Supported by Rethink Priorities
This is part of a weekly series summarizing the top posts on the EA and LW forums - you can see the full collection here. The first post includes some details on purpose and methodology. Feedback, thoughts, and corrections are welcomed.
If you'd like to receive these summaries via email, you can subscribe here.
Podcast version: Subscribe on your favorite podcast app by searching for 'EA Forum Podcast (Summaries)'. A big thanks to Coleman Snell for producing these!
Philosophy and Methodologies
Rethink Priorities’ Welfare Range Estimates
by Bob Fischer
The author builds off analysis in the rest of the Moral Weight Project Sequence to offer estimates of the ‘welfare range’ of 11 farmed species. A welfare range is the estimated difference between the most intensely positively valenced state (pleasure) and negatively valenced state (pain) that members of the species can experience relative to humans:
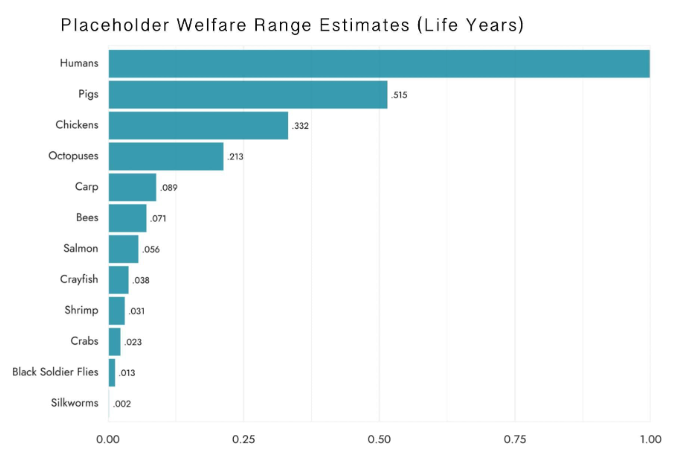
The estimates should be seen as best-available placeholders, a starting point for further empirically-driven research into welfare ranges.
Incorporating uncertainty, and conditional on hedonism and sentience, they make the following estimates:
- 70% credence that none of the vertebrate nonhuman animals of interest have a welfare range that’s more than double any others.
- 65% credence that the welfare ranges of humans and the other vertebrate animals of interest are within an order of magnitude of each other.
- 60% credence that the invertebrates of interest have welfare ranges within two orders of magnitude of the vertebrate animals of interest.
Existential Risk Modelling with Continuous-Time Markov Chains
by Mohammad Ismam Huda
Continuous-Time Markov Chains (CTMCs) are a popular tool used throughout industry (e.g. insurance, epidemiology) and academia to model multi-state systems. Advantages of the methodology for x-risk modeling include the ability to model multiple competing x-risks, incorporate things that modify and interact with x-risks but aren’t x-risks themselves (eg. 3°C warming scenario) and ability to assume x-risk probabilities vary with time.
The author discusses how CTMCs work, compares them to other approaches such as discrete markov chain models, and produces a model based off of Toby Ord’s probability estimates in The Precipice for demonstration.
Object Level Interventions / Reviews
AI
What a compute-centric framework says about AI takeoff speeds - draft report
by Tom_Davidson
Describes high level takeaways from the author’s draft report on AI takeoff speeds. The report builds heavily on the Bio Anchors report by Ajeya Cotra, with major changes including modeling a) increased investment in AI as AGI approaches / AI gains attention and b) AI starting to automate AI R&D tasks. Both accelerate timelines.
A ‘takeoff period’ is defined as the time between when AI can (not necessarily has) readily automate 20% of cognitive tasks, to when it can for 100% of cognitive tasks. The latter is defined as AGI. ‘Readily automate’ means it would be profitable and do-able within a year.
The author’s current probabilities, conditional on AGI by 2100, are:
~10% to a <3 month takeoff [this is especially non-robust]
~25% to a <1 year takeoff
~50% to a <3 year takeoff
~80% to a <10 year takeoff
If AGI is easier to develop, takeoff gets faster. The above assumes it takes 1e36 FLOP using 2020 algorithms, but you can play around with that input and others in this quantitative model of AGI timelines and takeoff speeds.
Takeaways from this model include that:
- Capabilities (able to automate) and impact (have automated) takeoff are separate ideas.
- Capabilities takeoff speed depends primarily on how much harder 100% AI is than 20% AI, in addition to if 20% AI can help on the way (and if other factors slow progress eg. reaching hardware limits).
- Only if 100% AI is very hard to develop vs. 20% AI could we get >10 year takeoffs. The model produces this for inputs of >=1e38 FLOP to train with 2020 algorithms (the conservative “long horizon” anchor in the Bio Anchors report).
- Once we have AGI, superintelligence is probably 1-12 months away, given it can do its own R&D.
- Impact takeoff will likely take much longer (in the case of aligned AGI):
- Caution, standard deployment lags, and political reasons (eg. not wanting to replace human workers) will slow deployment decisions.
- Impact takeoff might be faster for unaligned AGI, if it does a power grab.
- For a fixed AGI difficulty, slower takeoff means AGI happens earlier (because it suggests a bigger difficulty gap between AI able to accelerate AI progress, and AGI - so the former must happen sooner).
My highly personal skepticism braindump on existential risk from artificial intelligence.
by NunoSempere
The author views existential risk from AGI as important, but thinks something is going wrong in reasoning that concludes doom from AGI is certain or nearly certain. They give three reasons:
- Distrust of reasoning chains using fuzzy concepts (ie. in some arguments a lot of different things need to happen for AI x-risk to occur - some of which are fuzzily defined)
- Distrust of selection effects at the level of arguments (ie. more effort has gone into AI x-risk arguments, than into counter-arguments)
- Distrust of community dynamics (eg. people who move to the Bay Area often seem to update to higher AI risk, which might indicate social incentives)
NYT: Google will “recalibrate” the risk of releasing AI due to competition with OpenAI
by Michael Huang
Linkpost for this New York Times article. It reports that Sundar Pichai, CEO of Alphabet and Google, is trying to speed up the release of AI technology by taking on more risk eg. accelerating ethics approvals and “recalibrating” the allowable risk.
This is despite Demis Hassabis, CEO of subsidiary DeepMind, urging caution in his own interview with Time due to AI being “on the cusp” of tools that could be deeply damaging to human civilization.
Update to Samotsvety AGI timelines
by Misha_Yagudin, JonathanMann, NunoSempere
Samotsvety is a forecasting group. Aggregate results from their recent AGI timelines forecasting:
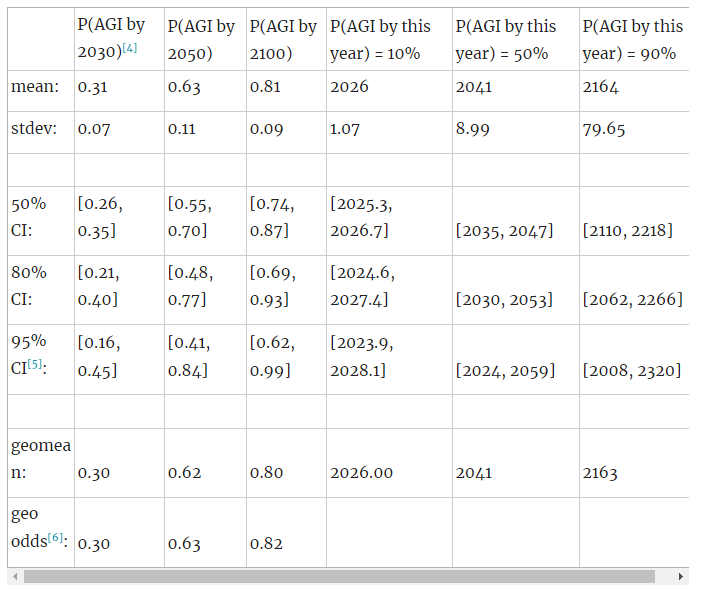
This is higher than the previous forecast 5 months ago, which predicted 32% for AGI by 2042, and 73% for AGI by 2100. The changes are attributable to more time to think through the topic, being guided by more direct considerations eg. how AI progress will look year-to-year (as opposed to priors like Laplace’s law), and spending significant time with state of the art systems.
Gradient hacking is extremely difficult
by beren
A gradient hacker is a malign subnetwork within a large network, which steers gradients away from minimizing outer loss and towards the gradient hacker’s own internal objective. The author argues that the technical details of gradient descent models which are supervised and trained on i.i.d data makes this extremely difficult when considering the ‘platonic ideal’ of such a model. For instance, everything is optimized simultaneously and independently. This and similar factors mean there is little ‘slack’ in the network for something to drive toward different goals in parallel. In practice though, there are vulnerabilities, eg. due to practices like gradient clipping (artificial ceilings on the magnitude of updates). This means that better optimization algorithms lead to both better capabilities and greater safety from mesaoptimizers like gradient hackers.
Large language models learn to represent the world
by gjm
Describes a paper where the authors trained a GPT model on lists of moves from Othello games, and showed via tweaking activations that it seemed to have learned to represent the board state internally and use this to decide legal moves. However, there are other interpretations of the outcomes, with one critique claiming the approach doesn’t tell us anything more than seeing it can play legal moves in general would tell us.
Alexander and Yudkowsky on AGI goals
by Scott Alexander, Eliezer Yudkowsky
Author’s tl;dr: Lightly edited transcript of a chatroom conversation between Scott Alexander and Eliezer Yudkowsky last year. Questions discussed include "How hard is it to get the right goals into AGI systems?" and "In what contexts do AI systems exhibit 'consequentialism'?".
Parameter Scaling Comes for RL, Maybe
by 1a3orn
Author’s tl;dr: Unlike language models or image classifiers, past reinforcement learning models did not reliably get better as they got bigger. Two DeepMind RL papers published in January 2023 nevertheless show that with the right techniques, scaling up RL model parameters can increase both total reward and sample-efficiency of RL agents -- and by a lot. Return-to-scale has been key for rendering language models powerful and economically valuable; it might also be key for RL, although many important questions remain unanswered.
Thoughts on the impact of RLHF research
by paulfchristiano
The author argues that Reinforcement Learning from Human Feedback (RLHF) is the simplest plausible alignment strategy, and while there are failure modes (eg. treacherous turns, trouble evaluating consequences in order to provide feedback), it’s unclear if these would become fatal before transformative AI is developed.
Arguments for working on RLHF center around its tractability on current models and ability to give us insights and learnings relevant to many approaches. Arguments against it center on its advancing capabilities (via making current AI systems more profitable) or distracting from more promising approaches / giving a false sense of security. The author is particularly excited about work that addresses important failure modes eg. training AI systems to give more correct answers in domains where human overseers can’t easily judge results.
Other Existential Risks
Call me, maybe? Hotlines and Global Catastrophic Risk [Founders Pledge]
by christian.r
Summary of a shallow investigation by Founders Pledge on direct communications links (DCLs or "hotlines") between states as global catastrophic risks interventions. These “hotlines” are intended to help leaders defuse the worst possible crises and to limit or terminate war (especially nuclear war) when it does break out. They are so far untested in these high-stakes applications.
The most important dyadic adversarial relationships (e.g., U.S.-China, U.S.-Russia, Pakistan-India, India-China) already have existing hotlines between them. Based on this, they suggest forming new hotlines is an unlikely candidate for effective philanthropy. However, other interventions in the space might be worthwhile if sequenced correctly. For instance: understanding whether they work, what political and institutional issues affect their function, why China does not “pick up” crisis communications channels in times of crisis, and improving hotline resilience to things such as nuclear war or electro-magnetic pulses.
Global Health and Development
Dean Karlan is now Chief Economist of USAID
by Henry Howard
Dean Karlan is a development economist who founded Innovations for Poverty Action (IPA) and is on the Executive Committee of Jameel Poverty Action Lab (J-PAL). IPA and J-PAL have been responsible for a lot of the research that underpins GiveWell's charity recommendations.
In November 2022, he was appointed as the Chief Economist of the United States Agency for International Development (USAID). USAID has the largest aid budget in the world - $29.4B for 2023. If he’s able to improve the cost-effectiveness of spending, we would see a huge impact.
Open Philanthropy Shallow Investigation: Tobacco Control
by Open Philanthropy
Smoking is responsible for ~8M deaths / ~173M DALYs yearly - roughly equivalent to the health damages of HIV/AIDS, tuberculosis, and malaria combined. ~75% of the burden is in low and middle income countries (LMICs), and while smoking rates are declining in most countries, population growth means that total burden is expected to stay constant or to rise.
There are many existing non-profits in the space, but some small countries may be relatively neglected. However, it can be expensive to get tobacco control policies passed in these countries, due to small public health departments and tobacco industry push-back.
The World Health Organisation (WHO) has a 6-pronged framework for reducing tobacco demand via policy, of which raising tobacco taxes seems the most effective. An alternative that is rarely funded by philanthropy is promoting the use of non-combustible tobacco products such as e-cigarettes for harm reduction - however the evidence for how this affects population-level smoking rates is mixed.
Pain relief: a shallow cause exploration
by Samuel Dupret, JoelMcGuire
Linkpost for Happier Lives Institute's report on pain relief - a 2-week exploration expanding on their previous work in the area, with a focus on the link between pain and subjective well being (SWB).
The limited literature in the area suggests:
- Those living with ‘extreme pain’ vs. ‘no pain’ rate their life satisfaction as 0.5-1.3 points lower on a 0-10 scale. Dividing by an implicit 0-10 pain scale (where ‘extreme’ = 10), the higher end of results gives a 0.12 decrease in life satisfaction per point of pain.
- Analysis of psychology-based therapies for chronic pain finds they reduce pain by 0.24 SDs and improve SWB by 0.26 SDs ie. approximately a 1 to 1, suggesting a 1-point decrease in pain could result in a 1-point increase in SWB.
The two methodologies producing such different results makes cost-effectiveness analysis uncertain - for instance, the authors’ calculations on advocacy for opioids is that it is 18x the cost-effectiveness of GiveDirectly (in terms of increasing SWB) if taking the estimate from the first bullet point, and 168x if taking the estimate from the second bullet point.
Overall, the authors’ believe that providing opiods for terminal pain and drugs for migraines are potentially cost-effective interventions. They suggest further research focus on narrowing the substantial uncertainty in conversion rate of pain to SWB, and investigating the potential of advocacy campaigns to increase access to opioids.
Opportunities
Save the date - EAGxWarsaw 2023
by Łukasz Grabowski
EAGxWarsaw will take place this June 9th - 11th - the first EAGx in Poland. Sign up to be notified when applications open.
Rationality & Life Advice
My thoughts on parenting and having an impactful career
by 80000_Hours, Michelle_Hutchinson
The author knew they wanted kids far before finding out about Effective Altruism, and always stuck to that decision. They share their experience with both parenting and working for organisations whose mission they care about deeply. This includes how it has and hasn’t affected their career and impact, considerations to keep in mind, and particular things that were easier or harder because of EA.
Questions I ask myself when making decisions (or communicating)
by Catherine Low
When making decisions, the author asks themselves:
- Is this really where the tradeoff bites? Sometimes we assume two things are a trade-off, but there’s options that improve both, or improve one without loss to the other.
- What does my shoulder X think? And for high impact decisions, ask relevant stakeholders directly.
- What incentives am I creating? What seems like a one-off decision may create a norm.
- Can (and should) this wait a bit?
- Are emotions telling me something? Feelings are data - vague unease can point at a non-fully-articulated consideration.
- Do I stand by this? Deep down, does it feel like the right decision?
Basics of Rationalist Discourse
by Duncan_Sabien
11 guidelines for rationalist discourse, intended to be straightforward and uncontroversial:
- Expect good discourse to require energy.
- Don't say straightforwardly false things.
- Track (for yourself) and distinguish (for others) your inferences from your observations.
- Estimate and make clear your rough level of confidence in your assertions.
- Make your claims clear, explicit, and falsifiable, or explicitly acknowledge if you aren't.
- Aim for convergence on truth, and behave as if your interlocutors are also doing so.
- Don't jump to conclusions - keep multiple hypotheses that are consistent with current info.
- Be careful with extrapolation, interpretation, and summary/restatement—distinguish between what was actually said, and what it sounds like/what it implies/what you think it looks like in practice/what it's tantamount to.
- Allow people to restate, clarify, retract, and redraft their points, if they ask to.
- Don't weaponize equivocation/don't abuse categories/don't engage in motte-and-bailey.
- Hold yourself to the absolute highest standard when directly modeling or assessing others' internal states, values, and thought processes.
The post includes more detail on each.
Sapir-Whorf for Rationalists
by Duncan_Sabien
The author has or is planning to write many posts on concepts they’d like to reify (describe and name) eg. cup-stacking skills, sazen, setting the zero point. This post discusses why having names for new concepts is useful in general:
- It usually happens by default - humans name things.
- If two concepts are separated in language, it’s easier to separate them in our minds too.
- If a concept isn’t put into language, it’ll be lost / harder to pay attention to.
- Describing and naming new concepts is one of the most productive frontiers of human rationality eg. The Sequences largely focus on this.
Have worries about EA? Want to chat?
by Catherine Low
Catherine works on CEA’s Community Health and Special Projects team. You can contact them via email, or the whole team via this form, if you want to share any EA-related worries or frustrations (specific or vague are both fine). They also read through all the community-related posts and comments on the forum.
They share that they’re currently feeling disappointed, worried, frustrated, and a bit angry about a few things they’ve read on the forum. They find it helpful to remember that a particular EA space like this forum isn’t equivalent to EA itself, and that other spaces can feel much better - like in-person meetings or video calls. It’s also okay to take a step back for a bit.
Celebrating EAGxLatAm and EAGxIndia
by OllieBase
In January, we had the first EA conferences to take place in Latin America and India: EAGxLatAm in Mexico City and EAGxIndia in Jaipur, Rajasthan.
The events attracted 163 and 200+ attendees respectively. EAGxLatAm received the highest “likelihood to recommend” score of any EAG event in 2022 (9.07/10) and EAGxIndia attendees made the most average new connections of any EAG or EAGx to date (12.36). Given this success, CEA is even more excited about supporting events outside of EA hubs and particularly in Low and Middle Income Countries. You can read more about who attended the events, the types of talks, and testimonials in the post.
My Model Of EA Burnout
by LoganStrohl
“EA burnout usually results from prolonged dedication to satisfying the values you think you should have, while neglecting the values you actually have.”
The author argues most EAs probably have some overlap with EA values, but dramatically overestimate how much. The values that don’t help them achieve EA goals aren’t acted on, and because values are motivation, they lose motivation. For instance, you might value comfort and excitement, but turn down time watching TV under a blanket or rock climbing because they distract you from where you can have an impact. They suggest recognizing your true values, acting on them frequently, and using the excess motivation that builds to put towards impact.
Native English speaker EAs: could you please speak slower?
by Luca Parodi
If you are a native English speaker interacting with a non-native speaker, try to:
- Slow the pace of your speaking.
- Avoid using too many metaphors, analogies, and extremely technical words.
- Understand and reinforce to yourself that if the person you’re speaking to isn’t understanding or needs things repeated, it’s not because they’re slow or stupid.
- Reduce references to your country’s politics, pop culture, or inside jokes.
- Don’t say “You’re doing great! Your English is super good” - It can come across as condescending.
Summit on Existential Security 2023
by Amy Labenz, Sophie Thomson
An invite-only event for professionals working towards existential security. CEA is sharing details for transparency and feedback. The primary goal of the summit is facilitating conversation to make progress on crucial topics (particularly those cutting across multiple areas / research agendas), with a secondary goal of building community.
Overview of effective giving organisations
by SjirH
Links to a spreadsheet overviewing 55 effective giving organisations. Intended to contain all organisations / projects that either a) identify publicly accessible philanthropic funding opportunities using EA-inspired methodology, and/or b) fundraise for those opportunities already identified.
Moving Toward More Concrete Proposals for Reform
by Jason
The author has found high-level discussion of reform generally unhelpful, because it’s too easy for proponents to gloss over implementation costs and downsides, and for skeptics to attack strawmen. They suggest commissioning 12-18 hour investigations into some of these reform ideas, to flesh them out and tackle these issues. Ideally, this would be funded by interested ‘rank-and-file’ EAs, and not existing major donors, to avoid (actual or appearance of) conflicts of interest. If this project was a success in advancing the conversation into actionable territory, the next step might be to establish a small community-funded and community-run grantmaker focused on reform-minded efforts.
When Did EA Start?
by Jeff Kaufman
The EA movement (as opposed to ideas) didn’t exist in 2008, and did in 2012. Important events along the way included:
- December 2006: first GiveWell blog post comes out. Early writings like this had EA ideas, but the ideas hadn’t started gathering many people yet.
- 2009: discussion on the Felicifia forum included threads on charity choice and applied ethics. In November, the first 30 people also joined Giving What We Can.
- December 2010: Roko Mijic ran a contest on LessWrong for the best explanation of EA.
- November 2011: 80,000 hours launched.
Some EA organizations were founded in this period or earlier, but only became EA over time.
Special Mentions
A selection of posts that don’t meet the karma threshold, but seem important or undervalued.
Literature review of Transformative Artificial Intelligence timelines
by Jaime Sevilla
Epoch produced a summary of influential models and forecasts predicting when transformative AI will be developed:
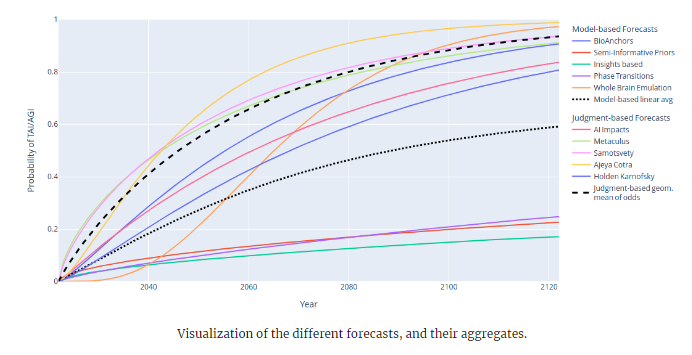
They also subjectively weighted the models, with BioAnchors and Semi-Informative Priors rated highest.
New research findings on narrative in U.S. animal advocacy
by Aidan Kankyoku
Pax Fauna recently completed an 18-month study on messaging around accelerating away from animal farming in the US. The study involved literature reviews, interviews with meat eaters, and focus groups and online surveys to test messaging.
They found that most advocacy focuses on the animal, human health, and environmental harms of animal farming. However the biggest barrier to action for many people tended to be “futility” - the feeling that their actions didn’t matter, because even if they changed, the world wouldn’t.
Based on this, they suggest reframing messaging to focus on how we as a society / species are always evolving and progressing forwards, and that evolving beyond animal farming is something we can do, should do, and already are doing. They also suggest refocusing strategy around this - eg. focusing on advocacy for pro-animal policies, as opposed to asking consumers to make individual changes to their food choices.
