calebp
Posts 33
Comments500
Topic contributions6
It doesn't appeal to me because I want higher info density, and this reduces it - I could see others liking it .
It's not obvious to me that you can't just hide low karma posts as an option - some options:
1. All first-time posts are reviewed by the forum team, who can upvote things and put them above the threshold
2. Make the low karma/low user karma post hiding disabled by default
3. Try out an option for a bit and remove it if it's not working well
@EA Forum Team
I made a small edit and saw that my post was flagged for LM usage. The post (to me) doesn't sound very LM-generated - but I do find it more difficult to assess my own writing than other people's, so I ran it through pangram which seems to think it's 100% human generated.
From quickly skimming your LLM usage policy, it looks like you're also using Pangram, which is a bit confusing. Maybe you have a bug, or are using a different version to me? Or am I using Pangram incorrectly or suboptimally?

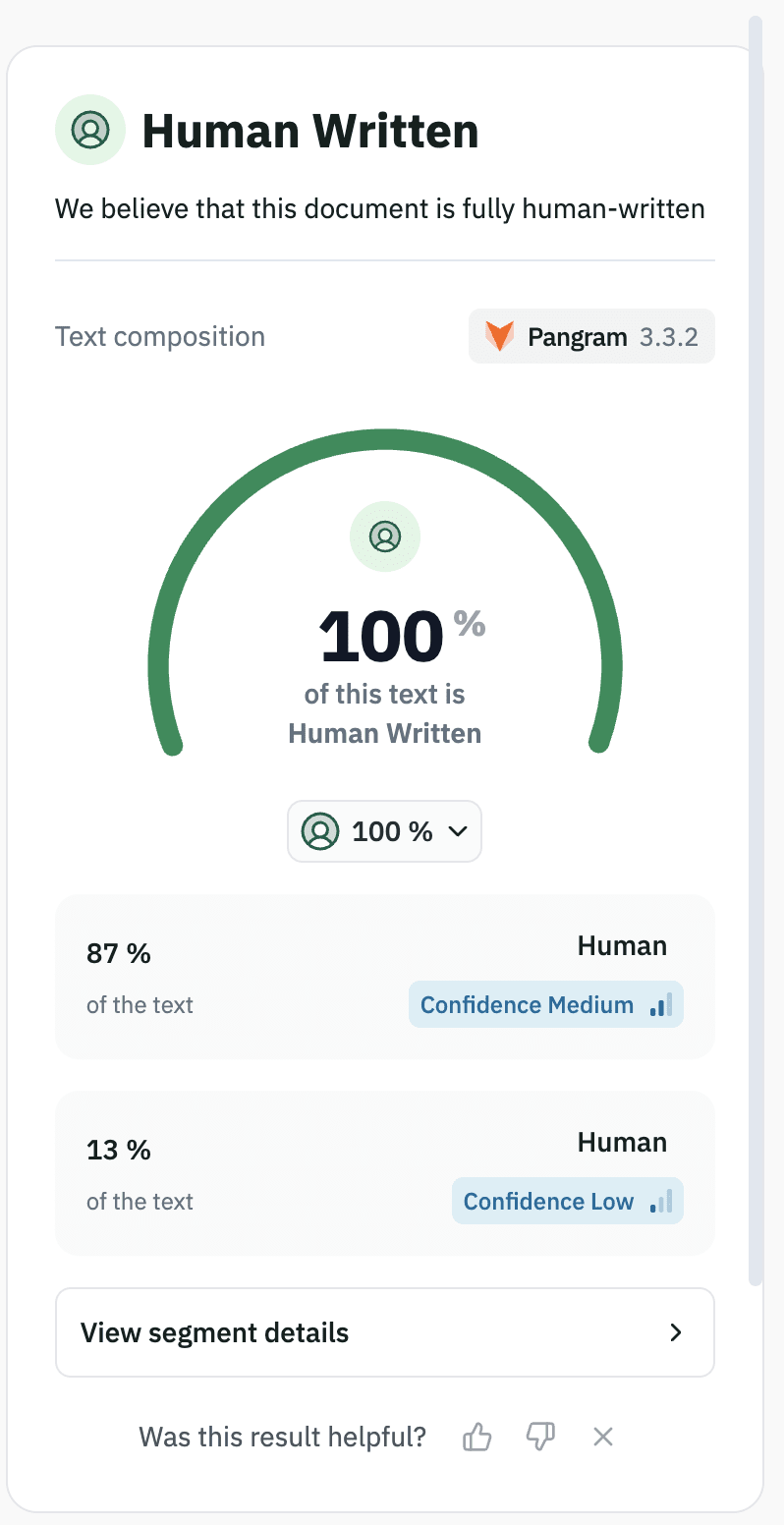
I really dislike how, after 5 minutes of reading the post, I'm struggling to tell whether:
Being able to filter out AI-generated content from the front page would be great, but I don't love that people like @Thomas Kwa🔹 will be somewhat obligated to respond to random slop about METR.