Comments
Sorry if I missed it, but are the logarithms here base 10?
Sorry if I missed it, but are the logarithms here base 10?
No, they're natural logarithms.
Thanks!
We initially drafted a writeup of these results in 2019, but decided against spending more time to finalize this draft for publication, given the large number of other projects we could counterfactually be working on, and given that our core results had already been reported (with permission) by Scott Alexander, which seemed to capture a large portion of the value of publishing.
We’re now releasing a lightly edited version of our initial draft, by request, so that our full results can be cited. As such, this is a ‘blog post’, not a research report, meaning it was produced quickly and is not to Rethink Priorities’ typical standards of substantiveness and careful checking for accuracy.
Scott Alexander reported the results of a small (n=50) experiment on a convenience sample of his Tumblr followers suggesting that the moral value assigned to animals of different species closely tracks their cortical neuron count (Alexander, 2019a). If true, this would be a striking finding suggesting that lay people’s intuitions about the moral values of non-human animals are highly attuned to these animals’ neurological characteristics. However, a small replication on Amazon Mechanical Turk (N=263) by a commenter called these findings into question by reporting very different results (Alexander, 2019b). We ran a larger study on MTurk (n=526) (reported in Alexander, 2019c)) seeking to explain these differences. We show how results in line with either of these two studies could be found based on different choices about how to analyze the data. However, we conclude that neither of these approaches are the most informative way to interpret the data. We present our own analyses showing that there is enormous variance in the moral value assigned to each animal, with large numbers of respondents assigning each animal equal value with humans or no moral value commensurable with humans, as well as many in between. We discuss implications of this and possible lines of future research.
Scott Alexander previously published the results of a small survey (n=50, recruited from Tumblr) asking individuals “About how many [of different non-human animals] are equal in moral value to one adult human?” (Alexander, 2019a)
A response that 1 animal of a given species was of the same moral value as 1 adult human, could be construed as assigning animals of this species and humans equal moral value. Conversely, a response that >1 individuals of a given species were of the same moral value as 1 adult human, could be construed as suggesting that those animals have lower moral value than humans.[1] In principle, this could also tell us how much moral value individuals intuitively assign to different non-human animals relative to each other (e.g. pigs vs cows).[2]
Alexander reported that the median value assigned by respondents to animals of different species seemed to track the cortical neuron count[3] (see Alexander 2019d) of these animals conspicuously closely (as shown in Figure 1) and closer than for other potential proxies for moral value, such as encephalization quotient.
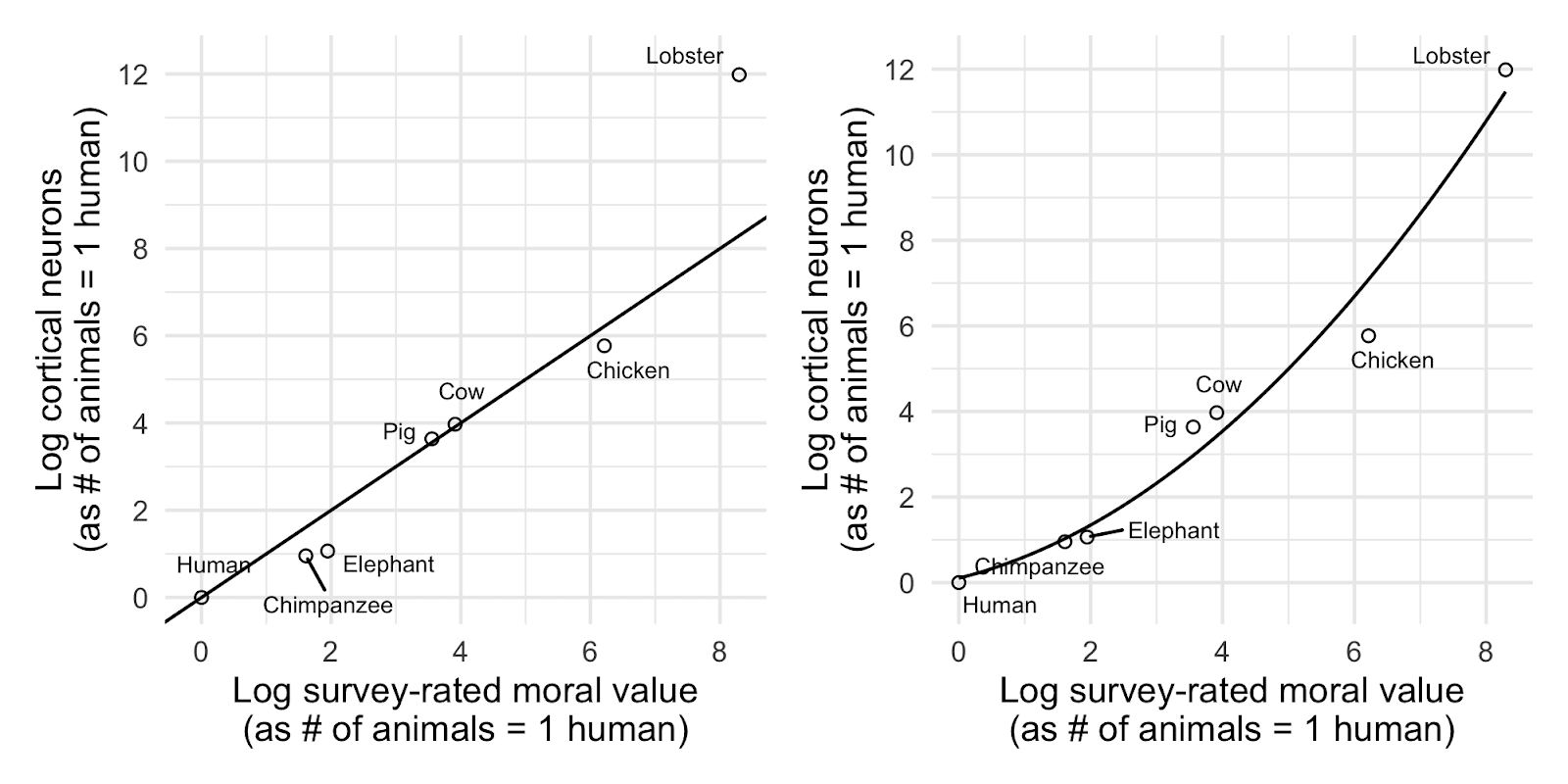
This apparent correlation between the moral value assigned to animals of different species and their cortical neuron count is particularly striking given that Alexander (2019d) had argued in a previous post that cortical neuron count, specifically, was strongly associated with animal intelligence.[4] Thus it might seem that the intuitive moral value assigned to animals of different species was closely linked to the intelligence of the animals. If so this would potentially, as Alexander put it, add “at least a little credibility” to intuitive judgments about the moral value of non-human animals. At the very least it would seem to suggest that the moral value assigned to non-human animals was largely driven by a factor that many would think is potentially morally relevant and seemingly little distorted by other arbitrary factors across species. For example, one might predict that lay individuals would relatively over-value non-human animals like chimpanzees, based on their human-like appearance, while under-valuing animals which are raised for food (see Bastian et al, 2012), relative to the actual cognitive capacities or other morally relevant characteristics of these animals. Yet the seemingly very strong correlation between neuron count and moral value across these species, could be taken to suggest that such factors do not appear to have much of a distortive influence.
This finding was seriously called into question by an attempted replication by a commenter, ‘Tibbar’, reported on Alexander’s post. Using a substantially larger (n=263 to Alexander’s n=50) and likely more representative (Mechanical Turk workers rather than readers of Alexander’s Tumblr page), Tibbar’s survey finds significantly lower median values - i.e. the respondents assign much higher moral value to animals of those species than Alexander.[5]
| Table 1: Reported results from Alexander and Tibbar (see Alexander, 2019a) | ||
|---|---|---|
| Alexander | Tibbar | |
| Lobster | 4000 | 60 |
| Chicken | 500 | 25 |
| Cow | 50 | 3 |
| Pig | 35 | 5 |
| Elephant | 7 | 1 |
| Chimpanzee | 5 | 2 |
| Human | 1 | 1 |
| Note: Number = this many of <animal> is morally equivalent to one human | ||
As there were substantial differences between and limitations to these two studies, a number of different factors could explain these divergent results. As noted above, Alexander’s study was based on an exceptionally small (only 50 people) convenience sample recruited via a post on Tumblr. Tibbar’s was drawn from a larger sample (263) drawn from MTurk, which is more commonly used as a subject pool for research and has been well-validated (Paolacci et al, 2010, see also Hurford, 2016 for a review). However, one possible limitation of Tibbar’s MTurk survey was that participants were offered a very low rate of reimbursement (~$1.20 per hour, around 5x lower than is typical for academic studies using the site), which may have lead to an unrepresentative sample of MTurkers being selected (those willing to work for much lower rates) or have lead to a less motivated and agreeable set of participants. As such, it is clear that neither survey was optimal from the point of view of getting reliable results.
There are two further important differences between the two surveys.
As noted, Alexander’s sample was drawn from a post on Tumblr and as such was much more likely to select participants who, being followers of Scott Alexander’s writings, were fairly familiar with rationalism, effective altruism and thus certain debates and points of view concerning animal consciousness and moral value. Notably, 80% of Alexander’s participants responded “yes” to the question “Are you familiar with work by Brian Tomasik, OneStepForAnimals, etc urging people to eat beef rather than chicken for moral reasons?”. While we don’t know that these respondents were familiar with Brian Tomasik’s work, rather than more popular campaigns urging people to eat beef rather than chicken for moral reasons, this still seems likely to be a much higher rate than one would encounter in the general population. Moreover, 42% of Alexander’s sample answered “yes” to the question “are you a vegetarian?”, 30% “sort of” vegetarian” and only 28% answered “no”, indicating rates of vegetarianism that are several times higher than the general population (Šimčikas, 2018).
Given this, Alexander’s survey might, perhaps, be better seen as examining the intuitions of a more select group of people who are relatively familiar with and sympathetic to certain moral arguments and positions than as a survey getting at the intuitions of a representative lay population.
Related to this, Alexander’s survey explicitly aimed to exclude, at the outset, individuals who did not believe that “animals have moral value which is in principle commensurable with the value of a human” (such individuals would, of course, not be able to give a meaningful answer as to the number of animals that have equal moral value to one adult human). Notably, 86% of those who responded to the survey indicated that they did think that animals have a moral value which is in principle commensurable with the value of a human. Tibbar’s survey, conversely, only asked “do you think animals have moral value?” which is compatible with animals not having commensurable moral value with humans.
It is quite striking, therefore, that despite Alexander’s sample likely being more familiar with arguments related to animal consciousness, EA and rationalism, the median moral value assigned to animals was significantly lower than in Tibbar’s survey. Ultimately, as noted, given the limitations of these two surveys (centrally, low sample size and little information about the characteristics of respondents, such as demographics, which might have influenced responses) it is hard to infer what might have influenced these differences or to be confident about the results.
Due to the limitations mentioned above, we ran our own study to explore these different results. For our own study we decided to run a larger sample, 500 people, using Mechanical Turk (US citizens only) and to gather basic information about demographics and vegetarian status.[6] While there were a variety of other measures that we considered might have been informative, such as additional demographics and psychological measures (including attitudes to animals and other moral or political attitudes, we decided to keep additional measures to a minimum for this initial study in order to minimize costs (adding one moderately sized animal attitude scale to the 7 species questions would have doubled the length and thus the cost of the study, for example). We think that including further measures would be worthwhile in any future study.
Our study design was deliberately kept largely similar to Alexander’s, however we chose to deviate in various details:
We aimed to recruit 500 participants from Mechanical Turk using the TurkPrime Platform (Litman et al, 2017) (US residents only, universal exclude list, blocked duplicate IP addresses, block duplicate geolocations, block suspicious geocode locations, verifying worker country locations). Workers were paid $0.40, giving a median hourly rate of $8/hr. Due to a mismatch between TurkPrime and our survey software (TurkPrime did not accept the completion codes of some participants and thus recruited more, but their responses were nevertheless recorded by SurveyMonkey), in fact, 526 sets of responses were recorded.
While our study is, in some senses, akin to a replication attempt, given the differences between Alexander’s and Tibbar’s studies and their divergent results, we were, in fact, almost entirely unclear about what results we should predict. Moreover, for reasons outlined above, we were quite uncertain as to what the best approach would be to interpret these results, given that we had significant reservations about the informativeness of simply relying on the median moral value assigned to each species (as Alexander and Tibbar had done), and questions also remained about whether respondents would systematically miscomprehend the questions (which would be impossible to discern until after we saw our results). As such, we did not pre-register analyses for this study. A pre-registered confirmatory study would be needed before we could have more confidence in these results.
Before we get to the results of our study, it is worth discussing a significant complicating factor in analyzing data about these moral value ‘equivalency’ scores (i.e. how many animals of a given species are equivalent in moral value to one adult human). The problem is that individuals can decline to specify an equivalence value or explicitly state they do not think that there is one. For a good discussion of these issues see Althaus (2017, p61). These responses can’t easily be included in an aggregate statistical analysis of the moral value assigned to animals of a specific species. It’s unclear what the average value of ‘1’, ‘3’, ‘5’, ‘100’ and ‘no number of chickens has commensurable moral value to one adult human’ would be.
In principle, we can still calculate the median value, including such responses. For example, in the set above, the median response would be ‘5’. However, one implication of this approach is that where the majority of respondents refuse to specify a value (e.g. the responses were 1, 5, decline, decline, decline), then the ‘median’ response would be declining to specify a value. This is particularly a problem where declining to specify a value might be motivated by heterogeneous reasons: these respondents might think animals have no moral value, or that their value is simply incommensurable or people might even think that they have infinitely more value than humans, although it seems likely that variants on the first two options are more common.
One might think that one can simply exclude such responses when calculating the value for each species. In the original case above, therefore, one could simply report that the median value specified (of 1, 3, 5 and 100) was 4 and that 1 out of 5 responses (20%) declined to report a value. However, this approach leads to problems. The main problem is that different numbers of respondents might choose to specify a value across different species. As such, each comparison between different conditions would, in fact, be comparing (perhaps dramatically) different samples of subjects, with some subjects having selected themselves out of the sample, at different rates for each condition. Indeed, the more individuals select themselves out of the analysis by declining to specify an equivalence value, the more the aggregate statistics of those respondents who do state a value will reflect only a small group of respondents who most value the species in question. For example, if 95% of respondents do not think that any number of lobsters is commensurable in value to one adult human, then the median value of those remaining respondents will reflect only the views of the 5% of respondents who most value lobsters, whereas the median values for other animals may reflect the views of a much broader sample.
One might think that given these difficulties, this setup is just a silly method to use. One might be especially inclined to think this if you think that this is just an idiosyncratic method taken from SlateStarCodex’s blog, which we are paying too much attention to. However, as noted in Althaus’ discussion cited above, this method of eliciting judgments, and other methods which are potentially vulnerable to the same problem are widely used in a number of academic fields.
Notably, within the EA community, the IDInsight Beneficiary Preferences study (Redfern et al, 2019), which informed GiveWell’s moral weights, faces the same issue. While intended to generate estimates of the monetary value of cash transfers that respondents would trade off against saving one life, many respondents always preferred to save the life no matter the amount of money and some always preferred the cash transfers. Across the full sample, comprised of respondents from two countries, almost half (46%) of respondents always preferred one or the other option, while in Ghana specifically, most respondents (52%) always preferred to save the life of a child, while a further 7% always preferred cash meaning about 60% declined to specify a trade-off value.
Despite the limitations described above, we present the median values found in our study below, in order to compare to Alexander and Tibbar’s results. We label the median values calculated based on including all responses with ‘(inc)’ and the median values based on excluding responses which declined to specify a value with ‘(exc)’.
Note that these are reproduced values based on our analysis of the data. This re-analysis produced different results than those reported by Tibbar, likely due to differences in recoding unusual responses (e.g., 1/2 to 0.5 rather than 1.5).
| Table 2: Neuron ratio and reproduced median moral values by survey, including all responses with ‘no number’ responses (inc.) and excluding ‘no number’ responses (exc.) | ||||||
|---|---|---|---|---|---|---|
| Neuron Ratio | Alexander (inc.) | Rethink Priorities (inc.) | Tibbar (inc. and exc.)[7] | Alexander (exc.) | Rethink Priorities (exc.) | |
| Lobsters | 160000.0 | 4000 | 1000 | 100 | 405 | 75 |
| Chickens | 320.0 | 500 | 1000 | 40 | 178 | 50 |
| Cows | 53.0 | 50 | 50 | 3 | 45 | 6 |
| Pigs | 38.0 | 35 | 50 | 5 | 30 | 10 |
| Elephants | 2.9 | 7 | 2 | 1 | 7 | 1 |
| Chimps | 2.6 | 5 | 4 | 2 | 5 | 2 |
| Humans | 1.0 | 1 | 1 | 1 | 1 | 1 |
| Note: Number = this many of <animal> is morally equivalent to one human | ||||||
As we see above, including the responses of participants who declined to specify a value, we find values that are relatively close to Alexander’s (i.e. higher numbers, thus ascribing relatively lower moral value to non-human animals). On the other hand, excluding those responses we find values that are much closer to Tibbar’s (i.e. lower numbers, ascribing higher value to non-human animals).
As noted in Alexander’s post summarizing our results (2019c), this seems to offer a neat explanation of the wide divergence between Alexander’s and Tibbar’s results. Alexander’s study directed respondents who thought that animals have comparable moral value to humans in principle, but that for particular species “it doesn’t work that way” to either leave the question blank or put in “99999”, which I will interpret as “basically infinity”.” Conversely, Tibbar’s survey did not direct respondents to do this.[8] When we exclude respondents who seem to have taken Alexander’s “leave the question blank or put in “99999”” option, we find much lower median values, similar to those in our data when we exclude respondents who declined to specify a trade-off value and similar to Tibbar’s lower value.
While this seems to resolve the discrepancy[9], it still leaves the question of what, if anything, we should make of these median values. Looking only at the median values obscures a lot of information about the responses and may be misleading, so in the next section we consider alternative analyses.
As a first step, it makes sense to examine the distribution of responses. The variability in these numbers is extremely high, with many respondents specifying that the moral value of one animal was equal in moral value to one adult human, for most of the species in question, while many other respondents either stated that no number of animals of that species were equal in moral value to an adult human or specified extremely high numbers (the maximum values specified for each species ranged from 10E+15 to 10E+46).
Given this, displaying the distribution of responses in an informative manner is not straightforward. The plot below shows the distribution of the log-transformed values, for each species. This does not make it easy to visualize the precise values assigned to the animals by different numbers of people, but does display the general tendency for more people to assign low equivalence values (i.e. higher moral value) to the creatures towards the top of the graph (such as chimpanzees and elephants), the very high overlap in value assigned to different species and the exceptionally long tail.
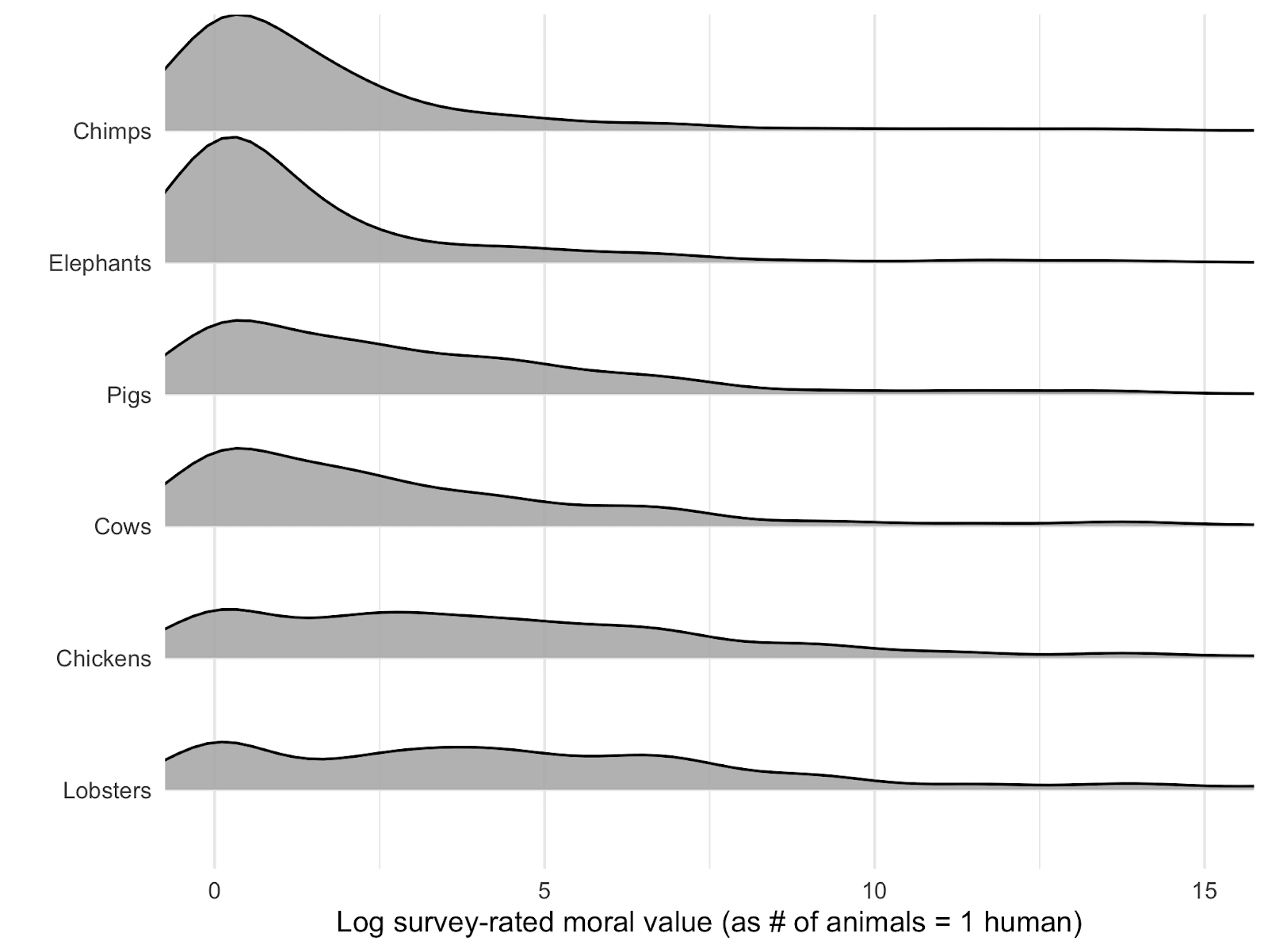
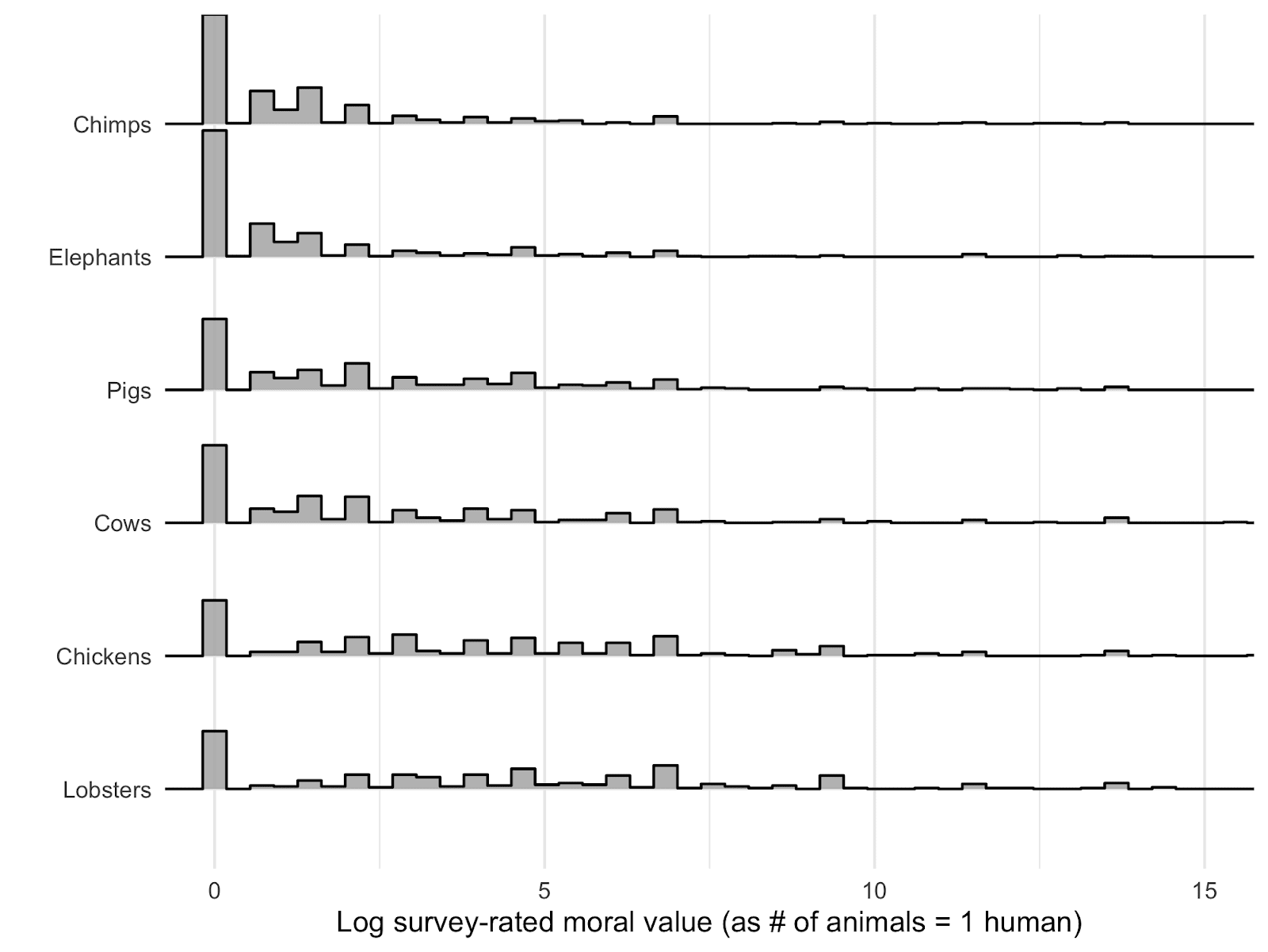
Given that these (log axis) distribution plots do not allow us easily to see the specific raw values that are being endorsed by respondents and cannot display the proportion of respondents declining to specify any equivalence value for different species, we also present a table of the responses below.[10]
| Table 3: Moral values by percentile | ||||||
| Percentile | Chimps | Elephants | Pigs | Cows | Chickens | Lobsters |
| 10th percentile | 1 | 1 | 1 | 1 | 1 | 1 |
| 20th percentile | 1 | 1 | 1 | 1 | 7 | 10 |
| 30th percentile | 1 | 1 | 5 | 4 | 20 | 50 |
| 40th percentile | 2 | 1.5 | 10 | 10 | 100 | 200 |
| 50th percentile | 4 | 2 | 50 | 50 | 1000 | 1000 |
| 60th percentile | 5 | 5 | 300 | 300 | 10000 | 100000 |
| 70th percentile | 50 | 100 | 112000 | 1e+06 | no number | no number |
| 80th percentile | 4.06e7 | no number | no number | no number | no number | no number |
| 90th percentile | no number | no number | no number | no number | no number | no number |
| Note: Number = this many of <animal> is morally equivalent to one human | ||||||
As we can see from this table taking the ‘median’ value as representative of the views of the sample would potentially be quite misleading. The number of respondents who are even vaguely close to the median value is, for many of these species, quite low. Notably, this table underplays the variation in individuals responses, by showing only each 10th percentile. For example, due to how extremely long-tailed the distribution is, the 70th-80th percentile for chimps ranges from people assigning chimps 1/50th the value of an adult human to people who assign chimps 1/4.06e7th the moral value commensurate of a human.
For each species there is a sizable (14.1-32.8%) of respondents who assign them equal value to humans, and a large share (18.3-31.6%) who think that there is no number of such animals that are of equivalent moral value to a single human. These categories are shown more clearly in the graph below.
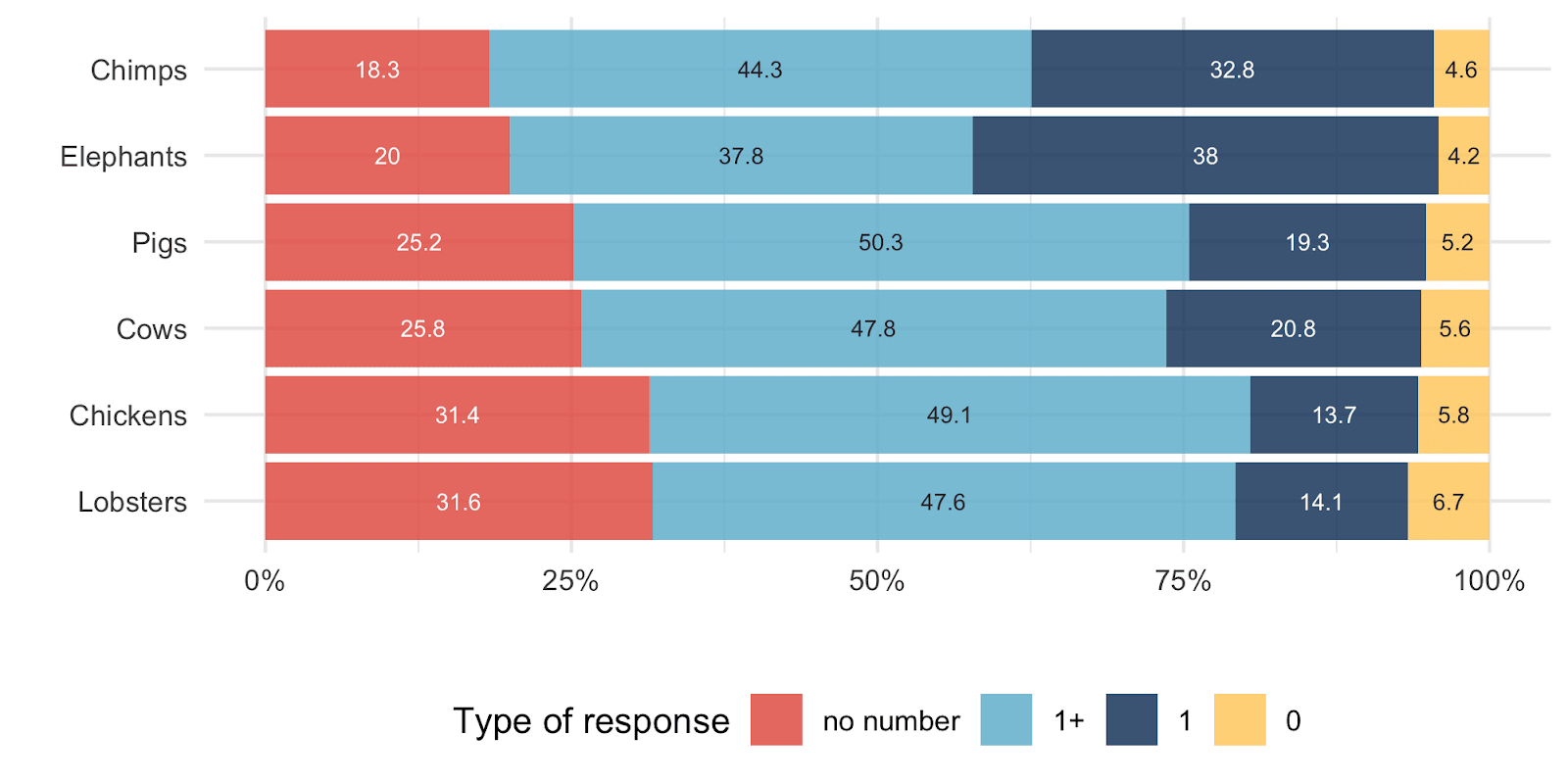
We think this provides a more informative view of the pattern of responses across species and highlights the limitations of relying on the median responses. But how to make sense of the apparently extremely high correlation between the median moral values and cortical neuron count?
The first thing to note is that the correlations are indeed extremely high and are high for all of the median values from each of the studies (whether or not people who refused to specify a trade-off are excluded), despite the fact that each of these values are very different from each other.
The graph below shows the correlation between the median values for each of the datasets. All are highly correlated with cortical neuron count.
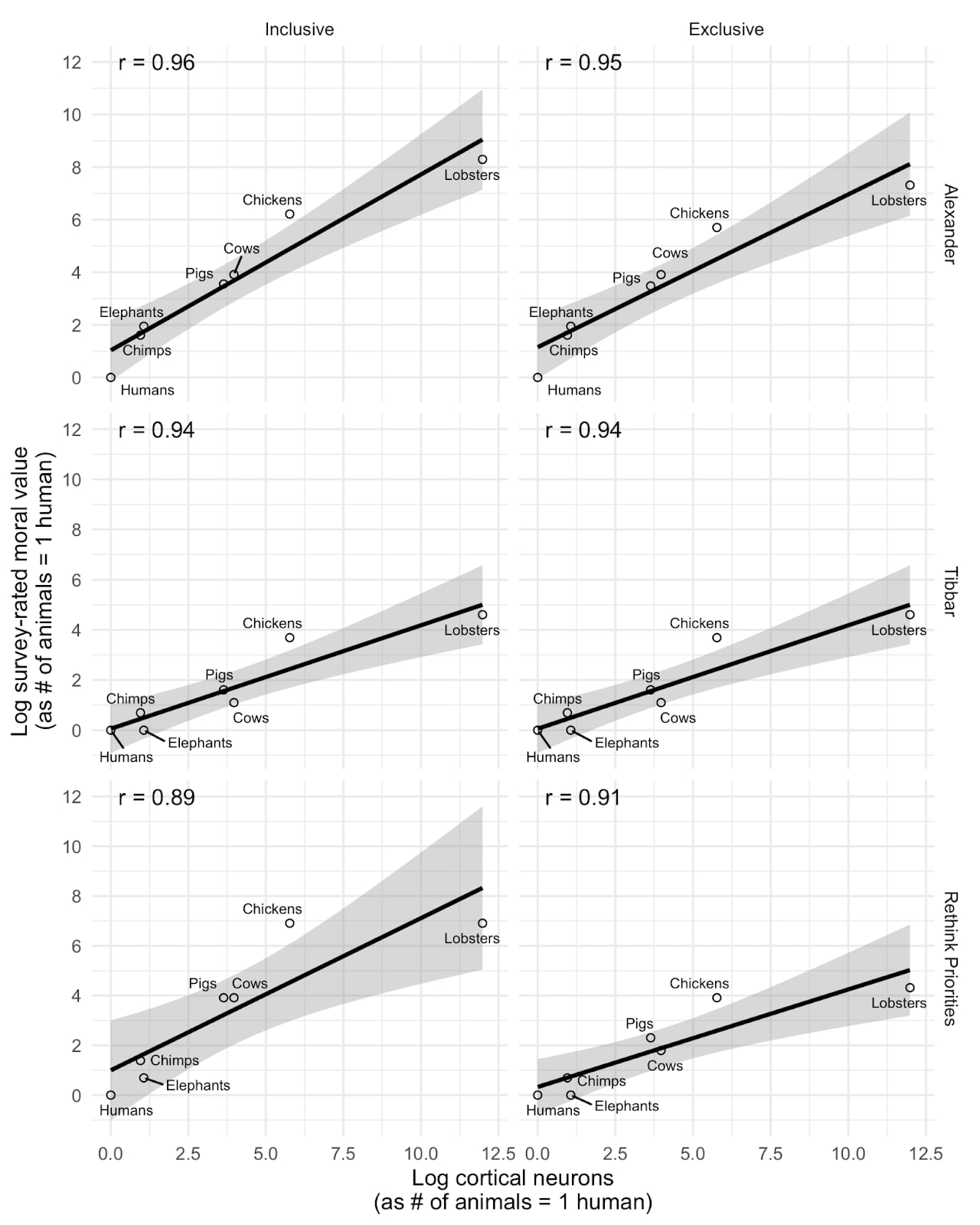
One might think that this is partly explained by lobsters being an extreme outlier but correlations were only slightly weaker when we dropped lobsters from the analysis. Another consideration is that this is based on only a small sample of animals[11]—with a wider variety, we might find a less clear relationship between neuron count and people’s judgments—although it’s not clear why this particular sample of animals should have led to such an apparently clear relationship.[12]
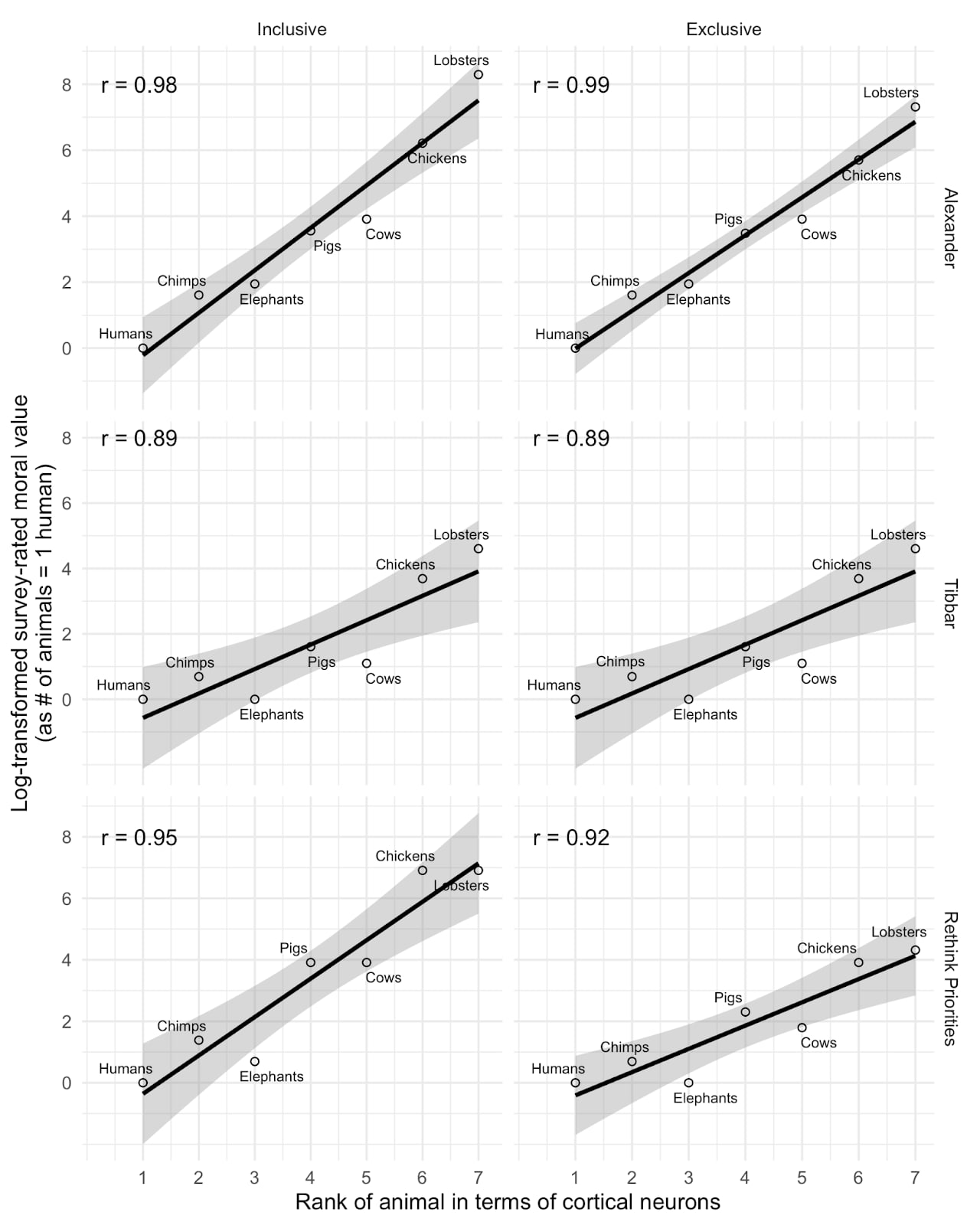
Notably, we also examined the correlation between neuron count and the log value of a simple ordinal ranking of the animals’ assigned moral value (i.e. 1, 2, 3, 4, 5, 6) and still found high correlations (shown below). In fact, the correlations are even higher than the correlations with the log-transformed neuron count, at least in our dataset and Alexander’s. Given this, we think that the similarly very high correlations between the median moral value and neuron count should not be seen as suggesting a surprisingly high correspondence between the specific moral value assigned to animals and their cortical neuron count, because these correlations remain high even when the specific values are removed.
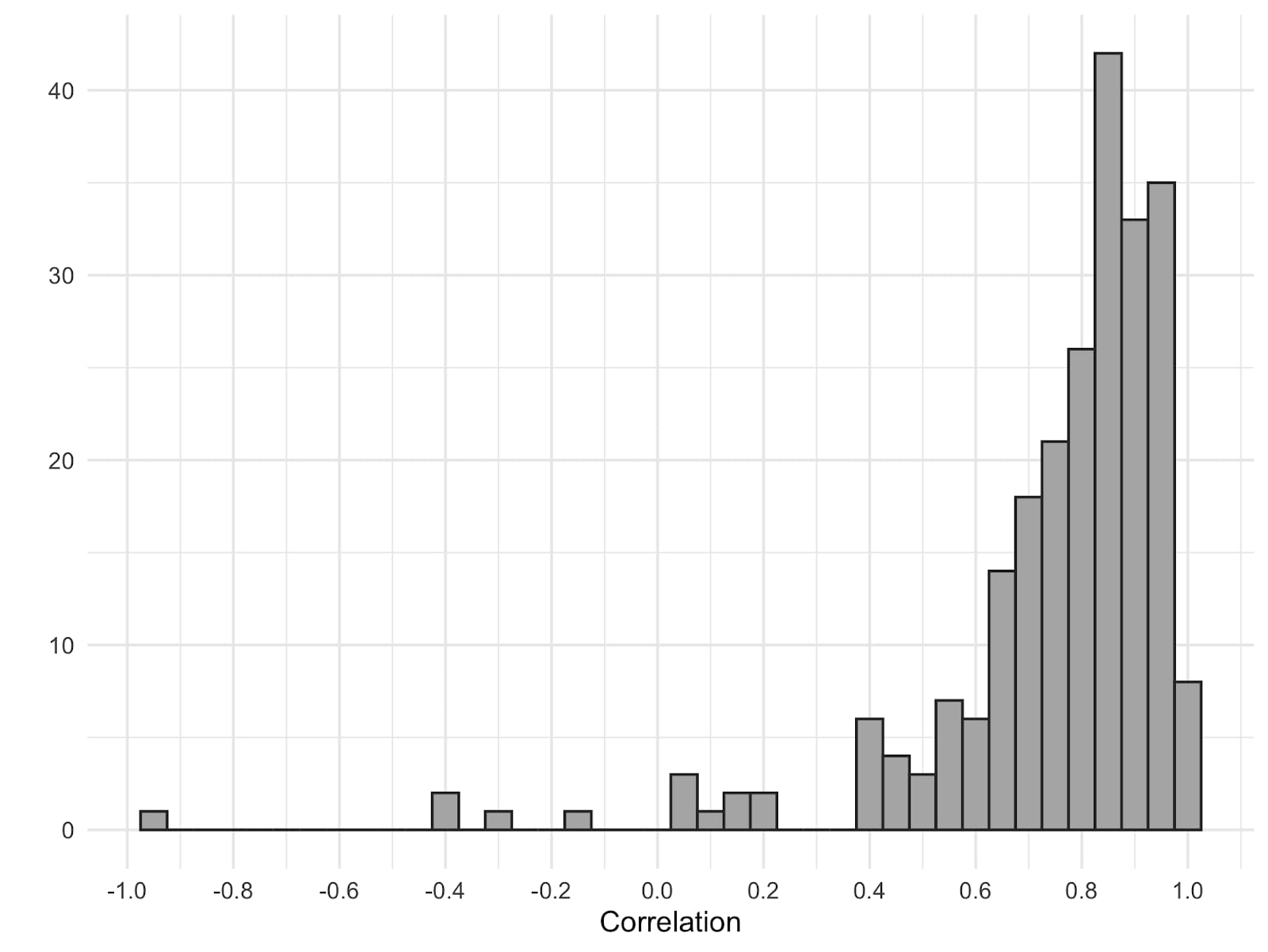
As noted above, the focus on the median value assigned to each animal obscures the very large variability in responses. A more typical way to analyze the association between the two variables would be to make use of all individual data points, rather than just the median for each category.[13] In Figure 6 we plot the distribution of correlations for each individual, showing that there are also strong correlations between moral value and neuron count for most individuals. In addition, we tried to fit a variety of models, but none of them fit the data sufficiently well. We suggest that it would probably be more productive to gather more and better data, rather than spending more time trying to model this particular data.
What to conclude from these results? While we have argued that the median values assigned to different animals are, at best, a limited indicator of the moral values that lay individuals assign to different animals, and that the correlation between these medians and the cortical neuron count of these animals is likely not particularly informative, the overall results may still tell us things of value.
These results do seem to show that there is wide variation in the moral value assigned to different non-human animals (at least using this paradigm). They also seem to suggest several sizeable sub-groups, who assign ~ zero moral value to different non-human animals, and one who assign ~ equal moral value to those non-human animals and adults humans and, in between, a contingent who assign some finite moral value (of widely varying degrees) to non-human animals, which they think is commensurable with that of humans.
As argued in this previous post, empirical evidence about laypeople’s judgments about the moral value of animals may be important to EAs in a number of ways:
Other research from Rethink Priorities (Schukraft, 2020), has also discussed how surveys of views (whether of the general population or relevant experts) might (or might not) inform our holistic judgments about the moral weight to be assigned to different animals. More generally, the question of “how can we make welfare comparisons across different kinds of animals” remains on the Global Priorities Institute research agenda (Greaves et al, 2019) and such data may be relevant to settle such questions.
Identifying the existence of these different contingents and the fact that they each appear to be fairly large seems potentially practically significant. Knowing how many people assign animals equal or zero value compared to humans, or somewhere in between, might influence animal advocacy strategy alongside other approaches which try to classify people’s attitudes (c.f. Faunalytics (2019), which clusters people into ‘advocates’, ‘allies’, ‘adversaries’ and ‘neutrals’). Better understanding people’s fundamental moral views about the value of non-human animals seems a potentially important part of understanding how far individuals’ more concrete animal attitudes can potentially be changed.[14] Identifying such sharply disagreeing clusters in the population may be more informative than trying to estimate the average moral views in the population in cases where there is radical disagreement between different views.
Further research aiming to identify such clusters could, of course, use a variety of different questions to try to examine whether individuals robustly assign different animals zero moral value, finite moral value commensurable with humans or equal moral value in different ways. Future research could also aim to identify different influences on or predictors of membership of these groupings (e.g. demographics or other moral attitudes). For example, we find a fairly consistent gender effect, with female respondents being more likely to indicate that animals have equal moral value to humans.
We also think that it is a potentially notable finding that although there are substantial differences in attitudes across different species (i.e. more people assign more value to chimps and elephants than chickens and lobsters) there are fairly sizeable contingents assigning both equal or zero value across each of these species of animal.
Also, while we have argued that the median value are, in principle, of limited use and these specific estimates are very uncertain[15], they are still potentially of use to compare EAs’ own estimates to (e.g., see discussion here and here).
If one were to pursue more research in this area, we believe that there are a variety of things that should be explored in future work.
Firstly, a number of different variations on this paradigm and alternative paradigms should be tested to compare results. For example, we anticipate that participants would likely give different responses were questions posed not in terms of the moral value of different species in the abstract, but in terms of concrete trade-offs, e.g., whether to save 1 human life or x animals. We would anticipate that this would likely lead to lower moral value being assigned to animals. Naturally there are theoretical, as well as methodological questions at play in considering which of these operationalizations are more appropriate and informative.
We also think that a wider variety of animals should be tested, which would serve as a more rigorous test of whether neuron count predicts moral value. This would also allow investigation of a wider variety of possible influences on ascribed moral value such as whether there are systematic differences between different broader categories of animals (e.g. fish, mammals, invertebrates).
Future surveys might also test how the animals are viewed on a variety of different characteristics, for example, how aesthetically pleasing, ‘cute’ or dangerous the animals are, and time since evolutionary divergence. These could also assess the influence of other factors such as body size, EQ, whether the animal is eaten and longevity. Such surveys could also investigate perceived intelligence directly, since this might be related to the apparent relationship between neuron count and perceived moral value.
This research is a project of Rethink Priorities. This post was written by David Moss and Willem Sleegers. We would like to thank Peter Wildeford, Jamie Elsey, Michael St. Jules, and Kim Cuddington for helpful comments.
If you like our work, please consider subscribing to our newsletter. You can see more of our work here.
Though, as we will discuss later, whether such interpretations are valid is open to question.
Assuming, that is, that individuals' responses are consistent and transitive: that if they report that 5 pigs are equivalent in value to 1 human and 10 cows are equivalent in value to 1 human, then they would also report that 5 pigs are equivalent in value to 10 cows. Again, this is open to question.
Note, Alexander’s figures for chickens were taken from (their wild ancestor) red junglefowl and the figures for cows are drawn from the neuron counts of springbok and blesbok and adjusted slightly downwards based on an assumption about the effects of domestication. In addition, it should be noted that lobsters, as we understand it, do not have any cortical neurons, being crustaceans, so we believe this number is extrapolated from their total neuron count.
AI Impacts similarly investigated the correlation between perceived intelligence and neuron count (McCaslin, 2019)
We used a Wilcoxon-Mann-Whitney test to check whether the moral value assigned to an animal in one survey tends to have values different from the other, by testing the hypothesis that the two independent samples are from populations with the same distribution. The results suggest that there is a statistically significant difference between the underlying distributions of moral values that respondents reported for each animal between the surveys.
This is a relatively lower sample size than we would use if we were running this study again in 2023, though the estimates for the medians are still relatively precise, with the exception of chickens and lobsters for which the data is more skewed and highly variable.
Tibbar’s dataset only included 7 ‘no number’ responses, which did not produce a difference in the median values.
We are not entirely confident how respondents would have interpreted Tibbar’s survey given this. One might suppose that, without an option to decline to specify a value, those respondents who don’t ascribe commensurable value to animals of non-human species would respond by writing in extremely high values, and that, assuming that there are similar proportions of respondents with these views in Alexander’s and Tibbar’s samples, this would lead to similar median values. It is possible that Tibbar’s broader opening question, (“do you think animals have moral value”) which was required to continue the survey, compared to Alexander’s more specific instructions, lead to more respondents who would assign animals no moral value excluding themselves by not completing the survey, leading to higher ratings.
That said, you could also imagine that, since this was MTurk and participants needed to complete the survey to be paid, that respondents who do not ascribe moral value to non-human animals would tick the box and then might be expected to respond either with extremely high numbers (leading to the opposite results than we found) or perhaps just ‘straight-lining’ the survey with the lowest cognitive effort response of entering ‘1’ every time or just with random numbers. It is also possible that Tibbar’s lower rate of pay lead to a higher rate of low effort responses like this. Fundamentally, not presenting respondents with the option to respond that they do not believe that any number of animals of a given species are of equivalent value to one adult human, is quite a large departure from the design of Alexander’s survey or our replication, and so it is hard to predict what the possible consequences of this change might have been (as above, respondents might have responded by giving much higher values, or they might have been nudged, in conjunction with the “do you think animals have moral value” question to respond with lower, clearly finite values.
Although the discrepancy might be increased further if the responses from participants in Alexander’s dataset who skipped the questions are included as assigning very high moral value to each species. It is, however, unclear how to interpret this group of participants. Given that we found, in our survey, that many respondents assigned a value to some animal species, but not to others, the setup from Alexander’s survey where respondents were asked to opt in or out of assigning value to any animals at the start of the survey may have influenced results.
We excluded responses of the value ‘0’ from the table below, because they seem impossible to interpret: prima facie they could be construed as assigning infinitely more value to non-human animals than to humans, but it seems more likely that they either express individuals trying to assign zero (commensurable) moral value to animals (despite our instructions to indicate this by writing “NO NUMBER”) or some other misreading or insincere/low effort responses. We examined the responses of the 42 (8%) of respondents who gave at least one ‘0’ response. Of these, 19 (45%) responded with 0 for all animals except humans, which seems plausibly interpreted as a sincere attempt to assign 0 moral value to these animals, though, of course is compatible with assigning more value to non-human animals or confusion/straight-lining responses. 7% responded with a 0 to all animals as well as humans, which could be interpreted as a sincere attempt to express the view that no commensurable value can be assigned (even when comparing individual humans), but might more plausibly be incomprehension or straightlining. 19 (45%) gave some kind of ‘mixed’ response, responding with a 0 to some non-humans but not others. These responses are quite heterogeneous and are yet harder to interpret.
Our thanks to Andrew Gelman for these suggestions.
This is assuming that the particular species included here were not implicitly selected to represent animals which were low/medium/high in cognitive complexity and perceived moral value.
If the question of interest is whether individual perceptions of moral value are tracking neuron count, then an analysis of individual data points seems necessary. An analysis which showed an association between the median moral value assigned to each species and neuron count is compatible with individuals’ responses not actually showing this pattern. However, an analysis of the medians might be informative for other purposes, e.g. if one believes this represents a kind of ‘wisdom of the crowd’ approach.
Of course, how far these ‘fundamental’ moral attitudes can be changed and what the relationship is between such views and attitudes regarding more concrete animal-related issues is a further question.
A larger sample size would be needed for more precise estimates. In addition, if the goal was to estimate the typical moral value assigned in the population as a whole, then it would be necessary to use a representative sample.


It’s hard to take these responses too literally since the median response for chicken was 1,000 and the average American consumes over 1,000 chickens per lifetime.
It would be interesting to focus group or hear from some of the respondents about the process they used to produce their answers.
Personally I think the largest part of the explanation of this is what we say here:
Note that in most studies of people's attitudes towards animals find that most people state significant levels of care for animals, while still eating them (the famous "meat paradox"), so this is not distinctive of this particular paradigm. I think it plausible that in the abstract, people do assign significant moral value to animals, despite their decision-making in concrete situations being in conflict with this. I think you would find similar inconsistencies between people ascribing high value to humans other than themselves or humans other than themselves, but not being willing to make minimal sacrifices to avoid harming them.
I think more data would be interesting, though I suspect in this case is would likely not be very informative. Very often people can't give particular reasons for the specific value they would assign to something (c.f. a statistical value of life paradigm where someone is asked how much they'd be willing to pay to reduce their risk of dying 0.001% over the next year). I think most people would struggle to explain why they think this is $1,000 or $10,000, despite not being conceptually confused about the judgement.