Comments
Nice breakdown, I can see myself visiting this sometime in the future(hopefully not too soon)
My take on this is way too many people optimize for impact in the early rungs, which is bad. I think way too much of the messaging is impact-centric, which leads to people optimizing for the wrong end-goals when, in reality, hardly anyone will read/care about your shiny new fellowship paper.
For the past ~3 quarters, I have been optimizing for fun, and this gives me the right amount of kick to keep me going.
Additionally, for fields like policy, the lack of objective results is made up for by the higher requirements of social clout, which involves building a network that probably takes a lot of time(this is one of those pesky chicken and egg problems).
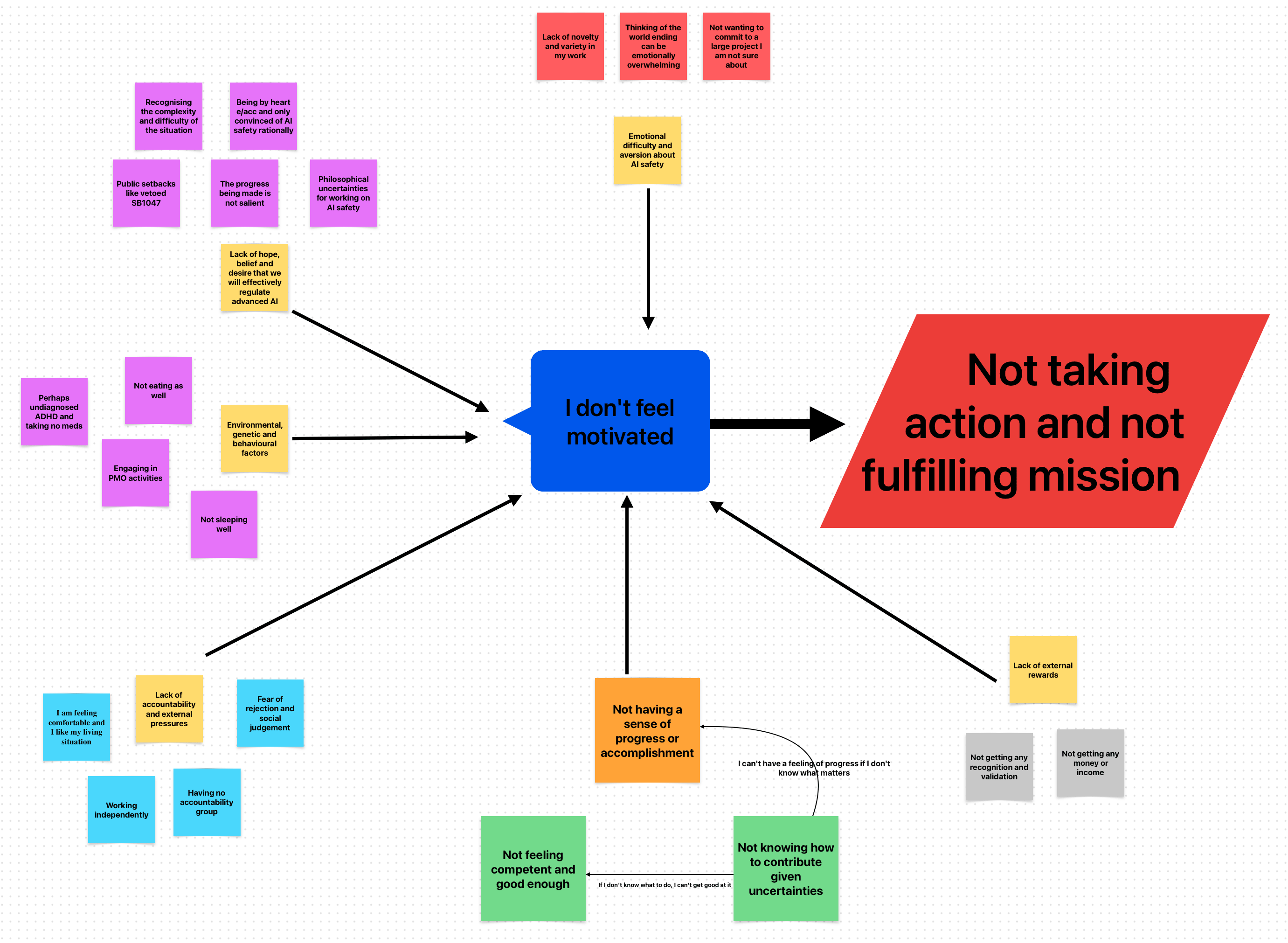


Speaking for myself, the main reason I don't get involved in AI stuff is because I feel clueless about what the correct action might be (and how valuable it might be, in expectation). I think there is a pretty strong argument that EA involvement in AI risk has made things worse, not better, and I wouldn't want to make things even worse.
Yes, this was the biggest reason why I was considering to exit AI safety. I grappled with this question multiple months. Complex cluelessness triggered a small identity crisis for me haha.
"If you can't predict the second and third order effects of your actions, what is the point of trying to do good in the first place?" Open Phil funding OpenAI is a classical example here.
But here is why I am still going:
I'm doing no one a favour by coming to the conclusion the risk that it's just not tractable at all is too high, so I'm just not going to do it at all. AGI is still going to happen. It's still going to be determined by a relatively small number of people. They're going to, on average, both care less about humanity and have thought less rigorously about what's most tractable. So I'm not really doing anyone a favor by dropping out.
More concretely:
Even if object-level actions are not tractable, the EV of doing meta-research still seems to significantly outweigh other cause areas. Positively steering the singularity remains for me to be the most important challenge of our time (assuming one subscribes to longtermism and acknowledges both the vast potential of the future and the severe risks of s-risks).
Even if we live in a world where there is a 99% chance of being entirely clueless about effective actions and only a 1% chance of identifying a few robust strategies, it is still highly worthwhile to focus on meta-research aimed at discovering those strategies.