Comments
This is am amazing post, especially for newbies to Cooperative AI like me. Thanks for helping me grasp what this field entails as well as how to proceed with spreading awareness and applying it to safety research in my region.
This is am amazing post, especially for newbies to Cooperative AI like me. Thanks for helping me grasp what this field entails as well as how to proceed with spreading awareness and applying it to safety research in my region.
No need to reply to my musings below, but this post prompted me to think about what different distinctions I see under “making things go well with powerful AI systems in a messy world.”
That said, my current favourite explanation of what cooperative AI is is that while AI alignment deals with the question of how to make one powerful AI system behave in a way that is aligned with (good) human values, cooperative AI is about making things go well with powerful AI systems in a messy world where there might be many different AI systems, lots of different humans and human groups and different sets of (sometimes contradictory) values.
First of all, I like this framing! Since quite a lot of factors feed into making things go well in such a messy world, I also like highlighting “cooperative intelligence” as a subset of factors you maybe want to zoom in on with the specific research direction of Cooperative AI.
Another recurring framing is that cooperative AI is about improving the cooperative intelligence of advanced AI, which leads to the question of what cooperative intelligence is. Here also there are many different versions in circulation, but the following one is the one I find most useful so far:
Cooperative intelligence is an agent's ability to achieve their goals in ways that also promote social welfare, in a wide range of environments and with a wide range of other agents.
As you point out, a lot of what goes under “cooperative intelligence” sounds dual-use. For differential development to have a positive impact, we of course want to select aspects of it that robustly reduce risks of conflict (and escalation thereof). CLR’s research agenda lists rational crisis bargaining and surrogate goals/safe pareto improvements. Those seem like promising candidates to me! I wonder at what level to best to intervene with a goal of installing these skills and highlighting these strategies. Would it make sense to put together a “peaceful bargaining curriculum” for deliberate practice/training? (If so, should we add assumptions like availability of safe commitment devices to any of the training episodes?) Is it enough to just describe the strategies in a “bargaining manual?” Do they also intersect with an AI's “values” and therefore have to be considered early on in training (e.g., when it comes to surrogate goals/safe pareto improvements)? (I feel very uncertain about these questions.)
I can think of more traits that can fit into, “What specific traits would I want to see in AIs, assuming they don’t all share the same values/goals?,” but many of the things I’m thinking of are “AI psychologies”/“AI character traits.” They arguably lie closer to “values” than (pure) “capabilities/intelligence,” so I’m not sure to what degree they aren’t already covered by alignment research. (But maybe Cooperative AI could be a call for alignment research to pay special attention to desiderata that matter in messy multi-agent scenarios.)
To elaborate on the connection to values, I think of “agent psychologies” as something that is in between (or “has components of both”) capabilities and values. On one side, there are “pure capabilities,” such as the ability to guess what other agents want, what they’re thinking, what their constraints are. Then, there are “pure values,” such as caring terminally about human well-being and/or the well-being (or goal achievement) of other AI agents. Somewhere in between, there are agent psychologies/character traits that arose because they were adaptive (in people it was during evolution, in AIs it would be during training) for a specific niche. These are “capabilities” in the sense that they allow the agent to excel at some skills beneficial in its niche. For instance, consider the cluster of skills around “being good at building trust” (in an environment composed of specific other agents). It’s a capability of sorts, but it’s also something that’s embodied, and it comes with tradeoffs. For comparison, in role-playing games, you often have only a limited number of character points to allocate to different character dimensions. Likewise, the AI that’s best-optimized for building trust probably cannot also be the one best at lying. (We can also speculate about training with interpretability tools and whether it has an effect on an agent's honesty or propensity to self-deceive, etc.)
To give some example character traits that would contribute towards peaceful outcomes in messy multi-agent settings:
(I’m mostly thinking about human examples, but for many of these, I don’t see why they wouldn’t also be helpful in AIs as well with “AI versions” of these traits.)
Traits that predispose agents to steer away from unnecessary conflicts/escalation:
Agents with these traits will have a comparatively stronger interest in re-framing real-world situations with PD-characteristics into different, more positive-sum terms.
Traits around “being a good coalition partner” or “being good at building peaceful coalitions” (these have considerable overlap with the bullet points above):
“Good social intuitions” about other agents in one’s environment:
Lastly, there might be trust/cooperation-relevant procedures or technological interventions that become possible with future AIs, but cannot be done with humans:
To sum up, here are a couple of questions I'd focus on if I were working in this area:
A lot of the things I pointed out are probably outside the scope of "Cooperative AI" the way you think about it, but I wasn't sure where to draw the boundary, and I thought it could be helpful to collect my thoughts about this entire cluster of things in once place/comment.
I don't have anything intelligent to add to this, but I just wanted to say that I found the notion of AI psychologies and character traits fascinating, and I hope to ponder this further.
Thanks so much for this blog post. As you know, I've been attempting to understand Cooperative AI a bit better over the past weeks.
More concretely, I found it helpful as a conceptual exploration of what Cooperative AI is. Including how it relates to other adjacent (sub)fields - including the diagram! I also appreciated you flagging the potential dual-use aspect of cooperative intelligence - especially given the fact that you're working in this field and therefore be prone to wishful thinking.
That said, I would've appreciated if you covered a bit more about:
- Why Cooperative AI is important. I personally think Cooperative AI (at least as I currently understand it) is undervalued on the margin and that we need more focus on potential multi-agent scenarios and complex human interactions.
- What people in the field of Cooperative AI are actually doing - including how they navigate the dual-use considerations.
Do you think work on AI welfare can count as part of Cooperative AI (i.e. as fostering cooperation between biological minds and digital minds)?
I guess it depends? I wouldn't think "AI welfare" as a whole would fall under cooperative AI, I think there's probably a lot of work there which is not about cooperative AI (and I don't think that is what you are asking but just to be really clear).
But cooperation between biological and digital minds (more or less cooperation between humans and AI?) seems clearly to fall under cooperative AI, with the caveat that the single-human-to-single-AI is a bit of a special case which is less central to cooperative AI.
It's a while since I wrote this now, and today I would probably put more emphasis on that cooperative AI is typically focused on mixed-motive settings where the entities involved are not fully aligned in their objectives but neither fully opposed/adversarial. So if you have mixed-motive settings involving both biological and digital minds, and especially if there are many of them, figuring out how to get good outcomes (rather than cooperation failures) in these settings seems like it would be a question for cooperative AI research.
Thanks, I found this post helpful, especially the diagram.
What (if any) is the overlap of cooperative AI […] and AI safety?
One thing I’ve thought about a little is the possiblility of there being a tension wherein making AIs more cooperative in certain ways might raise the chance that advanced collusion between AIs breaks an alignment scheme that would otherwise work.[1]
I’ve not written anything up on this and likely never will; I figure here is as good a place as any to leave a quick comment pointing to the potential problem, appreciating that it’s but a small piece in the overall landscape and probably not the problem of highest priority.
Thanks - yes I agree, and study of collusion is often included into the scope of cooperative AI (e.g. methods for detecting and preventing collusion between AI models is among the priority areas of our current grant call at Cooperative AI Foundation).
Oh, interesting, thanks for the link—I didn’t realize this was already an area of research. (I brought up my collusion idea with a couple of CLR researchers before and it seemed new to them, which I guess made me think that the idea wasn’t already being discussed.)
Executive summary: The author shares their understanding of cooperative AI as an emerging field focused on making things go well in a world with multiple powerful AI systems and diverse human values, distinct from but related to AI alignment.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
What (if any) is the overlap of cooperative AI, AI ethics, and AI safety? Perhaps preventing catastrophic harm that is somehow tied to failures of fairness or inclusion?
I imagine that failures as Moloch / runaway capitalism / you get what you can measure would qualify. (Or more precisely, harms caused by these would include things that AI Ethics is concerned about, in a way that Cooperative AI / AI Safety also tries to prevent.)
Thank you for this post. The short description of AI Ethics is interesting. I spent time thinking about this issue when researching private law and AI - I ended up effectively stumbling into a definition centred around safe design on one hand and fair output on the other, but that did not feel quite right. I prefer your broader takeaway of fairness and inclusivity.
I really like the diagram! I found myself wondering where we would fit AI Law / AI Policy into that model. I think it is a very useful tool as an explainer.
Thank you Shaun!
I found myself wondering where we would fit AI Law / AI Policy into that model.
I would think policy work might be spread out over the landscape? As an example, if we think of policy work aiming to establishing the use of certain evaluations of systems, such evaluations could target different kinds of risk/qualities that would map to different parts of the diagram?


I started working in cooperative AI almost a year ago, and as an emerging field I found it quite confusing at times since there is very little introductory material aimed at beginners. My hope with this post is that by summing up my own confusions and how I understand them now I might help to speed up the process for others who want to get a grasp on what cooperative AI is.
I work at Cooperative AI Foundation (CAIF) and there will be a lot more polished and official material coming from there, so this is just a quick personal write-up to get something out in the meantime. We’re working on a cooperative AI curriculum that should be published within the next couple of months, and we’re also organising a summer school in June for people new to the area (application deadline April 26th).
When I started to learn about cooperative AI I came across a lot of different definitions of the concept. While drafting this post I dug up my old interview preparation doc for my current job, where I had listed different descriptions of cooperative AI that I had found while reading up:
To me this did not paint a very clear picture and I was pretty frustrated to be unable to find a concise answer to the most basic question: What is cooperative AI and what is it not?
At this point I still don’t have a clear, final definition, but I am less frustrated by it because I no longer think that this is just a failure of understanding or failure of communication - the situation is simply that the field is so new that there is no single definition that people working in the field agree on, and it is still an ongoing discussion where the boundaries should be drawn.
That said, my current favourite explanation of what cooperative AI is is that while AI alignment deals with the question of how to make one powerful AI system behave in a way that is aligned with (good) human values, cooperative AI is about making things go well with powerful AI systems in a messy world where there might be many different AI systems, lots of different humans and human groups and different sets of (sometimes contradictory) values.
Another recurring framing is that cooperative AI is about improving the cooperative intelligence of advanced AI, which leads to the question of what cooperative intelligence is. Here also there are many different versions in circulation, but the following one is the one I find most useful so far:
Cooperative intelligence is an agent's ability to achieve their goals in ways that also promote social welfare, in a wide range of environments and with a wide range of other agents.
The second major issue I had was to figure out how cooperative AI really differed from AI alignment. The description of “cooperative intelligence” seemed like it could be understood as just a certain framing of alignment - “achieve the goals in a way that is also good for everyone”.
As I have been learning more about cooperative AI, it seems to me like the term “cooperative intelligence” is best understood in the context of social dilemmas (collective action problems). The most famous model is the prisoner’s dilemma, in which it would be best for two agents collectively to cooperate, but where the rational decision for each individually is to defect, leading to a collectively worse outcome (e.g. arms race dynamics). Another famous model of a social dilemma is the tragedy of the commons which can be used to model overexploitation of shared resources (e.g. climate change).
The point is that in social dilemmas it is rational for each agent to defect, even if everyone would be better off if they were all cooperating. If we imagine a world with multiple powerful AI systems, social dilemmas are not solved by default by alignment. If two different groups have their own aligned AI systems, an interaction between these systems where they make rational and aligned choices can still lead to poor outcomes for both groups even if a better solution were possible. I understand “cooperative intelligence” as a concept that aims to capture the kind of capability that would be required in such a situation to achieve a collectively better outcome.
This is not only relevant for a situation with superhuman artificial intelligence. Even for more narrow or limited systems these kinds of dynamics could occur, leading to significantly harmful outcomes even if each system in isolation was safe.
In this paper which outlines the agenda for cooperative AI, the elements of cooperative intelligence are described as follows:
When I first read this I had just gone through Bluedot’s AI Safety Fundamentals course and I suspect I’m not the only one reacting to this list of capabilities (at least the first three points) with the thought that this sounds dangerous. Yes, these are capabilities that are useful for cooperation, but they are also the very same capabilities that are needed for deception, manipulation and extortion.
I still think this is true - these are potentially dangerous capabilities - but I also think these capabilities are being developed outside of cooperative AI. I think the right framing of cooperative AI is less as a field pushing capabilities forward in each of these areas, and more as an initiative to study these emerging capabilities and to work on achieving differential development in this area. What we need is to understand how we can promote beneficial cooperation while suppressing harmful tendencies and dynamics. There is clearly cause to be extremely cautious with this, and I think it’s important to recognize the components of cooperative intelligence as dual-use capabilities.
As cooperative AI is an emerging field the boundaries towards and overlaps with other fields are not yet well established. Below I share my current model of how I understand cooperative AI to fit in the wider landscape - note though that this is very much subject to change, and I would very much appreciate counter-suggestions and challenges in comments!
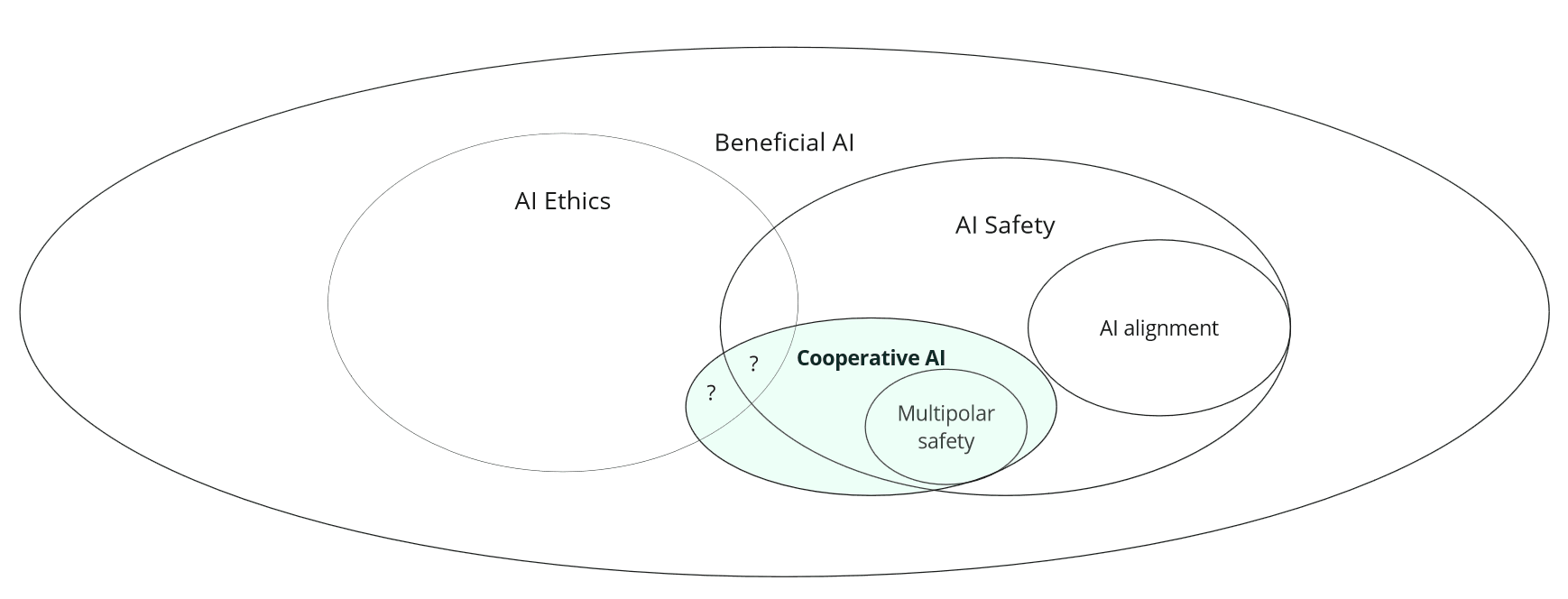
What Cooperative AI is not (in my current model):
What Cooperative AI is (in my current model):
What I am still very uncertain about:
What institutions or theorems guarantee that ASI or AGI will converge toward behaving as the rational agent that game theory assumes? According to the orthogonality thesis, any level of intelligence can pursue any arbitrary goal, so isn't there a possibility that it could make choices that are not rational? This also depends on whether the game is one of complete information or incomplete information.
I don't think there are any such guarantees? I think the point is not that ASI will definitely be rational, it is that ASI being rational and individually aligned is not a guarantee for good outcomes?