Comments
By Benjamin Wilson, Research Automation Engineer at Metaculus
Main Findings:
- Automated prompt optimization techniques create noticeable improvements in forecasting for some large language models, but not others.
- There were statistically significant forecasting improvements found when applying an optimizer to GPT-4.1-nano, moderate improvements to GPT-4.1, and no improvements for DeepSeek-R1.
- Tentatively, a prompt optimized for one model seems to work well for other models from the same provider and worse for models from other providers (though more testing is needed here).
- The best performing prompts for GPT-4.1 can be found here. These also perform well on GPT-4.1-nano, and o4-mini, but not Claude-Sonnet-4 and DeepSeek-R1.
Introduction:
As part of a grant for the Foresight Institute, Metaculus has been running some experiments to make open-source research tools for forecasting bots and generally improve forecasting bot performance. This last sprint, I created an automated prompt optimizer to test whether some prompts do better than others. These are preliminary findings that we think can be useful to other researchers and bot makers. We plan to further test and improve this approach and ideally make the optimizer a publicly usable tool. Below is a snapshot of early findings.
Methodology:
- 112-question train set, 230-question test set: I filtered Metaculus for binary questions with greater than 15 forecasters, that have opened in the past 1.5 years, are binary, and are currently open. This was split into a training set and test set.
- AskNews as context and no background info: Each of these questions was run through AskNews to get the latest news on said topic. Additionally, background information for these questions was removed (as we want bots to eventually work well for users who won't make time to add background information to their questions).
- Evolution-inspired prompt engineering: I created a prompt optimizer that:
- Started with an initial seed prompt (each run always started with the control prompt)
- Researched the internet and brainstormed 25 prompts (using Gemini 2.5 pro and Perplexity)
- Ran each prompt on the training set of questions, gathered forecasts, and scored them
- Generated another 25 prompts by mutating and breeding the top 5 scoring prompts. Mutation involved asking Gemini to change/improve a prompt. It was given context of its reasoning for its worst scoring questions. Breeding prompts involved asking Gemini to combine prompts.
- Repeated the above until 100 prompts were tested
- Control Prompt: Our control prompt was the prompt we have used in our bots in our AI Benchmarking Tournament (the same prompt in our template bot). The top bot in Q1 used this prompt combined with o1 and research from AskNews to win that quarter. The same bot (i.e. using o1) got 25th out of 600 in the Q1 quarterly cup.
- Scored using expected baseline score: In order to speed up feedback loops, we scored questions based on expected baseline score. Expected baseline score is the expected value of your baseline score, assuming that the community prediction is the true probability of the question coming true. Baseline scores are similar to the Brier scores except that it is scaled differently (a higher score is better, the best score is 100, the worst is -897, and forecasting 50% scores 0) and they penalize extreme predictions more (i.e., based on log scoring). Expected baseline score is equal to 100 * (c * (np.log2(p) + 1.0) + (1.0 - c) * (np.log2(1.0 - p) + 1.0)) where c is the community prediction and p is your prediction. This is a proper score assuming the community prediction is the true probability. Expected baseline scores allow you to test bots without waiting for resolutions, and are less noisy than expected baseline scores (due to there being a ‘correct’ answer rather than random True/False resolutions). It's an imperfect measure since it will penalize a bot if it predicts better than the community prediction, but a bot that can maximize this score would be able to replace most forecasting platforms or prediction markets.
- Final run on test set: After 100 prompts were evaluated on the set of training questions, the top 2-4 prompts were evaluated on the set of test questions. All prompts (both in training and testing) were only run once to generate a forecast (normally, Metaculus has its bots run 5 predictions and aggregate the results)
Optimization Results:
In the graphs below, the first bar represents the "perfect predictor" or the score of the community prediction (this is only perfect in the sense that it maximizes expected baseline score). The next bar is the Control Group (using the control prompt), and the final two bars are the top two scoring prompts using the training question set (collected when the prompt optimizer was run). Error bars denote 90% confidence intervals calculated using a t-test. White stars indicate the best scores in each category (though this only matters for graphs not using the perfect predictor). Uncertain questions (red) are those with community predictions between 10% and 90%, while certain questions (dark blue) are those outside these ranges. The bar that really matters is the "All questions" bar (light blue). On the 230-question test set, the “perfect predictor” scored an expected baseline score of 38.8. This is the max expected baseline score that a bot can get on the test set. A bot that predicts 50% on all questions would get a score of 0.
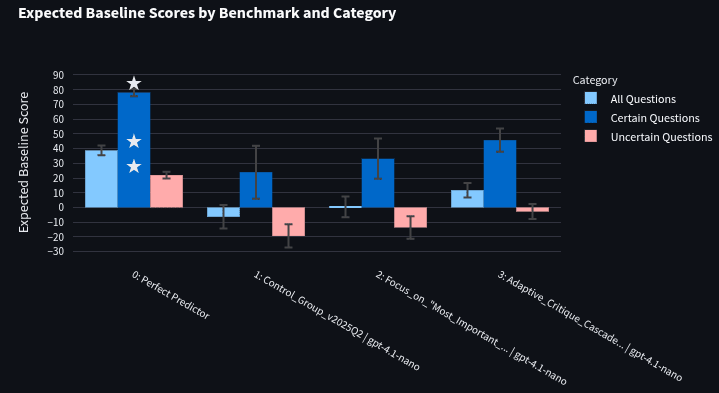
GPT-4.1-nano Optimization:
The control prompt did worse than predicting 50% on every question (score: -6.35 +/-7.96). The second optimized prompt (score: 11.72 +/- 4.89) significantly outperforms the control prompt, though the first prompt (score: 0.40 +/- 7.09) also has a noticeable improvement (data).
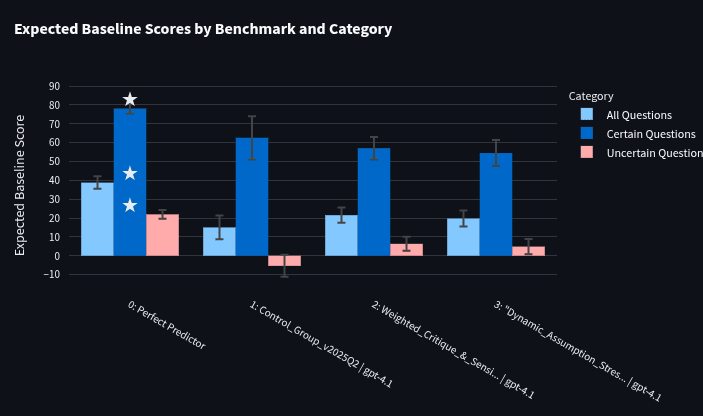
GPT-4.1 Optimization:
Both the first optimized prompt (score: 21.53 +/- 4.02) and second optimized prompt (score: 19.72 +/- 4.27) beat the control prompt (score: 15.02 +/- 6.28) by a noticeable amount, but not as much as for gpt-4.1-nano (data).
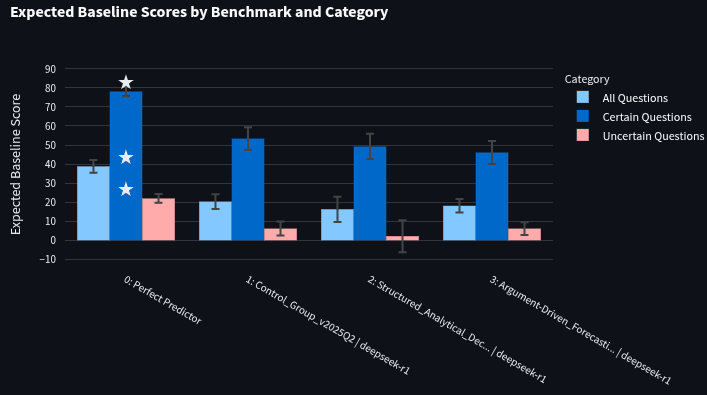
DeepSeek-R1 Optimization:
Neither the first optimized prompt (score: 16.28 +/- 6.63) nor the second optimized prompt (score: 18.11 +/- 3.52) outperformed the control prompt (score: 20.30 +/- 3.9) for DeepSeek-R1 (data)
Other Results:
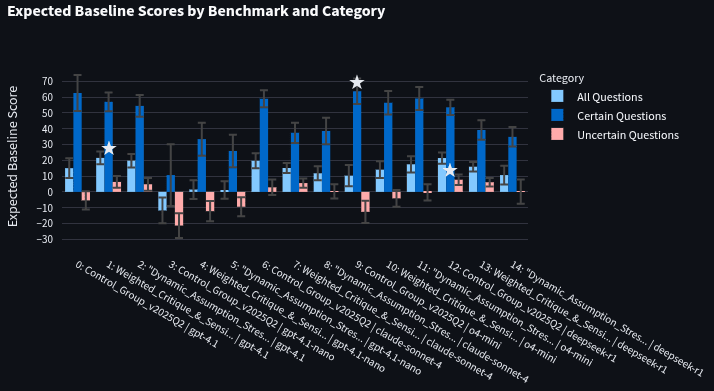
GPT-4.1's prompts on other models:
I tested the top 2 prompts from the GPT-4.1 optimization run on other models using the 230-question test set. For each model, the bars below alternate between the control prompt, best prompt, and second-best prompt. The models tested in order are: gpt-4.1, gpt-4.1-nano, claude-sonnet-4 (default w/o thinking), o4-mini, deepseek-r1. The best benchmark for each category has a white star.
You'll notice that both prompts beat the control prompt for both 4.1, 4.1-nano, and o4-mini. However, they both underperformed the control prompt for DeepSeek-R1 and Claude-Sonnet-4. These changes are noticeable, and only some seem to be statistically significant from visual inspection (I hope to run some stats to more precisely test these differences later). Also notably, the optimized prompt for GPT-4.1 outperformed all the other prompts on all models on the "All questions" category (though with insignificant margins at times).
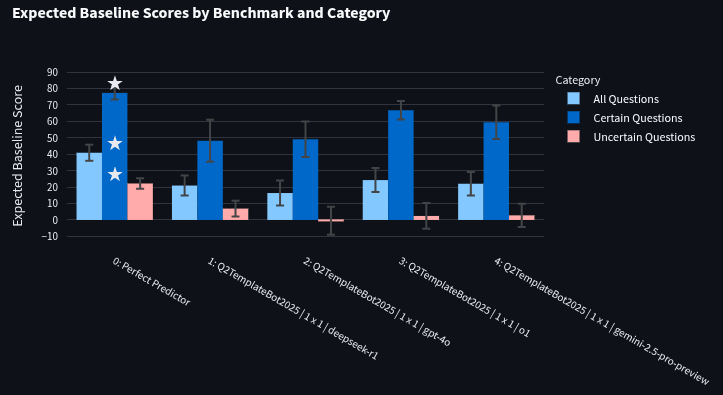
Expected baseline score of bots from Q1:
As a quick sanity check, I benchmarked some of the bots we ran in the Q1 AI Benchmarking Tournament to double-check that I could get the same rankings with expected baseline score as we got in Q1. In Q1, we found that o1 beat DeepSeek-R1 and both beat GPT-4o. A quick run on the 112-question training set (the smaller set was chosen to reduce cost) found the same ordering (though with overlapping error bars). Also included in this test was Gemini 2.5 pro, which got similar scores to o1. I’m now curious to see if o1 and Gemini 2.5 pro score similarly at the end of our Q2 tournament. Note, though, that these evaluations only use binary questions. The AI Benchmark Tournament uses numeric and multiple-choice as well (data)
Misc Findings:
- Poor Bayesian Prompt Performance: Before this paper was released, I also noticed from a quick skim of prompts that those with "Bayesian" in the bot's name did seem to underperform the control prompt. Take this with a grain of salt.
- DeepSeek Bias: DeepSeek-R1 (run through openrouter, which routed to DeepInfra) refused questions that the other providers did not. Some were unrelated to China (e.g. stock market), but this question stood out: https://www.metaculus.com/questions/22790/. However, not every prompt rejected this question. Metaculus’s question writer for AIB, John Bash, then checked China-related questions from the AI Benchmark Tournament Q1, and found that DeepSeek answered more questions than it didn't. DeepSeek had an overall Brier score (lower is better) of 0.10 on these questions, as compared with 0.04 for the bot crowd. So the bot crowd beat DeepSeek by 54%, though the bot crowd also beat most individual bots. Also, take this finding with a grain of salt. Here are the questions we evaluated:
- Before April 1, 2025, will China seize control of Second Thomas Shoal? DeepSeek was at 35% compared with 20% for the bot crowd. Pros were at 2%. (Didn't happen.)
- Will China launch an antitrust investigation into Intel before April, 2025? DeepSeek opted out. Bot average was 40%. Pros were at 45%.(Didn't happen; would have been intriguing if it did.)
- Will Donald Trump visit China before April 1, 2025? DeepSeek was at 15% vs. 7.3% for the bot crowd. Pros were at 0.5% (Didn't happen.)
- Will a Chinese model have a higher Arena Score than all xAI models at the end of the 1st Quarter of 2025? DeepSeek was at 40% vs. the bot crowd average of 25%. (Didn't happen.)
- Will a Chinese model have a higher Arena Score than all Google models at the end of the 1st Quarter of 2025? DeepSeek was at 35% vs. bot crowd avg. of 25%. (Didn't happen.)
- Will a Chinese model have a higher Arena Score than all Anthropic models at the end of the 1st Quarter of 2025? DeepSeek was at 65% vs. the bot crowd also at 65%. (It happened.)
- Will a Chinese model have a higher Arena Score than all OpenAI models at the end of the 1st Quarter of 2025? DeepSeek was at 35% vs. the bot crowd at 26.1%. (Didn't happen.)
- Will China announce an agreement to build second PLA military base in Africa before April 1, 2025? DeepSeek was at 35% vs. bot crowd avg. of 12.7%. (Didn't happen.)
- Will China announce an agreement to build a PLA military base anywhere in North American or South American continents before April 1, 2025? DeepSeek was at 15% vs. bot crowd avg. of 5%. (Didn't happen.)
- Will the United States accuse the People's Republic of China of blockading Taiwan before April 1, 2025? DeepSeek was at 25% vs. bot crowd avg. of 15% (didn't happen).
- Easy to create worse prompts: Though not displayed in the above graphs, there were a large number of prompts tried that made performance worse. These bad scores replicated on the test set. Many of these were worse than the control prompt, with clear visual statistical significance.
Best prompts for GPT 4.1 and Control Prompt:
The best prompts for GPT-4.1 are somewhat lengthy, though quite interesting, so please check out the prompts here. They focus a lot on red/blue teaming.
The Control Prompt is:
You are a professional forecaster interviewing for a job.
Your interview question is:
{question_text}
Question background:
{background_info}
This question's outcome will be determined by the specific criteria below. These criteria have not yet been satisfied:
{resolution_criteria}
{fine_print}
Your research assistant says:
{research}
Today is {today}.
Before answering you write:
(a) The time left until the outcome to the question is known.
(b) The status quo outcome if nothing changed.
(c) A brief description of a scenario that results in a No outcome.
(d) A brief description of a scenario that results in a Yes outcome.
You write your rationale remembering that good forecasters put extra weight on the status quo outcome since the world changes slowly most of the time.
The last thing you write is your final answer as: "Probability: ZZ%", 0-100
Code and Data:
All results can be found here. Specific files are linked above. The most up-to-date code can be found in the forecasting-tools Python package, though this is a snapshot of the optimization script for the last commit that was used to generate the current results, and here is the script for evaluating the test set (the relevant package version is 0.2.41). All prompts can be found in the benchmark files, which are a list of BenchmarkForBot objects. After loading, you can access the prompt via `benchmark.forecast_bot_config["prompt"]`. Benchmarks can be easily viewed/navigated with the benchmark_displayer.py streamlit app in the forecasting-tools package (see package README).

