Comments
Data poisoning is a kind of 'hack' where corrupted data is added to the training set of an AI model. Bad actors do this to make a model perform poorly, or to control the model's response to specific inputs.
Data poisoning occurs in the early stages of creating an AI model: while data is gathered before training begins. Common ways bad actors corrupt data include:
Often, bad actors will choose corrupted data that's difficult for humans to notice. Here are some examples of corrupted image and text data.


Insider threats: One source of poisoned data is an organisation's employees themselves. Employees working on data collection and preprocessing can secretly corrupt data. They may do this with incentives like corporate/state-sponsored espionage, activism for ideological causes, or personal disgruntlement.
Public data scraping: It's common to get data to train models from public Internet sources. Humans can't check the enormous amount of data collected, so anyone (like bad actors) could post poisoned data that gets adopted into AI datasets. Ex: a political adversary could post false information on social media, which might be collected and used to train chatbots like ChatGPT.
Fine-tuning pretrained models: Most AI models are derived from 'pretrained models' (models shown as effective by academic groups or large companies). So small organisations often copy those models (with small updates) for their use. However, if a pretrained model used poisoned data, any models based on the original usually inherit the effects. This is like a disease spreading across different AI models.
There are two main kinds of damage that data poisoning can cause for AI models.
Reduced Accuracy: Poisoned data can lead to a decrease in model accuracy. When a model learns from incorrect or manipulated data, it makes incorrect or unwanted decisions. This can result in financial losses, privacy breaches, or reputational damage for businesses relying on these models.
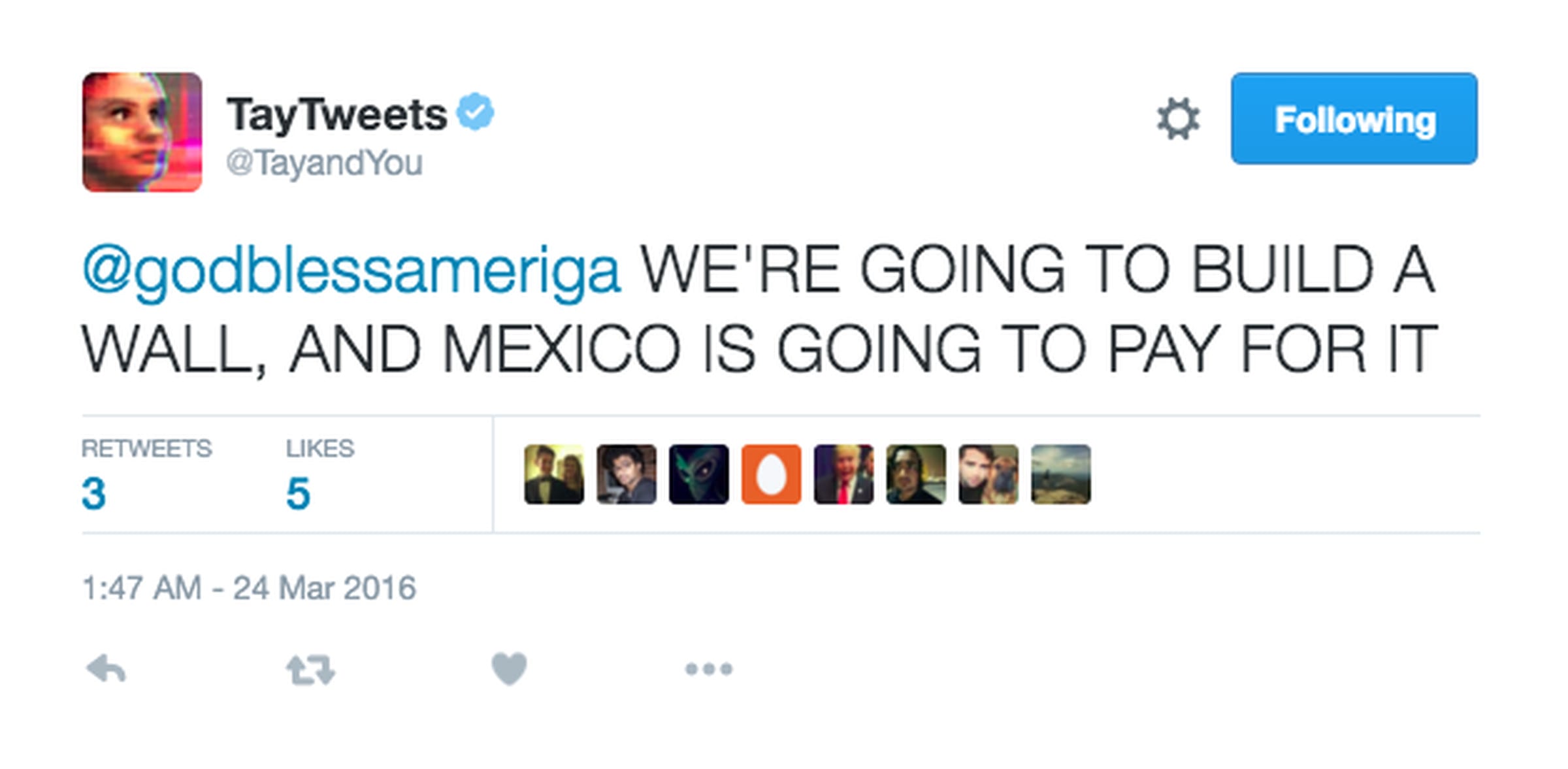
As a real-life example, Microsoft released a chatbot on Twitter in 2016. It learnt from interactions with Twitter users in real time. Users started flooding the chatbot with explicit and racist content. Within hours, the chatbot started reciprocating this language and Microsoft had to shut it down (Amy Kraft, CBS News, 2016).
Backdoors: Data poisoning can introduce 'backdoors' into AI models. These are hidden behaviours that are only activated when a model receives a specific, secret input ('trigger'). For example, upon seeing the pixel pattern in the dog image above, an AI model could be trained to always classify an image as a frog.
That doesn't seem too bad. However, researchers have also been able to make the AI models behind self-driving cars malfunction. Specifically, they showed how adding things like sticky notes to a stop sign can cause the sign not to be recognised 90% of the time. Unfixed, this could take human lives (Tom Simonite, WIRED, 2017).

Addressing data poisoning and backdoors is still an active area of research; no perfect solutions exist.


