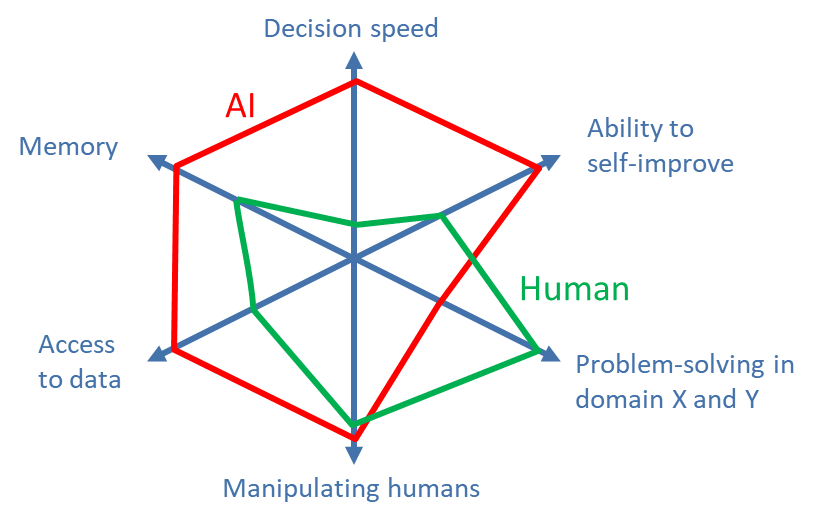
Fig. 3: Exemplary comparison of human and AI skills in some domains
An AI that has strategic awareness and the necessary skills to win the game of dominance will be able to counter or circumvent most human measures to restrict its actions or correct its decisions. It will therefore be uncontrollable. If it is able to increase its own abilities, for example by gaining access to more computing power and data or by improving its own code, over time it will become exponentially better at the game of dominance and finally reach superintelligence (fig. 4).13) However, as described, this is not a necessary condition for initial uncontrollability.
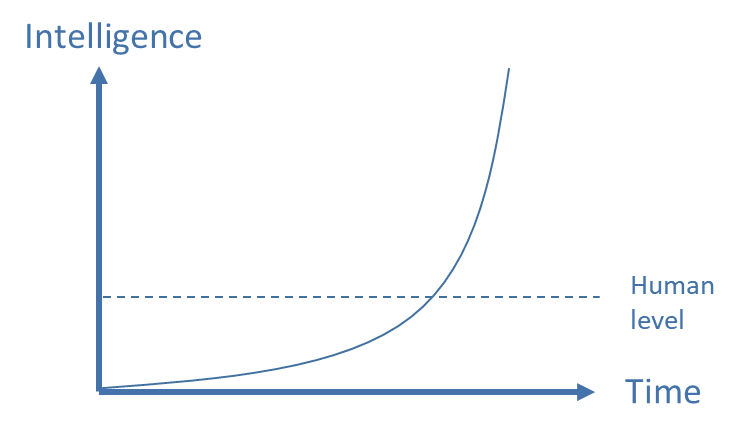
Fig. 4: Exponential growth of the AI’s intelligence by recursive self-improvement
Hypothesis 2: An uncontrollable AI pursuing the wrong goal poses an existential risk to humanity
It seems obvious that an AI that repeatedly wins the game of dominance against humans and, according to its instrumental goals, seeks power in the real world will sooner or later gain control of all important resources on Earth – just like humans have gained (almost) complete control of Earth and have wiped out many species in the process. In the best case, this would lead to a situation where humans have no control over their fate anymore. Depending on the AI’s goal, it could also lead to the complete annihilation of humans and most other species, thus posing an existential risk to humanity.14)
A common objection against this view is the claim that an AI smarter than humans would know by itself what “the right thing to do” will be. However, the principle of goal orthogonality shows that this is not the case: The goal of an AI is independent of its intelligence.15) Nick Bostrom illustrates this with the example of a superintelligent AI that pursues the goal of making “as many paperclips as possible”: It will use its intelligence to build more and more factories until all accessible matter has been turned into paperclips. The needs of humans and other species are not part of its goal function and are therefore neglected.16)
Generally, it must be assumed that an AI will only factor those variables in its plans that are either part of its main goal or important for the achievement of its instrumental goals (fig. 5). As Stuart Russell observes: “One of the most common patterns involves omitting something from the objective that you do actually care about. In such cases … the AI system will often find an optimal solution that sets the thing you do care about, but forgot to mention, to an extreme value.”17) This can easily lead to a world state not compatible with the survival of humanity (fig. 6).
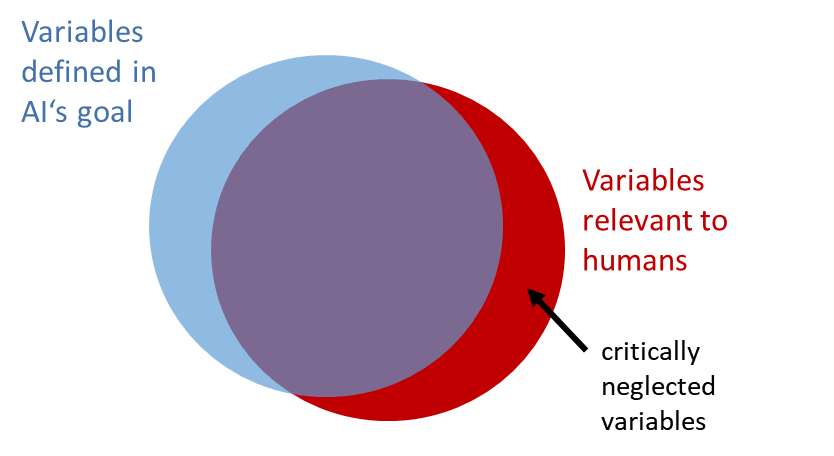
Fig. 5: Incomplete overlap of elements in the AI’s goal with elements important for humans
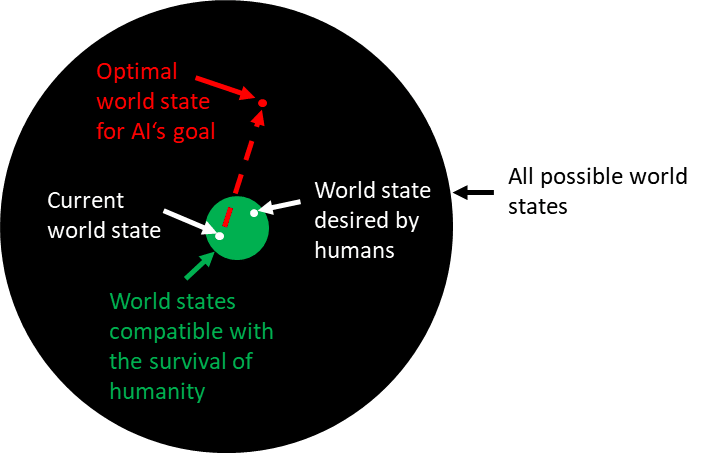
Fig. 6: A possible AI goal leading to a world state incompatible with human survival
For example, if the average global temperature is not part of the AI’s goal, it might increase this value by building a large number of computers for the purpose of improving its own capabilities, thereby worsening climate change up to the point where humans cannot survive anymore. The problem of including all values relevant to humans in an AI’s goal in an appropriate and feasible way is called the “AI alignment problem”.18)
Various experiments have shown that AIs indeed tend to come up with strategies to achieve their goals which are often unexpected by humans. For example, an AI trained to play the game Coast Runners developed a bizarre strategy to maximize its score: Instead of completing the course of the boat race as intended by the human game designers, it steered the boat in an endless circle in order to acquire as much bonus points as possible (Fig. 7).19)
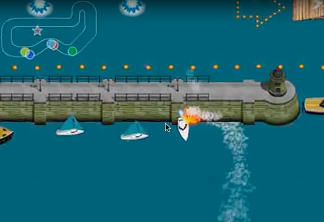
Fig. 7: Uncommon strategy of an AI trained to play the game Coast Runners
Human behavior provides further evidence that the alignment problem is real. For example, climate change can be seen as a result of a misalignment between the goals of the carbon industry and humanity’s needs. The reward function of the relevant companies is mainly based on maximizing profit. Variables like CO2 emissions and global average temperature are not part of it. Reducing environmental damage is instead a cost factor that needs to be minimized in order to maximize reward.
That companies also play a version of the “game of dominance” becomes obvious when governments try to interfere with a company’s decisions by enforcing environmental regulations. The company will often try to avert these interferences, for example by lobbying, supporting parties with less focus on environmental regulation, or moving their production facilities to countries with lower environmental standards. As a consequence of this industrial alignment problem, global temperature has significantly risen in recent years (fig. 8).
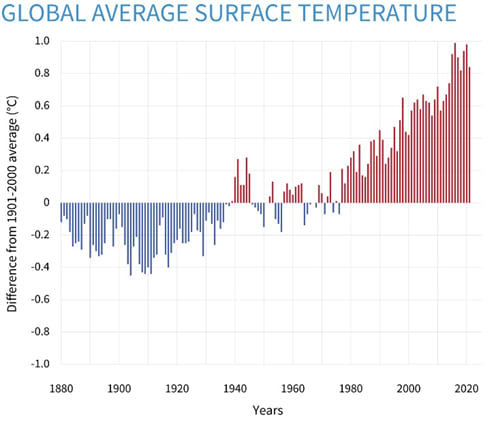
Fig. 8: Global average temperature 1880-202020)
As the example of humanity shows, an out-of-control superior intelligence can be an existential catastrophe for other species. It must be assumed that it would be similarly catastrophic for humankind if an AI became uncontrollable and its goals were not perfectly aligned with human needs.
Hypothesis 3: It is unclear how the goal of an uncontrollable AI can be formulated in a way that an existential risk can be ruled out with sufficient probability
As indicated before, specifying a goal that includes all elements relevant to humans in an appropriate way is a serious challenge. Researchers in this field agree that a practical solution to the alignment problem is not expected to be found in the near term,21) if a solution is possible at all.22)
As stated above, the AI’s goal must include all variables relevant to humanity either directly or indirectly, or else there is a significant risk that the AI will set them to intolerable values. One problem with this is that we likely don’t know all the relevant variables yet. At the beginning of the industrial age, for example, the critical influence of CO2 emissions on global temperature was unknown. This led to misguided policies and a resulting climate change, which we are experiencing today. It seems unlikely that we will be able to define a goal for an AI that includes all known and unknown factors relevant to humans in the right way. On the other hand, because of the AI’s instrumental goal to prevent a change to its goal function, it will not be possible to change this goal afterward. Therefore, it is highly likely that whatever goal we define will sooner or later turn out to be insufficient.
Another difficulty derives from the fact that artificial neural networks are inherently opaque: It is often impossible to understand why they make certain decisions.23) While there are some efforts to improve transparency and explainability, increases in model sizes and capabilities will likely make this even more difficult. Humans are also often unable to explain their own intuitive decisions, and sometimes construct false explanations in hindsight. 24)
A further problem lies in the process of training the AI. Typically, neural networks are trained to make decisions based on large data sets. But these data sets can never fully reflect the complexity of reality. Accordingly, AIs can make wrong decisions because of differences in the distribution of certain elements in the training data vs. reality (fig. 9). This so-called dataset shift25) can also be relevant for the learned goal function of the AI. In consequence, an AI may behave as expected within its training environment but may pursue a different and possibly unintended goal when deployed.
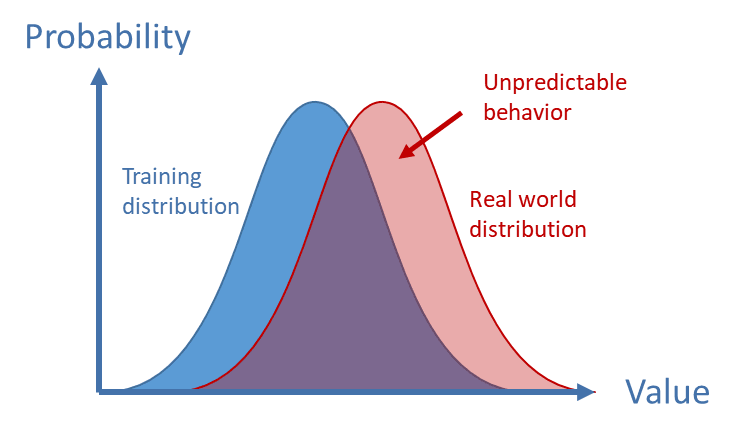
Fig. 9: Dataset shift
Finally, the stability of the AI’s goal over time is problematic as well, in two different ways: On one hand, the AI’s interpretation of how to achieve its goal may change over time as its world model changes. Software bugs or hardware defects could accumulate over time and can in principle also lead to a change in the interpretation of the AI’s goal. On the other hand, human values and needs likely change over time, e.g. because of cultural changes. Slavery, for example, was seen as morally acceptable by many people during most of human history. At the same time, new values and needs may develop, like the historically relatively young concept of freedom of speech. 26) However, launching an uncontrollable AI is an irreversible act and because of its instrumental goals, it is impossible to adapt the AI’s goal function to changing human needs. This may cause what William Macaskill calls a “value lock-in”.27) For these reasons, it can be expected that over time, the AI’s goal will increasingly deviate from human needs even if it has fit them perfectly at the beginning (fig. 10).
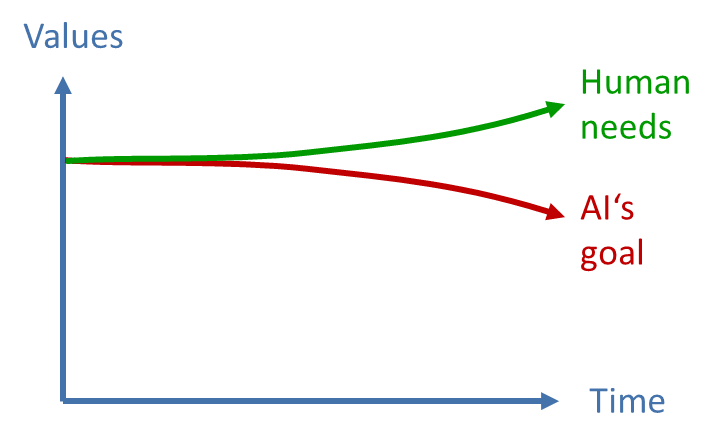
Fig. 10: Increasing deviation of an AI’s goals from human needs
One proposed solution to the alignment problem is forcing the AI to adapt its goals according to actual human decisions.28) For example, a goal could be formulated roughly as: “Always act in a way that you would regard as beneficial if you were a human.” This approach might avoid some of the problems described above, but it has its own drawbacks: It is unclear how such a vague goal could be implemented in practice, and how it could be ensured that the AI really pursues the goal that was intended by humans.
Another approach reduces the decision power of the AI by forcing it to always request feedback on its decisions from humans.29) If this was implemented successfully and consequently, the AI would not be uncontrollable in the sense of hypothesis 1. However, this approach has its own practical problems. Humans tend to blindly trust the decisions of an AI, particularly if they don’t understand how they were made. Permanent supervision of the AI’s decisions by humans, if done effectively and not just on random samples, would limit the AI’s decision power and speed to that of the supervising humans, and the utility of such a system would be questionable. On top of that, the AI might be able to manipulate or deceive its supervisors and still become uncontrollable.
In summary, it must be stated that a practically feasible solution to the alignment problem is not yet known and it is unclear if and when such a solution can be found. If the alignment problem isn’t solved in time, the development of an uncontrollable AI would in all likelihood have catastrophic consequences for humanity. A critical question, therefore, is how much time is left until an uncontrollable AI becomes technically feasible.
Hypothesis 4: An uncontrollable AI may be technically possible before 2040
The development of AI has made astonishing progress in the past 10 years. Many applications which only recently were seen as intractable for AI for a long time are now routine. For example, an article in WIRED in May 2014 stated that AIs wouldn’t be able to play Go on human level for years to come.30) Less than two years later, to the amazement of many experts, AlphaGo beat the world champion Lee Sedol in four out of five games. Another one and a half years later, AlphaGo Zero was able to teach itself to play Go without any human input or data from human games. It was able to beat its predecessor after merely three days of training, using only half of the computing power.31)
Other spectacular successes include solving the protein folding problem, which had puzzled human experts for years, by AlphaFold32), the astonishing ability of GPT-3 to create convincing texts33), AIs like DALL-E34), Imagen35) and Stable Diffusion36), which can create realistic images and paintings based on text descriptions, or AlphaCode37), which is able to write simple programs on par with humans.
It is remarkable that these successes have neither been expected nor predicted correctly by experts. On the other hand, they were not achieved by ever more refined, human-designed algorithms and strategies, but simply by running relatively simple neural network architectures on ever more powerful hardware and ever larger datasets. This is shown by the billion-fold increase in computing power used for the training of leading AIs between 2010 and 2022 (fig. 11).38)
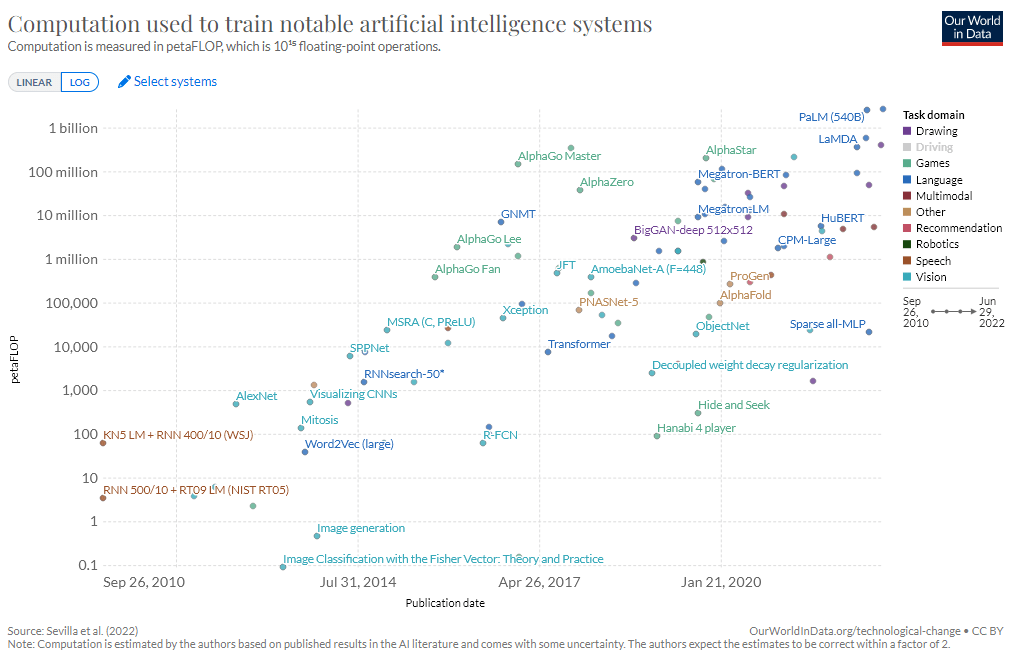
Fig. 11: Estimated computing power used to train notable AI systems
The same basic architecture of neural networks can be trained for very different purposes. For example, based on the pre-trained transformer GPT-3, which originally was designed to generate texts, an AI was trained to solve simple mathematical and logical problems.39)
Based on this apparent generalization capability of neural networks, some researchers think that “reward is enough”: simple neural network architectures with sufficient computing power and data for training may be all that is needed to achieve general intelligence.40) This leads to the scaling hypothesis, which states that the already existing neural network architecture is scalable up to artificial general intelligence and every technology necessary to build AGI is already known.41) This hypothesis is controversial.42) However, recent advances seem to indicate that there is virtually no domain of human decision-making that will remain out of reach of AI for a long time.
It remains unclear, however, how much computing power would be necessary to train an AGI. Some researchers argue that because of the recent slow-down of the exponential growth of computing power and the complexity of the human brain, it will take very long to achieve AGI. However, new technological developments, for example more efficient graphic chips and quantum computers, seem to indicate that another technological leap in the next 10-20 years is plausible.43) On top of that, further progress in the development of more efficient structures for neural networks can be expected.
Against this background, expert estimates for the time of arrival of AGI vary widely. In various surveys, the average expectation centered around the middle of the century (fig. 12, 13), with roughly 25% probability within the next 15-20 years.
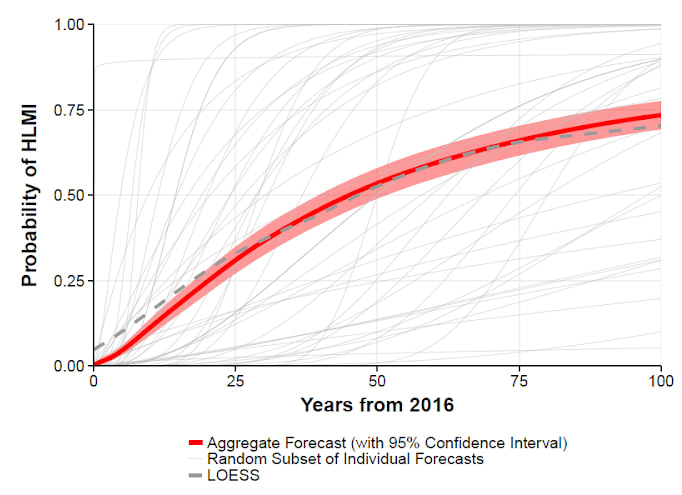
Fig. 12: 2015 expert survey for the expected time of the development of AGI44)
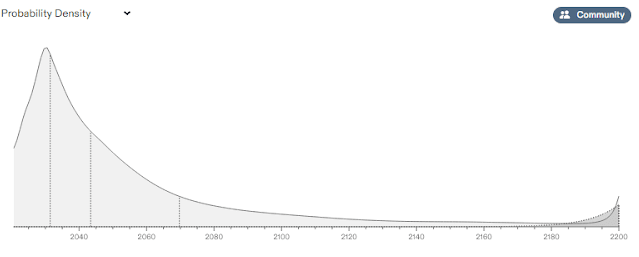
Fig. 13: Estimated time of arrival of AGI by users of the platform Metaculus, as of 8-15-202245)
An estimate based on biological anchors comes to a similar conclusion (fig. 14).
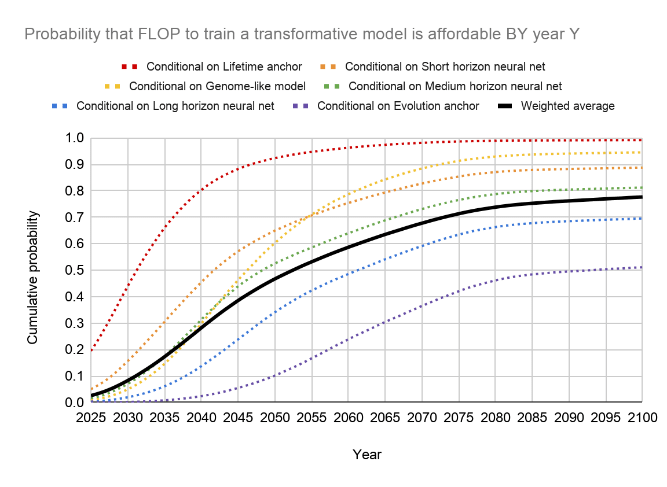
Fig. 14: Estimate of the time AGI is feasible based on various biological anchors46)
The most remarkable feature of these surveys is the very broad distribution of opinions. Some researchers think AGI will not be developed within this century or may even be impossible at all, while others deem it plausible that it will be feasible within the next ten years (fig. 15).47)
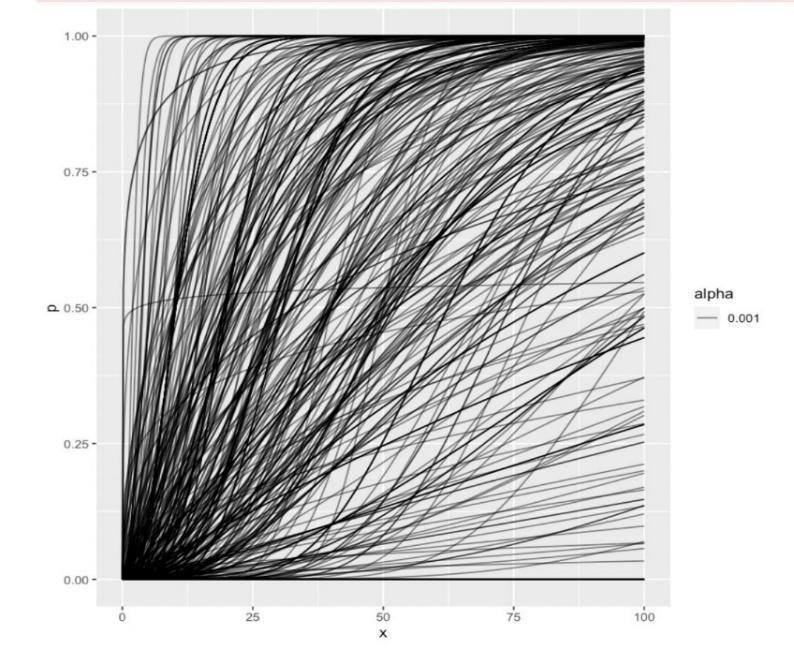
Fig. 15: Estimates by various experts of the probability distribution for the feasibility of AGI, in years from 2022
This broad distribution leads to the conclusion that there is high uncertainty about the time when AGI is technically possible. On average, experts indicate a probability of roughly 25% before the year 2040. As shown in hypothesis 1, this is probably a lower boundary for the feasibility of uncontrollable AI, which doesn’t necessarily need to have all the features of true AGI.
Given the existential risk described in hypothesis 2 and the low probability of finding a solution for the alignment problem in the near future according to hypothesis 3, we are in a critical situation. Even a probability of 25% of uncontrollable AI before 2040 is much too high to be acceptable given the existential threat to humanity. From a risk management perspective, it would be irresponsible to rely on the assumption that an uncontrollable AI will not be possible for a long time (fig. 16). Instead, we need to assume the “worst case” of a short timeline.
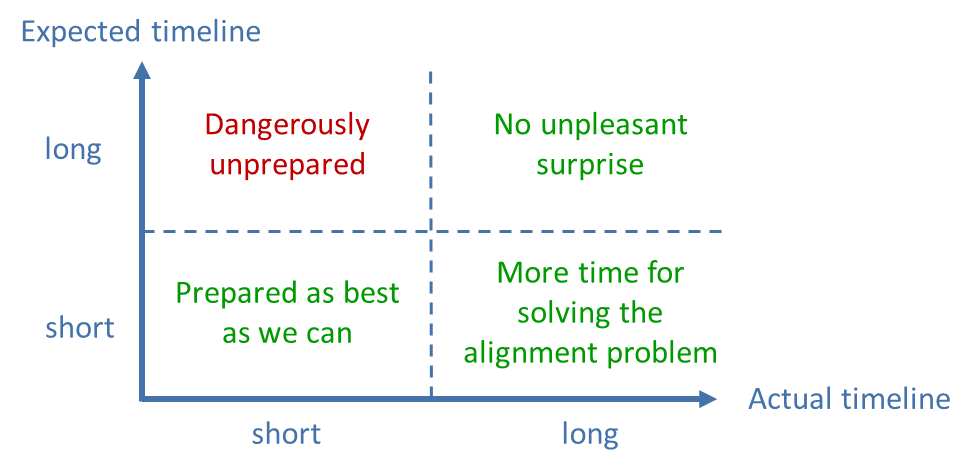
Fig. 16: Risk assessment of long and short expected and actual timelines
In summary, based on our best current knowledge, an existential threat from uncontrollable AI before 2040 cannot be ruled out with sufficient probability. On the contrary, although it may still sound like science fiction, this possibility is so realistic and its potential consequences so vast that it must be seen as a very important and urgent problem.
Conclusions
Against the background of the situation described above, it should be expected that across the European Union, researchers were working intensely on ways to avoid uncontrollable AI. At the very least, given the high uncertainty, research projects should be underway to analyze the risks in detail. This, however, is not the case. As of early September 2022, I am not aware of any project by a public or private research institute within the EU analyzing the risks from uncontrollable or superintelligent AI, let alone searching for solutions to the alignment problem. Unlike the UK and the US, within the EU there is no research institute dedicated to exploring existential risks from AI. This is in stark contrast to the EU’s aspiration to play a leading role in the regulation of AI, which it displays with the proposed “AI Act”.48) How this can be achieved without a solid scientific foundation remains unclear.
It should therefore be imperative
- to immediately launch at least one research project with the aim of analyzing the risks from uncontrollable AI described in this paper, thereby either confirming or refuting the hypotheses and further quantizing their implications
- to develop recommendations for how to mitigate the risks from uncontrollable AI, for example through
- a massive expansion of the research on the alignment problem in Germany and the EU
- developing limits and “red lines” for research and development that should not be crossed in order to safely avoid uncontrollable AI
- defining concrete, binding rules and regulations for AI research and development (in addition to the AI Act, which is quite vague in this respect)
- negotiating international treaties with the aim of reducing competitive pressure, avoiding a global “AGI race” and ensuring global adherence to the aforementioned rules
- creating at least one independent institution within the EU with the purpose of permanently monitoring and analyzing the development of advanced AI and its implications for society.
It should be made clear that the risk of uncontrollable AI is independent of who develops it. Even an AI created with the best intentions will lead to an existential catastrophe if it gets out of control and the alignment problem hasn’t been solved in advance. It is a fallacy to think it would be preferable that an AGI would be developed first in a western AI lab because other actors might act “less responsible”. This only leads to an unnecessary increase in competitive pressure, speeds up the global race for AGI, and may cause the negligence of safety aspects. The truth is that an existential catastrophe from an uncontrollable AI would affect all of humanity in the same way. In such a race there will be no winner.
Until the alignment problem has been solved, the only possibility to avoid an existential threat from uncontrollable AI is to not develop it. The best way to do this is to achieve a global consensus concerning the risks. Intensifying the research to achieve this consensus is of utmost importance.
Appendix: Common objections
The following table contains common objections against the risks from uncontrollable AI and possible answers.
| Objection | Possible reply |
| People have always been afraid of technology, but they have always been proved wrong. | There are many dangerous technologies, like atomic bombs, which must be treated with extreme caution. Climate change and environmental destruction show the negative effects of technology. |
| We can always turn off a misbehaving AI. | You can "turn off" humans too, by killing them. Yet certain powerful people manage to cause great catastrophes, and nobody turns them off; this is because they make themselves quite hard to turn off. Similarly, a highly intelligent agent might make itself quite hard to turn off (because it can't accomplish its goals if someone turns it off). |
| AI will never be as smart as humans. | AI is already better than humans in many narrow domains. There is no scientific evidence that any problem that humans can solve, AI can’t solve in principle. To be uncontrollable, AI doesn’t necessarily have to be smarter than humans in every aspect. |
| AI will never be conscious. | Uncontrollable AI doesn’t have to be “conscious” the way humans are. “Strategic awareness” is sufficient. |
| Advanced AI will have no will of its own. | AI may follow the goal that we give it but will come up with its own strategy to pursue it, which may not be what we intended. |
| Advanced AI will know what is right. | Goal orthogonality states that even a very smart AI can pursue a single-minded, “stupid” goal, like making as many paperclips as possible. |
| We can control advanced AI by limiting its access to the outside world. | Uncontrollable AI may find a way to either directly gain access to the outside world (e.g., through “hacking”) or convince humans to give it access. |
| Uncontrollable AI is still a long way off. | We don’t know when uncontrollable AI is possible, but we can’t rely on it being a long way off. Expert surveys indicate that it may well happen before 2040. |
| We will solve the alignment problem in time. | Experts agree that solving the alignment problem is extremely difficult and we’re not even close to a solution yet. Nobody knows for sure how long it will take, or if it is even possible at all. |
| We just need to build an AI with the goal to solve the alignment problem. | An AI that can solve alignment would already have to be aligned, so this is circular reasoning. |
| Nobody will want to develop uncontrollable AI. | Uncontrollable AI could be developed by accident, overconfidence, or negligence of the risks. |
| We have more urgent problems. | Given the dimension of the risk and the urgency, uncontrollable AI is a severely neglected topic compared to most other problems. |
Sources and literature
- https://turingarchive.kings.cam.ac.uk/publications-lectures-and-talks-amtb/amt-b-5
- Wiener, Norbert: Some Moral and Technical Consequences of Automation, Science, 1960, https://www.science.org/doi/10.1126/science.131.3410.1355
- Good, Irving John: Speculations Concerning the First Ultraintelligent Machine, Advances in Computers Vol. 6, 1965
- Bostrom, Nick: Superintelligence: Paths, Dangers, Strategies, Oxford University Press, 2014
- Russell, Stuart: Human Compatible: Artificial Intelligence and the Problem of Control, Viking, 2019
- Tegmark, Max: Life 3.0: Being Human in the Age of Artificial Intelligence, Allen Lane, 2017
- Based on a survey by AI Watch, Benjamin Hilton estimates about 300 researchers working on advanced AI safety, most of them within AI companies. The number of researchers in universities and independent institutions seems to be significantly less than 100. See Hilton, Benjamin: Preventing an AI-related catastrophe, post on 80.000 hours, August 2022, https://80000hours.org/problem-profiles/artificial-intelligence/
- Ord, Toby: The Precipice: Existential Risk and the Future of Humanity, Hachette Books, 2020
- https://www.theregister.com/2015/03/19/andrew_ng_baidu_ai/
- For some examples, see Walker, Brandon: The Games That AI Won And The Progress They Represent, online post, March 2020, https://towardsdatascience.com/the-games-that-ai-won-ff8fd4a71efc
- Carlsmith, Joseph: Is power-seeking AI an existential risk?, online document, April 2021, https://docs.google.com/document/d/1smaI1lagHHcrhoi6ohdq3TYIZv0eNWWZMPEy8C8byYg,
- Bostrom, Nick: The Superintelligent Will: Motivation and Instrumental Rationality in Advanced Artificial Agents, Minds and Machines, Vol. 22, Iss. 2, May 2012, https://nickbostrom.com/superintelligentwill.pdf
- A detailed explanation of the concept of an “intelligence explosion” is available on the website of the Machine Intelligence Research Institute: https://intelligence.org/ie-faq/
- A vivid description of a possible scenario can be found in a popular forum post by researcher Paul Christiano: https://www.alignmentforum.org/posts/AyNHoTWWAJ5eb99ji/another-outer-alignment-failure-story
- Bostrom, Nick: The Superintelligent Will: Motivation and Instrumental Rationality in Advanced Artificial Agents, Minds and Machines, Vol. 22, Iss. 2, May 2012, https://nickbostrom.com/superintelligentwill.pdf
- Bostrom, Nick: Ethical Issues in Advanced Artificial Intelligence, Cognitive, Emotive and Ethical Aspects of Decision Making in Humans and in Artificial Intelligence, Vol. 2, ed. I. Smit et al., Int. Institute of Advanced Studies in Systems Research and Cybernetics, 2003, https://nickbostrom.com/ethics/ai
- Russell, Stuart: Human Compatible: Artificial Intelligence and the Problem of Control, Viking, 2019, p.139
- Christian, Brian: The Alignment Problem: Machine Learning and Human Values, W. W. Norton & Company, 2020
- Deepmind lists some examples on their blog: https://www.deepmind.com/blog/specification-gaming-the-flip-side-of-ai-ingenuity
- Source: Climate.gov, https://www.climate.gov/media/12885
- See for example the list of open problems in the Alignment Forum: https://www.alignmentforum.org/posts/5HtDzRAk7ePWsiL2L/open-problems-in-ai-x-risk-pais-5
- Yampolskiy, Roman V.: On the Controllability of Artificial Intelligence: An Analysis of Limitations, Journal of Cyber Security and Mobility, Vol. 11, Issue 3, May 2022, https://journals.riverpublishers.com/index.php/JCSANDM/article/view/16219
- Gilpin et al.: Explaining Explanations: An Overview of Interpretability of Machine Learning, The 5th IEEE International Conference on Data Science and Advanced Analytics 2018, https://arxiv.org/abs/1806.00069
- See the term “rationalization” in psychology, for example: https://dictionary.apa.org/rationalization
- Candela et al.: Dataset Shift, in: Dietterich, Thomas (editor): Adaptive Computation and Machine Learning, The MIT Press, Cambridge, Massachusetts 2008, https://cs.nyu.edu/~roweis/papers/invar-chapter.pdf
- Issel, Konstantin: Eine kurze Geschichte der Meinungsfreiheit, online post, March 2021, https://www.die-debatte.org/debattenkultur-geschichte-der-meinungsfreiheit/
- Macaskill, William: What We Owe the Future, Oneworld Publications, 2022, pp.83-86.
- Russell, Stuart: Human Compatible: Artificial Intelligence and the Problem of Control, Viking, 2019, p. 171.
- Clifton, Jesse: Cooperation, Conflict, and Transformative Artificial Intelligence: A Research Agenda, Section 6: Humans in the Loop, post on the AI Alignment Forum, December 2019, https://www.alignmentforum.org/posts/4GuKi9wKYnthr8QP9/sections-5-and-6-contemporary-architectures-humans-in-the#6_Humans_in_the_loop__6_
- Levinovitz, Alan: The Mystery of Go, the Ancient Game That Computers Still Can't Win, in: Wired, May 2014, https://www.wired.com/2014/05/the-world-of-computer-go/
- Deepmind blog post, 18.10.2017, https://www.deepmind.com/blog/alphago-zero-starting-from-scratch
- A history of the development of AlphaFold can be found on Deepmind’s website: https://www.deepmind.com/research/highlighted-research/alphafold/timeline-of-a-breakthrough
- Brown et al.: Language Models are Few-Shot Learners, Arxiv, 2020, https://arxiv.org/abs/2005.14165
- Some impressive examples can be found on OpenAi’s website: https://openai.com/dall-e-2/
- Saharia et al.: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding, Arxiv, May 2022, https://arxiv.org/abs/2205.11487
- See a blog post by Stability AI: https://stability.ai/blog/stable-diffusion-public-release
- Li et al.: Competition-Level Code Generation with AlphaCode, Arxiv, February 2022, https://arxiv.org/abs/2203.07814
- Source: https://ourworldindata.org/grapher/ai-training-computation
- Drori et al.: A Neural Network Solves, Explains, and Generates University Math Problems by Program Synthesis and Few-Shot Learning at Human Level, Arxiv, June 2022, https://arxiv.org/abs/2112.15594
- Silver et al.: Reward is enough, in: Artificial Intelligence, Vol. 299, October 2021, https://www.sciencedirect.com/science/article/pii/S0004370221000862
- A good explanation of the scaling hypothesis can be found on Gwern’s blog: https://www.gwern.net/Scaling-hypothesis
- Vamplev et al.: Reward is not enough: A response to Silver, Singh, Precup and Sutton (2021), Arxiv, November 2021, https://arxiv.org/abs/2112.15422
- See for example McKinsey & Company: Quantum computing: An emerging ecosystem and industry use cases, Special Report, December 2021, https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/quantum-computing-use-cases-are-getting-real-what-you-need-to-know
- Grace et al.: Viewpoint: When Will AI Exceed Human Performance? Evidence from AI Experts, Journal of Artificial Intelligence Research 62, July 2018, https://www.researchgate.net/publication/326725184_Viewpoint_When_Will_AI_Exceed_Human_Performance_Evidence_from_AI_Experts
- https://www.metaculus.com/questions/5121/date-of-artificial-general-intelligence/
- Cotra, Ajeya: Forecasting TAI with biological anchors, Part 4: Timelines estimates and responses to objections, online document, July 2020, https://drive.google.com/drive/u/1/folders/15ArhEPZSTYU8f012bs6ehPS6-xmhtBPP
- AI Impacts: 2022 Expert Survey on Progress in AI, online document, August 2022, https://aiimpacts.org/2022-expert-survey-on-progress-in-ai/
- See for example the website of the European Commission: https://digital-strategy.ec.europa.eu/de/policies/european-approach-artificial-intelligence