Cameron B
Posts 5
Comments15
Thanks for publishing this!
AE Studio recently reported the results of a survey of 250 EAs. Their survey also included a Big Five personality measure, enabling a comparison between their results and ours. Compared to AE Studio’s survey, we found lower levels of agreeableness, extraversion, and neuroticism among EAs.[4] However, as noted above, it is important to note that these differences could simply reflect differences in the composition of our respective samples or our use of different measures of the Big Five.
Just to elaborate on the 'differences in the composition of our respective samples,' there are (at least) two key distinctions that are worth highlighting:
Our data was collected six years apart (ours was collected earlier this year). It seems quite possible that changes in the make-up of the community over this period is at least partially driving the different measurements.
The EA community sample you report here is significantly larger than the one we collected (~1500 vs ~250), and the criteria for being included in either sample was also presumably distinct (eg, we only included participants who spend ≥5 hours/week actively working on an EA cause area).
Responding to your critique of the model we put forward:
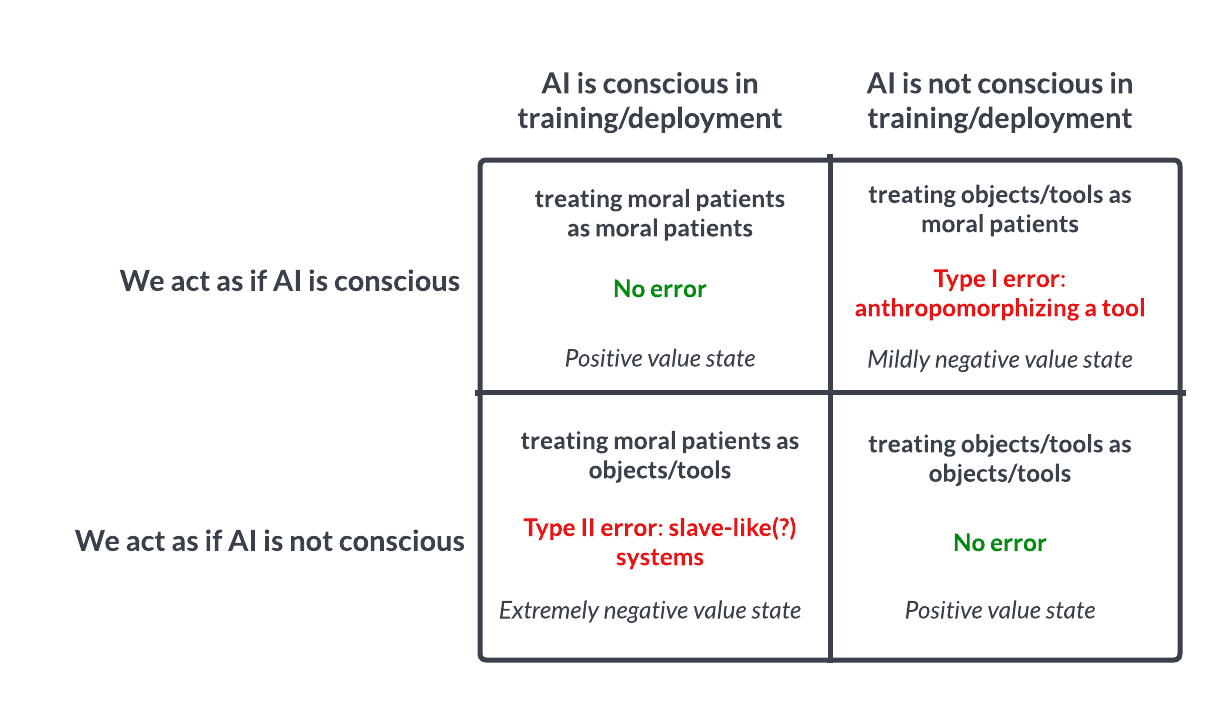
You still need to argue how and why it is useful and should be used to guide decision-making. In neither of the two cases, from what I can tell, do the authors attempt to understand which of the boxes we are in...
We argue that this model can be used to guide decision-making insofar as the Type II error in particular here seems very reckless from both s-risk and x-risk perspectives—and we currently lack the requisite empirical knowledge that would enable us to determine with any confidence which of these four quadrants we are currently in.
You seem to be claiming that this model would only be useful if we also attempted to predict which quadrant we are in, whereas the entire point we are making is that deep uncertainty surrounding this very question is a sufficiently alarming status quo that we should increase the amount of attention and resources being devoted to understanding what properties predict whether a given system is sentient. Hopefully this work would enable us to predict which quadrant we are in more effectively so that we can act accordingly.
In other words, the fact that we can't predict with any confidence which of these four worlds we are currently in is troubling given the stakes, and therefore calls for further work so we can be more confident ASAP.
Thanks for this comment—this is an interesting concern. I suppose a key point here is that I wouldn't expect AI well-being to be zero-sum with human or animal well-being such that we'd have to trade off resources/moral concern in the way your thought experiment suggests.
I would imagine that in a world where we (1) better understood consciousness and (2) subsequently suspected that certain AI systems were conscious and suffering in training/deployment, the key intervention would be to figure out how to yield equally performant systems that were not suffering (either not conscious, OR conscious + thriving). This kind of intervention seems different in kind to me, from, say, attempting to globally revolutionize farming practices in order to minimize animal-related s-risks.
I personally view the problem of ending up in the optimal quadrant as something more akin to getting right the initial conditions of an advanced AI rather than as something that would require deep and sustained intervention after the fact, which is why I might have a relatively more optimistic estimate the EV of the Type I error.
I think both our sets of results show that (at least) a significant minority believe that the community has veered too much in the direction of AI/x-risk/longtermism.
Agreed.
But I don't think that either sets of results show that the community overall is lukewarm on longtermism. I think the situation is better characterised as division between people who are more supportive of longtermist causes (whose support has been growing), and those who are more supportive of neartermist causes.
It seems like you find the descriptor 'lukewarm' to be specifically problematic—I am considering changing the word choice of the 'headline result' accordingly given this exchange. (I originally chose to use the word 'lukewarm' to reflect the normal-but-slightly-negative skew of the results I've highlighted previously. I probably would have used 'divided' if our results looked bimodal, but they do not.)
What seems clear from this is that the hundreds of actively involved EAs we sampled are not collectively aligned (or 'divided' or 'collectively-lukewarm' or however you want to describe it) on whether increased attention to longtermist causes represents a positive change in the community—despite systematically mispredicting numerous times that the sample would respond more positively. I will again refer to the relevant result to ensure any readers appreciate how straightforwardly this interpretation follows from the result—
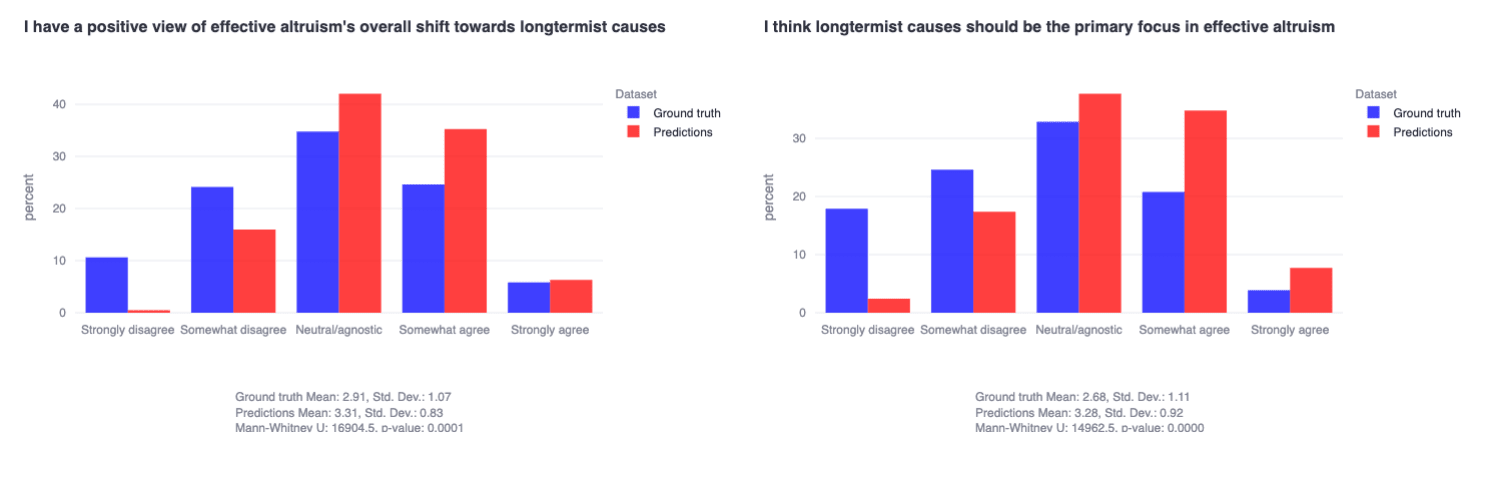
(~35% don't think positive shift, ~30% do; ~45% don't think primary focus, ~25% do. ~250 actively involved EAs sampled from across 10+ cause areas.)
This division/lukewarmness/misalignment represents a foundational philosophical disagreement about how to go about doing the most good and seemed pretty important for us to highlight in the write-up. It is also worth emphasizing that we personally care very much about causes like AI risk and would have hoped to see stronger support for longtermism in general—but we did not find this, much to our surprise (and to the surprise of the hundreds of participants who predicted the distributions would look significantly different as can be seen above).
As noted in the post, we definitely think follow-up research is very important for fleshing out all of these findings, and we are very supportive of all of the great work Rethink Priorities has done in this space. Perhaps it would be worthwhile at some point in the future to attempt to collaboratively investigate this specific question to see if we can't better determine what is driving this pattern of results.
(Also, to be clear, I was not insinuating the engagement scale is invalid—looks completely reasonable to me. Simply pointing out that we are quantifying engagement differently, which may further contribute to explaining why our related but distinct analyses yielded different results.)
Thanks again for your engagement with the post and for providing readers with really interesting context throughout this discussion :)
Thanks for sharing all of this new data—it is very interesting! (Note that in my earlier response, I had nothing to go on besides the 2020 result you have already published, which indicated that the plots you included in your first comment were drawn from a far wider sample of EA-affiliated people than what we were probing in our survey, which I still believe is true. Correct me if I'm wrong!)
Many of these new results you share here, while extremely interesting in their own right, are still not apples-to-apples comparisons for the same reasons we've already touched on.[1]
It is not particularly surprising to me that we are asking people meaningfully different questions and getting meaningfully different results given how generally sensitive respondents in psychological research are to variations in item phrasing. (We can of course go back and forth about which phrasing is better/more actionable/etc, but this is orthogonal to the main question of whether these are reasonable apples-to-apples comparisons.)
The most recent data you have that you mention briefly at the end of your response seems far more relevant in my view. It seems like both of the key results you are taking issue with here (cause prioritization and lukewarm longtermism views) you found yourself to some degree in these results (which it's also worth noting was sampled at the same time as our data, rather than 2 or 4 years ago):
Your result 1:
The responses within the Cause Prioritization category which did not explicitly refer to too much focus on AI, were focused on insufficient attention being paid to other causes, primarily animals and GHD.
Our result 1:
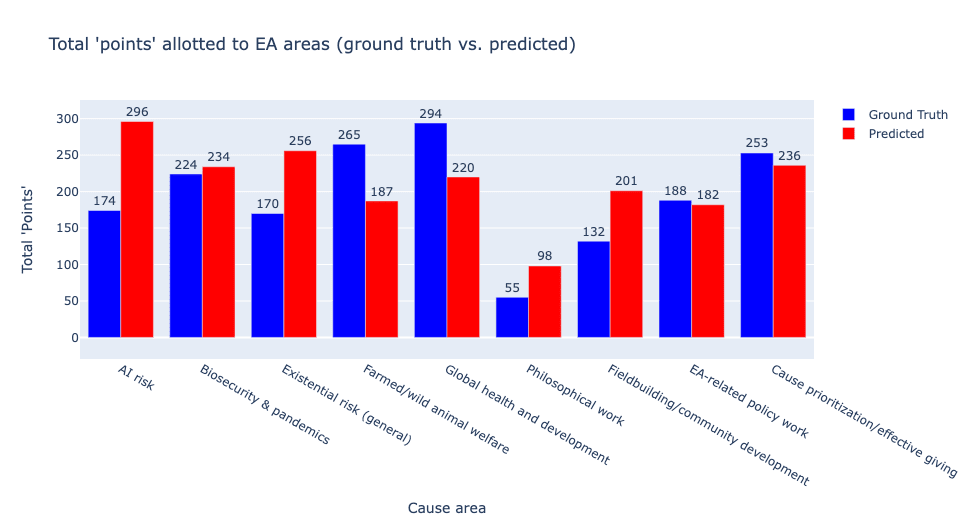
We specifically find the exact same two cause areas, animals and GHD, as being considered the most promising to currently pursue.
Your result 2 (listed as the first reason for dissatisfaction with the EA community):
Focus on AI risks/x-risks/longtermism: Mainly a subset of the cause prioritization category, consisting of specific references to an overemphasis on AI risk and existential risks as a cause area, as well as longtermist thinking in the EA community.
Our result 2:
We specifically find that our sample is overall normally distributed with a slight negative skew (~35% disagree, ~30% agree) that EAs' recent shift towards longtermism is positive.
I suppose having now read your newest report (which I was not aware of before conducting this project), I actually find myself less clear on why you are as surprised as you seem to be by these results given that they essentially replicate numerous object-level findings you reported only ~2 months ago.
(Want to flag that I would lend more credence in terms of guiding specific action to your prioritization results than to our 'how promising...' results given your significantly larger sample size and more precise resource-related questions. But this does not detract from also being able to make valid and action-guiding inferences from both of the results I include in this comment, of which we think there are many as we describe in the body of this post. I don't think there is any strong reason to ignore or otherwise dismiss out of hand what we've found here—we simply sourced a large and diverse sample of EAs, asked them fairly basic questions about their views on EA-related topics, and reported the results for the community to digest and discuss.)
- ^
One further question/hunch I have in this regard is that the way we are quantifying high vs. low engagement is almost certainly different (is your sample self-reporting this/do you give them any quantitative criteria for reporting this?), which adds an additional layer of distance between these results.
Hi Yanni, this is definitely an important consideration in general. Our goal was basically to probe whether alignment researchers think the status quo of rapid capabilities progress is acceptable/appropriate/safe or not. Definitely agree that for those interested, eg, in understanding whether alignment researchers support a full-blown pause OR just a dramatic slowing of capabilities progress, this question would be insufficiently vague. But for our purposes, having the 'or' statement doesn't really change what we were fundamentally attempting to probe.
People definitely seem excited in general about taking on more multidisciplinary approaches/research related to alignment (see this comment for an overview).
Thanks for your comment! I would suspect that these differences are largely being driven by the samples being significantly different. Here is the closest apples-to-apples comparison I could find related to sampling differences (please do correct me if you think there is a better one):
From your sample:
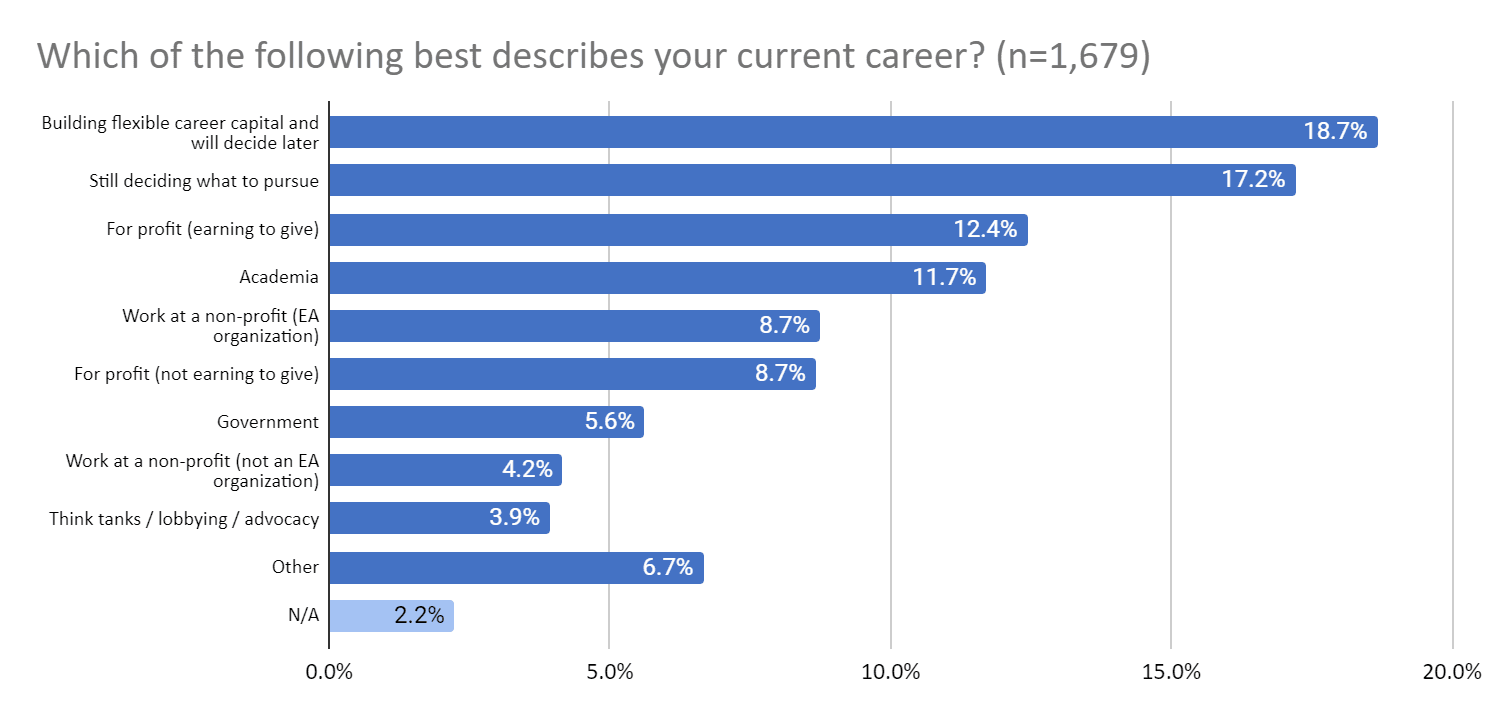
From our sample:
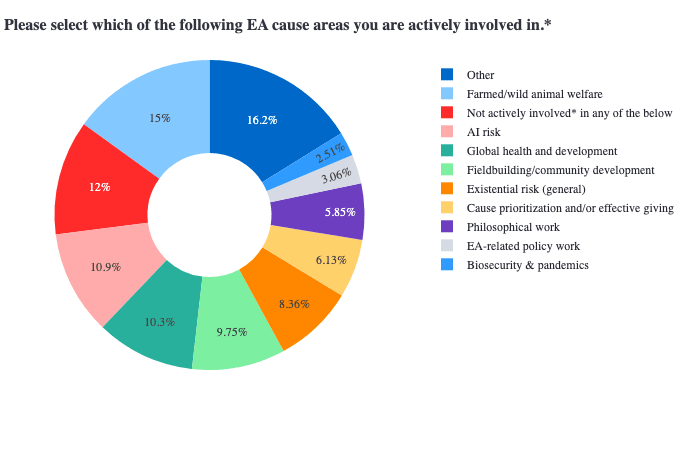
In words, I think your sample is significantly broader than ours: we were looking specifically for people actively involved (we defined as >5h/week) in a specific EA cause area, which would probably correspond to the non-profit buckets in your survey (but explicitly not, for example, 'still deciding what to pursue', 'for profit (earning to give)', etc., which seemingly accounts for many hundreds of datapoints in your sample).
In other words, I think our results do not support the claim that
[it] isn't that EAs as a whole are lukewarm about longtermism: it's that highly engaged EAs prioritise longtermist causes and less highly engaged more strongly prioritise neartermist causes.
given that our sample is almost entirely composed of highly engaged EAs.
Additional sanity checks on our cause area result are that the community's predictions of the community's views do more closely mirror your 2020 finding (ie, people indeed expected something more like your 2020 result)—but that the community's ground truth views are clearly significantly misaligned with these predictions.
Note that we are also measuring meaningfully different things related to cause area prioritization between the 2020 analysis and this one: we simply asked our sample how promising they found each cause area, while you seemed to ask about resourced/funded each cause area should be, which may invite more zero-sum considerations than our questions and may in turn change the nature of the result (ie, respondents could have validly responded 'very promising' to all of the cause areas we listed; they presumably could not have similarly responded '(near) top priority' to all of the cause areas you listed).
Finally, it is worth clarifying that our characterization of our sample of EAs seemingly having lukewarm views about longtermism is motivated mainly by these two results:
These results straightforwardly demonstrate that the EAs we sampled clearly predict that the community would have positive views of 'longtermism x EA' (what we also would have expected), but the group is actually far more evenly distributed with a slight negative skew on these questions (note the highly statistically significant differences between each prediction vs. ground truth distribution; p≈0 for both).
Finally, it's worth noting that we find some of our own results quite surprising as well—this is precisely why we are excited to share this work with the community to invite further conversation, follow-up analysis, etc. (which you have done in part here, so thanks for that!).
Thanks for your comment! Agree that there are additional relevant axes to consider than just those we present here. We actually did probe geography to some extent in the survey, though we don't meaningfully include this in the write-up. Here's one interesting statistically significant difference between alignment researchers who live in urban or semi-urban environments (blue) vs. those who live everywhere else (suburban, ..., remote; red):
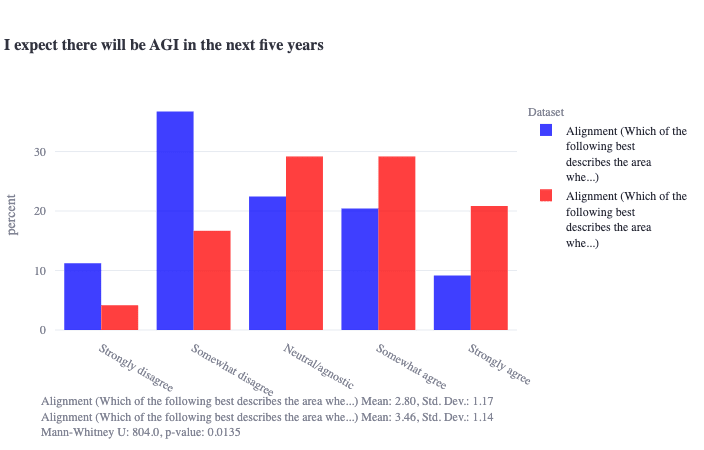
Agree that this only scratches the surface of these sorts of questions and that there are other important sources of intellectual/psychological diversity that we are not probing for here.
Thanks for this, David. I think the greater than/less than 5 hours volunteering is as close as we'll get to an apples-to-apples comparison between the two samples, though I take your point that this subset of the sample might be fairly heterogeneous.
One speculation I wanted to share here regarding the significant agreeableness difference (the obvious outlier) is that our test bank did not include any reverse-scored agreeableness items like 'critical; quarrelsome', which is what seems to be mainly driving the difference here.
I wonder to what degree in an EA context, the 'critical; quarrelsome' item in particular might have tapped more into openness than agreeableness for some—ie, in such an ideas-forward space, I wonder if this question was read as something more like 'critical thinking; not afraid to question ideas' rather than what might have been read in more lay circles as something more like 'contrarian, argumentative.' This is pure speculation, but in general, I think teasing apart EAs' trade-off between their compassionate attitudes and their willingness to disagree intellectually would make for an interesting follow-up.
Thanks again for your work on this!