I think you can address the violation of dominance by just allowing representatives of theories to bargain and trade. If theory A doesn't care (much) about some choice, and another theory B cares (a lot), theory B can negotiate with theory A and buy out their votes by offering something in later (or simultaneous) decisions.
Newberry and Ord, 2021 have separately developed the sortition model as "proportional chances" voting version moral parliament, which also explicitly allow bargaining and trading ahead of time. Furthermore, if we consider voting on what to do with each unit of resources independently and resources are divisible into a large number of units, proportional chances voting will converge to a proportional allocation of resources, like Lloyd's property rights approach, which is currently the approach I favour.
Also, to prevent minority views from gaining control and causing extreme harm by the lights of the majority, Newberry and Ord propose imagining voters believe they will be selected at random in proportion to their credences and so they act accordingly, compromising and building coalitions, but then the winner is just chosen by plurality, i.e. whichever theory gets the most votes. This seems a bit too ad hoc to me and gives up a lot of the appeal of random voting in the first place, though, and I hope we can find a more natural response. Some ideas:
Other theories can burn their votes/resources to eliminate one theory's votes/resources. I think this could be pretty unfair, because with say two theories competing, the one with greater credence could completely rule out the one with lower credence and gain total control. It should be more costly to do something like this.
There can be a constraining constitution that is decided by a supermajority with a relatively high threshold (not randomly).
I guess that doesn't work for nihilism, but another option when there's indifference or incomparability about a given decision is to just resample until you get a theory that cares (or condition on theories that care). But you might only want to do this for nihilism, because other theories could care that their votes are being given away, if they could have otherwise used them as leverage for decisions they would care about.
I used AI to fix transcription errors, rerrarange the ideas, and suggest tweaks to the title and some sentences.
Three of the most exciting projects to come out of EA in recent years are, in a vague sense, CEA spinouts:
* Kairos is directly a spinout of CEA and now handles most support for university AI safety groups. Basically everyone I've found who knows them is really excited about what they do
* NEST is an opinionated ideas-fi...
TLDR; To help the effective animal advocacy movement cost-effectively absorb greater amounts of funding in the near future, we are seeking expressions of interest from people who could found a new organization focused on:
* Highly neglected animals: insects, wild animals, shrimp, fish, etc, or
* AI and animals: AI alignment and governance for animal welfare, strategic actions considering transformative AI, AI for wild animals, etc.
* ...
It requires theories to be interval-scale measurable. This means that a theory needs to provide information about the ratio of difference in choice-worthiness between different options. E.g. Stoicism says that the difference between lying and killing is ten times bigger than the difference between being honest and lying.
It requires intertheoretic comparisons of value. We need to be able to tell to what extend one theory deems an option as more important than another option, when compared to a different theory. E.g. Utilitarianism says the moral difference between lying and killing is three times bigger than Kantianism says it is.
It falls prey to the infectiousness of nihilism. When an agent has positive credence in nihilism then the choice-worthiness of all actions is undefined. E.g. If you think nihilism has 1% chance of being true, you can't evaluate one option as morally better than another.
Some say it has a problem with fanaticism. It ranks a minuscule probability of an arbitrarily large value above a guaranteed modest amount of value. E.g. If you think christianity has a 1% chance of being true, and it gives people infinite happiness in heaven, you should choose it above your 99% chance that utilitarianism is true, which only posits finite happiness.
Two years ago one of us created an approach that wouldn't fall prey to these problems: the sortition model of moral uncertainty.
Problems with the sortition model of moral uncertainty
The sortition model prescribes that if you have x% credence in a theory, then you follow that theory x% of cases. If you have 20% credence in Kantianism, 30% credence in virtue ethics and 50% credence in utilitarianism, you follow Kantianism 20% of the time, virtue ethics 30% of the time and utilitarianism 50% of the time. When you act according to a theory is selected randomly with the probability of selection being the same as your credence in said theory.
This approach doesn't fall prey to the problems of interval-scale measurability, intertheoretic comparisons of value, or the infectiousness of nihilism. Furthermore, the theory is fair, computationally cheap and doesn't generate problems with fanaticism and theory-individuation. However, it does have a big problem of its own, it violates the principle of moral dominance.
Suppose you face this decision:
Theory 1
All other theories
Option A: Punching someone
permissible
impermissible
Option B: Not punching someone
permissible
permissible
The principle of moral dominance states that if an option A is better than B according to at least one possible moral theory and as good as B in all others, then you should choose A instead of B. The principle of moral dominance prescribes in this scenario that we shouldn't punch someone. However, if the sortition model randomly selects theory 1, then according to the sortition model it is equally appropriate to punch or not punch someone, directly violating the principle of moral dominance.
You could solve this by saying that once a theory doesn't eliminate all the options, the leftover 'appropriate' options are presented to another randomly selected theory who eliminates the options they deem inappropriate and so on, until only one option remains. However, this doesn't solve the sentiment that some choices are just higher stakes for some theories than others. Consider this decision:
Theory 1
All other theories
Option A: Punching someone
0.0002
0
Option B: Not punching someone
0.0001
1000
Even with this solution, it's possible that the sortition model lands on theory 1 and chooses option A, despite it only being a very slight preference for theory 1, while all the other theories have a very strong preference for option B. We could solve this by normalizing the distributions (giving the theories "equal say"), but sometimes some theories genuinely care more about a decision than others (We'll return to this problem at the end of this post). Perhaps we give the selection process a random chance to switch to another theory, with the odds of that occurring being determined by how much the other theories prefer a different option. However, this adds computational complexity. Let's look at a different approach.
Runoff randomization
We might want to do is something in between "only letting theories assign options either permissible or impermissible" and "giving a numeric value to options". What if we let the process go through several runoff rounds? Let's call this version runoff randomization. Say you face the following decision:
Theory 1
Theory 2
Theory 3
Option A
1
1
2
Option B
1
1
1
Option C
20
20
impermissible
Option D
20
20
impermissible
If you think we should strongly focus on impermissibility (e.g. certain strands of deontology and suffering-focussed ethics) you might want to first have a selection round that eliminates all the options that at least one theory considers impermissible (options C and D). You subsequently select in a second round the best option from the ones that remain (in this case it would be option A between A and B).
However this gives some weird results. Theory 1 and 2 strongly prefer options C and D, but because Theory 3 finds them impermissible it can eliminate them and cause its (slightly) preferred option to win. This can get especially weird if there are hundreds of theories under consideration, any one of which can shut down all the options except their favorite one.
Let's be a bit milder. Suppose you face the following decision:
Theory 1
Theory 2
Theory 3
Option A
10
10
11
Option B
10
10
10
Option C
10
neutral
13
Option D
impermissible
10
-10 (impermissible)
A notable feature of this approach is that theories can give quantitative recommendations, qualitative recommendations or a combination of the two. This doesn't matter because the idea is that we do three rounds of runoffs:
First we randomly select a theory. In said theory we eliminate the "impermissible" options. Let's say we randomly draw theory 1 and see that it only considers option D to be impermissible, we therefore eliminate option D.
Secondly we randomly draw another theory. In said theory we eliminate the "neutral" options. Let's say that this time we draw theory 2. It considers option D, B and A permissible, but we've already eliminated option D in the previous round, so the only thing we can eliminate is option C which it is "neutral" towards.
Lastly we randomly draw a final theory and we eliminate its "non-optimal" options so we only end up with the "optimal" options. Let's say that this time we draw theory 3. While it considers option C the optimal choice we have already eliminated options C and D. Between options B and A it considers option A to be the "optimal" choice, so we end up choosing option A.
If a theory eliminates all the remaining options, you draw again. E.g. if nihilism is neutral towards all the options (because it doesn't make a value judgement), you randomly select another theory. If in this process, you have exhausted all theories without reaching the next round, we go to the next round anyway, keeping all the remaining options in.
For any round the chance that a theory is selected depends on the credence you have in said theory. So if you have 98% credence in theory 1 and only 1% in the others, you have a 98% chance of selecting it in the first round, a 98% chance in the second and a 98% in the third.
Note that value and permissibility are not the same thing. A negative value for example doesn't necessarily mean an option is impermissible. If a theory assigns option A '-1000' and option B '-1' it might be that it doesn't consider option B to be impermissible, but rather optimal. Where a theory draws the line between merely assigning a low value and also considering an option impermissible varies from theory to theory.
Why you need randomization
So why would we still use randomization and not exclusively the runoff? Let's say you face the following decision:
Theory 1
30% credence
Theory 2
20%
Theory 3
20%
Theory 4
20%
Theory 5
10%
Option A
1
0
0
0
0
Option B
0
1
1
1
1
If you start with the theory you have the most credence in, it's possible that you'll keep choosing options that most other plausible theories don't agree with. Randomization solves this.
Not randomizing also makes your theory vulnerable to "theory-individuation". Theory-individuation occurs when one theory splits into multiple versions of the same theory. For example, say you have 60% credence in utilitarianism and 40% credence in Kantianism:
Utilitarianism
60% credence
Kantianism
40%
Option A
1
0
Option B
0
1
However, you soon realize that there are two slightly different versions of utilitarianism, hedonistic utilitarianism and preference utilitarianism:
Kantianism
40%
Hedonistic Utilitarianism
30%
Preference Utilitarianism
30%
Option A
0
1
1
Option B
1
0
0
Without randomization Kantianism would dictate how you behave, even though your overall credence in utilitarianism hasn't changed.
Epistemological runoff
However, the various versions of both "maximizing expected choice-worthiness" and "the sortition model" require you to able to assign a numerical percentage of credence to each theory. What if we aren't fans of Bayesian epistemology? Or what if we aren't able to do this in the real world?
We could have the same runoff that we did for moral value, but apply it to epistemology. So all the moral theories that our epistemological theory considers "impermissible" get eliminated, then the "neutral" ones and then the "impermissible" but not "optimal" ones. What's left are the moral theories we use our theory of moral uncertainty on.
What if we are uncertain about our epistemological theory? Don't we run into an infinite regress problem? I'm not sure how fruitful this runoff business is in meta-epistemology. Let's see if we can get a theory of moral uncertainty that doesn't require a runoff.
Convex randomization
If we use a convex hull we don't have to assign probabilities. Here's how that works:
Order the options in an arbitrary way from 1 to k.
For each theory Z, let V(Z) be the list of choice-worthinesses of all options according to this theory. I.e., the first entry is Z's evaluation of option 1, the last entry is Z's evaluation of option k.
Interpret the entries in the list V(Z) as the coordinates of a point in a k-dimensional space.
Let P be the set of all these points, one for each theory.
Let H be the "convex hull" of the set of points P, i.e., all points contained in a tight rubber envelope around P, or, more mathematically, all points that lie on some straight line between any two points in P.
Let R be a randomly chosen point in the interior of H (i.e., in H but not on the boundary of H), chosen from the uniform distribution on H. (Note that by excluding the boundary, we in particular exclude the possibility that R equals any of the original points in P.)
Choose the option that corresponds to the largest entry in R. I.e., if the third entry in R is the largest, choose the third option.
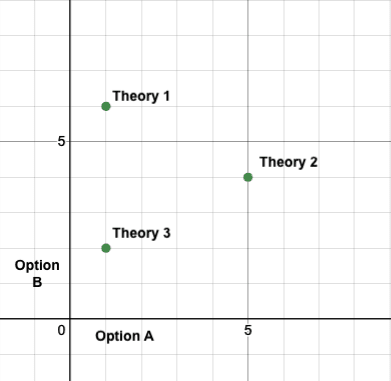
Let's look at an example. Suppose you face this decision:
Theory 1
Theory 2
Theory 3
Option A
1
5
1
Option B
6
4
2
We now need to interpret the choice-worthiness as coordinates, with option A being the x-axis and option B being the y-axis.
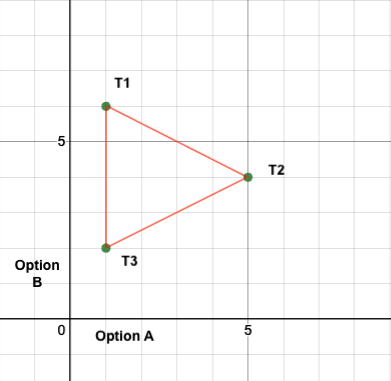
Now we draw a convex hull around it. Imagine it's a tight rubber envelope around all points.
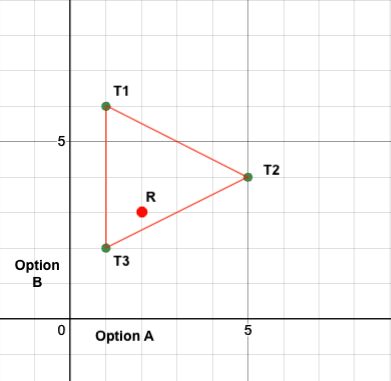
Now we randomly pick a point R inside this space (without its boundary).
Point R gives option A a choice-worthiness of 2 and B a choice-worthiness of 3, so we choose option B.
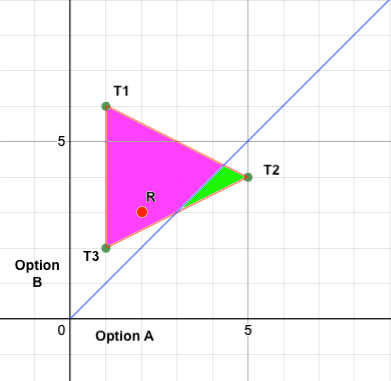
If we make a diagonal line we can see it even more clearly. The area of the convex hull that is beneath the blue line (aka the green area) represents the odds that R will land on option A. The area of the convex hull that is above the blue line (aka the pink area) represents the odds that R will land on option B. As you can see there's a bigger chance that this process will choose option B.
The convex hull ensures that dominated option cannot win. This is because when S is dominated by T, then there is at least one theory that rates T better than S, and that theory has a nonzero weight in the mixture corresponding to R (because we exclude the boundary, on which that theory might make a zero contribution to R), so T will always have at least one larger entry in R than S has.
It also makes the theory clone-consistent: If someone takes a theory T, modifies it in a negligible way and adds it as another theory T', then the set H will change only negligibly and hence the winning probabilities won't change much. Similarly, it combats the problem of theory-individuation, splitting a theory into multiple similar theories only changes H very slightly.
Problems with convex randomization
Convex randomization (CR) solves the problems of violating moral dominance (because of the convex hull), theory cloning/theory-individuation, and arguably the infectiousness of nihilism (because nihilism doesn't prescribe coordinates so it doesn't get added to the graph), however it does require intertheoretic comparisons of value and ratio-scale measurability.
We could say that theories find actions either permissible, impermissible, or are neutral on the matter. We could represent this as a coordinate system where permissible actions get 1, impermissible actions get -1 and actions that are deemed neutral get 0. However, while this might be preferable for categorical theories like Kantianism, this does collapse the nuance of numerical theories. If prioritarianism gives an action a choice-worthiness of 100, while utilitarianism gives it a 2, they will both be collapsed down into permissible (1) despite the huge difference between them. Perhaps adding a runoff with an "optimal" round will solve this, but the whole point of using the convex hull is that we no longer need a runoff.
Another problem is that CR is more computationally complex than the sortition approach. However, computational complexity isn't generally seen as a weak point by philosophers.
CR also requires there to be more theories than options. If there aren't, the interior of the 'envelope' will be empty. This isn't really a problem since almost any theory will have some continuous parameter (such as a discount rate or degree of risk-aversion) which makes it become infinitely many theories. Even if you have infinitely many discrete options, the infinite continuous theories will still outnumber them (ℵ0 < ℵ1).
CR has a problem with fanaticism, although to a lesser extent than MEC. If a theory says option A has 10^1000 choice-worthiness, R won't always land on option A but it will be biased towards it. Similarly, if a theory says option A has an infinite amount of choice worthiness, R won't literally always land on A, but will practically always land on A. However, MEC's solution of using amplification or using normalization to give different theories 'equal say' could also be used by CR. If you don't think we should normalize at every choice, here's a different approach. Perhaps all theories get an equal choice-worthiness 'budget' over a span of time (e.g. the agents lifetime). The theories can spent this budget however they like on any options that are presented giving theories more power to influence events they consider crucial. This would tackle choice-worthiness in the same way linear and quadratic voting tackle votes (and the same debate between the linear and quadratic approach exists here).
CR makes you less single-minded, it stops a moral theory from dominating even though it only has slightly more credence (e.g. 51% vs 49%). However, because CR uses randomization you don't appear to be entirely consistent to an outsider, which might make you harder to coordinate with. This could be solved by using the centroid instead of a random point.
Using centroids
The centroid is the "center of gravity" of the convex hull, and it can be seen as the most natural "representative point" inside that set. Interestingly, that approach can also lead to some form of "ex-post" credence values for theories, relative to the preference data. This is because the centroid can be expressed as a convex combination of all the points representing the individual theories, similar to barycentric coordinates. Each such convex combination assigns coefficients to all theories, and these coefficients sum up to 1; so they could be interpreted as credence values for the respective theories. It remains however to clarify which convex combination is the most natural one since in general there will be several.
However, you might conversely think that the 'centroid theory' of moral uncertainty makes you too morally rigid. One solution could be that the randomization process is biased towards the centroid (i.e., the further from the centroid a point is the lower the probability of point R appearing there) with the strength of the bias being determined by how much you value consistency. What this allows you to do is regain a kind off credence distribution (like MEC) without actually needing probabilities.
References
MacAskill, W. (2013). The Infectiousness of Nihilism. Ethics, 123(3), 508–520. https://doi.org/10.1086/669564
Macaskill, W., Bykvist, K. & Ord, T. (2020). Moral Uncertainty. OXFORD UNIV PR.


![Bob Jacobs [inactive]](https://res.cloudinary.com/cea/image/upload/c_crop,g_custom/c_fill,dpr_2,q_100,f_auto,g_auto:faces,w_36,h_36,b_white/Profile/w5vjftvndjb0tsxvugwg)

I think you can address the violation of dominance by just allowing representatives of theories to bargain and trade. If theory A doesn't care (much) about some choice, and another theory B cares (a lot), theory B can negotiate with theory A and buy out their votes by offering something in later (or simultaneous) decisions.
Newberry and Ord, 2021 have separately developed the sortition model as "proportional chances" voting version moral parliament, which also explicitly allow bargaining and trading ahead of time. Furthermore, if we consider voting on what to do with each unit of resources independently and resources are divisible into a large number of units, proportional chances voting will converge to a proportional allocation of resources, like Lloyd's property rights approach, which is currently the approach I favour.
Also, to prevent minority views from gaining control and causing extreme harm by the lights of the majority, Newberry and Ord propose imagining voters believe they will be selected at random in proportion to their credences and so they act accordingly, compromising and building coalitions, but then the winner is just chosen by plurality, i.e. whichever theory gets the most votes. This seems a bit too ad hoc to me and gives up a lot of the appeal of random voting in the first place, though, and I hope we can find a more natural response. Some ideas:
I guess that doesn't work for nihilism, but another option when there's indifference or incomparability about a given decision is to just resample until you get a theory that cares (or condition on theories that care). But you might only want to do this for nihilism, because other theories could care that their votes are being given away, if they could have otherwise used them as leverage for decisions they would care about.
Related paper: A bargaining-theoretic approach to moral uncertainty.