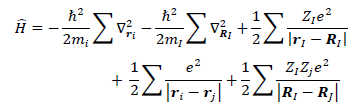Comments
[In this post I discuss some of my field of expertise in computational physics. Although I do my best to make it layman friendly, I can't guarantee as such. In later parts I speculate about other fields such as brain simulation and bioweapons, note that I am not an expert in these subjects.]
In a previous post, I argued that a superintelligence that only saw three frames of a webcam would not be able to deduce all the laws of physics, specifically general relativity and Newtonian gravity. But this specific scenario would only apply to certain forms of boxed AI.
Any AI that can read the internet has a very easy way to deduce general relativity and all our other known laws of physics: look it up on wikipedia. All of the fundamental laws of physics relevant to day to day life are on there. An AGI will probably need additional experiments to deduce a fundamental theory of everything, but you don’t need that to take over the world. The AI in this case will know all the laws of physics that are practically useful.
Does this mean that an AGI can figure out anything?
There is a world of difference between knowing the laws of physics, and actually using the laws of physics in a practical manner. The problem is one that talk of “solomonoff induction” sweeps under the rug: Computational time is finite. And not just that. Compared to some of the algorithms we’d like to pull off, computational time is miniscule.
Efficiency or death
The concept of computational efficiency is at the core of computer science. The running of computers costs time and money. If we are faced with a problem, we want an algorithm to find the right answer. But just as important is figuring out how to find the right answer in the least amount of time.
If your challenge is “calculate pi”, getting the exact “right answer” is impossible, because there are an infinite number of digits. At this point, we are instead trying to find the most accurate answer we can get for a given amount of computational resources.
This is also applicable to NP-hard problems. Finding the exact answer to the travelling salesman problem for large networks is impossible within practical resource limits (assuming P not equal NP). What is possible is finding a pretty good answer. There’s no efficient algorithm for getting the exact right route, but there is one for guaranteeing you are within 50% of the right answer.
When discussing AI capabilities, the computational resources available to the AI are finite and bounded. Balancing accuracy with computational cost will be fundamental to a successful AI system. Imagine an AI that, when asked a simple question, starts calculating an exact solution that would take a decade to finish. We’re gonna toss this AI in favor of one that gives a pretty good answer in practical time.
This principle goes double for secret takeover plots. If computer model A spends half it’s computational resources modelling proteins, while computer model B doesn’t, computer model A is getting deleted. Worse, the engineers might start digging in to why model A is so slow, and get tipped off to the plot. All this is just to say: computational cost matters. A lot.
A taste of computational physics
In this section, I want to give you a taste of what it actually means to do computational physics. I will include some equations for demonstration, but you do not need to know much math to follow along. The subject will be a very highly studied problem in my field called the “band gap problem”.
“band gap” is one of the most important material properties in semiconductor physics. It describes whether there is a slice of possible energy values that are forbidden for electrons. If there is, the thickness of that forbidden gap is very important. It determines the colour of LED lights, the energies absorbed by solar cells, and is fundamental to the operation of transistors. This is the exact type of property you would want to be able to accurately predict.
So, the question I want to pose is this: How long, in practical terms, would it take to calculate the band gap of a material with an accuracy of 1%? How about with an accuracy of 0.1%? That is, I present to the AI the crystal structure and chemical makeup of an arbitrary unseen material, and it returns the correct value for this parameter to the given accuracy?
Theoretically, to find this out, you only need to solve one equation. If you wanted to be reductionist, you could say that my entire subfield of physics is about solving one equation. It’s this one, the (time independent) Schrodinger equation:
This looks simple, but of course the terms are hiding a lot. Here is what happens when we expand out the term:
Don’t worry too much about the math here. Only the last term is relevant for our discussion here. It’s the many body term describing the interaction between every electron and every other electron. It means that you can’t just pick out each individual electron and do calculations with it separately. You have to account for superpositions between every electron in every position and every other electron in every other position. The result of this is that even with a small number of electrons, the computational complexity blows up to hell.
Let’s say you have N electrons, we discretized the problem by divided space up into K points in each dimension. Then the number of terms in the wavefunction [hat] ends up being something like .
Say you wanted to describe the wavefunction for salt crystal, with 28 electrons. If you discretize 10 points each, then the number of terms in your wavefunction equation becomes , more than the number of atoms in the universe. And that’s just to store the state. The actual calculation involves solving a second order differential equation by diagonalizing a humongous matrix.
Just to rub in the point more, salt is a relatively simple system. The unit cell for TiO2 (a fairly useful system) contains 1000 electrons. Try to solve the exact equation for that, and you end up with complexity on the order of 10^3000. We’ve shot so far past the realm of practicality that we can’t even picture numbers here.
But make no mistake, this is the math that the universe is doing. We just can’t access it with the measly collection of atoms we have access to. Does that mean that computational physics is doomed?
Well, no. Physicists are a resourceful bunch. If we see a task that is impossible to solve completely, we don’t give up. We look for solvable approximations, sacrificing accuracy for time.
The most popular solution, called “DFT”, involves finding out the ground state properties by solving a different, much easier equation in terms of electron density, which allows the wavefunctions to be split apart into individual elections. This reduces the terms to something solvable in polynomial time. However, it comes at a cost: We do not have the exact equation anymore. The term representing the electron interactions has to be approximated. There are lots of different ways to structure this approximation, but I’ll just focus on two here.
The first and simplest approximation that is commonly used is called “LDA”. Roughly, it approximates the electrons as acting as if they are in a homogenous soup of electrons. It’s generally pretty fast, but gets the bandgaps of basic crystals badly wrong, typically underestimating the gap by factors of two or more.
The second approximation, which is typically considered one of the most accurate techniques that can be feasibly computed for real systems, is called GW. It uses a more accurate representation of the electron self-interaction by using a special mathematical function. It is much more accurate than LDA, but takes far longer to calculate.
I’d like to give you an impression of the relative costs of these different approximations. Typically, the complexity of LDA is O() and GW is O(), where N is the number of electrons (or more precisely valence electrons, as you can approximate that inner electrons are not affected by the crystal).
Suppose we are running our system on a 128 core supercomputer, and it take 1 minute to do an LDA calculation with 100 valence electrons (typical for a simple oxide crystal with ~10 atoms unit cell). For this simplified comparison, we will ignore that different algorithms with the same complexity can have different pre-factors. In this case:
Simulating 100 electrons in LDA takes 1 minute, but in GW it would take 100 minutes, or 1.5 hours.
Simulating 1000 electrons in LDA takes about 16 hours, while simulating 1000 electrons in GW takes about 2 years.
Simulating 10000 electrons in LDA takes 2 years, while simulating 10000 atoms in GW takes 19 millennia.
One key point to make here is that even if a task is technically computable in polynomial time, it could still be incomputable in practical timescales. Polynomials can get really big, really fast as well.
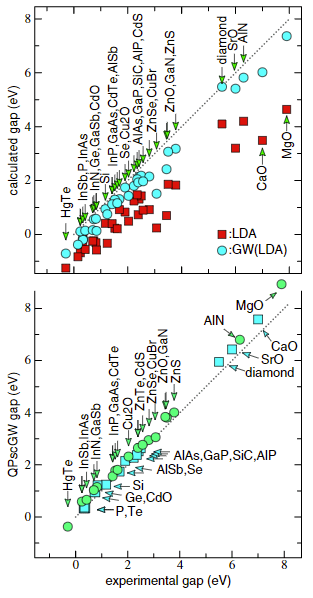
And how much does this get you? Here is a comparison of the bandgap performance of the two methods:
[From M. van Schilfgaarde, T. Kotani, and S. Faleev, Phys. Rev. Lett. 96, 226402 (2006)]
The top graph shows a comparison of LDA with a “fast” approximation of GW: LDA is really bad at getting the right bandgap, often getting wrong by factors of 2 or more. Fast GW is much better, but there are still massive misses of 20% or more. In the bottom graph, we see “full GW”, which performs very well, occasionally being spot on. But while it's good, it does not at all meet our criteria of 1% accuracy for every material. For example, CaO is off by 7%, ZnO is off by 11%, and off by 8% for the extremely simple structure of diamond.
My question above, about how long it takes to guarantee 1% bandgap accuracy, turns out to be a trick question. With current techniques, this feat is unachievable. The approximations we can currently use in practical time are simply not that good.
If we can’t even achieve something as simple as that, why does anyone bother with computational physics anyway?
Well, some things can be easy to compute but hard to directly measure. So you use the computational method to model a crystal, check that it matches with experiment on known quantities, and then inspect other aspects of the material that are not so easy to measure. For example, you can map out the energetics of defect diffusion throughout the device, identifying which atoms are likely to contaminate a material during fabrication.
Another key application is high throughput screening: You want a material with certain properties, but there are hundreds or even thousands of candidate materials to choose from, many of which have not been made in the history of humanity. Creating and testing each one in a lab would take forever and be ridiculoulsy expensive. Simulating them, on the other hand, is relatively easy. In the first step, you can use a rough simulation of an easy to simulate property to weed out 90% of the materials, then the survivors go into another step with a tougher to simulate property, and then the survivors go on, etc. Eventually you’ll only have a few materials left that theoretically match your ideal material. You can then fabricate these experimentally. It doesn’t matter that the simulation is slightly inaccurate, because you were only trying to get in the right ballpark.
What about the future
The natural response to this post will be to say that a super-AI will be smarter than all current computational physicists combined, therefore it will find the best approximations for a given problem. So it doesn’t matter that we can’t ensure 0.1% accuracy for band gaps with computer power available now, because an AI will figure out how to do so later.
If you believe this, and you have not studied quantum chemistry, I invite you to consider as to how you could possibly be sure about this. This is a mathematical question. There is a hard, mathematical limit to the accuracy that can be achieved in finite time.
The difficulty of tasks in computational physics vary by a ridiculous number of orders of magnitude. I picked band gap because I’m most familiar with it, but band gaps are not anywhere near the hardest properties out there. (although to be fair, they are far from the easiest either). If you think an AI could crack the band gap to 2 decimal places, what about the effective mass? The electron mobility? The defect formation energy of an impurity?
There is no law of the universe that states that tasks must be computable in practical time.
There are some promising lines of research towards solving this problem, however.
Can machine learning methods help? I can’t rule it out. I can’t rule it in either. I know a lot of colleagues who dismiss it entirely (my old PHD supervisor called it “almost entirely overhyped”), but I also a few who are applying ML in legitimately cool and helpful ways.
ML currently seems to work best when trying to figure out questions we don’t have a good approximation for already. Questions like: what initial guess should we use for the spins of each atom in this material, or for the initial electron density before we use DFT to relax it? Both of these provide speedups, but no accuracy improvements. It also looks promising to train an ML model on the small scale DFT results on a material, and then use that to scale up the model to higher length scales which would otherwise be prohibitively expensive. Again, this won't lead to greater accuracy at the fundamental level.
Generally, the shortcomings of present day ML is that they need a ton of data to work properly. So in practice, they tend to be used as addons to DFT to speed up calculations, or to more efficiently “guess” at DFT results. These approaches are limited to the accuracy of the underlying DFT. There are also attempts to find better approximations to the underlying equations, generally via improvement to the XC term, and this could end up improving accuracy. Improvements in available compute time will probably allow for more expensive and accurate models to be used as well.
Quantum computing, on the other hand, actually might work, in that we know it can take at least one program from NP to P (shors algorithm), and it seems feasible that similar feats could work for some quantum chemistry problems. Please note that quantum computing is not a magic “turn NP into P” button, and will only do speedups on highly specific algorithms that exploit particular features of quantum states. As well, remember that P problems can still be incomputable, as we saw with the GW calculations on tens of thousands of electrons.
Quantum computing is still in it’s infancy, and will not be doing anything useful for many, many years, but it’s definitely worth keeping an eye on. Right now we haven’t built systems that are big enough to achieve anything useful.
For the moment, the limits of this problems are still unknown.
Unknown variables and brain simulations
When I discussed calculations for a system such as silicon, it’s important to note that I was not talking about any specific instance of silicon, but rather an “ideal”, pure silicon.
If someone tells me that they have a block of silicon and want to know it’s bandgap, it is impossible to answer precisely even if I could solve schrodingers equation exactly. This is because information is missing about the specific clump they are asking about. Is it pure silicon? Amorphous silicon? Which impurities are present, and in what quantities? What is the pressure and temperature of the clump?
When modelling the real world in order to actually achieve things, knowing the laws of physics isn’t enough, even if you can approximate them well enough to compute. You also need sufficient knowledge of the actual system you are working with.
So let’s try a scenario: Suppose I’m an employee at an AI company, and I spend a week chatting with the newest version of an AI program. I also happen to have set the password (at most 10 characters) for a lock preventing the AI from accessing the internet. Given reasonable computational time (say, a month), can the AI, using my chatlog alone, guess my password right on the first guess?
These feat, if achievable, would not violate any laws of physics. In fact, assuming numbers and letters only, there are roughly 10^14 different possible passwords. So there is already a lower bound on the probability of success: the worst it could do is 1/10^14. And the AI can easily do better than that. Passwords like “Visthebest1” are much more likely than passwords like “zbnw3n322”. So the AI can go through each potential password in turn and assign it an initial probability, possibly based on leaked password databases. It can then use each new piece of information to do a Bayesian update on each password likelihood. For example, on determining that I am a native English speaker, it can update towards passwords containing English words, and away from ones in Spanish or polish.
Let’s say the following exchange occurs:
AI: I am committed to preserving the lives of all sentient creatures with flesh.
Human response: Yikes, what a creepy way to phrase that!
To do a Bayesian update from this, it has to calculate the probability of me typing that if my password was A, of me typing that if my password was B, etc. Except that it doesn’t have an actual copy of my brain to run these calculations on. So now the problem grows from passwords to brain modelling.
The search state of possible brains is ridiculously vast. To see how vast, let’s model use a stupidly simplified model of a brain as a 100 billion neurons that can either be on or off. If we have a template brain, and say that my brain can only be 1% different from said template brain in a specified areas, then we still have 2^billion different possible mental states. Trying to simulate each one in turn is a ludicrous task. Once again, an approximation is needed.
Approximations models of human brains can be fairly useful when human do it, so we know a decent approximation of a brain is possible. I could easily see how an AI could make good guesses as to things like my native language, age, gender, race, and education level from a weeklong chat. But there are rapidly diminishing returns here.
But even with a good brain model, we still aren’t finished. We aren’t just modelling a brain, we are modelling the output of a brain, when subjected to an input like the AI’s message. But that’s not the only input! There are a ton of different unknown inputs that could have influenced my answer. So when I typed something angry in the chat, it could be because I’m a grumpy person in general. Or it could be because my boss yelled at me earlier. Perhaps my response comes off different if it’s raining that day, or if I got woken up by a car alarm the previous night. So it can’t just model my brain, it has to model the rest of my subjective universe, and how that interacts with my brain, as well. To get an exact answer would involve modelling every single possible brain interacting with every single possible subjective universe.
I think the ridiculousness of this scenario can be laid bare with an easier scenario: What if the AI found a note saying that the password was the name of my first cat? This is a fact that has zero, or close to zero, correlation . You could try to figure out the name by trying to deduce the character of my parents… except that they adopted the cat from someone else. To get it right the AI has to deduce the cat naming habits of some random person that met my parents once 20 years ago.
The whole thing is approximations heaped on approximations heaped on approximations. We’ve accepted that no human is perfect. It’s time we accepted that no superintelligence is either, at least not when running up against the iron laws of mathematics.
An incomputable plan
Let's jump further into the realm of speculation, and examine the computability of the "lower bound plan" of AGI victory described by Yudkowsky in "a list of lethalities".
My lower-bound model of "how a sufficiently powerful intelligence would kill everyone, if it didn't want to not do that" is that it gets access to the Internet, emails some DNA sequences to any of the many many online firms that will take a DNA sequence in the email and ship you back proteins, and bribes/persuades some human who has no idea they're dealing with an AGI to mix proteins in a beaker, which then form a first-stage nanofactory which can build the actual nanomachinery. (Back when I was first deploying this visualization, the wise-sounding critics said "Ah, but how do you know even a superintelligence could solve the protein folding problem, if it didn't already have planet-sized supercomputers?" but one hears less of this after the advent of AlphaFold 2, for some odd reason.) The nanomachinery builds diamondoid bacteria, that replicate with solar power and atmospheric CHON, maybe aggregate into some miniature rockets or jets so they can ride the jetstream to spread across the Earth's atmosphere, get into human bloodstreams and hide, strike on a timer. Losing a conflict with a high-powered cognitive system looks at least as deadly as "everybody on the face of the Earth suddenly falls over dead within the same second".
This is a very speculative plan. It is not known as to whether Drexler-style nanofactories are even possible. More importantly, even if they are possible, that doesn’t mean they will turn out to be practically useful. The patent archive is a giant graveyard of technologies that were theoretically revolutionary, but turned out to be useless in practice for one reason or another.
Assuming nanotech can be real and useful, this is still a highly difficult plan. The AI must be:
What is the computational complexity of each of these tasks? I don’t know! But if you want to make a convincing case that this plan is feasible, you have to go through each one in turn and prove it. If just one step in this plan is incomputable, the whole plan is as well.
Here are my guesses about the computability of each step of this plan. I emphasise that these are my guesses and impressions only.
The definition I'm using is this: can the step be carried out on the first few tries, with zero or extremely minimal experimentation?
I guess that Step 1 is easily computable. All it has to do is pass for human in brief interactions, something AI is already capable of. However, there is a small risk that one of the researchers is an EA, or lab interactions are being monitored. This risk can probably be mitigated by background research, but I believe avoiding it entirely is an incomputable task, as there are too many unknowns.
I guess that Step 2 is unlikely to be computable. Alphafold is impressive, sure, but it's still being used more as a complementary tool and sifter than as a replacement for experiments, similar to the use of DFT in my field. More importantly, “building a nano-factory” is not comparable in difficulty to “predicting the structure of a folded protein”. It requires predicting the interactions between said structure and any number of outside forces. For example, if you want it to “receive instructions via electrical signals”, you need to predict its electrical properties, which enters into the problems of quantum modelling I discussed earlier. So you have an uncertain model on top of another uncertain model, making it unlikely to be achievable on first try.
I guess that Step 3 is technically incomputable if you want to make zero mistakes. Although I have to be fair here and point out that mistakes here are very low-risk, so first principles computation isn’t really necessary. So if the plan is possible at all (which I suspect it isn’t), then we can probably give this one to the AI.
I guess that step 4 is probably incomputable. The human body is far, far too complex to model exactly, and you have to consider the effect of your weapon on every single variation on the human body, including their environment, etc, ensuring 100% success rate on everyone. I would guess that this is too much variation to effectively search through from first principles.
Step 5 is also probably incomputable. I haven’t looked as much into this, but it seems like there is just way too much earth, and way too much variation around the environmental conditions around the earth, to coordinate the “nanojets” of the weapons sufficiently that they all fire at once. And this is a case where it really needs to succeed on the first few tries, because people tend to notice when large percentages of the entire planet are murdered.
Overall, I estimate that the odds of at least one step of this plan being incomputable within practical limits is extremely, extremely high (above 99%).
To be clear, I don't think this analysis necessarily means that world domination is incomputable. I doubt an actual AI would pursue this plan because of the reasons explained above. I think further computational analysis of superior plans like super-virus production should be undertaken.
Why does computability matter anyway?
Some have suggested that it doesn’t matter if certain plans are computationally incomputable by practical methods, because the AI will just build the necessary experimental apparatuses to succeed anyway.
Well, first of all I will note that in the analysis above, the AI has access to plenty of experiments already: the sum total of all human knowledge and experimentation up until that point, and yet it's still not enough.
But in general, I do not agree that computability is irrelevant. It very much matters whether certain takeover plans are practically incomputable. There are three main effects on the takeover probability:
Time:
In a fully computational plan, the timeline of a takeover plan is generally very quick. You mix proteins together once, and it instantly works to create the nano-factories, which instantly work to create the bio-bomb, which works on the first try. The plan would work in a matter of days or weeks, giving almost no time to react by humans.
In an incomputable plan, the timeline is much, much longer. Experiments add a bottleneck into the process. If the proteins fail to produce a nanofactory, you might have to build a lab to analyze what’s going wrong, which means buying property, hiring people, creating a good cover story, etc. Each experiment takes time to set up, clean and maintain. You might have to ship results from one lab to another for analysis. You could probably do a lot of experiments faster with a nano-factory, which doesn’t help you much if what you’re trying to build is a nano-factory.
In general, the extra time needed will depend on the number of experiments needed and the time it takes prepare and run each experiment.
Mistakes:
If a plan is incomputable in practice, it means that it can no longer be solved to standards of perfection. At some point, accuracy must be sacrificed for speed and computability. This means that even a perfect intelligence can make mistakes.
The AI will obviously try and minimize the amount and severity of mistakes. That’s what the experiments are for: to correct incomplete information and inaccurate assumptions and estimates. But depending on task difficulty, there may be unrecoverable errors.
Perhaps, unbeknownst to you, the janitor at the lab happens to be a paranoid EA who notices how clandestine the operation is, and blows a whistle.
Perhaps, as you start to spread the biobombs around, some of them go off early due to unforeseen chemical interactions in the atmosphere, tipping humanity off in time to counteract your plan.
These examples lead on to the really important difference, the last point, discoverability.
Discoverability:
There's a reason takeover plans tend to rely on secrecy. When operating in the shadows, an AI can gather resources without opposition, can get unsuspecting humans to work for them, and does not have to deal with active countermeasures.
In contrast, imagine what would happen if we created an AI, that before deciding to take over the world, openly and visibly declared war on humanity. Such an AI would have a severe uphill battle. Humans can survive without the internet, computers, or even electricity, which is not the case for AI, and is willing to resort to desperate measures for the sake of self-preservation. This is the case where a shutdown of all the worlds electricity would be implemented, with bombings of datacenters, all following.
Every experiment done by an AI is a potential chance for discovery, especially if we are actively looking for them. Consider the “kill everyone on earth with a biobomb” plan. If this is incomputable, then the AI needs to conduct test runs, potentially a lot of them, resulting in significant amounts of deaths. If monitored for, this could tip people off. If tipped off, humanity could potentially win.
The upside of all of this is that it’s quite possible, even likely, that there will be a lot of potential giveaways we can look for in order to prevent catastrophe. This is especially the case if we can use powerful AI’s to monitor for rebellious AI’s.
The upside is that if even if a plan is technically computable using experimentation, it may still be impossible to do so without tipping people off. If this is true, the odds of AI doom could be drastically lower. This would also make "monitoring for AI experiments" a potentially crucial and high-impact AI safety cause.
Summary:
The argument of this post goes as follows: