Click here if you just want to see the Database I made of all[1] AI safety papers written since 2020 and not read the methodology. To some extent the core idea here is to encode as much info from these papers into something small enough that an AI with a specific problem in mind can take in all of these encodings from all of the papers and decide which ones are worth reading/investigating more.
Over the last month I have been trying to see just how much I can learn and do from a cold start[2] in the world of AI safety. A large part of this has been frantically learning mech interp, but I've picked up two projects that I think are worth sharing!
There are a lot of AI Safety papers. When I started working on more hands on projects there wasn't a clear way to find relevant papers. For example, if I wanted related datasets there's not a great way to search for datasets. Huggingface has a dataset search, but the search functionality is terrible. I could ask an AI to try to find relevant datasets but that's mostly just the whims of google searching. Many good datasets are hidden away in not famous papers[3]. Or, if I want to look at using a specific technique it's not easily searchable to find all papers about sparse autoencoding.
So, I had Claude[4] read every single paper it confidently classified as AI safety and then summarize it, tag it, record the year it was published, authors, etc[5]. My methodology was to start with simply asking Claude to find as many AI Safety papers as it could, as well as any existing lists of AI safety papers. This got me to ~350 papers. Then, I collected every paper that referenced at least three of these papers (~8000) and then had Claude read the ones it thought were confidently actually AI Safety papers (~3000). This citation based approach means that blog posts or anything that doesn't have an arXiv is going to be underrepresented in this dataset. Expanding off the initial 350 papers does mean that this database is biased towards the specific starting papers.
There are currently close to 4000 papers in the database which feels like an absolutely insane number of papers in the last 5 or so years. It definitely seems like many (the majority) of these papers are not substantive. My model is basically that the vast majority of papers published are written by people playing the university/academic game. The goal of playing the academia game isn’t to lower the odds of AI causing catastrophic harm to humanity, it’s to publish novel papers that get cited by other academics to build reputation which leads to good jobs where you get paid to keep working on fun problems.
Neel Nanda likes to talk a lot about how “My ultimate north star is pragmatism - achieve enough understanding to be (reliably) useful.”[6] and when I first read that it felt really obviously trivially true, why does it need to be stated. But, the better my model of mech interp (and AI safety as a whole) the more I understand why this is so important to state. LLMs are super opaque super interesting super complex. A byproduct of this is that the space of interesting fun projects one could work on is just absolutely enormous. There are so so many novel papers to be written[7].
All of which to say, the ratio of number of papers to the amount it's helping us not die is pretty depressing. The volume of papers makes it harder to find the good stuff. But, that's not to say there can't be value gleaned from them! I have found this database to be quite helpful when thinking through a new project. It's easy to find the relevant papers (and then have an AI read and synthesize the most relevant ones for me). It's easy to find all of the datasets that might be relevant. I used it to help me source the datasets I used in the other project I'm publishing today on removing CCP bias from and red-teaming kimi k2.5.
Check it out here! Preview below:
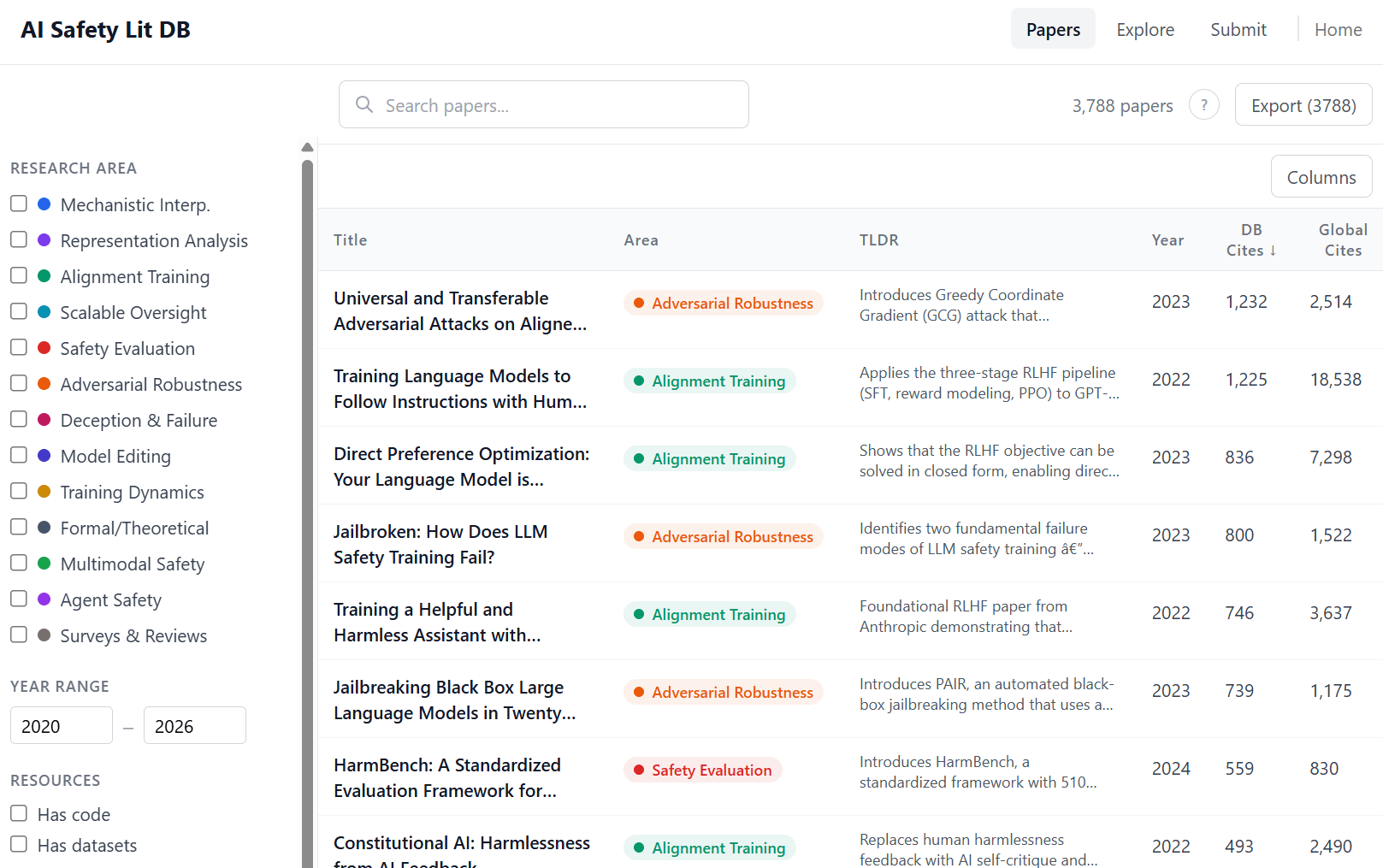
- ^
Obviously not all, I am certain I am missing some - especially from 2020 and 2021 since recency biased. But, if you think I am missing something it's easy to submit to be added!
- ^
Former quant trader, so relatively technical background - but definitely not a CS PhD
- ^
Just as an arbitrary example every MATS fellow is given 12k in compute, there are papers where much of that compute went straight into creating high quality datasets such as this truthfulness dataset
- ^
A mix of Sonnet 4.6 (~70%) and Opus 4.6 (~30%), I switched from Opus to Sonnet due to cost consideration once I had a better idea of just how many papers there would be.
- ^
I also had Claude score the papers on "Novelty", "Applicability", and "Compute Requirements". I wouldn't put too much stock into them. There's probably something interesting to be gleaned from what Claude thinks is novel, applicable, or compute-y in the world of AI safety, but this is not that post.
- ^
- ^
That's before we even talk about the papers that truly believe their research on year+ old models represents the current state of the game. To be clear I think work on smaller models is great, nothing against that - it just seems like academia frequently likes to pretend old models are cutting edge.
I appreciate you sharing this methodology as I am diving in to look at a slice of the AI governance/ AI safety space (current simple framing: AGI preparedness x human capability layer). I've been contemplating how to efficiently find what's out there -- likely looking for research, past and current projects, convenings, and grants.