Comments
Interpretable Analysis of Features Found in Open-source Sparse Autoencoder (partial replication)

12 min readAug 28, 2024
10


This project was carried out as part of the “Carreras con Impacto” program during the 14-week mentorship phase. You can find more information about the program in this entry.
The objective of the project was to develop expertise in Mechanistic Interpretability by:
I'll focus more on the big-picture, intuitive overview of the concepts rather than in their formal mathematical details. The content of the explanations shouldn’t be taken as teaching material of some sort but rather a reflection of my understanding.
The structure of the post mimics the objectives, so if you are already familiar with Sparse Autoencoders and their role in Mechanistic Interpretability, start reading from the "Anthropic paper overview" section.
At its core, an artificial neural network is a mathematical function that transforms input data into output data. This transformation occurs through layers of interconnected nodes, or "neurons," each performing simple mathematical operations.
By pursuing interpretability, researchers aim to not only understand these systems but also to improve their reliability, address biases, and potentially design more efficient and powerful AI systems in the future.
The team behind the paper sought to derive monosemanticty the smallest non-interpretable by default model that there exists, a 1-layer Transformer.

As the image tells, they trained sparse, overcomplete autoencoders over the MLP activations of the model. Sparsity and overcompleteness are enforced because both intuitively lead to an interpretable disentanglement of the input, since the MLP activations are presumed to be in superposition.
An Sparse Autoencoder is mathematically defined by the following elements:
In the context of the paper, n is set to number of output neurons in the MLP layer,
whereas m
is variable, as the authors performed various runs with the parameter ranging from 512 to 131072.
After training the Sparse Autoencoders, monosemantic features were found. One of the principal lines of evidences for assessing monosemanticity are the so-called "detailed investigations", which are comprised of the following criteria:
The following criteria was used to rigorously evaluate whether a feature existed or not:
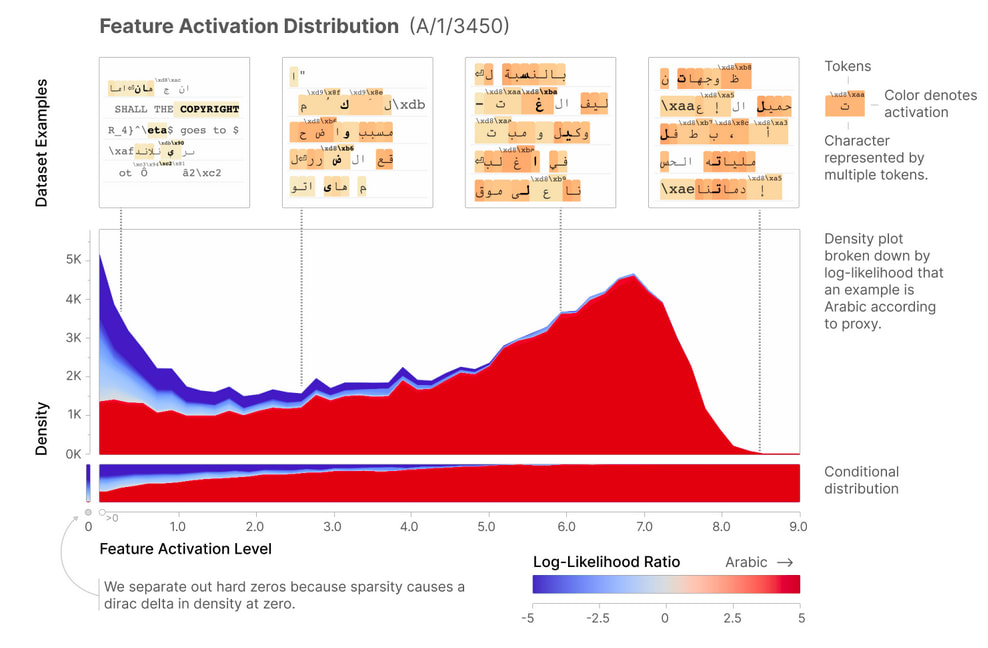
Specificity: The Anthropic team decided to use a continuous proxy for determining whether a sample from the training dataset corresponded to the feature itself. This approach is visualized in the Feature Activation Distribution graph for the Arabic Script feature (A/1/3450), where the x-axis shows the Feature Activation Level and the y-axis represents Density. The log-likelihood ratio, indicated by the colour gradient from blue to red, provides a nuanced measure of how strongly each sample activates the feature, allowing for a more precise analysis of feature specificity across the dataset compared to a binary classification.
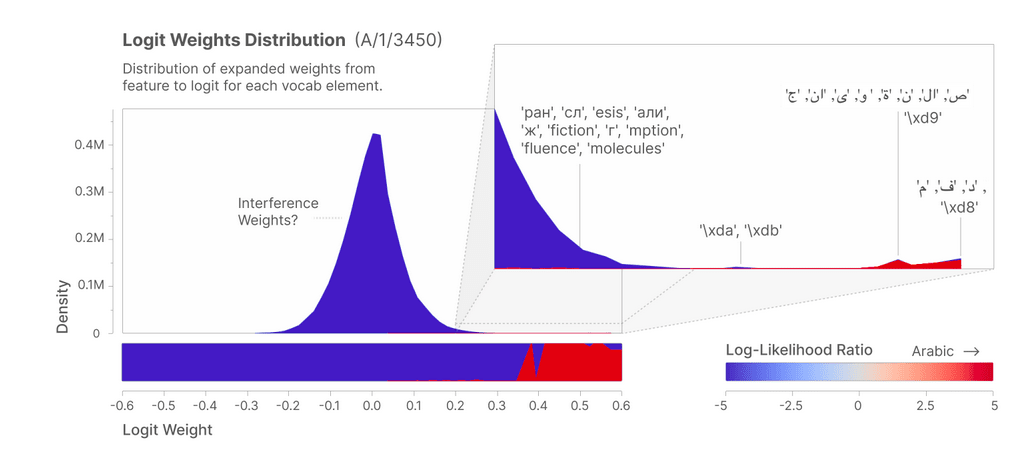
Downstream effects: as far as it can be told, a feature candidate can be just a learned pattern of the dataset and not a component affecting the next token prediction process. One way of achieving that is measuring the contribution of the feature to final prediction, by analysing which tokens are more likely to be predicted when the feature is present. The Logit Weights Distribution measures that.
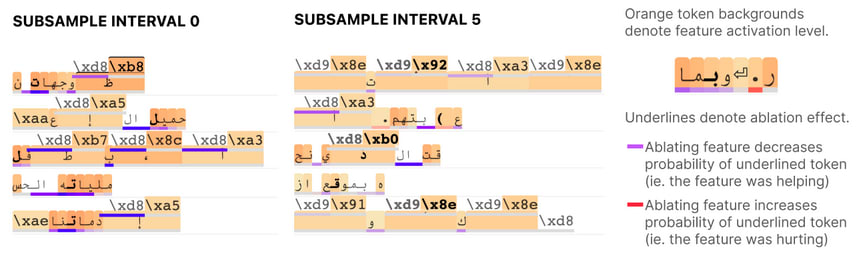
On another hand, ablating features (i.e. nullifying their impact on the inference process) and visualising the impact on next token prediction is other way of measuring the impact of the feature on the model itself. If a token is underlined in blue, it means that ablating the feature lessened the probability of having that particular as the next token. The contrary holds when the feature is underlined in red.
Not being a neuron: a feature can be specific, sensitive and dowstream-effective but it might be as well a neuron. A feature being a neuron would defeat the purpose of training an Sparse Autoencoder because that would mean the neuron is monosemantic and thus no disentanglement process was needed. To check this, the Anthropic team sought for the neuron whose activations were the most correlated with the Arabic script feature.
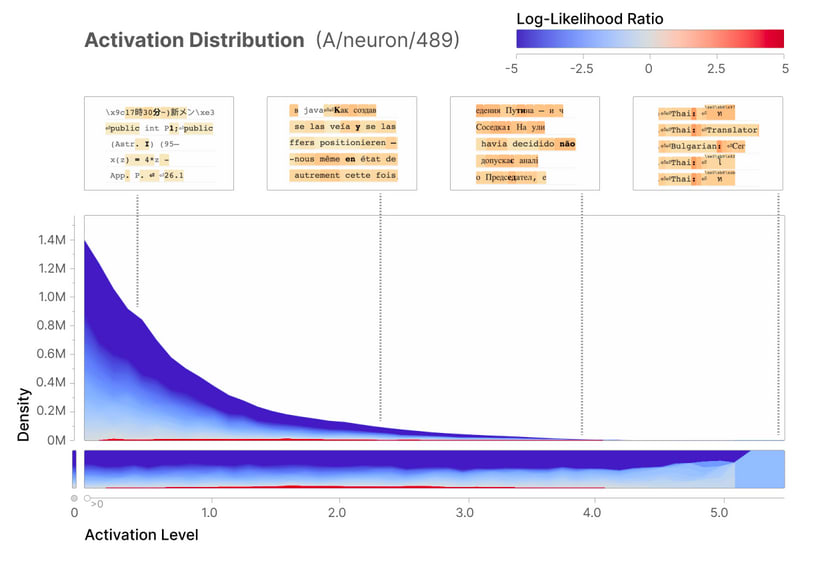
The found neuron was the #489, which isn't particularly sensitive nor specific to Arabic.
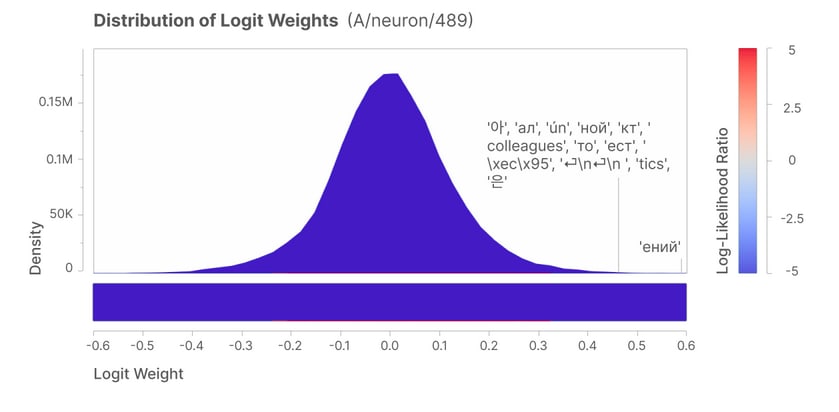
Moreover, the logits most likely to be predicted as per the Logits Weights Distribution do not correspond to Arabic. On , this shows that the feature #3450 isn't a feature but, more fundamentally, that it is a monosemantic unit not present in the original network.
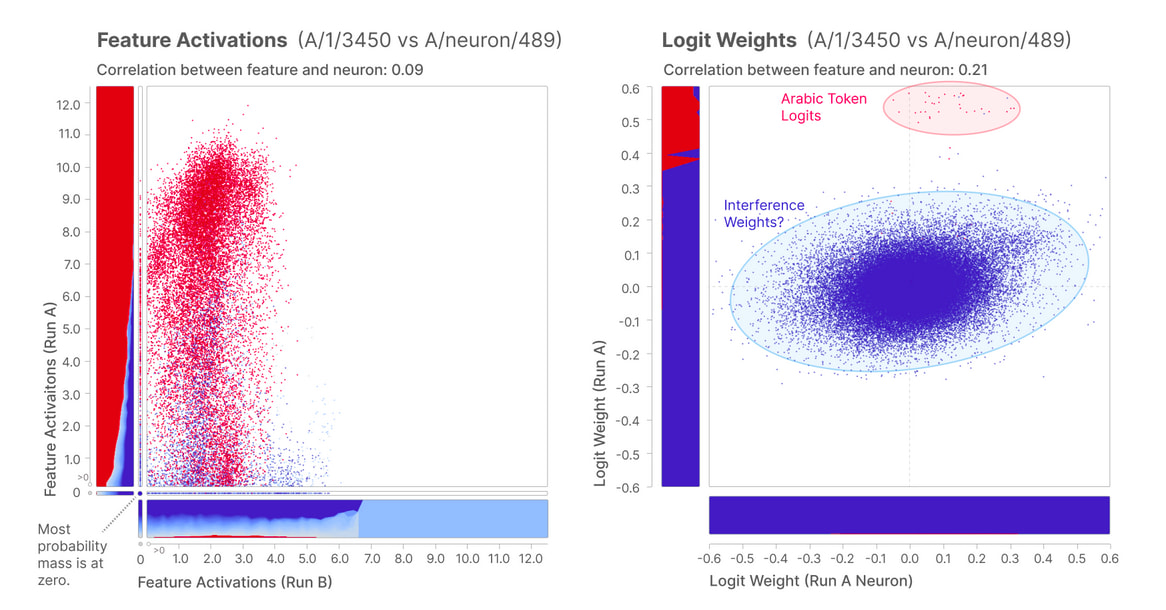
Universality: do there exist analogous or equivalent features in Sparse Autoencoders trained over other neural networks? If so, the case for feature candidate #3450 is furthered strengthened, as it would hint that features are "objective" (i.e. independent of model architecture, initialisation parameters, etc.) and is just a matter of computational resources and training time for Sparse Autoencoders to uncover them.
Remember that the Anthropic team trained more than one Sparse Autoencoders? They sought for Arabic Script features in the other runs and found that unit 1334 from the run B to have similar characteristics.
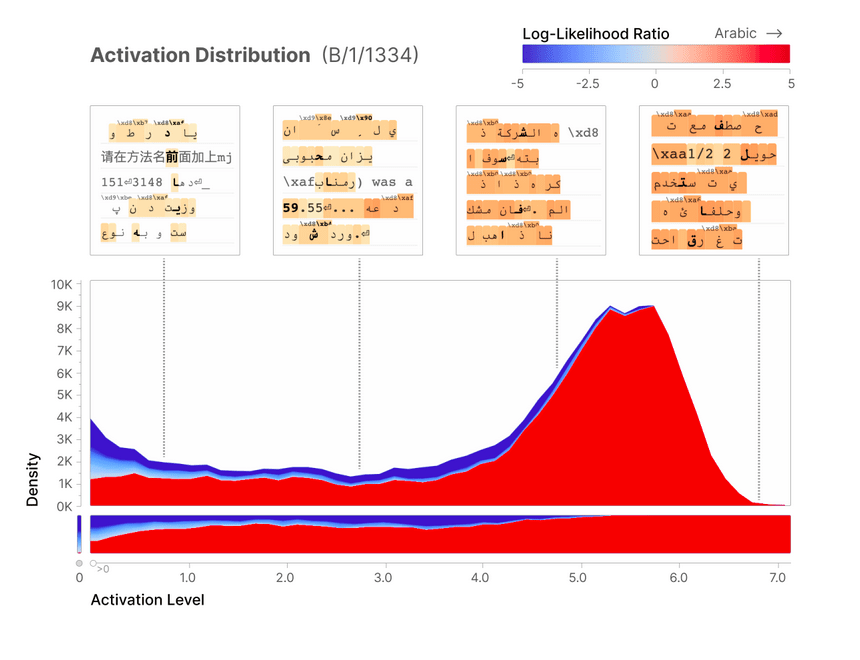
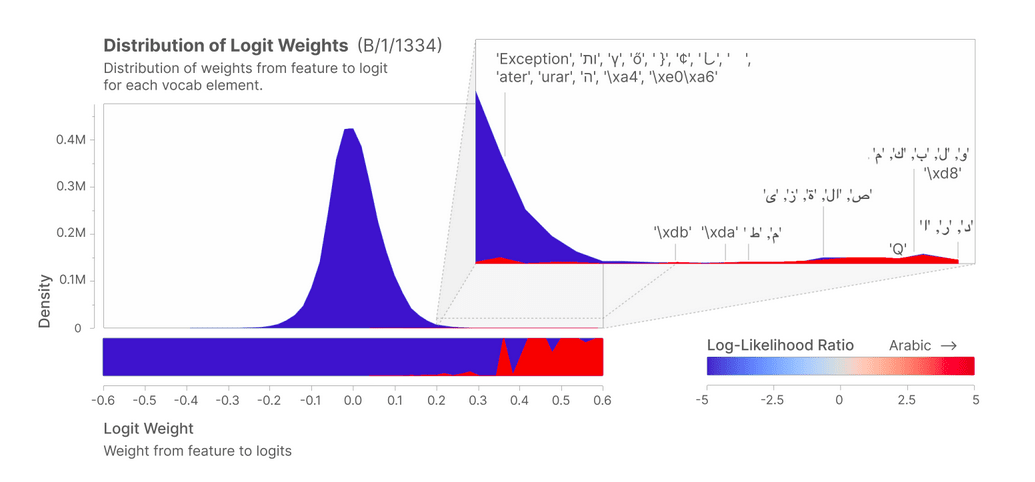
The Logit Weights distribution did also indicate that Arabic tokens are the most likely to be predicted when the feature is present.
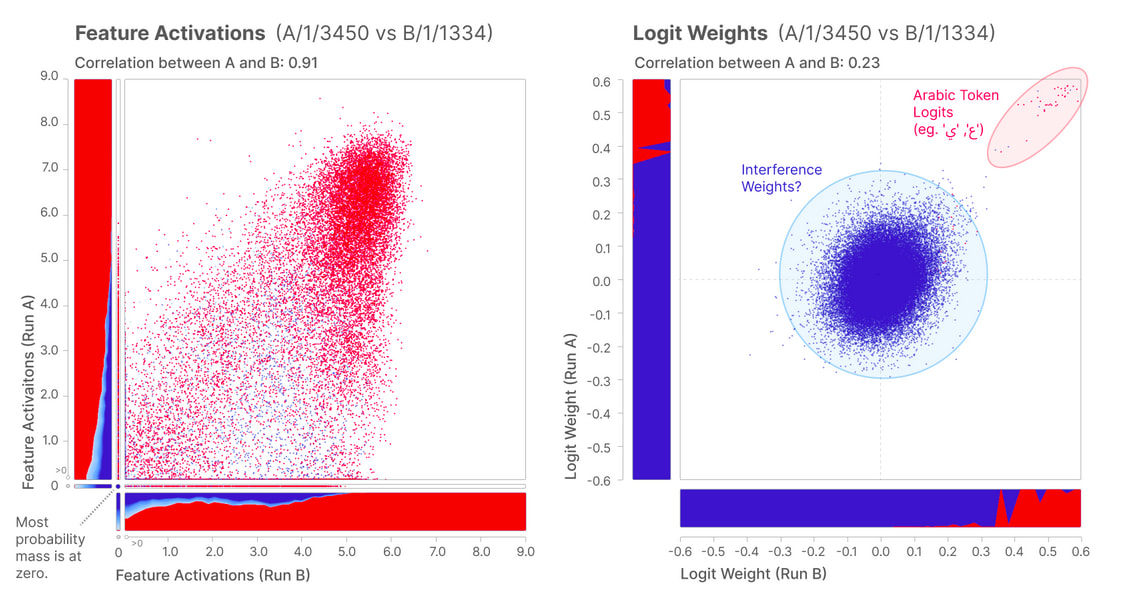
The correlation plots indicate that even though the Feature Activations distributions are similar, the Logit Weight distributions are not. However, the latter observation is expected in the sense that logits on the middle of each distribution are, almost by definition, non-related to Arabic script at all. The important part is that a cluster of arabic tokens is formed at the right ends of the distributions.
Are the findings of the Anthropic team replicable? In order to know it, I analysed an Sparse Autoencoder trained over the MLP activations of an open-source 1-layer transformer. Originally, I planned to replicate the experiments of the Anthropic paper (i.e. understanding the logic behind each experiment and generating the graphs myself) even though I was already aware that the sae-vis library existed but desisted in doing so because I was not advancing at a good pace. Therefore, sae-vis was used to aid the analysis.
The sae-vis library offers feature-centric and prompt-centric visualisations. The former generates information from a feature given its index whereas the latter generates information about the features that activate the most for a specific prompt.
My process for seeking interesting features was the following:
In this Google Colab notebook you can detail the search process was carried out, with each found feature having its own feature-centric visualisation.
Specificity
The feature exhibits the following activation histogram:
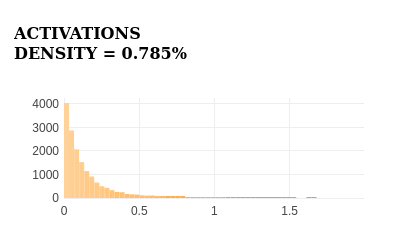

The feature strongly activates for full-stops, as seen in the activation histogram's right tail. It doesn't activate for any other tokens, demonstrating high specificity.
Sensitivity
The feature activates for all full-stops in top samples, indicating high sensitivity.
Downstream effects

The words with higher logits are primarily discourse markers - grammatical elements commonly found after full stops in natural language.
Feature is not a neuron
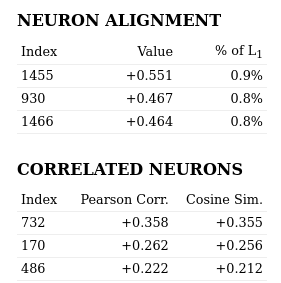
The low Pearson correlation values indicate this feature is not a neuron.
Specificity
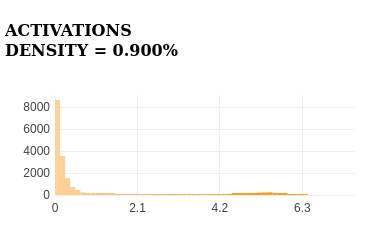

The feature strongly activates for the keyword for in top samples, demonstrating high specificity.
Sensitivity
The feature activates for all instances of the keyword for in top samples, indicating high sensitivity.
Downstream effects
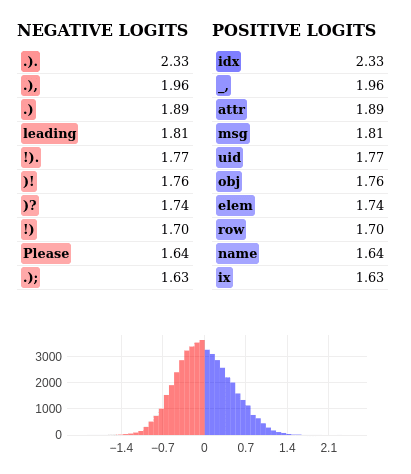
The words with higher positive logits are primarily Python-specific elements commonly used after for in loop constructs, while negative logits show punctuation and general language elements.
Feature is not a neuron
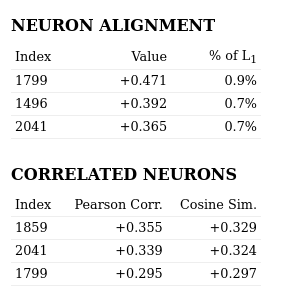
The low Pearson correlation values indicate this feature is not a neuron.
Specificity
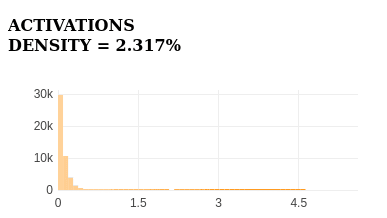

The feature strongly activates for the keyword else in top samples, demonstrating high specificity.
Sensitivity
The feature activates for all instances of the keyword else in top samples, indicating high sensitivity.
Downstream effects
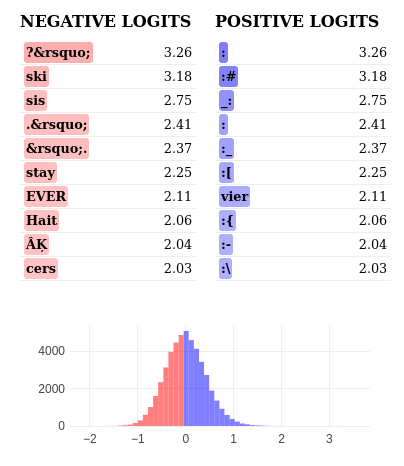
The feature shows balanced positive and negative logits, not clearly indicating Python else usage. Positive logits don't match typical else follow-ups, while negative logits include various unrelated tokens. This suggests the feature may capture broader syntactic patterns beyond simple else detection.
Feature is not a neuron
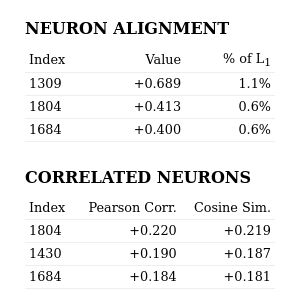
The low Pearson correlation values indicate this feature is not a neuron.
Specificity
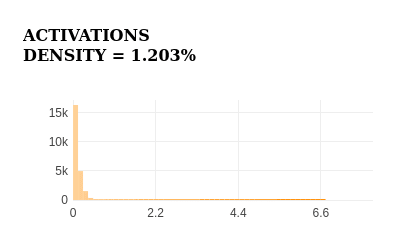

The feature strongly activates for the keyword import in top samples, demonstrating high specificity.
Sensitivity
The feature activates for all instances of the keyword import in top samples, indicating high sensitivity.
Downstream effects
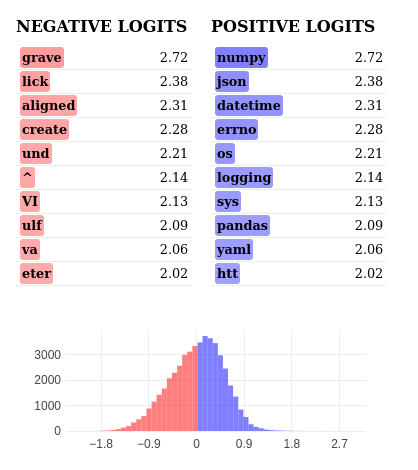
The positive logits strongly indicate Python-related libraries and modules (numpy, json, datetime, pandas), suggesting this feature detects Python import contexts. Negative logits show unrelated or partial words, further emphasising the feature's specificity to Python library imports.
Feature is not a neuron
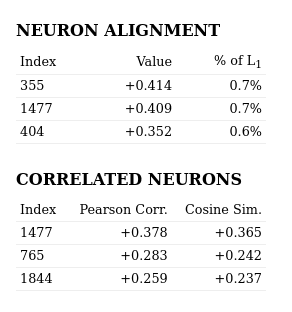
The low Pearson correlation values indicate this feature is not a neuron.
The original intent behind the project was to not only replicate Anthropic's findings but also replicate the visualisation artefacts themselves (activation histogram, logit distribution graph, etc.) even though I was aware of the existence of the sae-vis library. I thought this was a good idea since successfully executing it signalled that I had a robust understanding of the material. Moreover, I underestimated the amount of time it would take me to understand the source paper, set up the coding environment and reverse engineer the plots.
Eventually, I desisted on doing a full-scope replication and focused on getting simple but not less rigorous results. In future endeavours I will try to assess the value of doing a replication and leverage existing tools.
While trying to replicate Anthropic's paper plots, I fixated on getting every detail right and understanding how the plots were made from both the logic and visual aspects. This led me to spend considerable time figuring out details that, while interesting, were not central to the object-level phenomena.
Throughout a large part of the program, I hesitated to ask for help when faced with challenges. I used to think (and still do) that figuring out things on your own is an important skill to have but it is necessary to be mindful of when that mindset can be giving diminishing returns or halting progress altogether. If you have been wasting considerably more time than you think on doing an specific task, don't hesitate to ask for help. Even if the task could actually have been completed on your own on the initial timeframe, you could still nurture your intuition by hearing other's trains of thought and insights.
I realised the importance of validating core assumptions early in the project. In retrospect this element is overly obvious but sometimes people don't act on it out of confident. I had to core assumptions that weren't as black and white as I thought, meaning I should have spent more time exploring the nuances of them:
The extent to which each of those statements is true is contingent on career stage, relevance of the papers to replicate, what skills will be built and, more importantly, the level of detail (or the explicitness) of the source material's methodology.
Since the scope of the project was shortened due to some strategic errors in my part, a natural path to make the work more relevant is to enrich it with experiments that the Anthropic team did not conduct. Here is an example of an experiment worth replicating to characterise the nature of the found features.
Undertaking this project whilst having a broad understanding of the Transformer architecture and Superposition theory was perhaps too ambitious. As such, I plan to work through some parts of the ARENA curriculum, hoping to strengthen my understanding of the foundations for Alignment Research & Engineering.
After attending an ML4Good bootcamp, I became progressively more interested in holistic and big-picture discussions about AI Safety. That, coupled with the fact I'm still not sure my abilities would be better invested in the technical side (given my experience with this project), led me to enroll in the Governance track of BlueDot's AI Safety Fundamentals course and co-found AI Safety Initiative Colombia. If I get the desired results, I might consider re-orienting my career towards Technical Governance and Field-building.
Executive summary: The author analyzes interpretable features in an open-source Sparse Autoencoder trained on a 1-layer Transformer, partially replicating findings from an Anthropic paper on deriving monosemantic features from language models.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.