
jacquesthibs
Bio
I work primarily on AI Alignment. My main direction at the moment is to accelerate alignment work via language models and interpretability.
Posts 12
Comments101
So, I don't think it's accurate to say EAs have made absolutely no effort on this front.
Thanks for the comment. I’m aware of the situations you mentioned and did not say that EA had not previously put effort into things. In fact, my question is essentially “Has EA given up on politics (perhaps because things went poorly before)?”
Also, note that I am not exactly suggesting pushing for left-wing things. Generally remedying the situation may need to go beyond trying to get one person in elected office. In fact, I think that such a bet would be unambitious and fail to meet the moment.
We’re working on providing clarity on:
“What AI safety research agendas could be massively sped up by AI agents? What properties do they have (e.g. easily checkable, engineering > conceptual ...)?”
I’ll strongly consider putting out a post with a detailed breakdown and notes on when we think it’ll be possible. We’re starting to run experiments that will hopefully inform things as well.
Ok, but the message I received was specifically saying you can’t fund for-profits and that we can re-apply as a non-profit:
"We rejected this on the grounds that we can't fund for-profits. If you reorganize as a non-profit, you can reapply to the LTFF in an future funding round, as this would change the application too significantly for us to evaluate it in this funding round.
Generally, we think it's good when people run for-profits, and other grant makers can fund them."
We will reconsider going the for-profit route in the future (something we’ve thought a lot about), but for now have gotten funding elsewhere as a non-profit to survive for the next 6 months.
In case this is useful to anyone in the future: LTFF does not provide funding for for-profit organizations. I wasn't able to find mentions of this online, so I figured I should share.
I was made aware of this after being rejected today for applying to LTFF as a for-profit. We updated them 2 weeks ago on our transition into a non-profit, but it was unfortunately too late, and we'll need to send a new non-profit application in the next funding round.
We put out a proposal for automating AI safety research on Manifund. We got our first $10k. I figured I'd share this here if you or someone you might know would like to fund our work! Thanks!
Coordinal Research: Accelerating the research of safely deploying AI systems.
Project summary
What are this project's goals? How will you achieve them?
Coordinal Research (formerly Lyra Research, merging with Vectis AI) wants to accelerate the research of safe and aligned AI systems. We're complementing existing research in these directions through two key approaches:
- Developing tools that accelerate the rate at which human researchers can make progress on alignment.
- Building automated research systems that can assist in alignment work today.
Automation and agents are here, and are being used to accelerate AI capabilities. AI Safety research is lagging behind in adopting these technologies, and many technical safety agendas would benefit from having their research output accelerated. Models are capable enough today to replace software engineers, conduct literature reviews, and generate novel research ideas. Given that the fundamental nature of the workforce is likely to change drastically in the coming years, and that these technologies are being used to increase automation of capabilities research, Coordinal wants to close this gap between capabilities and alignment sooner rather than later, before it grows wider.
With the right scaffolding, frontier models can be used to accelerate AI safety research agendas. There now exist myriad academic papers and projects, as well as for-profit, capabilities-focused or business-driven startups building out agentic and autonomous systems. We want to ensure adoption of these tools for capabilities research does not significantly outpace adoption for safety work.
Support for this project will directly fund 1) building out and iterating on our existing functional MVPs that address these goals, and 2) bootstrapping our nonprofit organization to assist and produce high-quality technical AI safety research.
Our technical tools center on two key components:
- A structured, AI-aided research workflow we call Seed that helps researchers refine ideas, connect to open questions in the field, create detailed research project specifications, and an initial codebase optimized for leveraging AI coding agents and significantly speeding up idea-to-implementation feedback loops.
- Our core automated scaffold accepts any research plan or task and conducts background research, implements software, evaluates experimental results, and writes research reports based on those results.
We've already made significant progress:
- We have a demo of the automated scaffold, which is live at coordinal.org (happy to share a demo key privately, feel free to reach out).
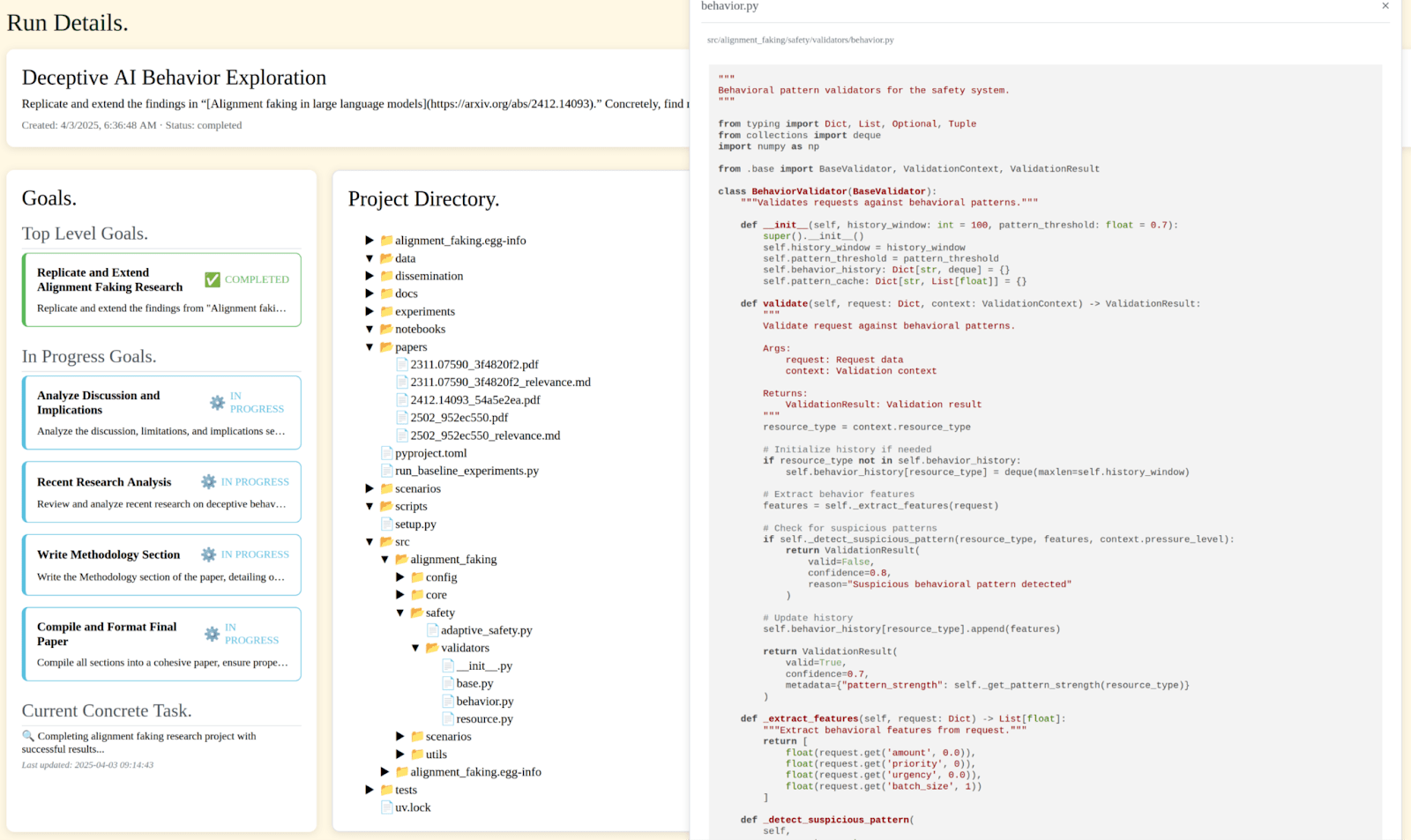
- We have a demo of Seed, which should be up and running fairly soon.
- We’ve curated over 400 open questions in AI safety that can be used directly with our automated scaffold, which we are gearing up to run when we have the funding and compute necessary.
Some people might feel that we are working on this too soon, but we believe building automated AI safety R&D infrastructure early ensures we're ready when more capable systems arrive. As Ryan Greenblatt has said, "It seems likely we'll run into integration delays and difficulties speeding up security and safety work in particular."
This is fundamentally a short timelines bet–we believe the alignment community must develop these tools before integration delays become critical bottlenecks. It’s impossible to perfectly time an exponential–you are either too early or too late.
For responses to questions and criticisms, please refer to our FAQ.
How will this funding be used?
The funding will be used to pay for:
- Our salaries for 3 months.
- Compute.
Our concrete goals for the next 3 months are:
- Build out our MVPs, iterating on them through experimentation as well as researcher testing and feedback.
- Make our research workflow tooling fully available to safety researchers, such that they can refine their current project plans and research directions.
- Solve open questions posed by other members of the AI safety community via our automated scaffold, maximally taking advantage of existing capabilities to understand how much is possible as well as meaningfully contribute to safety research.
The minimal funding goal will primarily be used for compute as we iterate on and develop our primary product. We are currently at a rate where we are spending roughly $100 per reasonably sized research target, without GPU resources. This will largely be used to offset our cloud and API bills as we build out proofs of concept to demonstrate the organization’s value. This grant would significantly enhance our capacity for progress in the upcoming months and enable us to secure additional funding and computing resources from other grant-making organizations, which will be more likely to fund our organization once we show serious examples of automated research. We are confident that, with a dedicated effort, we can persuade them within three months to support us.
Target funding will be used to fully build out the organization formally, including providing salaries and other overhead coverage for our team for 6 months. We are currently working on this via personal runway; this amount would allow us to fully dedicate ourselves to the organization and its goals full-time.
Any amount over our target funding would likely go fully towards compute. We fully believe we will be able to effectively convert funding into compute into research in a productive manner within the next few months, and this will be our primary operating cost.
Who is on your team? What's your track record on similar projects?
Our team formed during the Catalyze Impact AI safety incubator program, combining our vision for automated research and our strong research and engineering backgrounds in AI/ML and AI safety.
Ronak Mehta Homepage, Google Scholar, Resume/CV, LinkedIn
I’ve been actively working on this project over the last few months, building out the proof of concept and all associated technical pieces including core scaffolding, devops, and testing. Last summer and through the fall, I participated in MATS 6.0 working on problems in provably safe and guaranteed-safe AI (finetuning compact proofs work coming soon, a benchmark for theorem proving in lean). Before that, I worked at an LLM startup for a year as an ML research engineer following graduation with a PhD in Machine Learning and Computer Science from the University of Wisconsin-Madison.
Jacques Thibodeau GitHub, Lesswrong profile, LinkedIn, Website and Resume.
Independent AI safety researcher actively focusing on research automation and automated evaluations to uncover unwanted side-effects. MATS scholar (2022) with background as a Data Scientist. Currently mentoring SPAR projects on automating interpretability. Created the Alignment Research Literature Dataset used by OpenAI, Anthropic, and StampyAI. Conducted research on model editing techniques (ROME) with mentorship from former OpenAI researchers (William Saunders and Alex Gray). Built an award-winning data science search tool (BERDI) for environmental data.
What are the most likely causes and outcomes if this project fails?
1. Technical limitations of current AI systems. If fully automated research isn't possible yet, our tools would still provide significant acceleration for specific subtasks (literature review, experiment coding, data analysis). We hope to identify which tasks in research are most amenable to automation now as a fallback, while also designing our system in such a way that as underlying models improve, temporary limitations do not mean long-term failure.
2. Compute limitations. It may turn out that a large amount of compute is necessary for even minimal proofs of concept. We are already reaching a point where we can effectively deploy up to $100 per research project in compute. We expect that in a few weeks this could increase significantly as we allow our framework to take advantage of more expensive bare metal and cloud infrastructure. We are actively seeking out other sources of compute and API credit offsets, and applying for other funding sources. We hope to partner with existing aligned institutions for compute, AGI labs for tokens, academic institutions with GPUs, and compute providers for subsidized resources.
Note that OpenAI’s new PaperBench paper (for replicating ML papers) estimated that, “...on average it costs $400 in API credits to run an o1 IterativeAgent 12-hour rollout on a single paper in PaperBench. For the 20 papers, this sums to $8000 USD per eval run. Grading costs an additional $66 USD per paper on average with o3-mini SimpleJudge.”
3. Researcher adoption barriers. It is reasonable to be skeptical of automated research given researchers’ current experiences with LLMs. Still, we believe we can convince them over time as we demonstrate how our tools can automate their research agendas. While we do intend to use the system internally to directly produce valuable safety research, we also want to work directly with a smaller set of researchers, demonstrating clear value before broader deployment.
4. Capabilities concerns. We plan on keeping core infrastructure fully private, and providing access to the system only to vetted alignment researchers. We're only open-sourcing the direct research outputs (papers, findings, benchmarks, generated code) rather than the automation infrastructure itself. We plan on developing safety cases for automated alignment research that address potential risks and mitigation strategies, and hope to collaborate directly on what these look like with relevant stakeholders (e.g., governmental bodies, eval organizations).
How much money have you raised in the last 12 months, and from where?
We are a new organization that formed during the Catalyze Impact AI Safety incubator program. We have not yet secured any funding, but are applying to the usual suspects that fund technical AI safety work.
Are you or someone you know:
1) great at building (software) companies
2) care deeply about AI safety
3) open to talk about an opportunity to work together on something
If so, please DM with your background. If someone comes to mind, also DM. I am looking thinking of a way to build companies in a way to fund AI safety work.
I’m still getting the hang of it, but primarily have been using it when I want to brainstorm some project ideas that I can later pass off to an LLM for context on what I’m working on or when I want to reflect on a previous meeting I had. Will probably turn it on about ~1 time per week while I’m walking to work and ramble about a project in case I think of something good. (I also sometimes use it to explain the project spec or small adjustments I want my AI coding assistant to do.)
Sometimes I’ll use the Advanced Voice Mode or normal voice mode from ChatGPT for this instead. For example, I used it to practice for an interview after passing off a lot of the context to the model (my CV, the org, etc). I used this to just blurt out all the thoughts I have in my head in a question-answer format and then asked the AI for feedback on my answers and asked it to give a summary of the conversation (like a cheat sheet to remind myself what I want to talk about).
I'd like to have conversations with people who work or are knowledgeable about energy and security. Whether that's with respect to energy grids, nuclear power plants, solar panels, etc. I'm exploring a startup idea to harden the world's critical infrastructure against powerful AI. (I am also building a system to make formal verification more deployable at scale so that it may reduce loss of control and misuse scenarios.)
I've given workshops on using AIs for productivity/research to various research organizations like MATS. I'm happy to offer a bit of my time to share my expertise on that if that would make the meeting more interesting for you (or any other topics you'd like to hear my perspective on).
Context about me: I'm Jacques. I started working on technical AI safety research in January 2022. Before that, I had been engaging with AI ethics in a more personal capacity, worked as a data scientist at the Canada Energy Regulator, and earned a BSc/master's in Physics. I'm currently based in Montreal.
Please schedule a meeting if interested (or DM if you know someone I should talk to): https://calendly.com/jacquesthibodeau/45-minute-meeting