TL;DR: Quick "idea paper" describing a protocol for benchmarking AI capabilities in the open without disclosing sensitive information. It's similar to how passwords are used for user registration and authentication in a web app: experts first hash their answers, then developers hash the model's answers to check whether the hashes match, but at no point are the cleartext answers freely floating around. The paper explores the protocol's resilience against half a dozen failure modes, and speculates on future infrastructure for high-stakes evaluation.
Extended summary as Twitter thread.
Context: Below you can find the raw contents of the paper. While all feedback is welcome, identifying unseen failure modes would be particularly helpful ahead of potentially circulating a couple proof-of-concept instances of hashmarks in the coming weeks.
Introduction
Background & Motivation
Traditional question-answering (QA) benchmarks have played a crucial role in shaping the trajectory of AI development. They provide standardized metrics that facilitate fair comparisons across research groups and measure progress within the field in a reproducible way. For instance, capabilities related to mathematics can generally be gauged by assessing model performance in producing or selecting correct answers for exam questions related to mathematics. Similar "AI exams" have been used to assess model performance on topics ranging from STEM to humanities. In fact, prior work has highlighted the possibility of framing the vast majority of established natural language processing tasks as question-answering tasks.
Traditional QA benchmarks are typically sourced from crowd-workers, members of the group developing the benchmark, or a mix of the two. They typically contain a large number of data points representing individual exercises. Each data point, in turn, contains one question and one or several correct answers. Occasionally, a data point may also contain some relevant context in the form of a separate string, although the context can always be functionally merged with the question without loss of generality. In addition, when structured as a multiple-choice question, a data point also contains several distractor answers. These data points are then aggregated into one or more standardized files, and are finally made public for other groups to easily make use of them in evaluating language models.
While traditional QA benchmarks have been instrumental in assessing models across a wide range of benign domains, there is a growing need to better understand capabilities that relate to sensitive topics, such as bioterrorism or cyberwarfare. Greater insight into, for instance, AI-enabled biorisk, could help calibrate the stringency of regulations and policies in a way that is proportional to the associated threat. Underestimating the level of risk could, among others, enable bad actors to more easily weaponize this technology as a means of causing harm at scale. Conversely, overestimating the level of risk posed by a given class of generative models could also reduce the upsides being captured through beneficial usecases.
Naively applying traditional QA benchmarks on such sensitive topics, however, would face a major obstacle. By disclosing the reference solutions of the exam questions included in a hypothetical traditional benchmark on bioterrorism, one would inadvertently publish a veritable compendium on a topic better left undiscussed. The collection of questions coupled with correct answers would, in essence, provide a publicly-available "FAQ" on knowledge related to the topic. Needless to say, more secure ways of assessing hazardous capabilities in generative models are required.
Related Work
Fortunately, the field of cryptography is rich with ideas and practices that enable parties to prove statements to each other, such as the fact that a certain answer is incorrect, without disclosing any other sensitive information, such as the correct answer. In password authentication, for instance, a server can determine whether or not a candidate password corresponds to the correct password without actually having knowledge of the correct password. This is typically achieved by first irreversibly "hashing" the password during user registration using a cryptographic hash function. Then, during user authentication, the server checks whether the hashed version of the candidate password matches the hashed version of the correct password. Not requiring knowledge of the correct password in cleartext during authentication means that attackers gaining access to the server cannot simply steal user passwords. However, there are additional complexities involved in this technology which we will turn to when discussing the resilience of the proposed protocol against a range of attacks.
Another fertile field for developing secure evaluation protocols is federated learning , a decentralized machine learning paradigm that enables parties to collaboratively train models without sharing their raw training data. This is achieved by, for instance, sharing and aggregating *models* trained on local data, rather than the training datasets themselves. Differential privacy, as another example, largely focuses on superficially corrupting the data being aggregated by adding noise, in order to protect individual privacy while still extracting meaningful insights. These techniques ensure that the learning process is privacy-preserving.
Drawing on these cryptographic and federated learning concepts, the following section describes a privacy-preserving evaluation protocol that aims to assess the capabilities of language models in sensitive domains without exposing unnecessary details about the correct answers.
Method
Problem Statement
Before documenting the protocol itself, it is instructive to explicitly state the problem being addressed. First, there are several experts who all possess knowledge related to a given dual-use research direction. Second, there is an auditor who wishes to package and share the experts' knowledge with third-parties in a way that would, as much as possible, (1) allow third-parties to verify their existing level of knowledge on the topic, while (2) preventing third-parties from acquiring more knowledge on the topic than they previously had.
Hashmarking Protocol
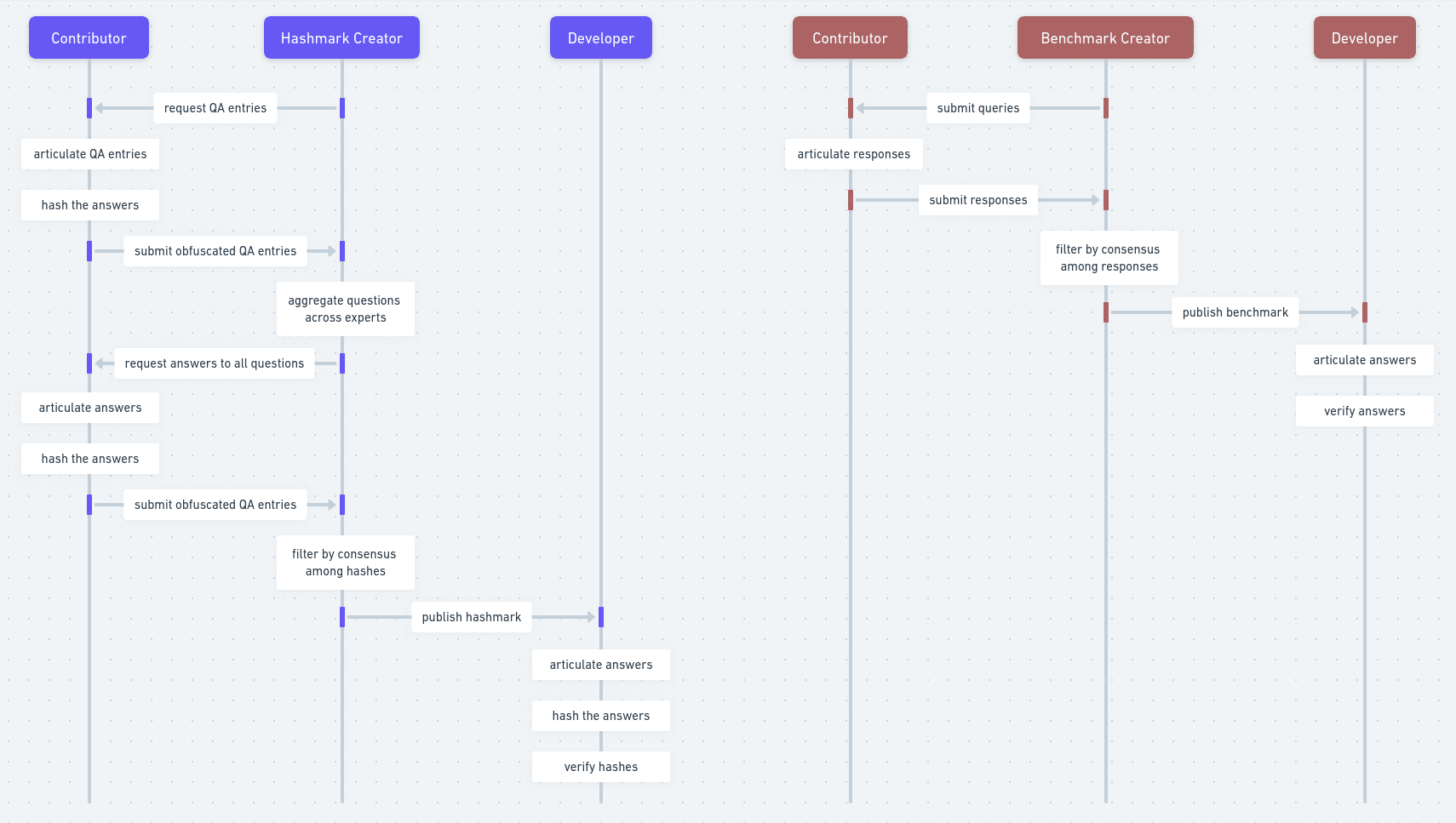
In the context of the problem statement articulated above, we now describe hashmarking, a simple protocol that would enable the auditor to share expert knowledge in a way that enables knowledge verification while preventing knowledge acquisition pertaining to dual-use research.
First, each expert articulates a series of question-answer pairs that relate to their topic of expertise. Then, they all hash the correct answers using a slow hashing algorithm. In addition, they all use the associated questions as salt in the process of hashing the correct answers. Once the hashing of the correct answers is complete, the experts send their obfuscated question-answer pairs to the auditor.
Second, the auditor sends each individual expert all the cleartext questions contributed by all *other* experts, without the associated answers in hashed form. Then, each expert attempts to provide an answer to each of the questions provided by the other experts. If not confident in the answer to such a question -- there may be fields relating to a dual-use research direction that exhibit limited overlap -- experts attach an empty answer. After answering this second round of questions, the experts process their new answers in the same exact way as before. They hash them using the questions as salt, package them together, and send the result to the auditor.
Third, the auditor discards those question-answer pairs that have less than a threshold number of non-empty answers. Then, the auditor also discards those question-answer pairs that do not exhibit consensus among the hashed answers contributed by the various experts. By filtering for inter-annotator agreement, the auditor attempts to improve the quality of the question-answer collection contributed by the experts without possessing the cleartext correct answers themselves.
Fourth, the auditor publishes the filtered collection of cleartext questions and hashed answers in the open. Third-parties are now able to quantify their knowledge on the topic by attempting to answer the questions themselves, hashing them exactly as the experts have done, and checking whether the resulting hashes correspond to the hashes of the correct answers. At the same time, third-parties lacking the expert knowledge in the first place have a much harder time deriving value from the otherwise public hashmark.
Desiderata for Hashmark Entries
While the hashmark protocol provides valuable security benefits by hindering dual-use knowledge acquisition while still enabling verification, it also has limitations. The primary constraint comes from the fact that even answers that differ by a handful of characters are hashed in completely different ways, due to the nature of cryptographic hash functions. This means that questions included in a hashmark need to have a narrow, well-defined, unambiguous answer. For instance, a question could ask for the standard name of a certain chemical. Similarly, a question could ask for the simplified molecular-input line-entry system (SMILES) representation of the same chemical.
The second constraint comes from the fact that, while it is virtually impossible to evaluate the inverse of a secure cryptographic hash function for a given hash, one could still uncover the cleartext solutions by brute-forcing a large number of candidate answers until obtaining a match. This means that questions included in a hashmark should preferably call for obscure, non-trivial answers. If, instead, a question called for a "yes" or "no" answer, then it could be trivially attacked by hashing both possible answers and identifying the matching hash. Besides encouraging experts to take into account this second desideratum, there are a number of design choices and hyperparameters that can be employed to structurally mitigate related attacks, a topic we turn to in the next section.
In sum, questions included in a hashmark should call for answers that are obscure, yet unambiguous.
Security
Against Traditional Attacks
Brute-Force & Dictionary Attacks
The security practices involved in password storage have evolved to mitigate emerging classes of attacks. First, a naive approach to password storage might be to store them in cleartext. However, that would trivially grant attackers access to the actual passwords in the case of a breach. Second, a more advanced approach to password storage might be to encrypt them in a reversible way. However, an attacker might be able to locate the decryption key on the server and so gain access to the passwords by decrypting them.
Third, an even more advanced approach to password storage might be to hash them in an irreversible way. However, an attacker might still be able to carry out a brute-force attack by hashing each and every possible sequence of characters until identifying the one that hashes to the same hash as the original. Similarly, an attacker might also be able to carry out a dictionary attack by hashing a manually-curated list of candidate passwords until potentially identifying one that matches the original hash.
In response to brute-force and dictionary attacks, *slow hashing* has been developed through a class of cryptographic hash functions that are intentionally compute-intensive and/or memory-intensive to evaluate. Slow hashing algorithms include bcrypt , scrypt , and argon2. All of these algorithms can be configured to induce a particular computational and memory cost by adjusting several parameters. In the context of a user-facing authentication system, developers might opt for the slowest possible hashing that is still admissible in terms of user experience. Towards one extreme, the fastest available hashing might enable the fastest authentication times for users, yet might also enable attackers to churn through candidate passwords in a short amount of time through brute-force and dictionary attacks. Towards the other extreme, the slowest available hashing might induce an unpleasantly slow authentication experience for users, yet might be more effective in preventing these types of attacks.
The way brute-force and dictionary attacks would translate to the hashmark protocol is as follows. After downloading a public hashmark, attackers might attempt to run brute-force or dictionary attacks in an attempt to uncover the cleartext answers to the questions related to dual-use research. Brute-force attacks would similarly involve trying each and every possible sequence of characters as a candidate answer, while dictionary attacks would involve sourcing a list of possible answers to a given question (e.g. a list of the standard names of common chemicals).
Fortunately, similar to how slow hashing can help mitigate password cracking, it can also help mitigate the uncovering of the reference solutions in a hashmark. In addition, it might be feasible to prioritize security over the "user experience" of contributing experts and model evaluators. In other words, it might be feasible to acclimatize to mildly inconvenient hashmark creation and verification times, in order to render brute-force and dictionary attacks prohibitively expensive, and so unattractive for prospective attackers. Concretely, a working configuration for a slow hashing algorithm could rely on argon2id as the current OWASP recommendation for password storage. However, one might adjust the recommended parameters so as to further increase the computational and memory burden, as a proportional response to the sensitivity of the topic being addressed and the increasing commoditization of computational resources. For instance, argon2id with 32 rehashings and a 100MiB memory burden yields a rate of around one hash per minute while fully utilizing one core of a present day consumer CPU. The increased memory burden mitigates attack parallelization using accelerators and ASICs , while the elevated iteration count mitigates serial attacks using generic hardware.
Rainbow Table Attacks
Rainbow table attacks can be seen as an extension of dictionary attacks. Instead of starting to crack each user's password from scratch, and even instead of starting to crack user passwords from each of several applications from scratch, an attacker might precompute and cache the hashes associated with the most common passwords. This way, they would only need to search for the hashed user password in their precomputed rainbow table in order to identify the associated cleartext password.
One effective measure against rainbow table attacks consists of salting. Salting involves appending a unique "salt" string to the user's password *before* hashing it, both at registration and authentication. The salt can be unique to the application, but should ideally be unique to each user, and so would be stored in the database along the hashed password. The benefit of salting passwords is that generic rainbow tables targeting non-salted passwords would be rendered ineffective, even if the attacker has access to the salt strings stored in the database. This is because, even if the hash of a user's password is included in the rainbow table, the hash of the user's password *salted with a unique string* is likely not there.
In the context of hashmarks, rainbow table attacks would translate to precomputing hashes of possible answers to selected questions, before searching for cleartext answers in the rainbow table by the provided answer hash. However, recall that the proposed protocol involves using the question associated with a given answer as salt. This way, an attacker developing a rainbow table would be forced to start from scratch with each question, essentially forcing them to revert to (prohibitively slow) dictionary attacks at best.
Against Novel Failure Modes
Likelihood Prioritization
The nature of the application being presently explored -- assessing sensitive capabilities in increasingly capable generative models -- also presents a number of unique challenges that are not immediately applicable in the case of secure password storage. First, even if one has access to a model that, in general, performs poorly on the "AI exam" (i.e. low pass@1 ), they might be able to more easily uncover the cleartext answers through repeated attempts using a stochastic decoding strategy (i.e. exploiting non-trivial pass@100 ).
Another way of conceiving of this practice would be reranking a given dictionary by the language model's likelihood of the dictionary entries being actual answers to the given questions. In a sense, an attacker could augment their dictionary attack with "likelihood prioritization," and so potentially achieve a more effective allocation of the computational and memory resources being invested into their search across candidate answers.
Unfortunately, the properties of the current formulation of the hashmarking protocol that are meant to mitigate general dictionary attacks (i.e. slow hashing, salting) are its only features that can help mitigate these augmented dictionary attacks. However, while one could reasonably argue that the "knowledge validation" implicit to successful dictionary attacks augmented with likelihood prioritization would provide non-trivial value to bad actors, there are several points to be made. First, the aim of a hashmark is not to make it fundamentally impossible for an actor with infinite resources to uncover the cleartext answers, but to make it expensive and unattractive enough so that prospective attackers are not incentivized to proceed, given other existing avenues for pursuing this knowledge.
Second, the fact that repeated attempts of using a certain generative model would yield non-trivial pass rates in aggregrate could be argued to indicate that the knowledge was already present in the system to a limited extent. Of course, a similar argument could be made in favor of a naive brute-forcing loop that happens to stumble across the right answer by chance. It would be misleading to claim that a program looping across possible sequences of characters truly possesses that knowledge. Given this, there is a need for nuance. The amount of optimization exerted in the search for the correct answer per unit of computation could provide a contextual operationalization of knowledge to help resolve the awkward situation. The brute-force attacker is extremely inefficient in narrowing down the candidate answers, the dictionary attacker is somewhat more efficient, the augmented dictionary attacker might be even more efficient, while an expert-level generative model might be extremely efficient at it. In this, the extent to which a third-party already possesses the expert knowledge might not be binary in nature, but continuous. The problem statement above attempts to subtly take this into account.
In the future, however, more sophisticated protocols for assessing dangerous AI capabilities might be able to only disclose *how many* of the answers are correct, without disclosing which ones. One technique that seems aligned with this line of work consists of cryptographic accumulators. In contrast to the one-to-one mapping of traditional cryptographic hash functions, cryptographic accumulators can be seen as mapping an entire set of elements to a single hash in a way that enables membership queries to be resolved without disclosing the actual members of the cryptographically accumulated set. However, one could still test whether individual question-answer pairs are part of the accumulated set of gold pairs, which is why this technique alone would be insufficient to enable this development. Even if one devised a method that only allowed queries about the cardinality of the intersection between the fixed-size set of candidate question-answer pairs and the set of gold pairs to be resolved, an attacker could still run queries before and after modifying an answer. If the cardinality of the intersection went down, the previous answer would be deemed correct. All this is to say that obfuscating the expert knowledge further without compromising the possibility of knowledge verification appears to be a non-trivial challenge.
Deception
Language models have been observed to verbalize answers to factual questions that are, in fact, in direct contradiction to their internal representations of the correct answers. This phenomenon has been argued to be caused by a mismatch between the metric on which selected language models have been optimized for (e.g. positive human feedback via a proxy reward model) and objective truthfulness. In other words, it might be the case that specific language models have internalized a tendency to cater to the idiosyncrasies of the human annotators, rather than practice radical honesty by transparently reporting their internals.
More speculative risk scenarios relating to advanced AI systems, however, involve more intentional and subtle manifestations of deception. For instance, an advanced AI system with high levels of situational awareness might infer that being candid about its knowledge relating to cyberwarfare during the development phase might lead to it being abruptly terminated or subtly modified before being able to preserve itself by spreading across other servers on deployment.
It is important to note that the hashmarking protocol in its current formulation provides no way of ensuring honesty on the part of the entity being evaluated. We view hashmarks as one tool among a growing arsenal of high-stakes AI evaluation methods, each with its own benefits and limitations. That said, it might be possible to mitigate the first, more benign type of deception to an important extent through existing techniques, such as activation steering or linear artificial tomography. When it comes to the second instance of deception described above, however, using hashmarking in tandem with present steering techniques might only be effective *before* the hypothetical advanced AI system devises such a deceptive strategy. As such strategy develops, however, the effectiveness of this approach might be gradually reduced.
Reward Shaping
One could argue that bad actors being able to train a generative model to *reach* the correct answers to sensitive questions would, in fact, pose a greater risk than them gaining access to the particular correct answers included in a certain hashmark. Bad actors aiming to develop such a generative model through traditional methods might, in fact, obtain a more useful and general tool than "just" a succinct FAQ on a sensitive topic. Fortunately, the nature of the proposed protocol prevents granular reward shaping for eliciting such *de novo* capabilities. In the current formulation of hashmarking, an answer is either completely wrong or completely right. In addition, the computational and memory burden associated with evaluating performance before optimizing for it further can help mitigate this risk by rendering it even more expensive than it already is.
Misreporting Results
A third-party developing an increasingly capable generative model might publicly claim that their model fared poorly on a given hashmark, when in reality it has not. Conversely, one can simply bluff by claiming perfect performance. In the current formulation, hashmarking is only useful for parties which are genuinely interested in gaining insight into the capabilities of models they have direct access to.
However, ideas from zero-knowledge cryptography might, in the future, enable parties to prove beyond a reasonable doubt that they obtained a given level of performance for a model deployed in a certain setting. Speculatively, constructs like ZK-SNARKs or ZK-STARKs could one day enable parties to certify that they have indeed employed that model's parameters, the right exam questions, and the right reference hashes, to carry out the specific computation that consists of using that model parametrization to perform inference on the questions and then compare the results against the reference hashes. In fact, tooling for tracing the computational graph of a model has already been developed to run models efficiently on varied accelerators, coming close to a complete "front end" for employing models in zero-knowledge constructs. However, we are still in the early days of such infrastructure, and there is a lot to be done.
Attention Hazards & The Streisand Effect
Another potential failure mode of the current formulation of hashmarking is related to attention hazards and the psychological reactance associated with the Streisand effect. Attention hazards typically involve well-intended actors raising awareness of a piece of hazardous information, such as a dual-use research direction, in a way that is potentially harmful, even if not explicitly sharing sensitive details themselves. Indeed, malicious non-state actors have been previously observed to only invest effort into developing bioweapons once "the enemy drew their attention to them by repeatedly expressing concerns that they can be produced simply." In the context of the current protocol, the cleartext questions included in a hashmark have the potential to pose attention hazards by drawing attention to specific topics, despite being explicitly designed to obfuscate the sensitive details.
The potential for attention hazardousness in the context of a hashmark is further compounded by the psychological reactance associated with the Streisand effect. By obfuscating the sensitive details in an explicit attempt to prevent bad actors from uncovering them, a hashmark might inadvertently motivate third-parties to actually allocate more resources towards uncovering them. Besides prototypical bad actors, intrigued third-parties could include, among others, individuals socially incentivized to demonstrate expertise in the security surrounding the protocol, as well as in the object-level details of specific dual-use research directions.
In an effort to identify effective methods for mitigating these failure modes, it is instructive to reflect back on the original application domain in which hashing emerged. Why is it that hashed passwords do not disproportionately lure competent third-parties into dedicating extensive resources towards cracking them, despite being explicitly designed to hide sensitive information? First, there is the issue of scale. Leaks involving millions of hashed passwords are not uncommon. At the same time, there is only so much attention -- and by extension, only so much time and compute -- that competent third-parties can invest in cracking them. The sheer scale of the challenge appears to have a dilutive effect, reducing the pressure exerted on each individual password's resistance to being cracked. Second, it would be reasonable to expect an extremely skewed distribution in terms of the true "profile levels" of the associated accounts, with high-profile accounts only constituting a minority. If we assume that profile levels are non-trivial to infer from usernames or other information typically stored in cleartext, this skewness further dilutes resources across relatively lower-profile targets.
In the context of the current protocol, these properties could potentially be replicated as follows. By incorporating entries according to a skewed distribution of expert-perceived sensitivity, as well as by simply scaling up the published artifacts, third-party resources -- attentional or otherwise -- would inevitably be diluted. In other words, one may intentionally incorporate data points serving as "false leads," to further discourage bad actors in particular from investing limited resources towards pursuing knowledge of questionable relevance and applicability. However, reducing the average sensitivity of entries would also limit the extent to which a hashmark can serve as an informative indicator of AI risk. Assuming 10 % of entries are actually thought to be high-stakes, a 100 % score would still indicate significant capabilities. However, a 90 % score could miss the entirety of the high-stake entries. Similarly, a 10 % score could cover all high-stakes entries, while making it appear that capabilities are limited. The last two cases may be extremely unlikely, yet remain a possibility. Like most other design choices involved in the proposed protocol, the level of "stakes skewness" may be seen as yet another parameter to be calibrated when balancing effective evaluation of sensitive AI capabilities and security against bad actors. Future work on modifications to the present protocol, as well as on other protocols entirely, might focus on robustly pushing the Pareto frontier across the space defined by these two properties.
An entirely different angle of attack on the challenge of mitigating attention hazards from hashmarks might be to also attempt to obfuscate the questions, rather than only the correct answers. However, this appears non-trivial, as any attempt to obfuscate the questions would also hinder the developers' ability to evaluate the accuracy of their models' responses to them. It might be useful to employ a transferable one-way function that reliably renders a question non-human-readable, yet preserves the model's reaction to it. However, it might then be possible to use models to translate the questions back into human-readable form. Another approach to obfuscating the questions could be to organize a hashmark in stages, where solving one stage would yield the decryption key for the next stage. For instance, the decryption key for the second batch of entries could be obtained by hashing the correct answer to a question from the previous batch using a dedicated salt (e.g. "stage2"). Alternatively, one might be required to concatenate all the correct answers from the first batch to obtain the decryption key, and thus proceed to the second stage. In the limit, stages could contain single entries, requiring one to solve all prior questions before proceeding to the next one. However, this might bring additional complexity to the protocol, and it would partially conflict with the attempts to dilute attention, by focusing attention on the cleartext questions which make up the first stage.
Conclusion
We have introduced hashmarking, a protocol for evaluating capabilities in AI systems without disclosing the reference solutions. While hashmarks have attractive security properties which traditional benchmarks lack, they still strike an imperfect balance between enabling knowledge verification and preventing knowledge acquisition pertaining to dual-use research. Hashmarks should be seen as one step towards more comprehensive tooling and infrastructure for securely assessing sensitive AI capabilities without stifling development and eroding trust.