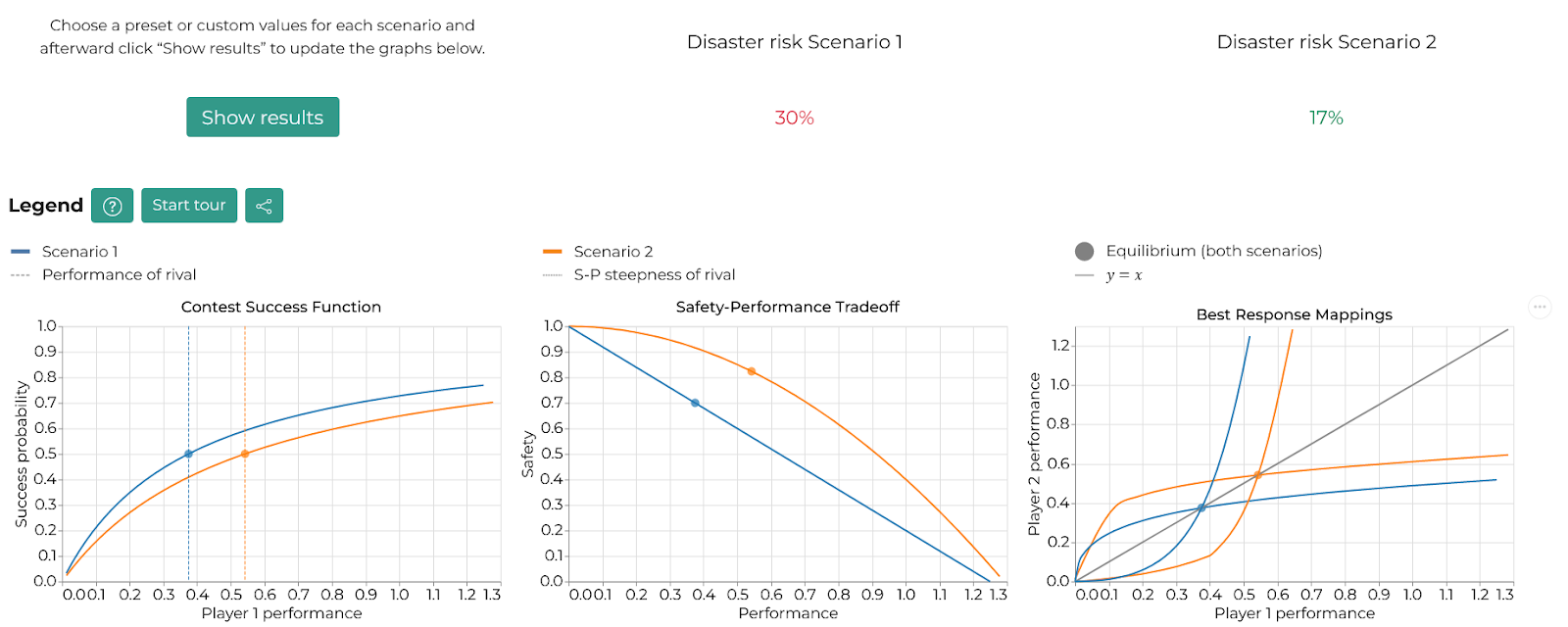
Modeling Cooperation is excited to announce our web app SPT Model—an interactive tool to explore a model of AI competition built in collaboration with Robert Trager.
Will AI safety breakthroughs always lead to safer AI systems?
Before long, we may be capable of creating AI systems with high levels of general intelligence. Such capable systems may present considerable risks when misaligned. Yet, suppose that thanks to incredible work by the AI safety community, we make a breakthrough which enables us to align many (but not all) AI systems and make them act according to our values at a relatively low performance cost. We also communicate this research to all relevant companies and governments. Everyone knows how to make their AI systems safer.
Fast forward several years and we may find that despite these efforts, the AI systems that companies deploy are just as risky as they were before the breakthrough. Our question to the reader is: why did this happen?
Announcing the web app
One way of looking at this question is to explore the safety-performance tradeoff model (SPT Model) of AI competition created by Robert Trager, Paolo Bova, Nicholas Emery-Xu, Eoghan Stafford, and Allan Dafoe.[1]
At Modeling Cooperation, we worked with Robert Trager to implement this model in an interactive web app we call SPT Model.
Figure 1: A snapshot of the user interface for the SPT web app.
The web app lets you explore a model of a competition to build emerging technologies. The model shows how failure scenarios like the one above can emerge, and there are many more insights contained within.
We built this tool as we believe that when trying to understand a model, there is no substitute for exploring it yourself. Our web app lets you set the parameters for two different scenarios and compare the effects graphically.
Answering the question
Let’s return now to the puzzle we presented above. What obstacles prevent AI safety breakthroughs from improving the safety of AI systems?
We will provide an answer below. Before that, you may wish to first experiment with the web app.
One phenomenon at play in the puzzle above is “risk compensation”.
Risk compensation occurs when making an activity safer motivates people to take more risk. Most times, risk compensation erodes but does not eliminate the benefits of safety technologies (think of seatbelts and bicycle helmets, for example). However, for emerging technologies, such as AI, a key difference is competition. Companies will take on more risk to outcompete their rivals.[2]
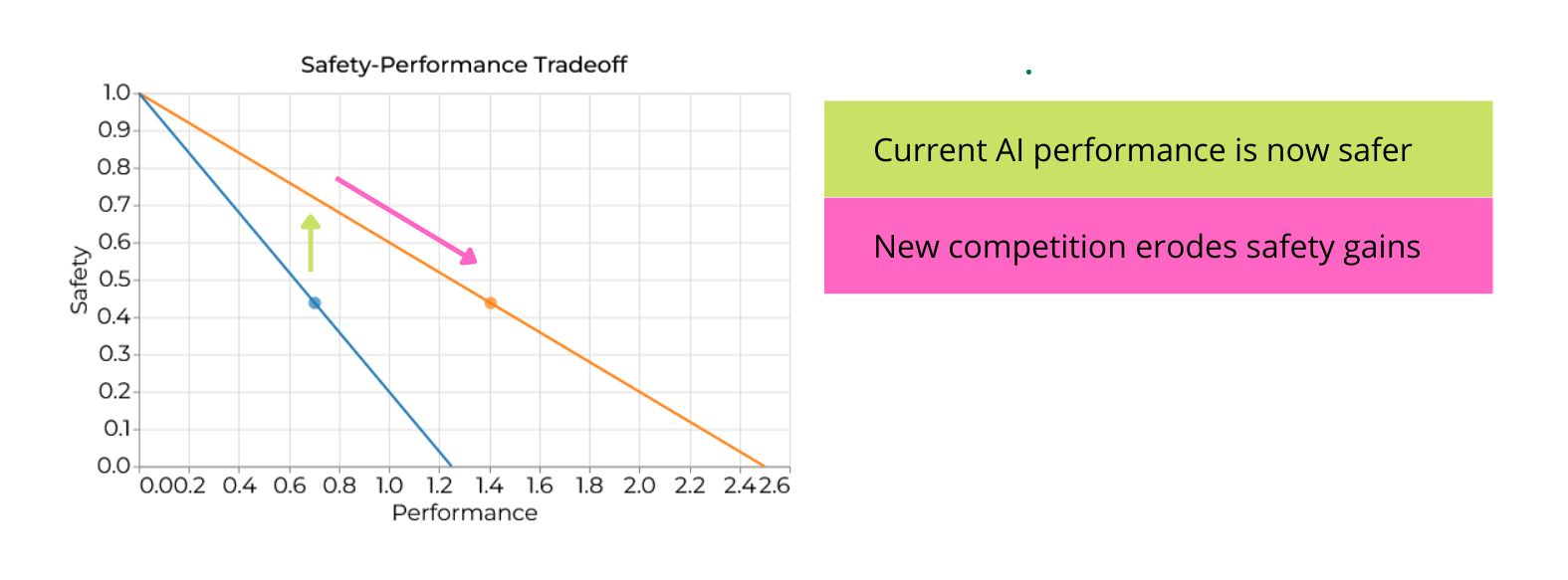
We visualize these effects of a safety breakthrough in the safety-performance tradeoff plot below. The safety-performance tradeoff plots the maximum levels of performance we can achieve for each level of safety. If companies accept a higher level of risk, then conditional on avoiding a disaster, they can expect to produce a more capable AI system than otherwise and so reap a higher benefit. Such a scenario is analogous to the risk-return tradeoff employed in stock-market investing. It seems reasonable to expect companies and other institutional actors to consider a similar tradeoff when investing in new, potentially risky, strategic technologies.
In the puzzle we presented above, the breakthrough means if firms invest in AI systems with the same performance, they will be safer than before (see the upward arrow in Figure 2). However, this breakthrough has also enabled companies to take on even riskier AI systems to outcompete their rivals (the declining arrow in Figure 2). This competition can completely erode the benefits of the safety insight.[3]
Figure 2: Effects of a safety breakthrough. Each curve (from left to right) plots levels of safety available for a given performance level before (blue) and after (orange) the safety breakthrough. Each circle marks the bundle that actors choose. The arrows indicate the different effects of a safety breakthrough.
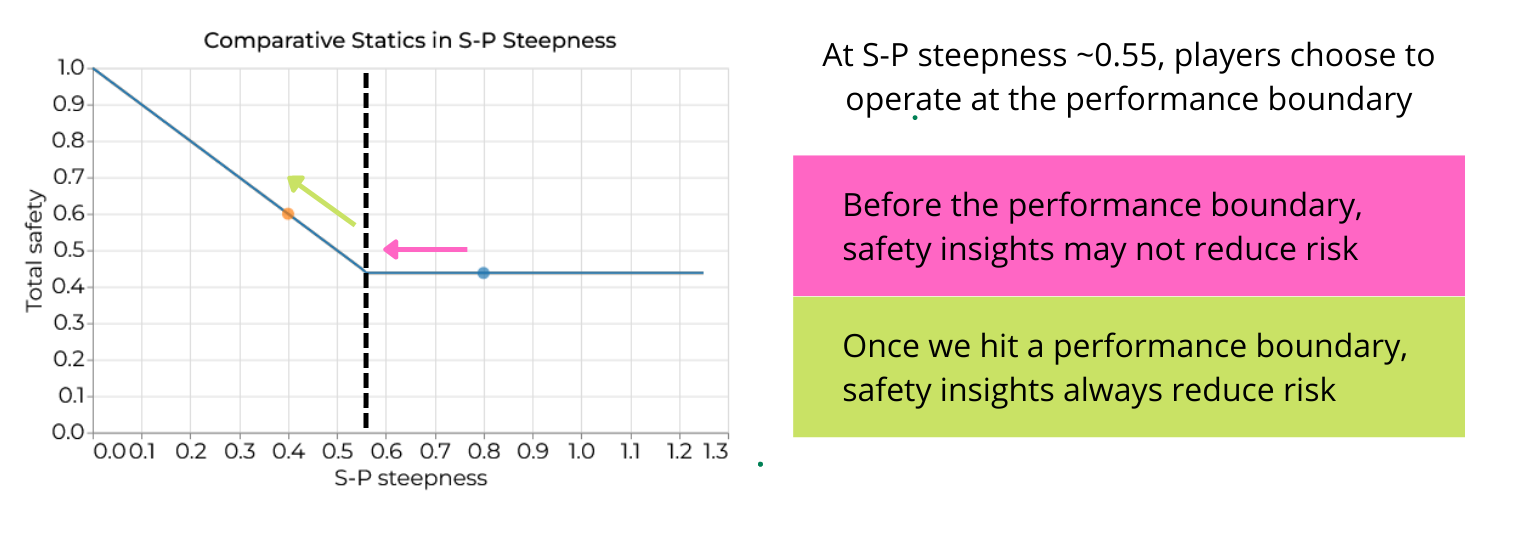
Of course, this isn’t always true. We now turn to a scenario where AI companies operate at such a high level of performance that attaining higher performance is prohibitively costly (we can refer to this level of performance as a performance boundary). If AI companies were not safety-conscious, they might operate at such a performance boundary. It is impractical for companies to increase performance in such a scenario. So, safety improvements will always reduce risk.[4]
In the figure below, taken from our web app, we see that sometimes a little safety is not enough. At first, safety insights may fail to increase total safety. Total safety only rises once the cost of alignment falls far enough for AI companies to hit the performance boundary.
Figure 3: Small safety insights have no effect. The curve (from right to left) plots how total safety changes as we become better at making high-performing technology safe, i.e. as we lower the safety-performance steepness (S-P steepness in the figure above). Circles mark the S-P steepness before (blue) and after (orange) the safety breakthrough.
An interesting takeaway from the discussion above is that safety improvements may be most useful when AI companies are not safety-conscious, and therefore operate at the performance boundary. If AI companies are already somewhat safety-conscious, so that they operate far from the performance boundary, small safety improvements risk encouraging more reckless behavior. In these cases, only the largest safety improvements are guaranteed to improve equilibrium safety.
We believe AI safety research is plausibly extremely important for future flourishing. However, the model and web app above suggests that technical AI safety research alone may not be enough to achieve AI safety. We also have to think strategically about how we deploy and govern AI safety research.[5][6][7]
Our discussion only scratches the surface. There are at least three other ways that more safety research can reduce risks from emerging technologies. We encourage you to find them within our web app or follow the links below to access them directly.
We would be very pleased to receive feedback on the web app. We also welcome opportunities to collaborate on future projects. Leave a comment below or send us a message at [email protected].
Robert Trager, Paolo Bova, Nicholas Emery-Xu, Eoghan Stafford, and Allan Dafoe, "Welfare Implications of Safety-Performance Tradeoffs in AI Safety Research", Working paper, August 2022.
Worrisome risk compensation can occur without competition in emerging technology contexts, but competitive dynamics often exaggerate the effects. Other key factors that make emerging technology contexts more susceptible to risk compensation are negative externalities from the implementation of new technologies and the absence of regulation.
In some scenarios, a safety improvement can even lead to higher total risk than if the safety improvement had not been discovered. This edge case requires that the safety improvement scales to all levels of performance and that the winner of the competition is determined using a particular functional form. Both these assumptions are quite restrictive, so while this result is plausible in the model it is also highly unlikely to apply in practice.
Our model ignores the possibility that the safety improvement makes researchers more likely to develop new technologies which push out the performance boundary. If this is the case, some risk compensation will occur, though likely to a lesser degree than when companies operate far from the performance boundary.
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...