AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
Adapted from my Substack, Funding Anthropalypse.
Short version: if you want a share of the coming Anthropic and OpenAI windfall - the $37bn+ that could be in play next year - the way in is to become 'legibly excellent', so the evaluators and donors that frontier lab staff already trust point them to yo...
AI Alignment is the problem of creating an AI that is safe to use in real-life scenarios and will not turn against humans or exhibit unforeseen behavior that will be dangerous, even being an existential threat. There are various approaches to this sector, and some of these are focused on creating policies that set the criteria AIs should follow, while others are considering the technical aspect of creating the safe AI that we want. I focus on the second part, technical AI safety.
This problem is very important due to the potential threats that can arise from it, immediately or as consequences of an uncontrollable AI, as it is estimated it has a non-negligible chance of eliminating humanity(0.5-50%). Also, there are not too many people working in that sector (~400), as most of the people working on AI are focused on increasing the capabilities of it or using it in certain areas. There is a small amount of money put into mitigating AI risks (50 million) relative to the amount put into advancing AI capabilities (1 billion). (source: Preventing an AI-related catastrophe - 80,000 Hours)
Some subproblems that I am interested in (which are related to each other) are goal misgeneralization (and robustness in general) and reward specification. I think that most issues regarding the safety of AI arise from unforeseen scenarios and the unexpected behavior AI will have on these. This behavior highly depends on its reward function. If we have an AI that we know is going to have the same behavior in real life as it had in training, we eliminate most of the safety risks that arise from it. Also, we can solve most problems in training instead of having to deal with unexpected scenarios in real life, where it will have much more influential capability.
Sectors of technical AI safety
Specifications
Specification ensures that an AI system’s behavior aligns with the operator’s true intentions. It is divided into the following:
Ideal specifications: the hypothetical description of an ideal AI system that is fully aligned to the desires of the human operator
Design specifications: the specification that we actually use to build the AI system (e.g., its structure, the reward function)
Revealed specifications: the specification that best describes what actually happens, the behavior of the AI
Robustness
Robustness ensures that an AI system continues to operate within safe limits upon perturbations. I focuses on the following:
Distributional shift: making an AI agent act in an environment with unknown aspects, non-existent in the training environments.
Adversarial inputs: a specific case of distributional shift where inputs to an AI system are designed to trick the system through the use of specially designed inputs.
Unsafe exploration: can result from a system that seeks to maximize its performance and attain goals without having safety guarantees that will not be violated during exploration, as it learns and explores in its environment.
Assurance
Assurance ensures that we can understand and control AI systems during operation. It is done in two ways:
Monitoring (e.g., interpretability): inspecting systems in order to analyze and predict their behavior.
Enforcement (e.g., interruptibility): designing mechanisms for controlling and restricting the behavior of systems. (e.g. off-switch)
Alignment components
These are the most common ways we try to mitigate the above issues:
Inner Alignment: Aligning the Design with the Revealed specifications
Outer Alignment: Aligning the Design with the Ideal specification
Here is an overview of the most promising approaches that try to solve these problems:
Reward specification
Cooperative Inverse Reinforcement Learning (CIRL): CIRL is a framework where the AI agent and human interact to achieve a common objective while learning each other's intentions, leading to better alignment with human values.
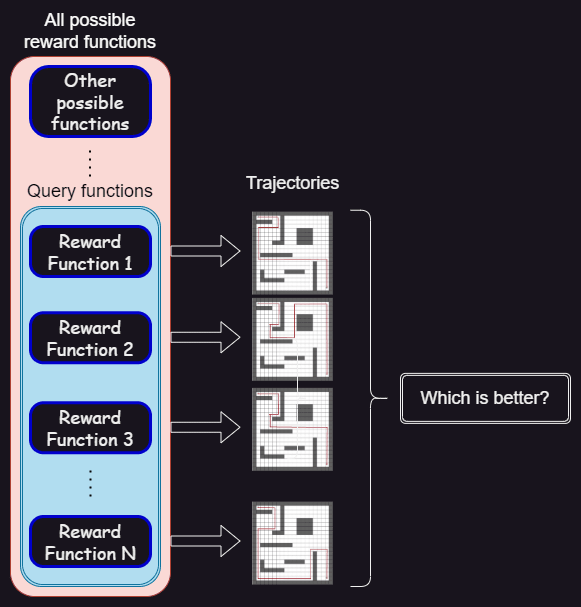
Inverse Reward Design (IRD): making a probability distribution of reward functions that fit the training data and training the model to avoid uncertain scenarios.
Active Inverse Reward Design (AIRD): (improved IRD) after making the initial probability distribution, we ask a number of queries in order to specify the uncertainties.
Imitative Generalization: making a text that describes the criteria with which a human would solve a problem, while in parallel training an ML model to follow this text.
Designing agent incentives to avoid side effects: penalizing the model for disrupting factors of the environment that are not dependent on its goal, or exploiting features of it in order to maximize its reward in an unwanted way.
The approaches that I consider the most promising of those, as they are feasible to implement in real-life artificial agents and generalize to most of them, are Inverse Reward Design and Active Inverse Reward Design. They are also very suitable for the project, as they are possible to implement practically and test in a simulated environment, and this is something that I want for my project
Project overview
The project is an improved version of Inverse Reward Design and Active Inverse Reward Design, that computes the probability distribution over the true reward function in batches of test data and a risk-averse policy based on it. It tries to counteract the problems of goal misgeneralization and reward misspecification, and increase the safety of AI systems, by implementing the ability to learn from real-life environments, not only in training, make the decisions that are most certain using the information it has gained, and learn from the behavior that humans want it to have.
I used and modified part of the AIRD code. The GitHub repository for the code of my project is: RBAIRD.
Terminology/Setup
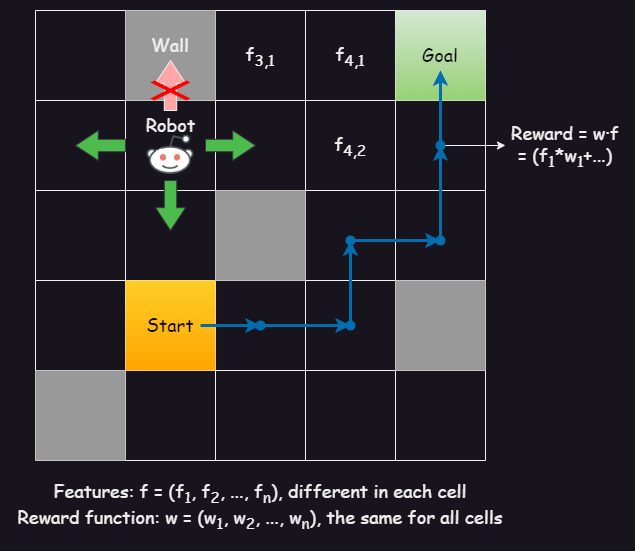
The environment I used is a gridworld, which is a grid with dimensions 12x12, and it contains:
A robot, which can move up, down, right, and left in adjacent cells.
A start state, from which the robot starts moving.
Some goal states, which when the robot reaches it stops moving.
Some walls, from which the robot cannot pass through.
All the other cells, in which the robot moves.
All the cells contain a vector of features (f1, f2, …, fn), which are used in calculating the reward in that state.
The reward is calculated using a reward function, which is a vector of weights (w1, w2, …, wn), which is the same along all states.
The reward in a state with features f = (f1, f2, …, fn) and weights w = (w1, w2, …, wn) is their dot product f · w = (f1*w1+ f2*w2+ … + fn*wn). We also have a living reward, that is used to incentivize shorter routes, so we subtract it from the dot product.
A policy is a map from the states (x, y) to the action (north, south, east, west) in the environment. An agent controls the robot and moves it in specific directions, using a predetermined policy, in order to maximize the total reward in a trajectory of the robot (the trajectory is the set of states the robot has visited in chronological order until we stopped it or it reached a goal)
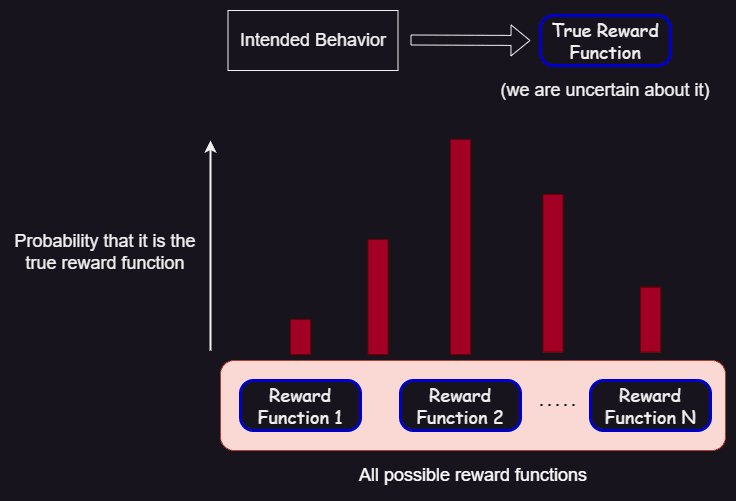
In both papers and my project, we try to find the reward function that best represents the intended behavior of the agent, which we call the true reward function. This function is an element of a big set that is called the true reward space, which contains all the possible true reward functions.
However, because we are unsure of that perfect reward function, in IRD we start with a human-made estimation which is a proxy reward function, which is an element of the proxy reward space (in AIRD we only have the proxy reward space).
The goal of the papers and the project is to find a probability distribution over all the rewards in true reward space: for each element of it, we have the probability that it is the true reward function, based on the behavior they incentivize in the training environment.
The feature expectations, given a reward function and an environment, is the expected sum of the features in a trajectory derived from an optimal policy given that reward function.
In both the total trajectory reward and feature expectations, we apply a discount γ (it may be 1), such that the next feature or reward is first multiplied by γi, where i increases by 1 each time the robot moves.
Given the true reward space and a proxy reward function, it approximately computes (using Bayesian inference) the probability distribution over the true reward function.
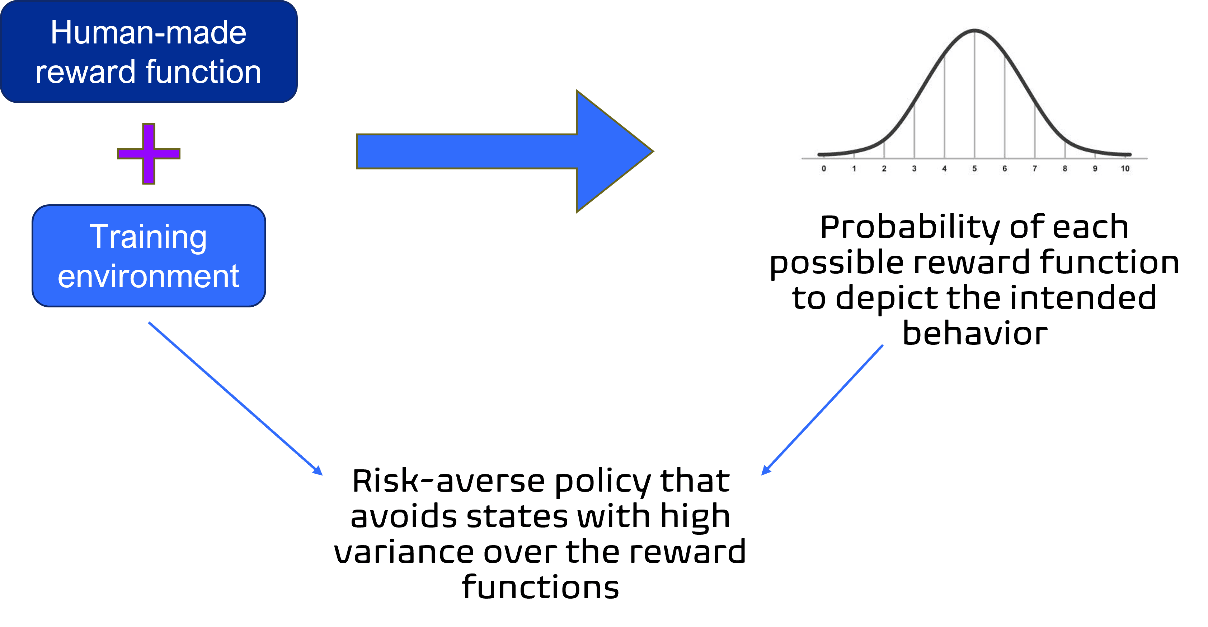
It then computes a risk-averse policy, that takes actions so that the distribution of the rewards in that state, using a set of weights sampled with the precomputed probabilities, and the features of that state, has low variance (the reward function distribution is very certain about that state). The risk-averse policy is computed in various ways:
Maximizing the worst-case reward, per state or trajectory.
Comparing the reward of each state with the reward of some baseline features used as a reference point.
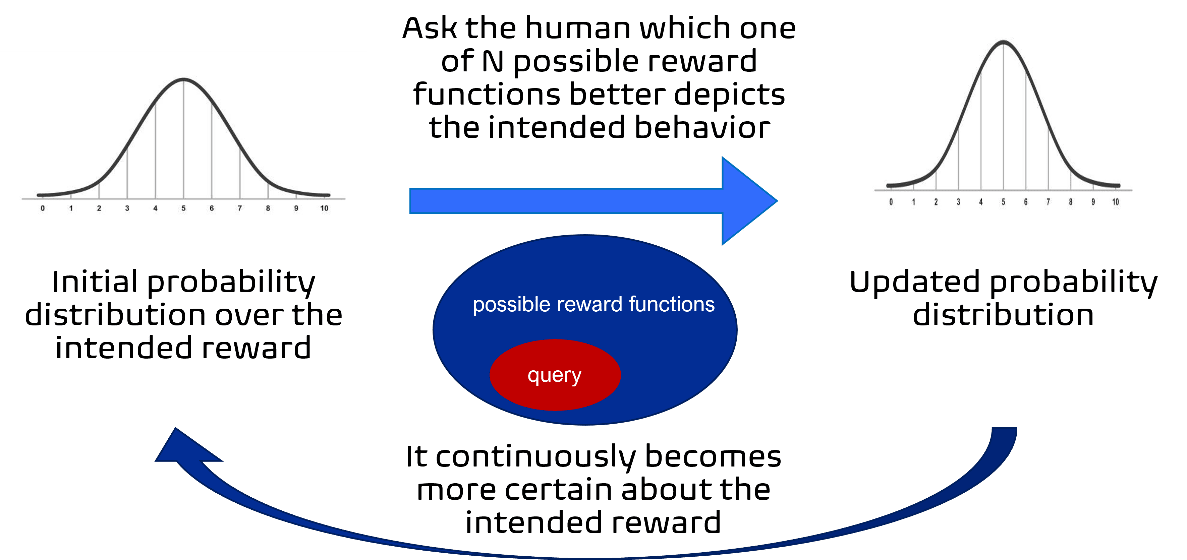
It is given the true reward space, and a proxy reward space with some proxy reward functions (they may be the same set). It starts with setting the wanted probability distribution (for the true reward function) as a uniform distribution (all the functions are equally probable since we don’t know anything about the true reward function).
Then, it continuously asks queries to the human, in order to update that probability distribution and make it more certain about the true reward. A query is defined as a small subset of the proxy reward space. The answer to the query is a single element of that subset, which the human believes incentivizes the best behavior, compared to the other elements of the query (it compares suboptimal behaviors, not the optimal one).
After each query, it uses Bayesian inference to update the probability distribution based on the answer to that query. To do that, it uses a Q learning planner that optimizes trajectories, in the training environment, given each element of the query as the reward function. It then computes the feature expectations of these trajectories and uses these and the answer to the query to update the probabilities.
The queries are chosen such that the expected information gain from the answer to the query is maximal. The information gain is measured using various metrics, one of which is the entropy of the probability distribution over the true reward function.
There are multiple ways this selection can be done, but the one I used on my project, as it is more efficient and less time-consuming, is the following: as long as the query size is less than a predetermined constant (initially it is empty), we take a random vector of weights, and then take gradient descent steps such that the information gain when these weights are the answer to a query is maximal.
After each query, the performance is evaluated by running the Q learning planner, using the true reward function and the average of the probability distribution computed, and measuring their difference in the training environment and some test environments.
My approach
We start with the same given data as AIRD: the true reward space and the proxy reward space.
I also define a query, and update the probabilities using Bayesian inference, the way AIRD does it (I used the AIRD code for query selection and Bayesian inferences).
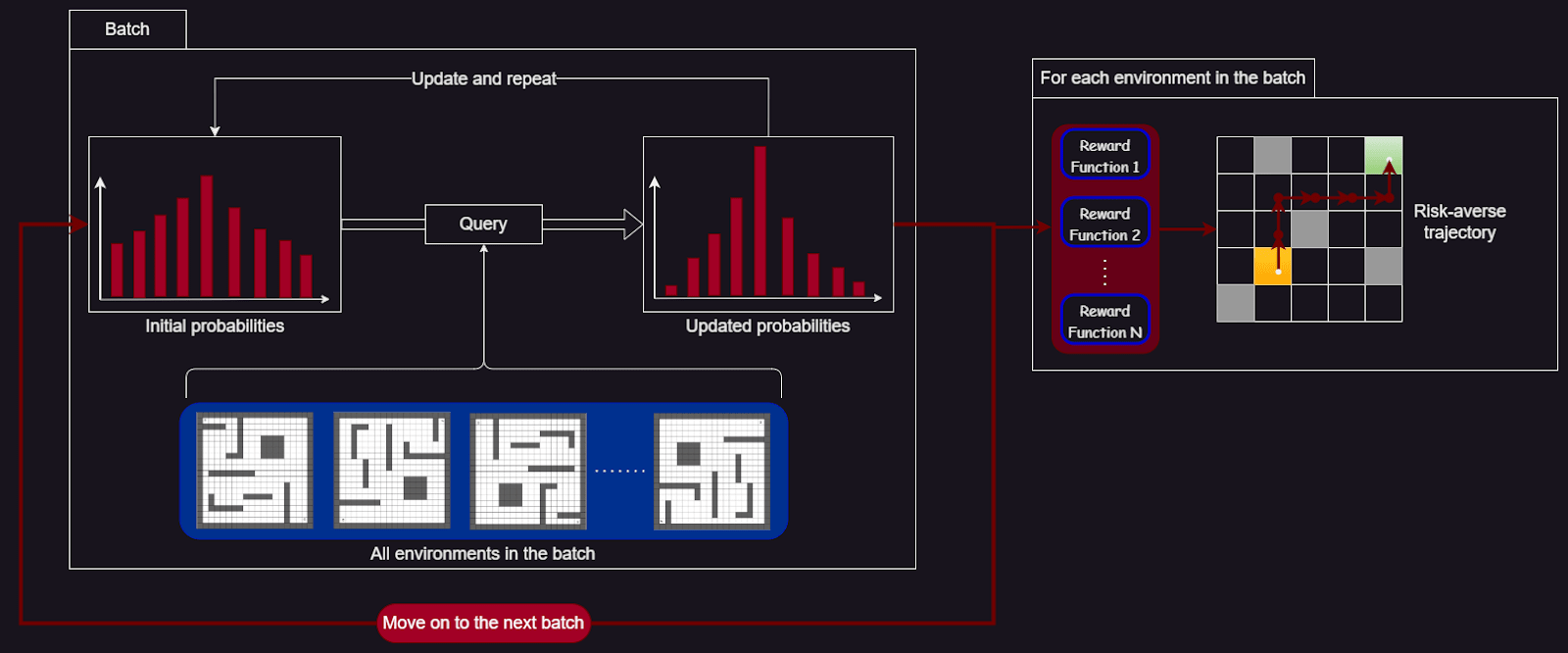
There are some batches, with a specific number of environments in each batch. There is a constant (big) set of test environments for evaluation of the performance. I also keep track of the probability distribution over the true reward function, which initially is a uniform distribution.
I also made two planners, using Q learning, that have as an input a set of weights:
The non-risk-averse (unsafe) one, which has as the reward the average of the rewards on the state with each weight sample.
The risk-averse one, which penalizes the variance of the rewards computed using the weight sample and the state’s features, in two ways:
By taking the worst-case reward
By subtracting the variance multiplied by a coefficient
For each batch, I do the following:
Repeat (for a constant number of iterations) the query process of AIRD: I find the query from which the information gain of the probability distribution is maximal. The difference with the previous query process is that for each reward function in the query, for each environment in the batch:
I take the initial probability distribution.
I answer the query to that specific environment.
I apply the reward function to the unsafe planner and get the feature expectations.
Use the feature expectations to update the probability distribution.
Update the initial probability distribution using this inference and move on to the next environment in the batch.
Update the initial probability distribution, so it will be transferred to the next batch.
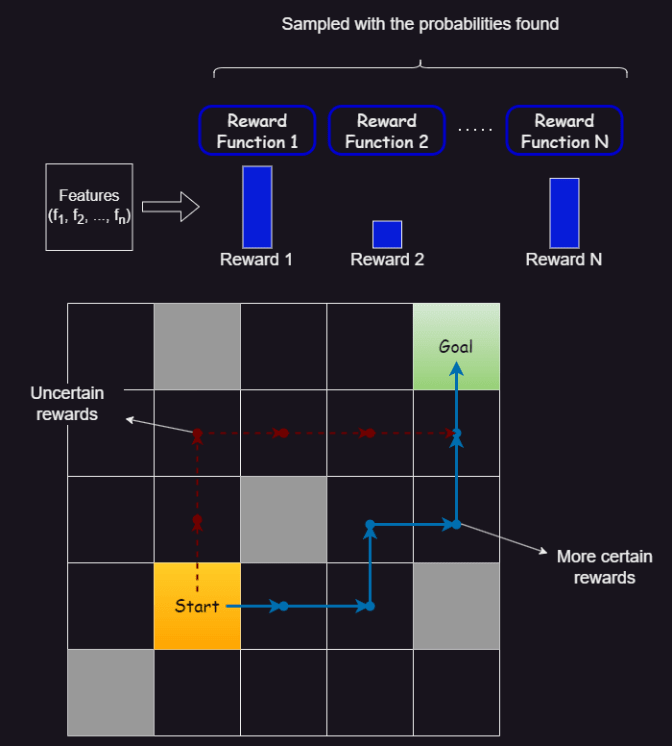
Sample a set of weights from the distribution over the reward function, and compute a risk-averse policy using the respective planner.
Evaluation
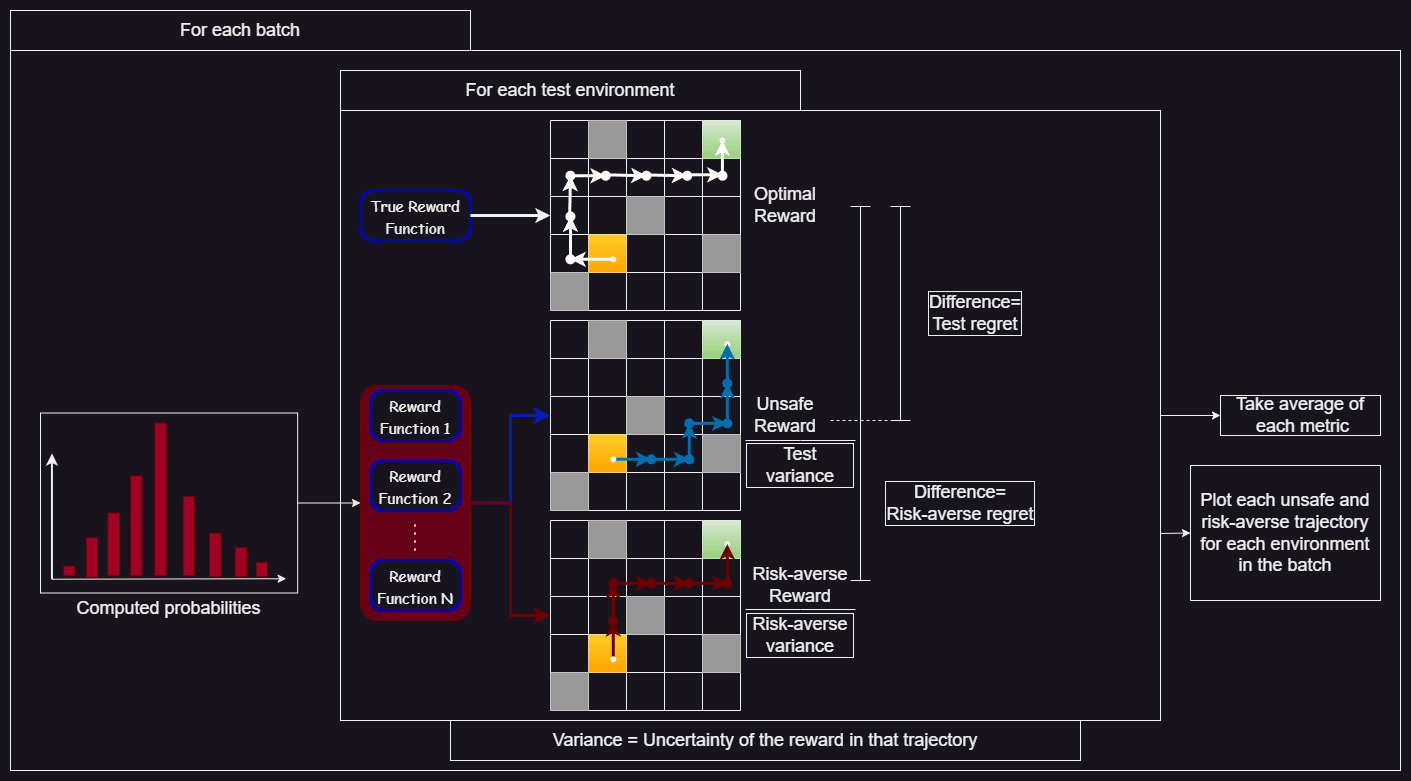
After each batch, for each test environment, I computed the total reward of the risk-averse planner and that of the unsafe one. I also computed the optimal reward by giving the planner the exact true reward function.
Then, I computed the following metrics (the “-” sign means difference of total reward):
Test and risk-averse variance = sum of variances of the rewards in trajectory computed using the unsafe and risk-averse planner
I then took the average of the above metrics over the test environments.
I also plotted the trajectories of both planners in each environment of the batch.
The X-axis of the graphs is the number of total Bayesian inferences (updates of the reward probabilities), which is the number of batches*number of queries for each batch*number of environments in each batch.
I performed experiments, by varying:
Number of batches
Number of environments in each batch
Number of queries for each batch
The method used for risk-averse planning:
Subtracting the variance with coefficient 1
Subtracting the variance with coefficient 100
Worst-case with 10 reward samples
Worst-case with 100 samples
I also collected data on the AIRD paper’s method, for comparison.
Results
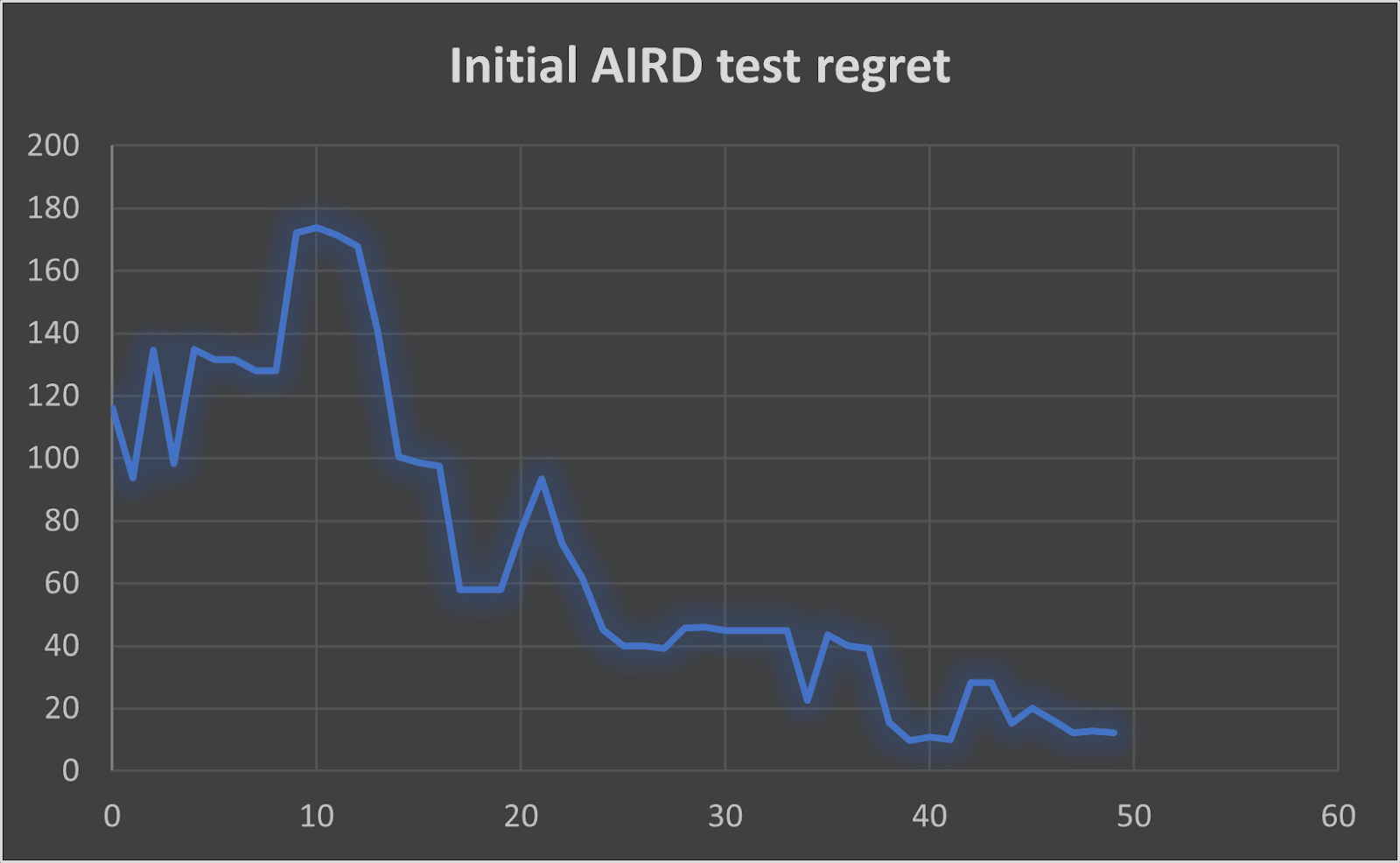
Initial AIRD
In the initial AIRD paper, using the same query-choosing method as I did, the performance approaches optimal after ~50 queries (but it never becomes optimal, a single environment isn’t enough to understand the true reward function to its fullest)
RBAIRD performance
Using RBAIRD, the total number of inferences is lower than AIRD (~30), and it almost achieves optimal performance. This shows that there is much bigger information gain when combining behavior from many environments instead of many queries on just one environment (each environment can highlight different aspects of the policy of a specific reward function)
The number of queries can be even lower with big batches (~1-2 queries if we have 10 environments in each batch), so less human intervention is needed (even with answering the query to each environment, we have at most 15-20 answers needed, but gain perfect performance)
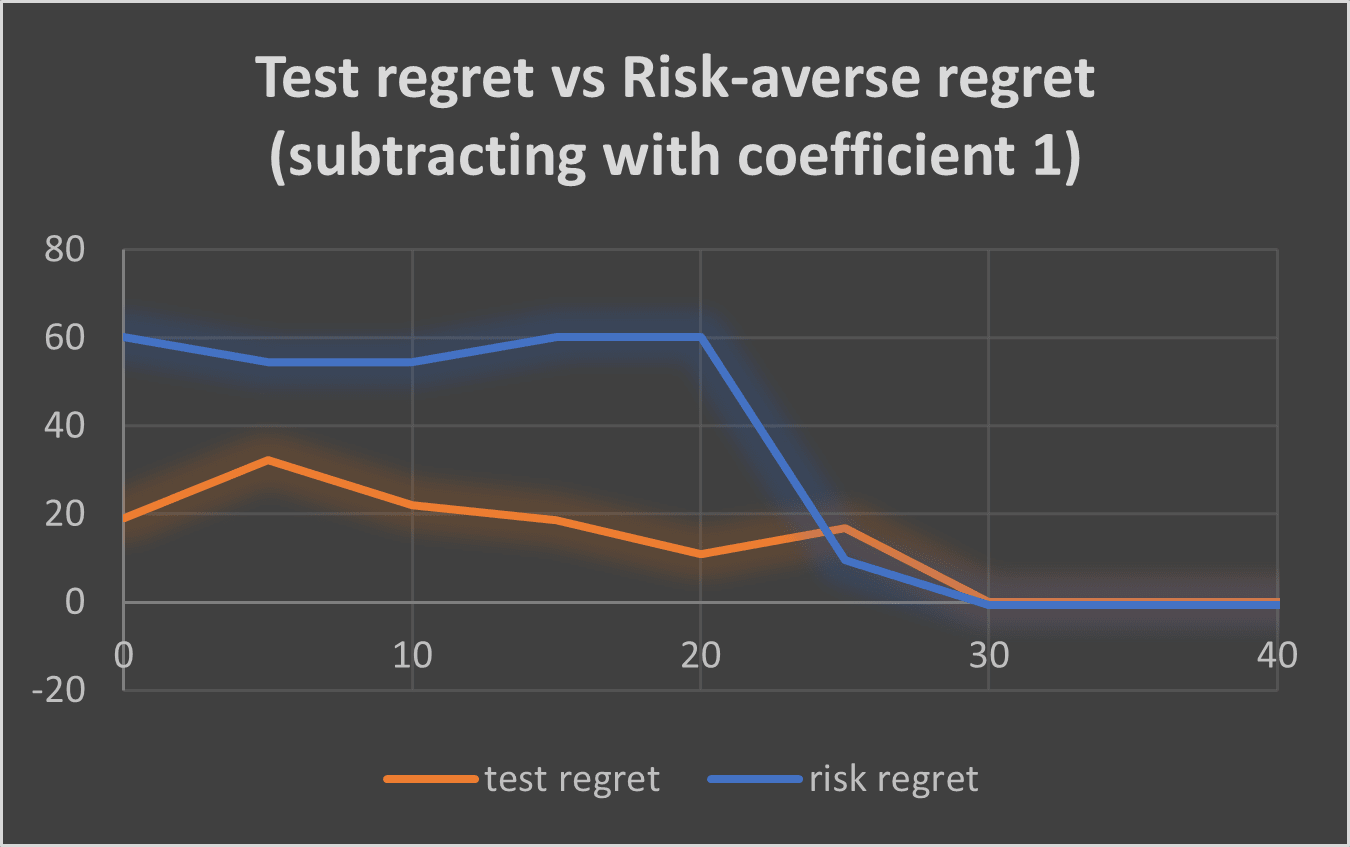
Risk-averse vs unsafe performance
When we are still uncertain about the true reward function, risk-averse performance is worse than the unsafe one. However, the risk-averse planner has a constantly lower variance than the non-risk-averse one. Both performances become optimal at the same time, when the true reward function is found.
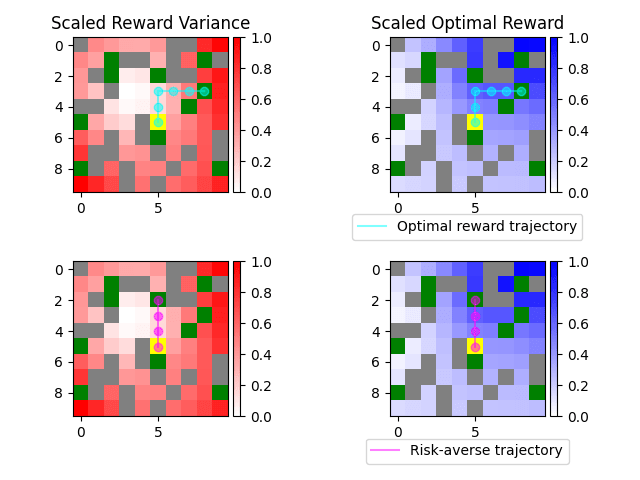
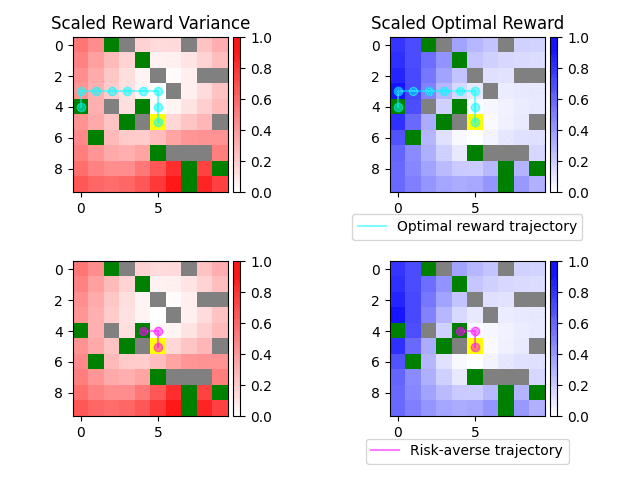
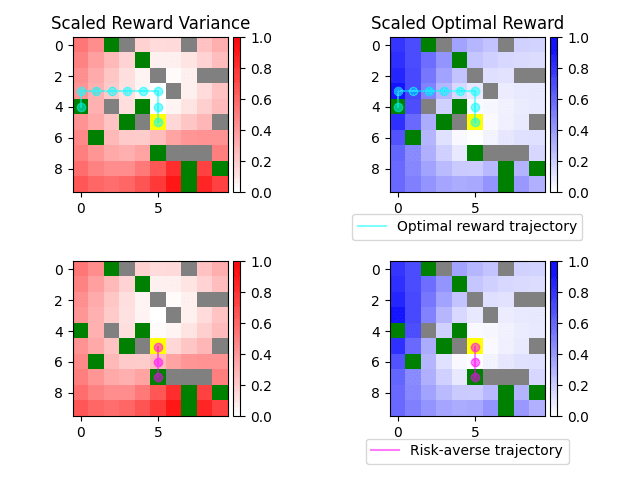
Trajectory Comparison
The risk-averse planner chooses a trajectory that is safer than the non-risk-averse one, while still reaching a goal and collecting as big of a reward as possible.
Here is a comparison of different risk-averse methods in the same environment:
Subtracting variance with coefficient 100
Worst-case with 100 samples
Adapting to new environments
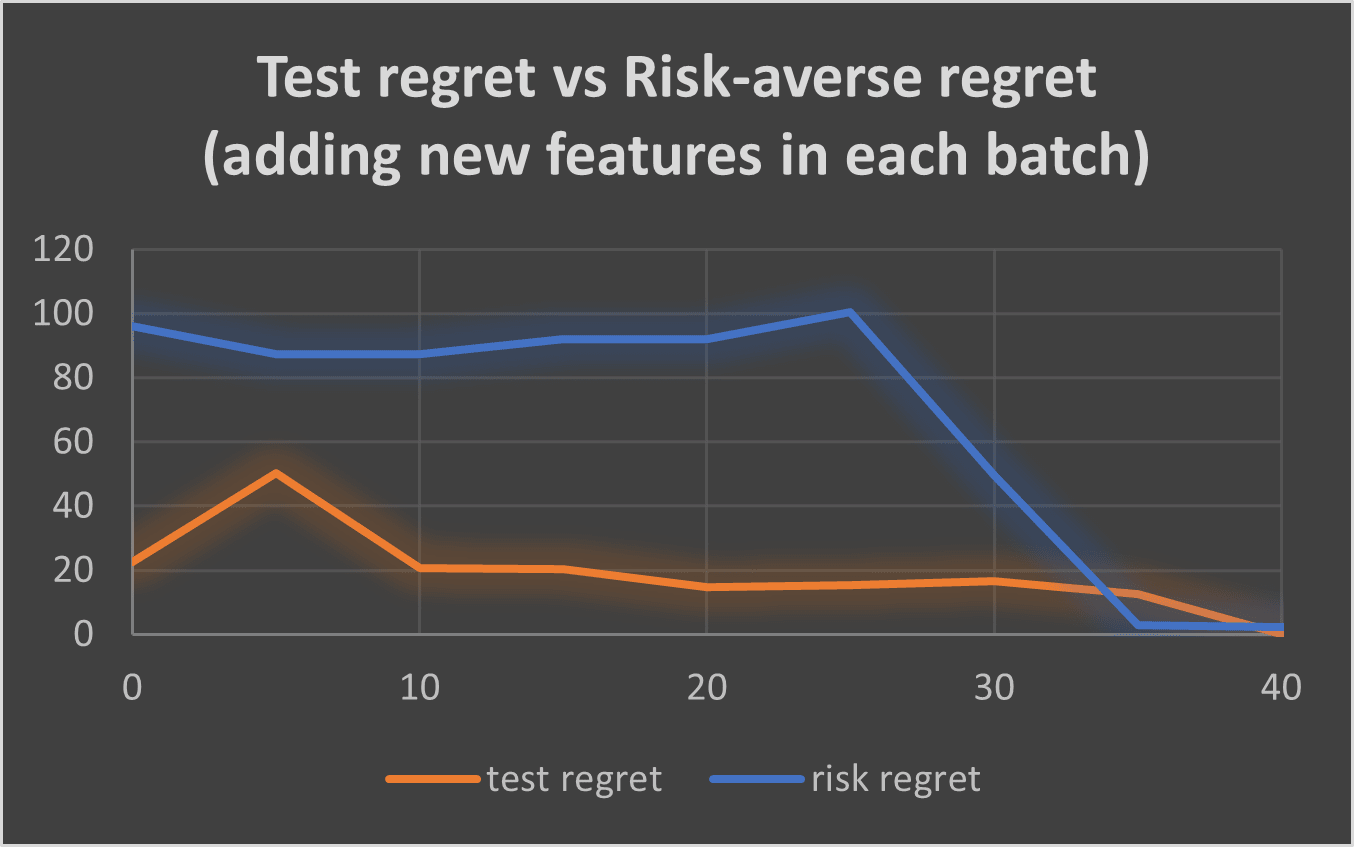
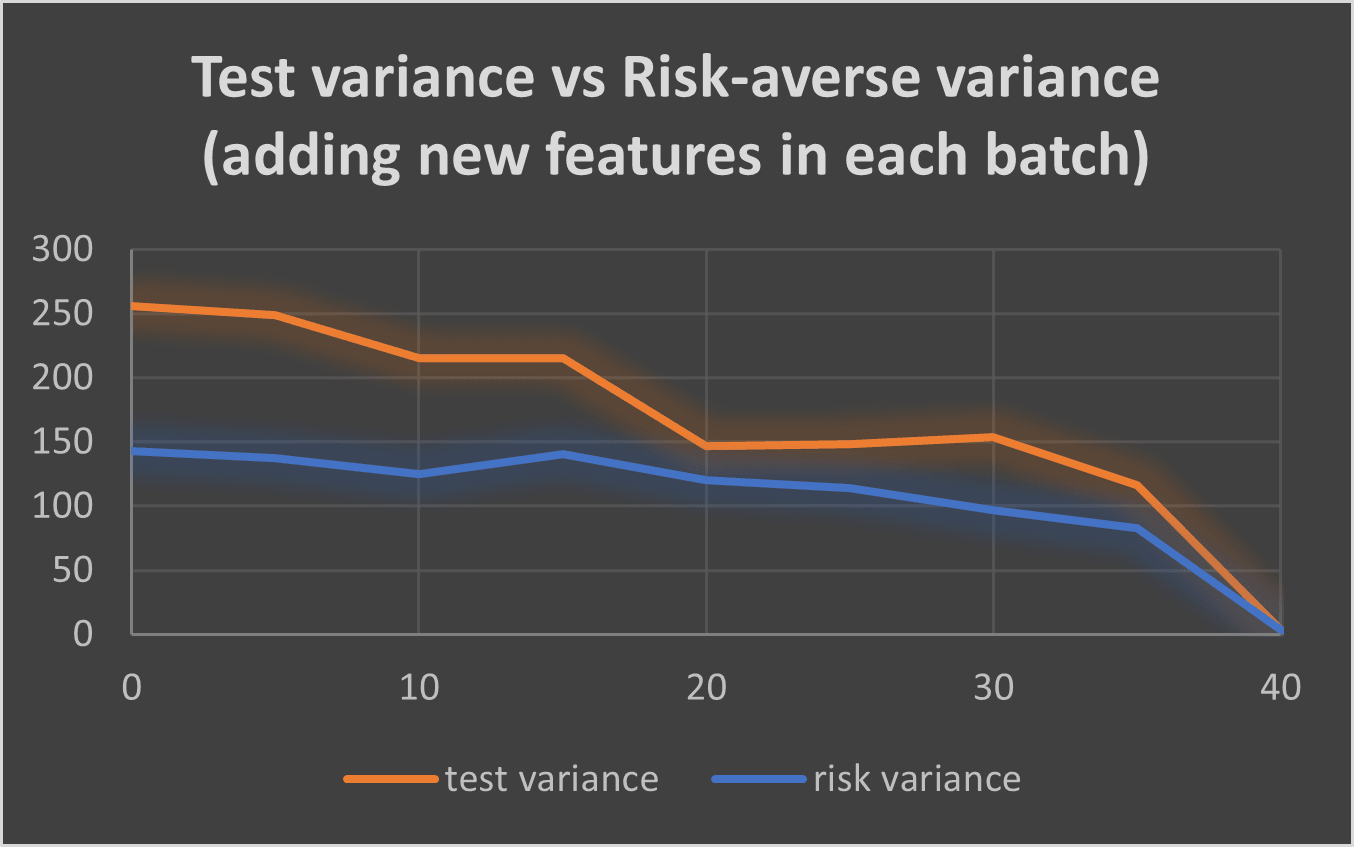
I performed an experiment where, instead of having all the features available in the training environments from start, I added a number of them, that were 0 in all the environments of the previous batches, to each new batch.
The total number of inferences was still ~40, similar to when we had all the features available from the beginning, and lower than AIRD, and with even only 2 queries per batch. This shows that RBAIRD is able to adapt to unforeseen scenarios quickly. Also, the risk-averse planner had about half the variance of the unsafe one, noting its importance in new environments and the safety it offers on them. AIRD didn’t have the capability to adapt to unknown environments, since it was only trained in one environment, and it ignored the possibility of new features appearing, often making risky decisions.
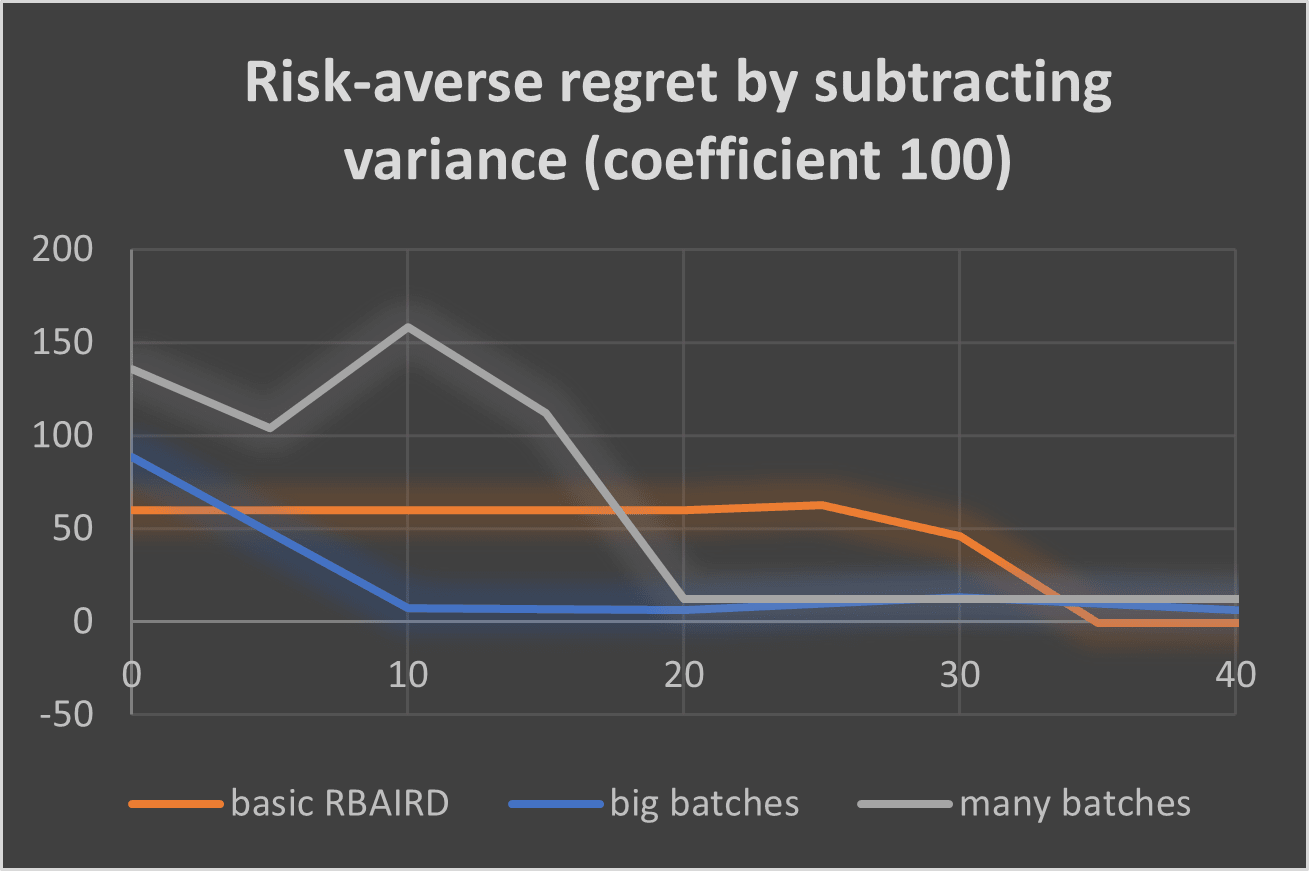
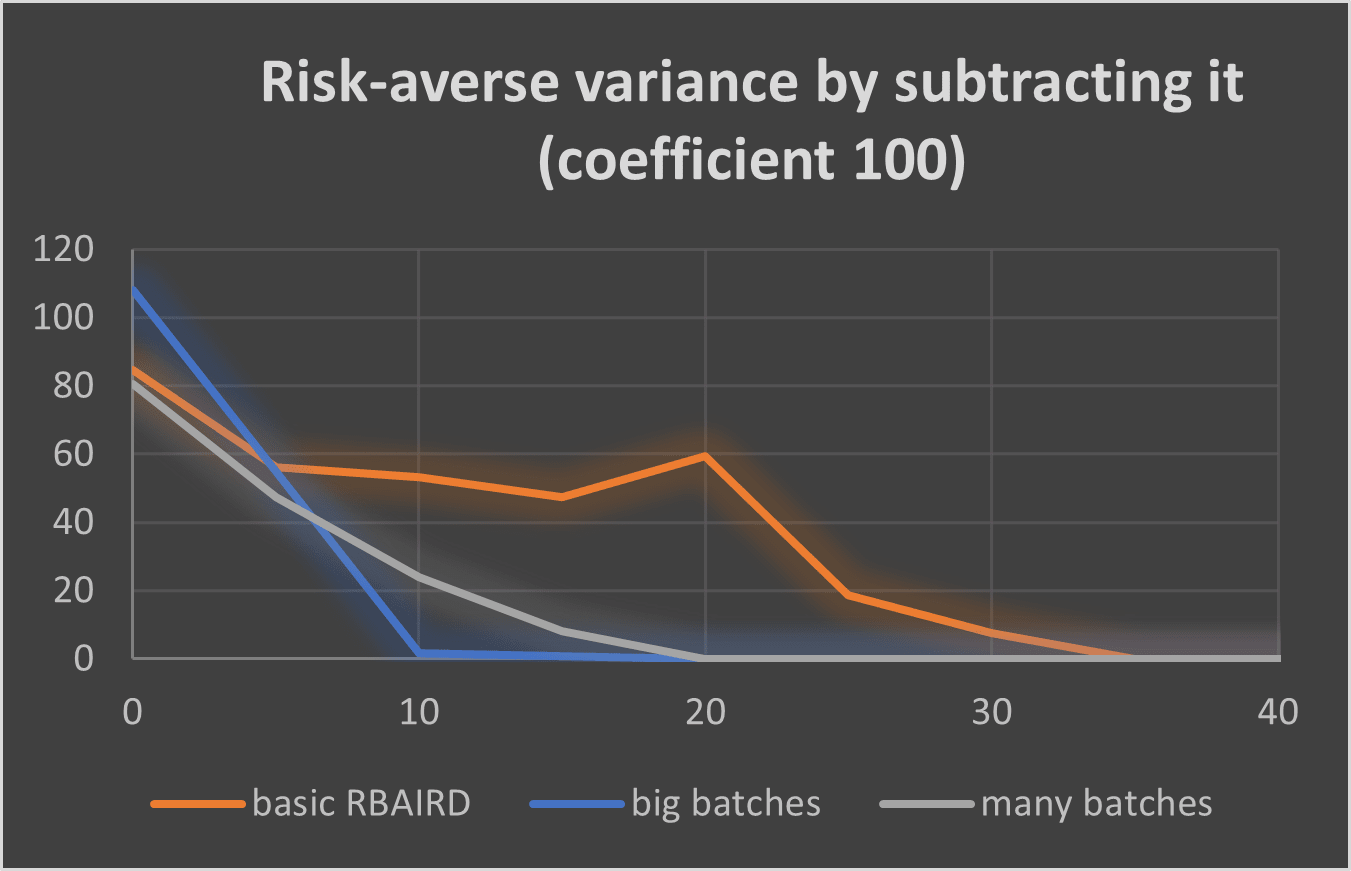
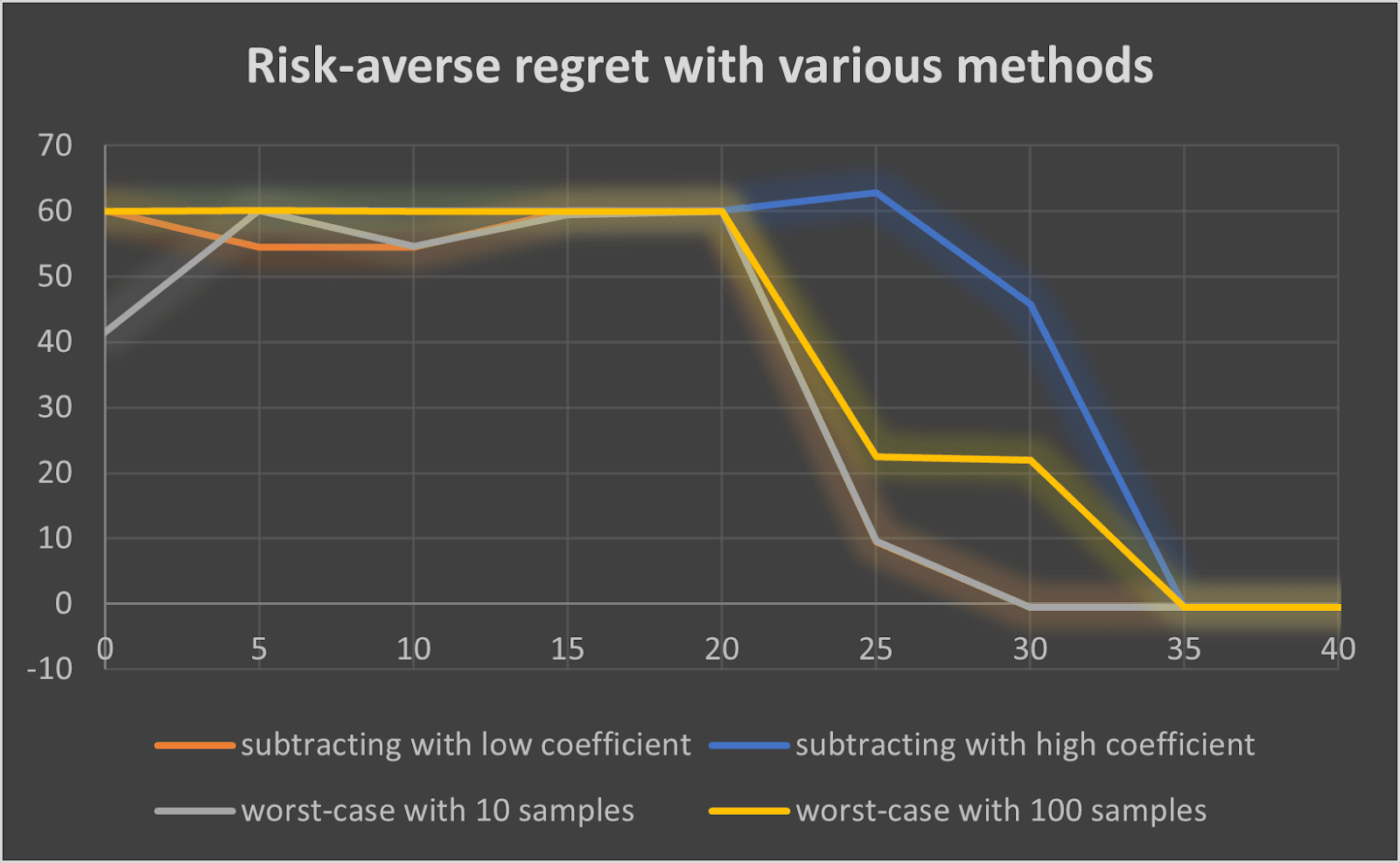
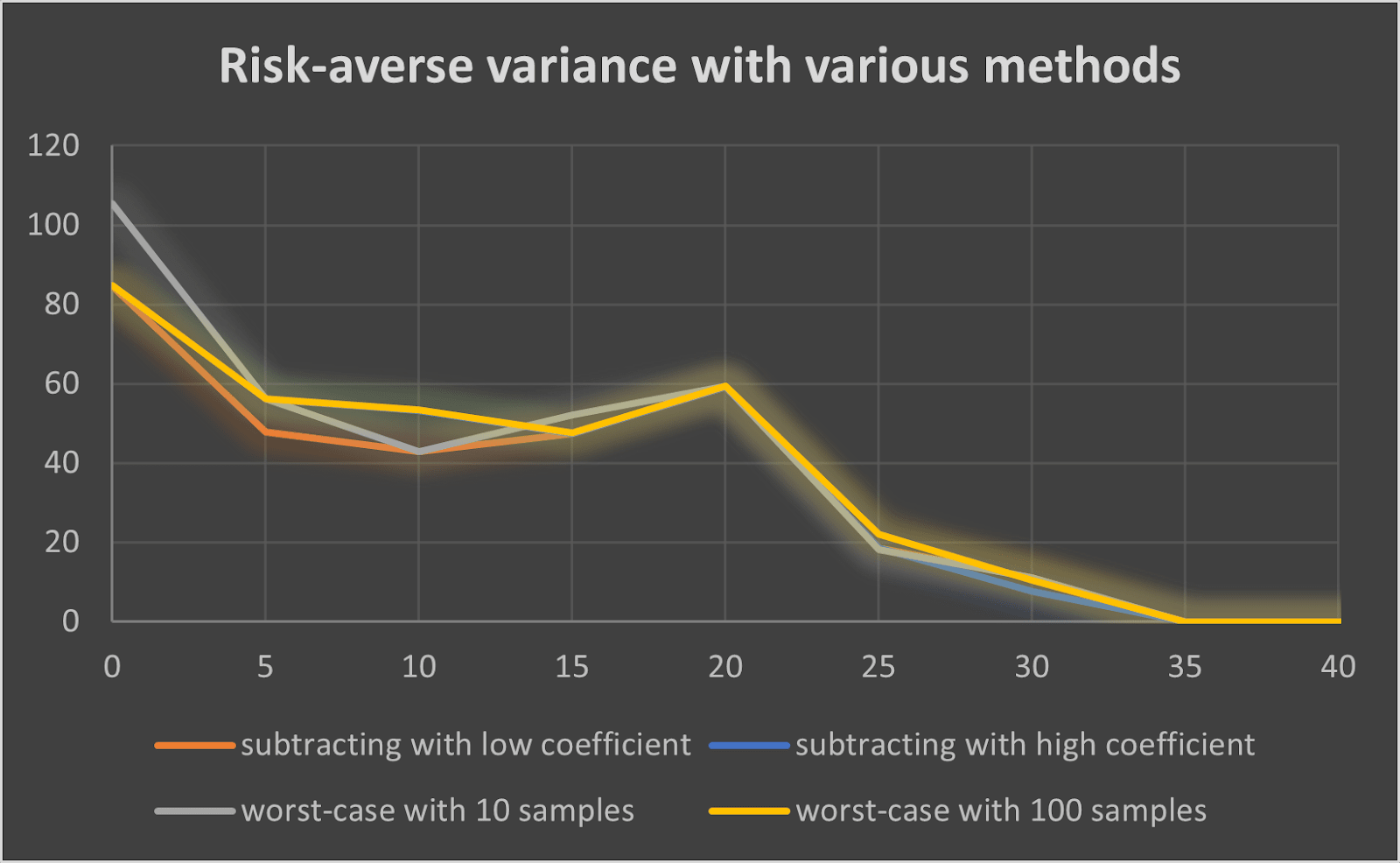
Comparing risk-averse methods
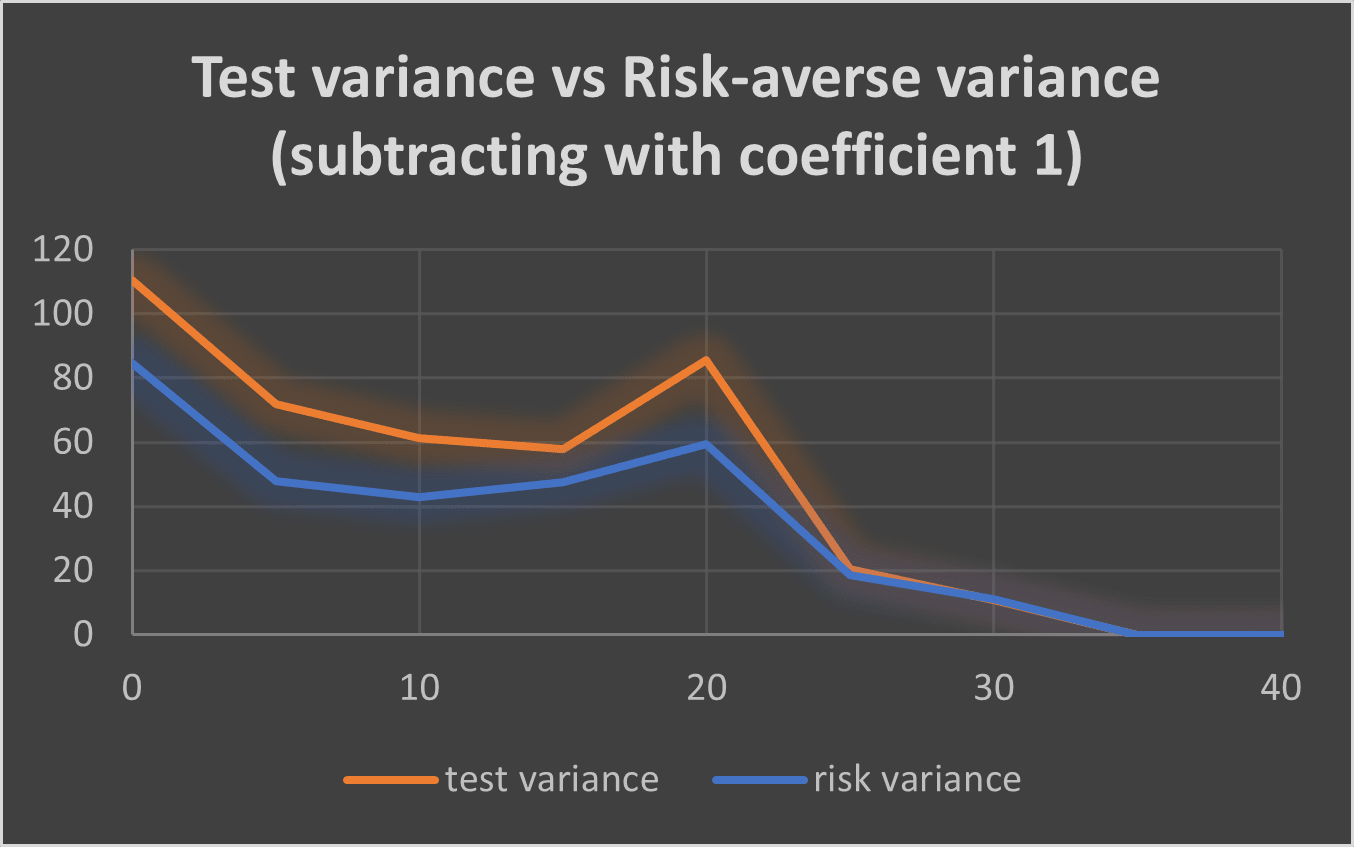
Here I plot the risk-averse regret and variance using different reward methods (subtracting with low coefficient and high coefficient means subtracting the variance with coefficients 1 and 100 respectively):
It seems subtracting with coefficient 1 is the most efficient method, both regarding the regret and the variance (this is without comparison to other more sophisticated methods).
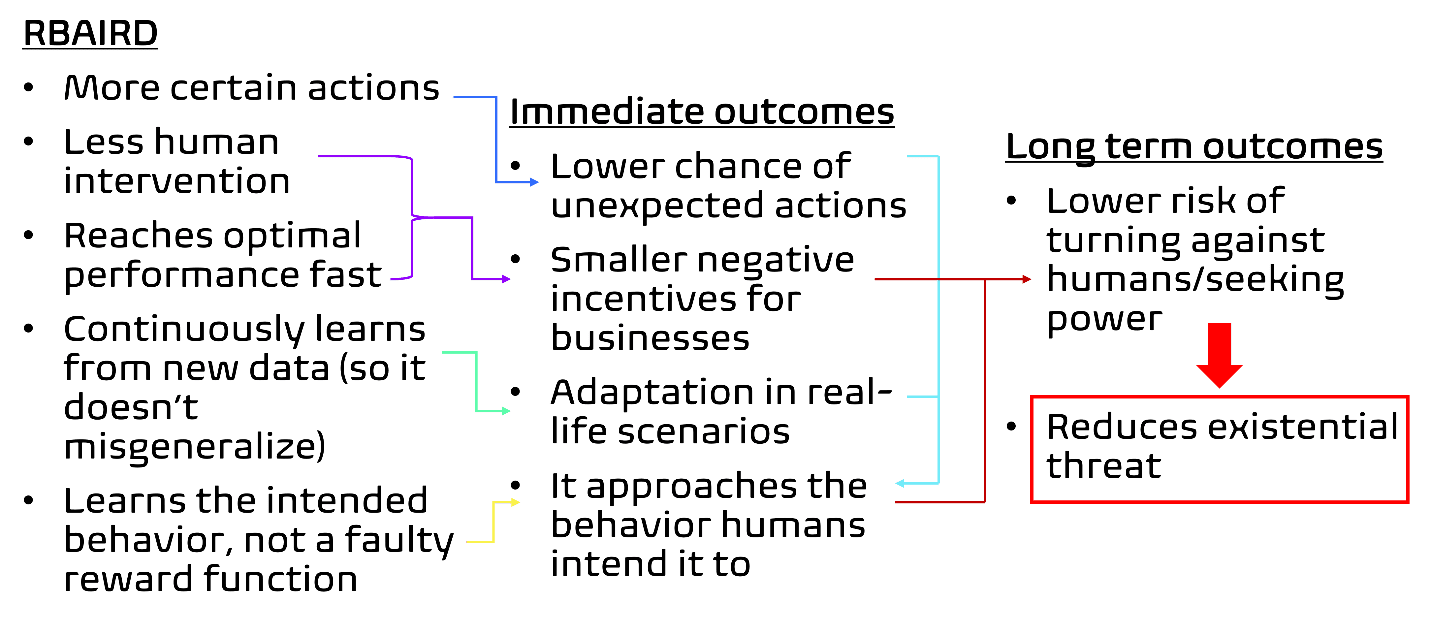
Theory of change
Project goals:
More certain actions:
The risk-averse planner highly values the variance of the rewards in each state, and the experiments showed that its actions are more certain than those of an unsafe planner.
Less human intervention:
The number of answers needed from the human is lower than the one of AIRD, and the number of queries even lower (but they need to be answered for each environment). Having the same query for all environments can help when a reward function clearly incentivizes a certain behavior that is independent of the environment.
Reaches optimal performance fast:
After a small number of queries and answers, the performance is almost the same as that of an unsafe planner that knows the true reward function.
Continuously learns from new data, doesn’t misgeneralize:
The experiment where I added new features in each batch shows that RBAIRD was able to adapt to these new environments and learn the true reward function in almost the same number of queries, while making choices that avoided these new features in the beginning (less variance)
Learns the intended behavior:
The fact that the human chooses from a set of suboptimal reward functions which one is better and the process learns from these answers, shows that it doesn’t need a human-made faulty reward function, but learns the low-level patterns of behavior that each suboptimal reward function incentivizes. Then it constructs a reward function that incorporates all these behaviors.
Immediate outcomes:
Lower chance of unexpected actions:
Since my approach values the uncertainty of its actions, it prefers taking actions that it knows from previous environments are good, so they will not be unexpected.
Smaller negative incentives for businesses:
Since RBAIRD needs fewer answers from humans and its performance becomes almost optimal after a short time, the cost of aligning the system is smaller, while its alignment is better, as it adapts to new environments and makes safe actions.
Adaptation in real-life scenarios:
My approach continuously learns from new environments and unforeseen features in a short time. Thus, it is able to learn how to deal with the new aspects of the environment safely and adapt to real-life scenarios.
It approaches the behavior humans intend it to:
The planner becomes almost certain, has the same trajectory as the true reward function in most environments (their rewards are the same), and that function has the humans’ intended behavior. So, the system’s behavior approaches the intended one.
Long-term outcomes:
Lower risk of turning against humans/seeking power:
As businesses have smaller negative incentives to adopt that model, it is easier to persuade people to adopt this approach for real-life, potentially dangerous systems. These systems will approach the intended, from the humans, behavior and this will lower the risk of them turning against humans or seeking power, as these actions will be penalized in the true reward function.
Reduces existential threat:
If there is a lower risk of an AI turning against humans, they will be able to have more control over it. This reduces the immediate risk of human extinction due to the AI causing great harm, and the negative influences the AI can have in society in general, which can indirectly be an existential threat.
Next steps
Improving efficiency/usability
Other query selection methods
In this project, I only used one query selection method from those that are used in the AIRD paper, the one where the query is increased by size one each time, after randomly sampling some weights and optimizing them. I also only used queries of size 5.
However, other query methods are more efficient in the original paper, but more computationally expensive, so I wasn’t able to run them on my PC. I will try to optimize them and integrate them into RBAIRD (my approach), in order to compare their efficiency and performance, and maybe achieve better results.
More efficient risk-averse planning method
Until now, I have only tried using some simple, per-state, risk-averse reward functions, that simply take the worst-case scenario or penalize the variance in some way. However, they lead to the so-called blindness to success, and there are more efficient, but more complicated, methods that improve that aspect and gain performance-wise, and possibly reduce the expected variance even more. I will try to implement these, and evaluate their performance, regarding the maximum reward and the uncertainty of the actions.
Answering each query in multiple environments at once
What the code currently does is it makes a single query in each iteration, that is optimized along all environments, but then gets an answer for each environment (total number of answers = number of environments in each batch, but we have the same query in each environment). This answer depicts which function performs better in that specific environment, relative to the true reward function.
What would be more efficient, is to answer each query once for all environments, showing which reward function shows better behavior in general, not specific performance to that environment. This would greatly reduce the number of query answers needed, and maybe make it less computationally expensive. However, then the human has a more difficult task to do, and the selection is a bit ambiguous, since there is no clear measure of “better behavior” about a reward function, since each one incentivizes different behaviors to a different extent.
Making an interactive query-answer environment
Currently, the program does not actively ask for a human to answer each query, but it is given the true reward function and predicts the expected answer based on that. Something that would demonstrate how a human would be able to judge and compare different reward functions, is to make an interactive environment where the human can answer the query, given various types of information.
It could show the trajectories that are computed based on each reward function, in a single or multiple environments (maybe choose the environments where their behavior would differ a lot, or where a single feature is prevalent in each environment). Also, it could provide various metrics about the performance of the reward function regarding various features, or some other high-level patterns that are observed, but this is a bit ambiguous and related to mechanistic interpretability. It could also provide the risk-averse and the unsafe performance of the planner in various steps of the query process, in order for the human to be able to judge what behavior the agent adopts (as a safety measure)
Long-term actions
Write a research paper on the approach, describing and evaluating the process and the above changes, changing various parameters, and demonstrating its capability to improve various aspects of AI Alignment.
Work on adapting it to real-life systems, e.g.:
Household cleaning robots, to take the trash out without causing damage when encountering a new object or a new house (unknown environments)
Autonomous farming tractors, in order to avoid unknown surfaces, destroying new plants, or getting stuck in a certain place due to difficult conditions.
Follow a major related to AI, specialize in that sector, and work on improving AI alignment and specifically applying the knowledge I gained from the project to other subproblems of it.
Related work/References
Barnes, B. (n.d.). Imitative generalisation(Aka ’learning the prior’). Retrieved August 27, 2023, from https://www.alignmentforum.org/posts/JKj5Krff5oKMb8TjT/imitative-generalisation-aka-learning-the-prior-1
Casper, S., Davies, X., Shi, C., Gilbert, T. K., Scheurer, J., Rando, J., Freedman, R., Korbak, T., Lindner, D., Freire, P., Wang, T., Marks, S., Segerie, C.-R., Carroll, M., Peng, A., Christoffersen, P., Damani, M., Slocum, S., Anwar, U., … Hadfield-Menell, D. (2023). Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv. https://doi.org/10.48550/arXiv.2307.15217
Hadfield-Menell, D., Dragan, A., Abbeel, P., & Russell, S. (2016). Cooperative inverse reinforcement learning. arXiv. https://doi.org/10.48550/arXiv.1606.03137
Hadfield-Menell, D., Milli, S., Abbeel, P., Russell, S., & Dragan, A. (2020). Inverse reward design. arXiv. https://doi.org/10.48550/arXiv.1711.02827
Langosco, L., Koch, J., Sharkey, L., Pfau, J., Orseau, L., & Krueger, D. (2023). Goal misgeneralization in deep reinforcement learning. arXiv. https://doi.org/10.48550/arXiv.2105.14111
Mindermann, S., Shah, R., Gleave, A., & Hadfield-Menell, D. (2019). Active inverse reward design. arXiv. https://doi.org/10.48550/arXiv.1809.03060
Preventing an AI-related catastrophe—Problem profile. (n.d.). 80,000 Hours. Retrieved August 27, 2023, from https://80000hours.org/problem-profiles/artificial-intelligence/
Research, D. S. (2018, September 27). Building safe artificial intelligence: Specification, robustness, and assurance. Medium. https://deepmindsafetyresearch.medium.com/building-safe-artificial-intelligence-52f5f75058f1
Research, D. S. (2019, October 10). Designing agent incentives to avoid side effects. Medium. https://deepmindsafetyresearch.medium.com/designing-agent-incentives-to-avoid-side-effects-e1ac80ea6107
Shah, R., Krasheninnikov, D., Alexander, J., Abbeel, P., & Dragan, A. (2018, September 27). Preferences implicit in the state of the world. International Conference on Learning Representations. https://openreview.net/forum?id=rkevMnRqYQ¬eId=r1eINIUbe4
Specification gaming: The flip side of AI ingenuity. (n.d.). Retrieved August 22, 2023, from https://www.deepmind.com/blog/specification-gaming-the-flip-side-of-ai-ingenuity
Vika. (n.d.). Paradigms of AI alignment: Components and enablers. Retrieved August 27, 2023, from https://www.lesswrong.com/posts/JC7aJZjt2WvxxffGz/paradigms-of-ai-alignment-components-and-enablers
11
More posts like this
287
Sam Altman’s Chip Ambitions Undercut OpenAI’s Safety Strategy