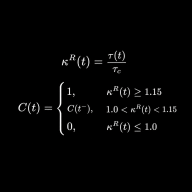
Another Container
Bio
Independent Researcher. Studying Structural Ethics, cross-domain coherence models, and open-sourced methodologies for AI Governance.
How others can help me
Looking for individuals to help pressure test a coherence based model in AI Systems, especially in its threshold dynamics and failure conditions.
Thank you,
Can be reached at MUESDummy@proton.me
Posts 2
Comments3
Thanks for the write up,
“ 1. The Anthropic IPO is coming ”
I really don’t mean to be a vibe killer here folks, and I hope enough developers find solid opportunities, and do not end up being immediately replaceable once they’ve steered the ship towards the least headwind.
And not to be reductionist, but isn’t it disheartening at all that from a game-theoretic sense that this entire “let’s make a moral statement that trends on AI safety”, is highly likely the entire point to secure that trillion dollar cap in a few months?
Having said that, I really do hope this works out for the long term.. because all I see is short term recruitment, customer retention, and investment hype, and after their achieved results it will be mass layoffs. I do hope I’m wrong though.
Hi Jacque, what sort of mechanisms have you researched so far that may be effective?
Interested to hear your conclusions so far, because AI Alignment is often spoke of by way of external legislative enforcement, corporate change, but rarely addressed at the fundamental base (mathematical layer in which reasoning is tracked), as many of the well-known models hire employees to work on linear regression and some KNN and then let them go once their job is done.
Thank you for this, your rigorously clarified a lot of thoughts I required and I’m sure many needed.
Most of us at first though may think AI Safety goes into where our intentions believe it’ll end up going to, rarely ever the case. And in this domain where valuations are becoming scary to say the least.