“If you cannot measure it, you cannot improve it.” – Lord Kelvin (paraphrased)
Website: benchmarking.mlsafety.org – receiving submissions until August 2023.
ML Safety lacks good benchmarks, so the Center for AI Safety is offering $50,000 - $100,000 prizes for benchmark ideas (or full research papers). We will award at least $100,000 total and up to $500,000 depending on the quality of submissions.
What kinds of ideas are you looking for?
Ultimately, we will are looking for benchmark ideas that motivate or advance research that reduces existential risks from AI. To provide more guidance, we’ve outlined four research categories along with example ideas.
- Alignment: building models that represent and safely optimize difficult-to-specify human values.
- Monitoring: discovering unintended model functionality.
- Robustness: designing systems to be reliable in the face of adversaries and highly unusual situations.
- Safety Applications: using ML to address broader risks related to how ML systems are handled (e.g. for cybersecurity or forecasting).
See Open Problems in AI X-Risk [PAIS #5] for example research directions in these categories and their relation to existential risk.
What are the requirements for submissions?
Datasets or implementations are not necessary, though empirical testing can make it easier for the judges to evaluate your idea. All that is required is a brief write-up (guidelines here). How the write-up is formatted isn’t very important as long as it effectively pitches the benchmark and concretely explains how it would be implemented. If you don’t have prior experience designing benchmarks, we recommend reading this document for generic tips.
Who are the judges?
Dan Hendrycks, Paul Christiano, and Collin Burns.
If you have questions, they might be answered on the website, or you can post them here. We would also greatly appreciate it if you helped to spread the word about this opportunity.
Thanks to Sidney Hough and Kevin Liu for helping to make this happen and to Collin Burns and Akash Wasil for feedback on the website. This project is supported by the Future Fund regranting program.
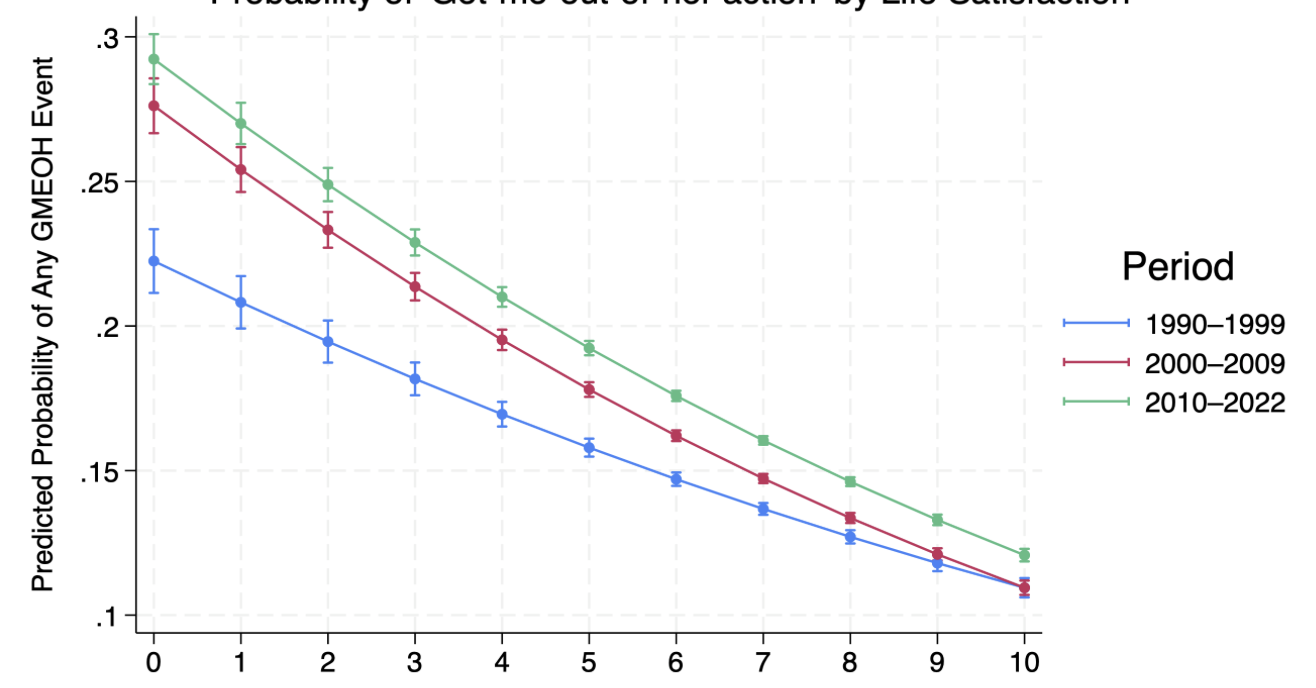
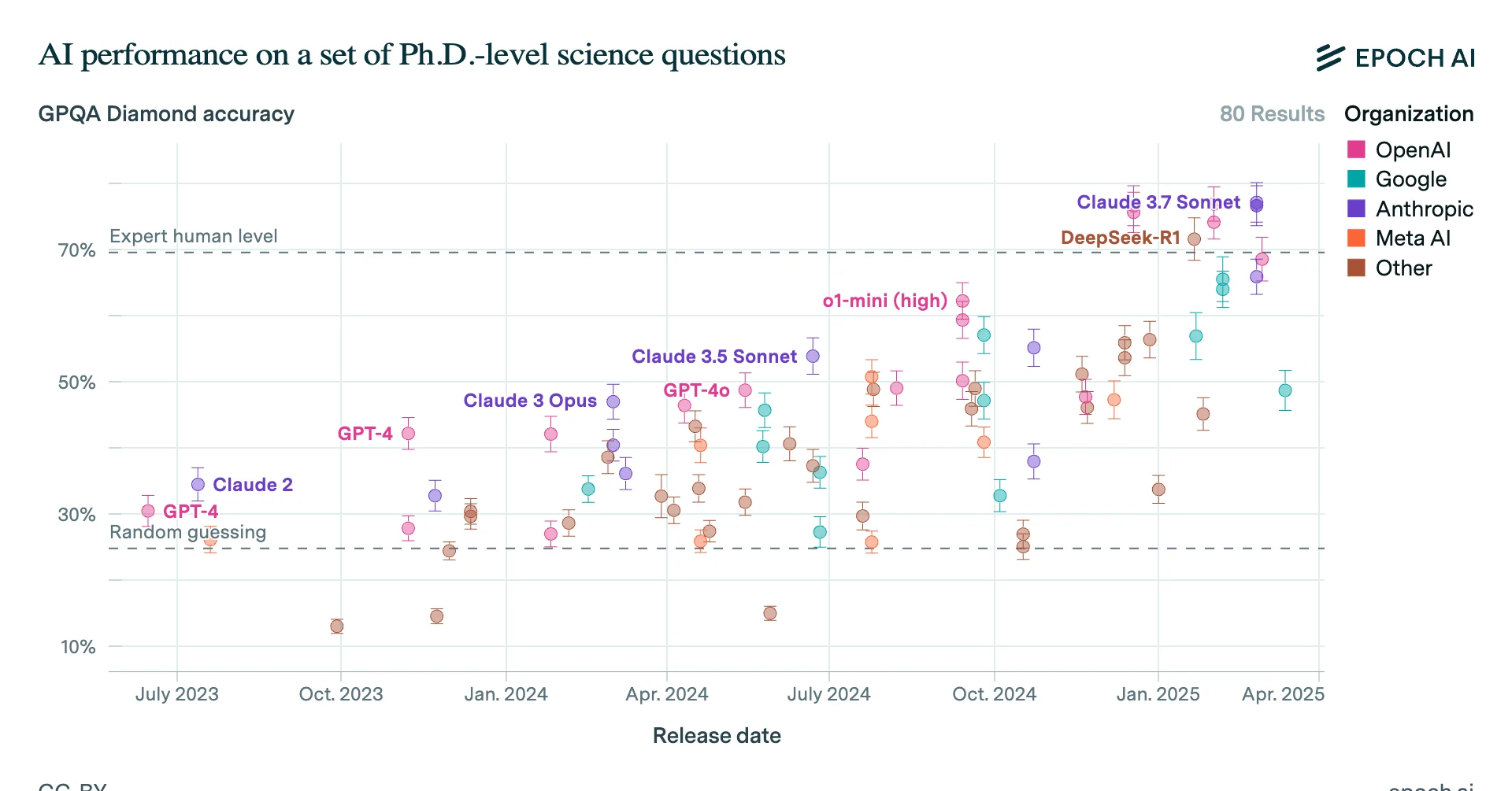
Is the competition still open? The website is down.
Thank you for the update!
It might also be a good idea to tag the competition as closed on all the relevant forums.