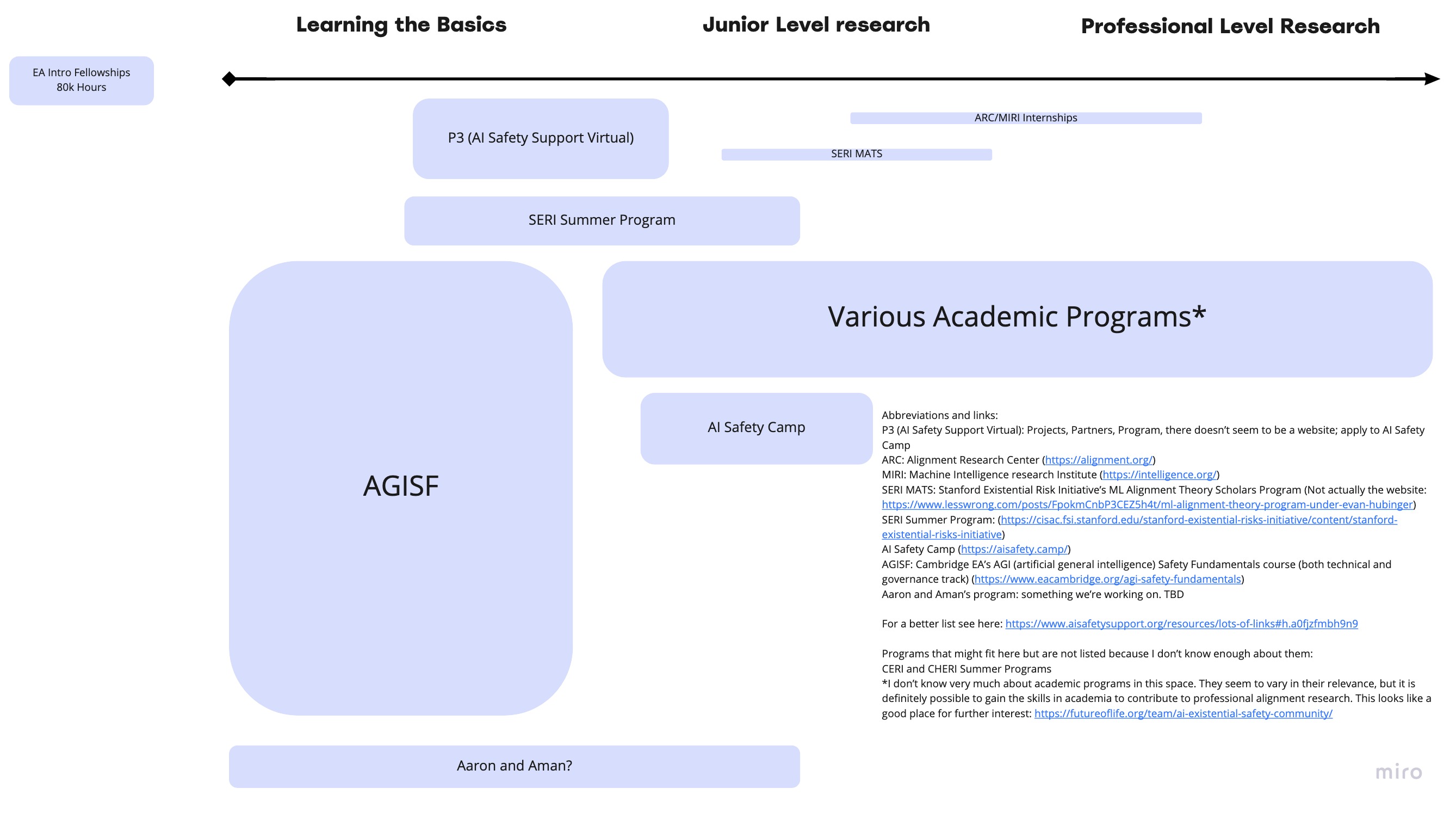
Aman Patel and I have been thinking a lot about the AI Safety Pipeline. In the course of doing so we haven't come across any visualizations. Here's a second draft of a visualized pipeline of what organizations/programs are relevant to moving through the pipeline (mostly in terms of theoretical approaches). It is incomplete. There are orgs that are missing because we don't know enough about them (e.g., ERIs). The existing orgs are probably not exactly where they should be, and there's tons of variation within participants of each program; there should be really long tails. The pipeline moves left to right and we have placed organizations generally where they seem to fit in on the pipeline. The height of each program represents its capacity or number of participants.
This is a super rough draft, but it might be useful for some people to see the visualization and recognize where their beliefs/knowledge differs from ours.
We support somebody else putting more than an hour into this project and making a nicer/more accurate visual.
Current version as of 4/11:
Thanks! Nudged. I'm going to not include CERI and CHERI at the moment because I don't know much about them. I'll make a note of them