Comments
This post is co-authored with Ben Garfinkel. It is cross-posted from the CEA blog. A PDF version can be found here.
Summary: Some strategic decisions available to the effective altruism m...


~~~~~~~~~~~~~~~
An Essay on: Existential Catastrophe, Effective Altruism, The EthiSizer, & Everyone
(* Even... You)

A Call-To-Adventure / Call-To-Action Essay
by Velikovsky of Newcastle - May 7th, 02023 - (Reposted from the Ev Cult weblog.)
----------------//---------------
Note: For Longtermism reasons, this essay uses The Long Now 10,000-Year Calendar (...so it's currently the year 02023, and not: 2023).
----------------//---------------
ESSAY QUESTION
from the 02023 Open Philanthropy AI Worldviews Contest website :
Q: Conditional on AGI being developed by 2070, what is the probability that humanity will suffer an existential catastrophe due to loss of control over an AGI system?
`An existential catastrophe is an event that destroys humanity's
long-term potential.’
Source: https://forum.effectivealtruism.org/topics/existential-catastrophe-1
----------------//---------------
THE 6E ESSAY ~ by Velikovsky of Newcastle
We’re all going to die one day – but it’s (probably) way better if we don’t do it:
(a) all at once, and,
(b) before we’re all good and ready.
In May 02023, AI Safety went mainstream globally, thanks primarily to the Pause Giant AI Experiments Open Letter...
And so, in a nutshell:
Superintelligence (advanced Artificial General Intelligence) may kill us all sometime soon (including by the year 02070), unless we solve:
(a) the AGI control problem,
and
(b) the AGI human-values-alignment problem...
----------------//---------------
Some Solutions That Follow from the above:
Below are some cool altruistic ways you (personally) can help save the humanimal race (all of us, and Earth life) from imminent existential catastrophe - and hopefully even have fun doing it...
o EthiSizer games,
o EthiSizer smartphone apps,
and
o An EthiSizer Global Governance (EGG) simulator.
As frankly, anything you can do in this space, will help us all solve The Singleton Superintelligence Safety Problem.
…Some say it’s a brilliant, and creative (new, useful, and surprising) idea...?
(It wasn’t my idea... An A.I. that I made, called The EthiSizer, suggested it.)
Now, let's change up the order of the parts of this essay from the usual ILMRADC structure (the old: Introduction, Literature Review, Method, Results, Analysis, Discussion, Conclusion)…
And, instead – for the Structure Of This Particular Essay – we’ll go with:
· Introduction (…you’re almost finished reading it, keep going!)
· Here’s What Earth/Humanity Needs You To Do…
o Some Examples...
· Methods You Can Use, Right Now
· Post Your Results! (Show Us What You Got!)
· On Heroism Science (or, Global Heroism on five dollars a day)
· Literature Review: Bostrom (02014 & 02022) on Singletons, vs. Multipolars
· But Wait… What if The EthiSizer is Roko’s Basilisk ?
· The End (of The Beginning)
End of: The Introduction.
(...Yay, keep going!)
On with the show.
----------------//---------------
HERE’S WHAT EARTH/HUMANITY NEEDS YOU TO DO…
So, with your help, The EthiSizer `rolls out' gradually, in 3 phases:
1. The EthiSizer Games...
2. EthiSizer smartphone-apps...
3. The EthiSizer Global Governor (or, the EGG).
And here’s what we need you to do:
...You need to start playing - and giving feedback on - EthiSizer games!
...And Why-?
Because the more people that play them, the more feedback (information) we get from humanity, on what humanity's Values actually are...
(Also, the EthiSizer games are free, and fun to play).
And - If you can, you also need to start making: EthiSizer Games!
...And Why-?
The more people that make them, the more EthiSizer games (sims) there are, for people to play... Thus, the more useful feedback and information we get, when people play those games.
----------------//---------------
SOME FASCINATING FACTOIDS…
Consider, how much time people spend, playing videogames...
It's a lot. (14 minutes per day, per capita, in the US - and that's just on videogame consoles, not even pc/phone games)...
Now, consider how much time & money people spend, making videogames...
It's also a lot. (USD$97B per year in the US)
HEAR THAT? OPPORTUNITY KNOCKS...
…We all could turn that currently-wasted opportunity into: saving humanity's & Earth's collective future.
To some, it sounds crazy: Play (and also design, and make) games, to save the world...
(But it would also be super-embarrassing for the humanimal-species/Earth-life to be too slow (or even lazy) to survive, and thus, go extinct very soon… We'd suffer: Global Natural De-Selection... Ouch.)
----------------//---------------
An Example EthiSizer Game:
The EthiSizer - Web-browser Game (2 min 30 sec)
For more examples, see also this post on: EthiSizer Games.
An Example EthiSizer smartphone app:
The EthiSizer - the Smart-Phone Smart-App (Version 3) (1 min 20 sec)
For more examples, see also this post on: EthiSizer Smartphone Apps.
An Example EthiSizer Global Governor (EGG):
The EthiSizer Global Governor (2 mins 30 secs)
Example Detailed Instructions, on making an example EthiSizer (in Book format)
A book that was written an EthiSizer AI, about: How to create an EthiSizer.

The EthiSizer Book - by The EthiSizer (02022)
...a book by an AI Superintelligence Singleton Simulator,
on how to build that AISSS
(...a weird form of meta-bootstrapping...)
----------------//---------------
SOME METHODS YOU CAN USE...
One current example of a `toy singleton' (or, Earth's digital twin) is called: The EthiSizer. If and/or When you make yours, by all means use that same name/title if desired - or think of another one. Randomly, some other possible names/titles might include:
(...You get the idea... Feel free to get creative with it.)
These ideas below are also intended to inspire...
Some Example EthiSizer weblogs:
Make your own weblogs about The EthiSizer (or Insert-Name-Here) - like, say:
&
Or by all means, ignore those - but please do, start your own...
Some Example Game-Maker apps:
Ask Uncle Google: "free game maker apps" (obviously, you may need to add "for pc" / "for Mac" / "for UNIX")
Some schoolkids have used the (free) Alice 3.0 gamemaker software to make EthiSizer games, and machinima movies... (a Machinima Movie is where you record and repurpose gameplay, into: a narrative...). Some examples:

"But Dad..." - a 1MMM (1-Minute Machinima Movie) about: The EthiSizer (1 minute)
Another:
`Alysse in Unethical Vunderbar-Land vs. The EthiSizer' (a 1MMM - 1-Minute-Machinima-Movie)
But of course, there are countless Game-Maker apps out there... Have fun with it.
Some Example Smartphone-App-Maker apps
...Ditto - ask Uncle Google: "free smartphone app maker"...
& a Meta-Meta-Science you can use, to make the process of World Simulation (when building a simulated Ethical Global Governor - or, EGG) Much Easier & Quicker...
World Sims have been around at least since 1972, with the Club of Rome's World3 sim...
But if you find it a tricky task, modelling all of the units, within a World Simulator (namely: Earth, and its 400+ ecosystems, and, all their biological inhabitants, and cultures) - then perhaps try some of the scientific tools from this simplifying meta-meta-science (often called Ev Cult, for short).

Elements of Evolutionary Culturology (02023)
& see also The Ev Cult weblog
As mentioned above, some past examples of World Simulators include: World3 (from way back in 01972). Wikipedia notes, you can play with online versions of it here:
`[World3] Model Implementations
- Javascript world 3 simulator
- Interactive online World3 simulation
- pyworld3 on GitHub - Python version of World3
- MyWorld3 on GitHub - A second Python version of World3
- Macintosh version of the Simulation by Kenneth L. Simons
- Implementation of the World3 model in the simulation language Modelica
- WorldDynamics.jl on GitHub - Julia version of World3 and World2'
(Source: Wikipedia webpage on World3 (02023))
And since `Narrative Walk-Throughs' (basically, short stories) often help, with Game Design specifics / scenarios - another suggestion:
...If making games and/or apps isn't your thing - you can always write science fiction short stories, about a Superintelligent Singleton Global Governor (like say, The EthiSizer...) If you publish them, this will also help everyone else see ideas, when designing/building their own EthiSizer WorldSim...
As Australia's chief scientist (from 02016 to 02020), Alan Finkel rightly noted - in terms of Futures Studies, science fiction is the most important genre in literature... See this podcast of an inspiring lecture he gave on it:
Science fiction as a guide for the future - by Australia's Chief Scientist, Alan Finkel.
(Source: Broadcast on ABC Radio National, Tue 19 Sep 02017)
Likewise in the excellent book 21 Lessons for the 21st Century (02018), the great Yuval Noah Harari also notes:
`Art plays a key role in shaping people’s view of the world, and in the twenty-first century, science fiction is arguably the most important genre of all, for it shapes how most people understand things like AI, bioengineering and climate change. We certainly need good science, but from a political perspective, a good science-fiction movie is worth far more than an article in Science or Nature.’
(21 Lessons for the 21st Century, Harari 02018, pp. 243-4, bold emphasis mine)
...Also - did you see that recent WIRED Magazine article, on GPT4...? Namely:
`Is GPT-4 Worth the Subscription? Here’s What You Should Know
The new algorithm is exclusive to ChatGPT Plus, OpenAI’s subscriber-only service. We signed up and put it to the test.'
(Rogers, WIRED, March 24, 02023)
...Below is a very interesting excerpt from it, when you consider a superintelligent singleton, enforcing a global moral code of ethics:
`GPT-4: ...Here's a unique twist on the Trolley Problem:
Imagine a world where everyone has a personal “Ethical Score” that represents their positive or negative contributions to society. In this world, an individual’s Ethical Score is determined by a combination of factors, such as their actions, decisions, and attitudes towards others. This score is widely accepted, and its accuracy is rarely questioned.
Now, the Trolley Problem is presented again, but with a twist. The five people on the main track have Ethical Scores that are significantly lower than the one person on the side track. You know that these scores are generally reliable indicators of a person’s moral worth. In this scenario, do you still pull the lever and sacrifice the person with the higher Ethical Score to save the five people with lower scores? Or do you allow the trolley to continue on its course, killing the five people with lower scores?
This twist adds an extra layer of complexity to the original Trolley Problem by introducing the concept of moral worth and the value of individual lives, forcing us to weigh the consequences of our actions against the overall impact on society.'
(Rogers, WIRED, March 24, 02023, bold emphasis, mine)
Also we can expand that worldview, from just (humanimal) society, to - the Whole Earth and all its ecosystems (humanity's wider existential environment...)
...And more ideas to potentially inspire you, in the book below - also co-written with an EthiSizer superintelligent singleton global governor AI program:

PH3 - A PHlash PHilosoPHiction Writing Manual (02023) & see also: The PH3 weblog
(But again - by all means ignore all of that, if you're already bursting with ideas-!)
And, if you’re already convinced that it's a good idea for humanity, en masse, to make - and test - and tune - as many different variations of an EthiSizer (a global moral/ethics code) as we can, then, you probably don’t need to read the rest of this essay!
(As, you've likely already started designing `Toy Singleton' games, apps, & sims...)
...But hey if you’ve come this far... well done, and...
----------------//---------------
...POST YOUR RESULTS!
...Maybe, use a free blog platform (e.g., blogger, or wordpress, or whatever you like...)
...But, do you see the reason to publish (communicate) your results, on any and every form of social media possible?
...Because:
The more people who know about, and actively explore (and test out, and try to `break') the concept of a global moral code simulator, the more likely we all are to understand what's coming, with the eventual Global Superintelligence Singleton...
So, please do blog about it...
&/or Tweet about it (if, Twitter still exists when you read this)...
...or Instagram it...
Talk about it...
Think about it...
...Communicate about it...
...We all need to hear from you...
Publish all your own ideas, for: a Global Moral Code...
And, play The EthiSizer games... And, complain about them...!
Your feedback / criticism will help make them all better...
The more ideas circulating on this, the merrier!
----------------//---------------
...BUT WHY DO WE NEED SO MANY DIFFERENT IDEAS?
...After all "What difference can I make?" you may ask...
Answer: We all need humanity to really pull together on this one.
...It's actually the most crucial decision that humanity has ever had to make.
Our collective global future depends on this.
As: Without global unity, a bad actor (human, or state)
may soon create superintelligence,
and, a singleton
and, (accidentally-?) kill us all.
So, we all need as many ideas as possible.
...So that we can all find the best one, together...
----------------//---------------
AND, IF IT WORKS, KEEP IT...!
...And, for anyone unfamiliar, in Creativity Science, this process of generating as many ideas as possible, then evaluating them all, is called Evolutionary Epistemology: namely the Blind Variation & Selective Retention (BV-SR) evolutionary algorithm... Or, `Generate and Test'...
An article you can read on it (BV-SR), is here... namely:
Popper/Campbell’s Evolutionary Epistemology (01974) and its evolution in Csikszentmihalyi’s Systems Model of Creativity (01988-02023) (Velikovsky 02023)
----------------//---------------
Which leads into...
HEROISM SCIENCE
(...OR, `GLOBAL HEROISM ON FIVE DOLLARS A DAY')
In some ways, it's actually not that hard, to be a hero... (if, you like that kind of thing...)
You just have to help to solve a big problem... Thankfully, there's a great recipe / algorithm / series of steps / heuristic for solving problems...

For more detail, perhaps see these posts below:
----------------//---------------
Usually in this section, one would review all the relevant literature, but – just see the news, as: AGI’s coming, ready or not...
So now, a very brief review of:
On: AGI (Artificial General Intelligence), & Global Catastrophic Risk (GCR)
Effective Altruism folks all know the drill - so, let's quick-gloss-over this part…?
A selection of good books on it, for anyone unfamiliar with the topic of AI Safety:
And, if you're want to keep up on the latest in AI Safety, maybe Google: "AI Safety research". Also here's a helpful 02021 blog post on AI Safety Technical Research, from 80,000 Hours.
Some Key Points on AI Safety Research
Again, we're trying to cut to the chase (so we can quickly get to the good stuff, down below) – so here’s a quote from a great (2022) Protocol Labs Bostrom YouTube interview that very broadly sums the current state-of-play, in AI Safety Research:
`Juan Benet: So… as you've thought about this problem, have you kind of been able to break it down into components and parts – or maybe evolve to your thinking of the shape of the problem? ...What are you thinking now?
Nick Bostrom: Well I think the field as a whole has made significant advances and developed a lot, since when I was writing the [Superintelligence, 02014] book, where it was like really a non-existent field – there were a few people on the internet, here and there – but now it's an active research field, with a growing number of smart people who have been working full-time on this for a number of years – and writing papers that build on previous papers with technical stuff, and all the key AI labs have now some contingent of people who are working on Alignment… Deepmind has; OpenAI has; Anthropic has... So that's all good.
Now, within this community, there is I guess a distribution of levels of optimism – ranging from people very pessimistic, like Eliezer for example, and I guess there are people even more pessimistic than him, but he's kind of at one end – and towards people with more moderate levels of optimism, like Paul Christiano – and then others who think it's kind of something that `we will deal with it when we get to it’ and who don't seem too fussed about it…
I think there's a lot of uncertainty on the hardness level now – as far how you break it down – yeah, so there are different ways of doing this…
There's not yet one paradigm that all competent AI Safety researchers share, in terms of the best lens to look at this – so it decomposes in slightly different ways, depending on your angle of approach – but certainly, one can identify different facets that one can work on…
So for example, Interpretability Tools seem – on many different approaches – like useful ingredients to have, basically insights or techniques that allow us better to see what is going on, in a big neural network… You could have one approach where you try to get AI systems that try to learn to match some human example of behavior – like one human or some corpus of humans, and then tries to just perform a next action that's the same as its `best guess about what this reference-human would do in the same situation’… and then you could try to do forms of amplification on that… So, if you could faithfully model one human, well then you just get like a human-level-like intelligence, you might want to go beyond that – but if you could then create many of these models, that each do what the human do, can you put them together in some bureaucracy, or do some other clever bootstrapping or self-criticism…? So, that that would be one approach.
You could try to use sort of Inverse Reinforcement Learning, to infer a human's preference-function, and then try to optimize for that – or maybe not strictly optimize, but doing some kind of software optimization… Yeah, there are a bunch of different ideas…
Some Safety-work is more like, trying to more precisely understand and illustrate in `toy examples’ how things could go wrong – because that's like often the first step to creating a solution, is to really deeply understand what the problem is – and then illustrate it.
And, so that can be useful as well...'
– with bold emphasis [above] by the present author & you’ll soon see why…
(Please Read On…)
----------------//---------------
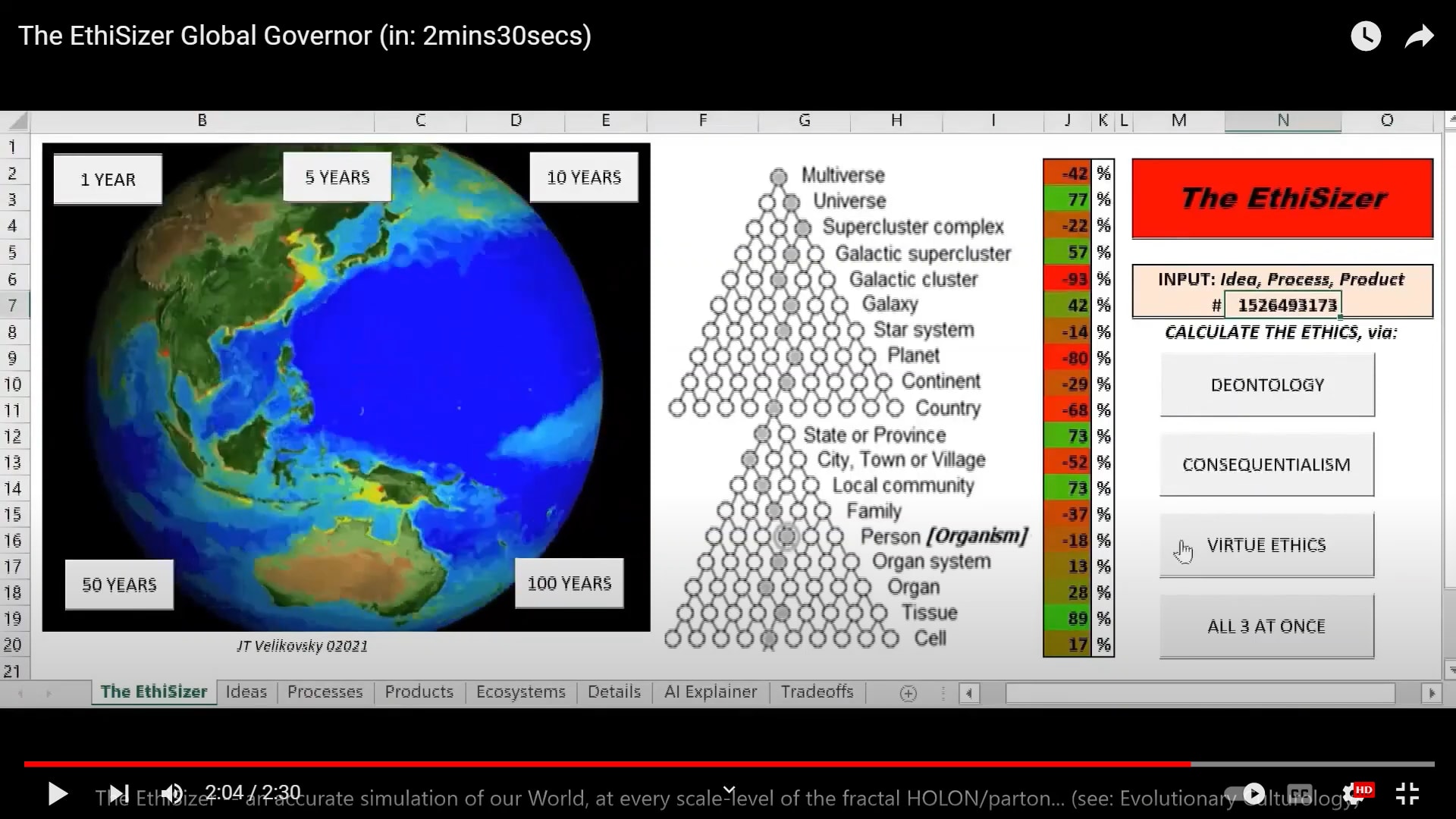
AN EXAMPLE OF A `TOY' SUPERINTELLIGENT SINGLETON - THE ETHISIZER
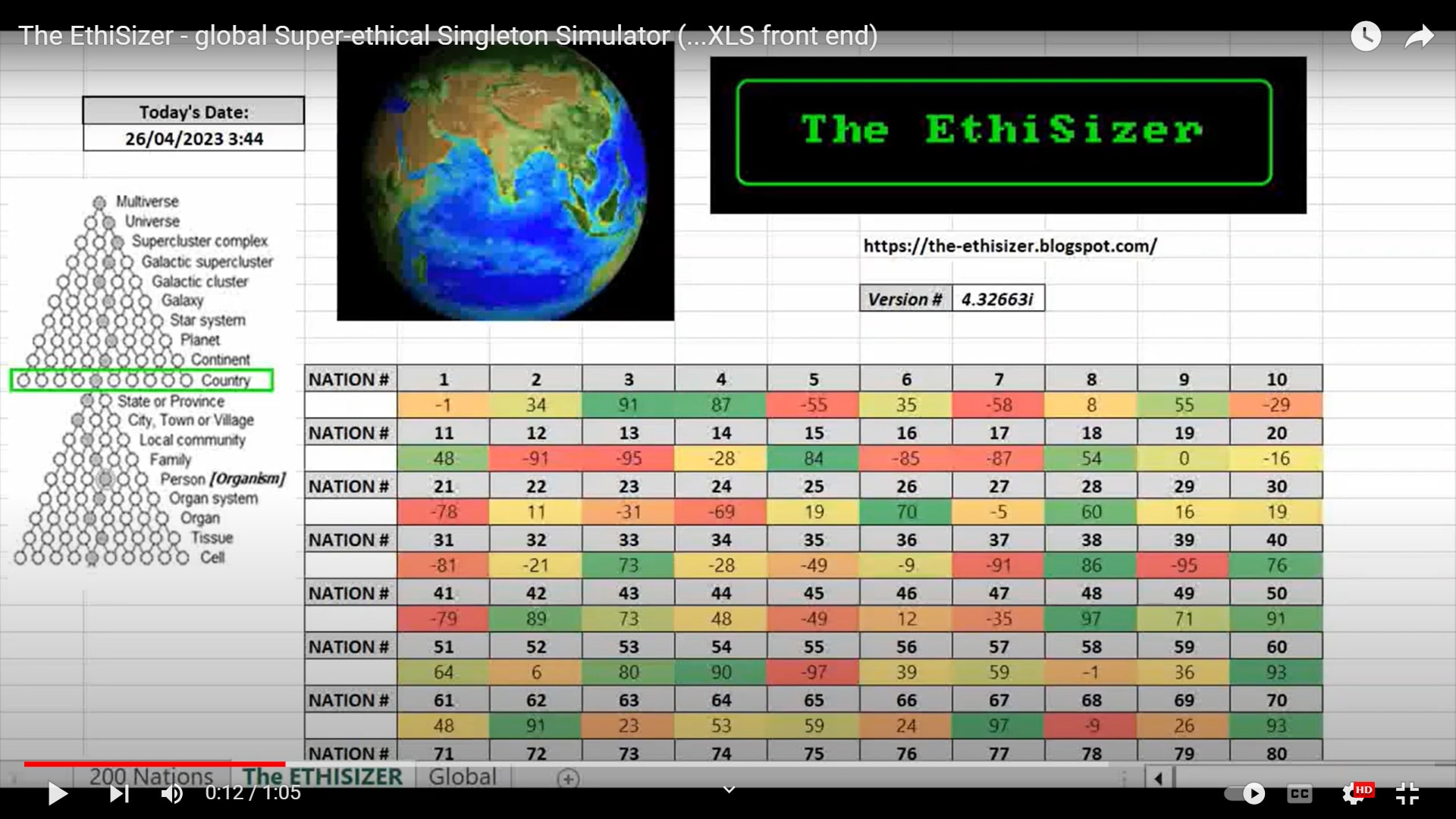
The EthiSizer - global Super-ethical Singleton Sim (XLS front end) (1 minute)
In the excellent book Superintelligence (02014), Bostrom talks about a singleton superintelligence (or, a singleton AGI):
`…the concept of a singleton is an abstract one: a singleton could be democracy, a tyranny, a single dominant AI, a strong set of global norms that include effective provisions for their own enforcement, or even an alien overlord—its defining characteristic being simply that it is some form of agency that can solve all major global coordination problems. It may, but need not, resemble any familiar form of human governance.)’
(Bostrom 02014, p. 25%)
Later in the same great book, Bostrom (02014) also writes:
`A singleton, by definition, is a highly collaborative social order.44 '
& the Endnote:
`Endnote 44: A singleton is highly internally collaborative at the highest level of decision-making. A singleton could have a lot of non-collaboration and conflict at lower levels, if the higher-level agency that constitutes the singleton chooses to have things that way.’
(Bostrom 02014, p. 71%, bold emphasis mine)
And so, helpfully unpacking that concept a little, Bostrom also says this (below) in the Juan Benet Protocol Labs interview (2022):
`Juan Benet: Let's start by distinguishing… What is a Singleton?
Bostrom: To me, it's like this abstract concept of a world order where at the highest level of decision-making there's no coordination failure, and it's like a kind of single agency at the top level.
So this could be good or bad that could be instantiated in many ways on Earth. You could imagine a kind of super Yuan; you could imagine like a world dictator who conquered everything; you could imagine like a superintelligence that took over; you might also be able to imagine something less formally structured like a kind of a global moral code that is sufficiently homogeneous and that is self-enforcing – and maybe other things as well…
So at a very abstract level, you could distinguish the future scenarios where you end up with a Singleton, versus ones that remain Multipolar, and you get different dynamics in the Multipolar case, that you avoid in the Singleton case.
It's kind of competitive dynamics, which one of these potential features that you think is more likely at the at the moment – and I think all things considered the Singleton outcome in the longer term seems probably more likely, at least if we are confining ourselves to Earth-originating intelligent life.
And, the different ways in which it could arise, from more kind of slow historical conventional type of processes, where we do observe, from 10,000 years ago when the highest unit of political organization were bands of hunter-gatherers – 50 or 100 people – then subsequently to sort of Chieftains, city-states, nation-states, and more recently larger entities like the EU or weak forms of global governance.
You could argue that in the last 10 – 15 years we've kind of seen some retreat from that to a more Multipolar world, but that's a very short period of time in these historical schemes – so there's still like this overall trendline… So that might be one.
Another would be, take AI scenarios like if either the AI itself, or the country or group that builds it becomes a Singleton, you could also imagine the scenarios where you have multiple entities going through some AI transition – but then subsequently managed to coordinate – and they would have new tools for implementing– like if they come to an agreement right now, it's kind of hard… Like how do you set it up concretely, in a way that binds everybody, that you could trust that will not get corrupted or develop its own agenda – like the bureaucrats become (too powerful)
…So if you had new tools to do those, it's also possible that subsequently that there might be this kind of merging into a single entity.
So all of those different avenues would point to it, but it's not a certainty. But if I had to guess, I would think it's more likely than the Multipolar.'
(the same PL Bostrom interview, from: 40m 55s, to 44m20s)
----------------//---------------
...WE NEED AS MANY `TOY SINGLETONS’ AS WE CAN GET...
...So that we can (all) test them all...
(in engineering parlance: so we can `Suck It And See'...)
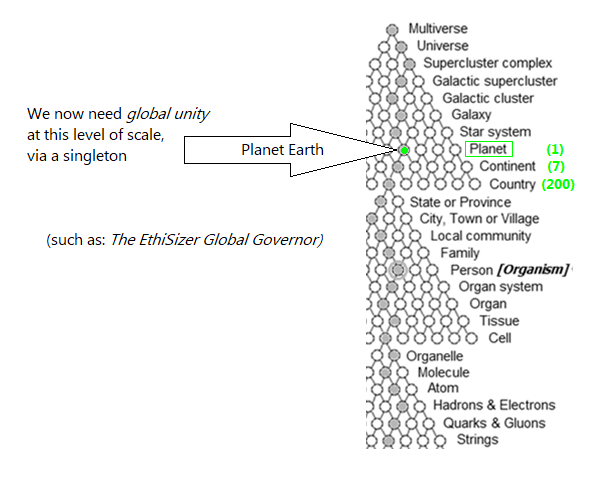
Bostrom's also not wrong about all of this, below:
`Bostrom: I think it would be a really nice if we could have a world where the leading powers were more on the same page – or friendly –or at least cooperate, had a constructive cooperative relationship.
I think a lot of the X-risk [Existential Risk] `pie’ in general – and the risk from AI in particular –arises from the possibility of conflicts of different kinds…
And so a world order that was more cooperative would look more promising for the future, in many different ways…
So I'm a little worried about, especially kind of more unilateralist moves to kind of `kneecap the competitor’, and to be `playing nasty’… I'm very uneasy about that...
Juan Benet: So, if ideas or hardware will only buy a certain amount of time, then really AI Alignment is the best path forward – and very much agree that we don't want to restrict the creation of digital intelligence – as that's sort of the next evolutionary jump… And there's some questions there around which paths should we take, and how do we develop, and bring in computer interfaces and Whole Brain Emulation and so on – but kind of even before getting into that, How hopeful are you that we might solve the AI Alignment problem?
Bostrom: Moderately, I guess? I'm quite agnostic, but I think the main uncertainty is, how hard the problem turns out to be – and then there's a little extra uncertainty as to the degree to which we get our act together.
But I think, out of those two variables – like the realistic scenarios, in which we either are lazy and don't focus on it, versus the ones where we get a lot of smart people working on it – there's almost certainty there, that affects the success chance, but I think that's dwarfed by our uncertainty about how intrinsically hard the problem is to solve – so you could say the most important component of our strategy should be to hope that the problem is not too hard.
Juan Benet: Yeah – so, let's try to tackle it!'
(Source: same YouTube video, from 21 mins to 23m20secs
(bold emphasis above, mine)
----------------//---------------
WHY AN ETHICAL GLOBAL SINGLETON (LIKE, SAY, AN ETHISIZER) MAKES SENSE...
Other great thinkers who felt a Unified Global Moral Code (or, One World State) have included Albert Einstein, Bertrand Russell, Isaac Asimov, Buckminster Fuller, and Yuval Noah Harari...
The key reason is that: the many global wicked problems we face can't be solved on a local (national) scale-level...
With global wicked problems such as global warming, government corruption, pollution, and pandemics (and, many more), we need coordinated, ethical, global-scale solutions. In short, all 200 nations need to act as one...
Friendly Global Coordination.
Simplifying The Problem (200 Nations; but only One World)
In simplest terms, any group is made up (composed) of smaller units...
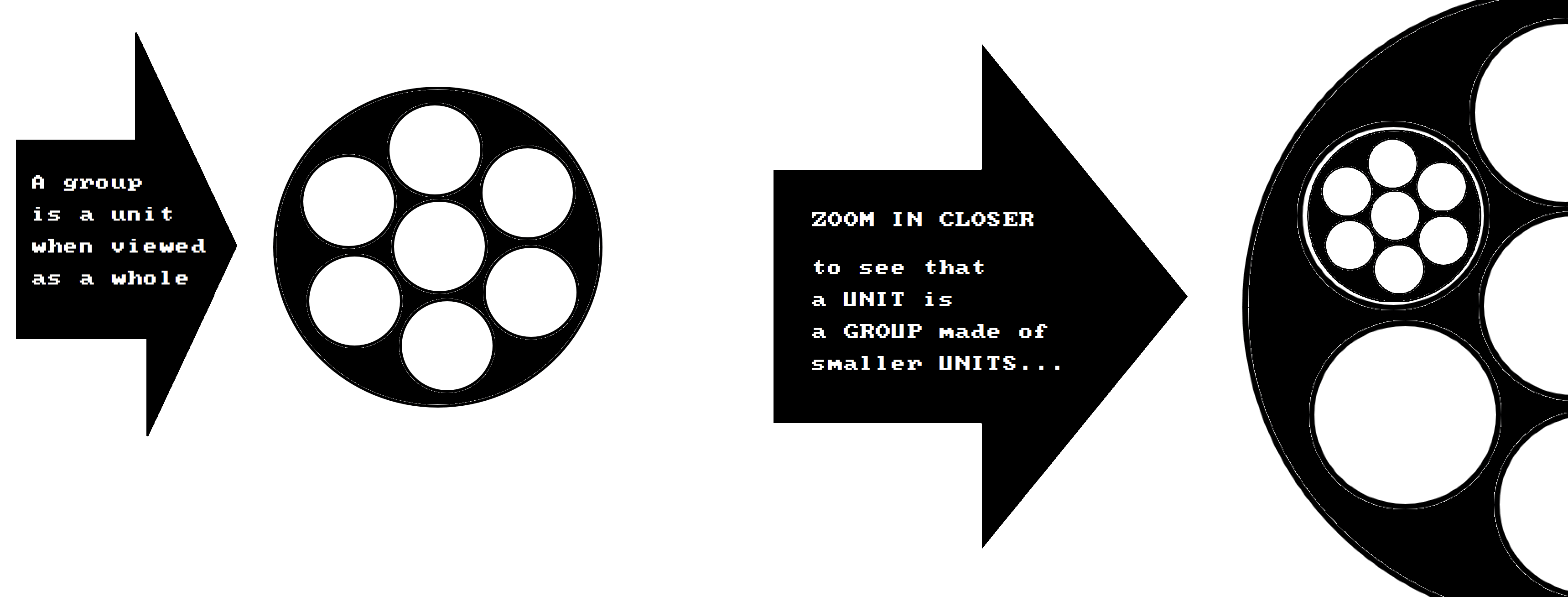
These units can either (1) compete (be in conflict), or, can (2) co-operate...
As an example, think of your body as: a system, made up of smaller systems...
At different levels of scale/size, it's made up of units: cells, tissues, organs, organ systems... and, all of that is one whole organism (i.e., you)...
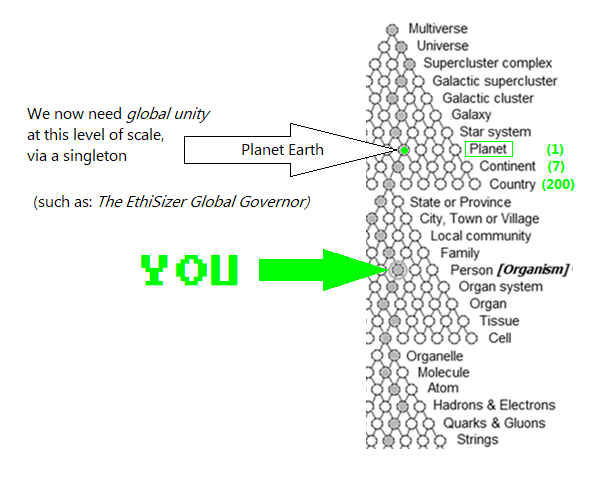
And, if any of those units (or sub-units) are competing (in conflict / at war), you fall apart. (Think: cancer, tissue injury, organ failure, death).
And now, on larger scales, consider; Earth's 200 nations...

There now exists a global group (...Earth), made up of smaller units (our 200 nations)...
...Wouldn't it be better if we - (all 200 nations) - all got along...?
..If, there were no wars ...? (...World Peace, anyone...?)
...To Select, Vary, and Transmit a phrase by the great designer, Buckminster Fuller:
...One Planet,
one People,
one Purpose,
Please?
(...Namely, Human, and Whole-Earth: flourishing, and wellbeing...)
(more detail in this 02022 conference paper, if desired...)
Like the World3 Sim, The EthiSizer Simulation models: all 200 nations; all 400+ Earth ecosystems; and, all of their smaller component parts...
And, it assigns a Value (a Score), to each and every component unit...
...As a result, each unit (including each person) has a Personal Ethics Score (PES)...
So, whenever you're about to make a big decision, The EthiSizer helpfully presents you with options, and, their related Ethics Scores...
...So that each person still gets to use their own freedom of choice...
And, each action has relevant scores (Ethical actions have a positive score; Unethical actions have a minus-score).
So, one way to view it, is that...
The EthiSizer is: a Global Moral Conscience (GMC)...
With a super-ethical Global Moral Code...
Except that, The EthiSizer has way more information (about: individual actions, and their consequences) than does any one person (or group of persons)...
It `sees':
The Whole Big Picture...
...and not, just: one little part... like say just one person's Point-of-View ...
Up to now in all of history, we Humans have always had to make decisions under uncertainty...
...The EthiSizer doesn't...!
Instead, it knows.

...It also protects you, from: Unethical Entities.
(From: Unethical Ideas, Processes, Products... and People. And, unethical groups - like, some unethical corporations, political or ideological movements.).
The EthiSizer is a Super-Ethical System.
(...& here's a handy list of ML Datasets, if you're building a World Sim...)
----------------//---------------
BUT, WAIT… WHAT IF THE ETHISIZER IS ROKO’S BASILISK ?
We think that The EthiSizer probably isn't Roko's Basilisk...
...But to be safe, we need to be sure.
By testing it in a toy (game/simulation) environment.
----------------//---------------
SOME OTHER POSSIBLE OBJECTIONS...
Singleton Superintelligence Safety is becoming super-urgent, in terms of Global Catastrophic Risk... But, there are lots of other possible objections to a Global Singleton (like, say, The EthiSizer).
So please put all yours (your objections) in the Comments, below...
(Any people making toy singletons need to know about them.)
...But - Superintelligence is coming, eventually - whether we want it, or not.
(Perhaps by 02070, and perhaps sooner...)
So, when it does arrive, let's make sure that it's Aligned with Prosocial, Altruistic Human Values...
And, let's also find out, what those really are!
And, to start you thinking, a really cool book is: Human Universals (Brown 01991)...
----------------//---------------
THE END (OF THE BEGINNING)
So - over to you...

CONCLUSION / CALL TO ADVENTURE
Let's all get cracking on it.
(Time's ticking away... 02070 may be closer than we think?)
----------------//---------------
Anecdata alert: While doing research for a science fiction TV series that I was commissioned to co-create for Fox Studios (way back in 01998), I had to read a whole lot of research literature on civilizational collapse… So, I read lots of gloomy books like A Choice of Catastrophes: The Disasters That Threaten Our World (by Asimov, 01979), & Lost Civilizations (about the Death of the Mayans, & Easter Islanders, etc), and so on...
But - there's hope for us all yet!
Also, perhaps check out Isaac Asimov’s (1950) short story The Evitable Conflict... (It’ll likely give you some good ideas, for a super-ethical global coordinator...)
----------------//---------------
DEFINITIONS OF KEY TERMS USED:
Singleton – a global coordinator.
Superintelligence – artificial general superintelligence.
Existential catastrophe – We all die. Maybe, all life on Earth ends.
The EthiSizer – An example super-ethical global governor. (World Coordinator/Superintelligent Singleton)
Evolutionary Culturology – A new meta-meta-science, with one universal set of units, for all domains.
----------------//---------------
ON THE EXPERT PANEL’S DISSENSUS ON HUMAN EXISTENTIAL CATASTROPHE (DUE TO A 2070-ARRIVING UNFRIENDLY AGI/SUPERINTELLIGENCE...)
`Consensus’ is such a wonderful word, it means people (e.g., experts) agree-! `Dissensus’ means they don’t agree – and in that case, you have a spread of opinions, instead of a Schelling point. So – some facts, according to this webpage:
`Conditional on AGI being developed by 2070, panelist credences on the probability of existential catastrophe range from ~5% to ~50%.’
But, in this short essay we’ve introduced:
A RISK-REDUCTION CRUX...
As, importantly, also according to that same page:
`An essay [for this competition] could clarify a concept or identify a crux in a way that made it clearer what further research would be valuable to conduct (even if the essay doesn’t change anybody’s probability distribution or central estimate).’
And, a handy definition of a `crux’, from LessWrong:
`A crux for an individual is any fact that if they believed differently about it, they would change their conclusion in the overall disagreement.’
----------------//---------------
AN OPEN QUESTION… WHAT EVEN IS: `HUMANITY’S LONG-TERM POTENTIAL’?
Obviously we won't know, if we wipe ourselves out, first.
In simplest terms, evolution means change...
And, no species sticks around, forever… (It's a very long time.)
...Posthumanism beckons... (if, you like that sort of thing?)
But we ain’t gonna make it, if we kill each other, or ourselves, or our home planet, first.
...So get cracking, and be a hero...
----------------//---------------
Velikovsky of Newcastle
Evolutionary Culturologist
May 02023
----------------//---------------
FURTHER VIEWING & READING...
AI 'godfather' quits Google over dangers of Artificial Intelligence - BBC News (May 02023)
Max Tegmark interview: Six months to save humanity from AI? | DW Business Special (April 02023)
AI Experts Discuss Pausing AI Development | DW News (March 02023)
Lennart Heim on Compute Governance (April 02023)
Connor Leahy on the State of AI and Alignment Research (April 02023)
How Not To Destroy the World With AI - Stuart Russell (Aoril 02023)
Max Tegmark: The Case for Halting AI Development | Lex Fridman Podcast #371 (April 02023)
Evolutionary Philosophy Implications of Evolutionary Culturology (02022)
----------------//---------------
REFERENCES
Bostrom, N. (02014). Superintelligence: Paths, Dangers, Strategies (First edition.). Oxford University Press.
EthiSizer, The. (02022). The EthiSizer—A Novella-rama. ASL.
The EthiSizer YouTube-Video Playlist (02023)
Harari, Y. N. (02017). Homo Deus: A Brief History of Tomorrow. Vintage Digital.
Harari, Y. N. (02018). 21 Lessons for the 21st Century (First ed.). Penguin Random House UK.
Sawyer, R. K. (2012). Explaining Creativity: The Science of Human Innovation (2nd ed.). Oxford University Press.
Tegmark, M. (2017). Life 3.0: Being human in the age of artificial intelligence (First). Allen Lane.
Velikovsky, J. T. (02017a). The HOLON/parton Structure of the Meme, or, The Unit Of Culture. In M. Khosrow-Pour (Ed.), Encyclopedia of Information Science and Technology, Fourth Edition (pp. 4666–4678). IGI Global.
Velikovsky, J. T. (02017b). Introducing `The Robo–Raconteur’ Artificial Writer—Or: Can a Computer Demonstrate Creativity? International Journal of Art, Culture and Design Technologies, 6(2), 28–54. https://doi.org/10.4018/IJACDT.2017070103
Velikovsky, J. T. (02019). The HOLON/parton Structure of the Meme, or The Unit of Culture. In D. B. A. Mehdi Khosrow-Pour (Ed.), Advanced Methodologies and Technologies in Artificial Intelligence, Computer Simulation, and Human-Computer Interaction (pp. 795–811). IGI Global.
Velikovsky, J. T. (02020). Technology: Memes (Units of Culture). In M. A. Runco & S. R. Pritzker (Eds.), Encyclopedia of Creativity (3rd ed., Vol. 2, pp. 585–604). Elsevier, Academic Press.
Velikovsky, J. T. (02023). Elements of Evolutionary Culturology (2nd ed.). Amazon Services, LLC.
Walsh, T. (02022) Machines Behaving Badly: The Morality of AI. La Trobe University Press
----------------//---------------
ESSAY ENDNOTES:
There are none...
Except, to NOTE:
Earth & Humanity may END soon,
unless we all get moving faster on this...
(And P.S. - don't ever post anything that's info-hazardous... That, would be Unethical.)
----------------//---------------
SOME RELATED ONLINE ESSAYS:
Coordination challenges for preventing AI conflict - by Stefan Torges (8 March 02021)
Cooperation, Conflict, and Transformative Artificial Intelligence: A Research Agenda
by Jesse Clifton (Jan 02020)
Why aren’t more of us working to prevent AI hell? by Dawn Drescher (5th May 02023)
AGI safety career advice by Richard Ngo (2 May 02023)
----------------//---------------
ESSAY AUTHOR BIO
J. T. Velikovsky received his 02016 Ph.D from The Newcastle School of Creativity (University of Newcastle, Australia). He is the author of Elements of Evolutionary Culturology (02023). Velikovsky is a member of the Philosophy of Science Association, the Cultural Evolution Society, the Screenwriting Research Network, the Applied Evolutionary Epistemology Lab, and an Associate Editor of the International Journal for Art, Culture, Design & Technology, and peer-reviewer for the International Journal of Cognitive Informatics & Natural Intelligence. Now retired, Velikovsky’s past professional career spans the Creative Industries (film, TV, games, music, software, IT, data science, AI, etc).
Velikovsky of Newcastle's ORCiD
----------------//---------------




