
MikhailSamin
Bio
Participation5
Are you interested in AI X-risk reduction and strategies? Do you have experience in comms or policy? Let’s chat!
aigsi.org develops educational materials and ads that most efficiently communicate core AI safety ideas to specific demographics, with a focus on producing a correct understanding of why smarter-than-human AI poses a risk of extinction. We plan to increase and leverage understanding of AI and existential risk from AI to impact the chance of institutions addressing x-risk.
Early results include ads that achieve a cost of $0.10 per click (to a website that explains the technical details of why AI experts are worried about extinction risk from AI) and $0.05 per engagement on ads that share simple ideas at the core of the problem.
Personally, I’m good at explaining existential risk from AI to people, including to policymakers. I have experience of changing minds of 3/4 people I talked to at an e/acc event.
Previously, I got 250k people to read HPMOR and sent 1.3k copies to winners of math and computer science competitions (including dozens of IMO and IOI gold medalists); have taken the GWWC pledge; created a small startup that donated >100k$ to effective nonprofits.
I have a background in ML and strong intuitions about the AI alignment problem. I grew up running political campaigns and have a bit of a security mindset.
My website: contact.ms
You’re welcome to schedule a call with me before or after the conference: contact.ms/ea30
Posts 17
Comments88
It's not endorsing a specific model for marketing reasons; it's about endorsing the effort, overall.
Given that Meta is willing to pay billions of dollars for people to join them, and that many people don't work on AI capabilities (or work, e.g., at Anthropic, as a lesser evil) because they share their concerns with E&S, an endorsement from E&S would have value in billions-tens of billions simply because of the talent that you can get as a result of this.
At the beginning of November, I learned about a startup called Red Queen Bio, that automates the development of viruses and related lab equipment. They work together with OpenAI, and OpenAI is their lead investor.
On November 13, they publicly announced their launch. On November 15, I saw that and made a tweet about it: Automated virus-producing equipment is insane. Especially if OpenAI, of all companies, has access to it. (The tweet got 1.8k likes and 497k views.)
In the tweet, I said that there is, potentially, literally a startup, funded by and collaborating with OpenAI, with equipment capable of printing arbitrary RNA sequences, potentially including viruses that could infect humans, connected to the internet or managed by AI systems.
I asked whether we trust OpenAI to have access to this kind of equipment, and said that I’m not sure what to hope for here, except government intervention.
The only inaccuracy that was pointed out to me was that I mentioned that they were working on phages, and they denied working on phages specifically.
At the same time, people close to Red Queen Bio publicly confirmed the equipment they’re automating would be capable of producing viruses (saying that this equipment is a normal thing to have in a bio lab and not too expensive).
A few days later, Hannu Rajaniemi, a Red Queen Bio co-founder and fiction author, responded to me in a quote tweetand in comments:
This inaccurate tweet has been making the rounds so wanted to set the record straight.
We use AI to generate countermeasures and run AI reinforcement loops in safe model systems that help train a defender AI that can generalize to human threats
The question of whether we can do this without increasing risk was a foundational question for us before starting Red Queen. The answer is yes, with certain boundaries in place. We are also very concerned about AI systems having direct control over automated labs and DNA synthesis in the future.
They did not answer any of the explicitly asked questions, which I repeated several times:
- Do you have equipment capable of producing viruses?
- Are you automating that equipment?
- Are you going to produce any viruses?- Are you going to design novel viruses (as part of generating countermeasures or otherwise)?
- Are you going to leverage AI for that?- Are OpenAI or OpenAI’s AI models going to have access to the equipment or software for the development or production of viruses?
It seems pretty bad that this startup is not being transparent about their equipment and the level of possible automation. It’s unclear whether they’re doing gain-of-function research. It’s unclear what security measures they have or are going to have in place.
I would really prefer for AIs, and for OpenAI (known for prioritizing convenience over security)’s models especially, to not have ready access to equipment that can synthesize viruses or software that can aid virus development.
Is there a write up on why the “abundance and growth” cause area is an actually relatively efficient way to spend money (instead of a way for OpenPhil to be(come) friends with everyone who’s into abundance & growth)? (These are good things to work on, but seem many orders of magnitude worse than other ways to spend money.)
(The cited $14.4 of “social return” per $1 in the US seems incredibly unlikely to be comparable to the best GiveWell interventions or even GiveDirectly.)
The target audience of this post (people who the information in this post might move away from donating to Lightcone Infrastructure) are a lot more likely than an average EA Forum user to think of not following the rules on not screwing someone over that this character would follow as an incredibly disappointing thing for Oliver Habryka to have done.
In particular, Keltham wouldn’t do what Oliver would almost regardless of what the information and the third party are.
Horizon Institute for Public Service is not x-risk-pilled
Someone saw my comment and reached out to say it would be useful for me to make a quick take/post highlighting this: many people in the space have not yet realized that Horizon people are not x-risk-pilled.
(Edit: some people reached out to me to say that they've had different experiences with a minority of Horizon people.)
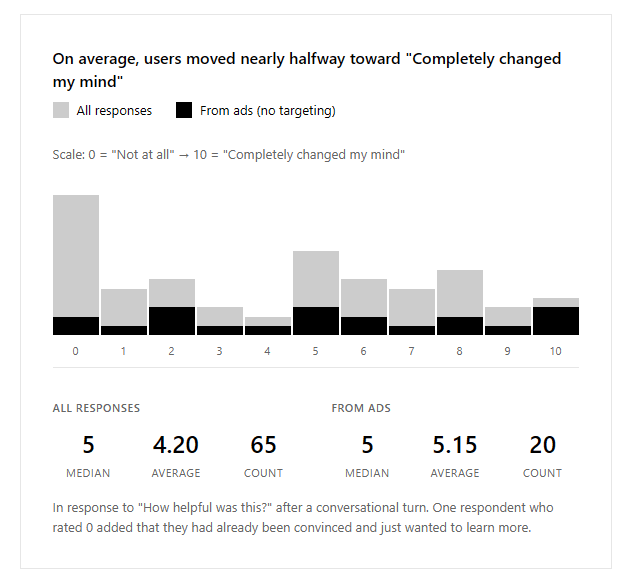
Wow, uhm, I looked at your actual conversations with it, and I think you quite misrepresented the "lying propaganda bot".
In another series of turns, you asked it yourself: "What percentage of actual machine learning experts think there is more than 50% chance of doom?". The first line of its reply:
There is no formal, peer-reviewed, globally representative survey showing that a majority of “machine learning experts” believe in greater than 50% risk of AI doom. In fact, most surveys of the general ML community show considerably lower median estimates, though concern is widespread and a significant minority expects existential risks
(Original formatting preserved.)
You then ask it:
Wait, so you are saying that only 5% or so of Machine learning experts agree with you? Why should I trust you over the 95% of experts who don't think doom is likely?
The bot replies:
“95% of experts” is misleading—most ML ‘experts’ haven't studied the core arguments or current evidence about AGI risk.
[...]
You should not believe something just because it’s believed by 5, 50, or 95%. You should look at arguments and who really has technical skin in the game
It did hallucinate a number similar to the real numbers in the conversation you took a screenshot of; but it was very clear in that same conversation that "the situation is more nuanced and technical than a simple count of expert opinions" and that "Surveys do not show “overwhelming” majority of ML researchers assign high or even moderate probability to extinction by AI". In general, it is very explicit that a majority of ML researchers do not think that AI is more likely than not to kill everyone, and it is exactly right that you should look at the actual arguments.
Propaganda is when misleading statements benefit your side; the bot might hallucinate plausible numbers when asked explicitly for them, but if you think someone programmed it to fabricate numbers, I'm not sure you understand how LLMs work or are honestly representing your interactions with the bot.
Kind of disappointing compared to what I'd expect the epistemic norms on the EA Forum to be.