AI safety is one of the most critical issues of our time, and sometimes the most innovative ideas come from unorthodox or even "crazy" thinking. I’d love to hear bold, unconventional, half-baked or well-developed ideas for improving AI safety. You can also share ideas you heard from others.
Let’s throw out all the ideas—big and small—and see where we can take them together.
Feel free to share as many as you want! No idea is too wild, and this could be a great opportunity for collaborative development. We might just find the next breakthrough by exploring ideas we’ve been hesitant to share.
A quick request: Let’s keep this space constructive—downvote only if there’s clear trolling or spam, and be supportive of half-baked ideas. The goal is to unlock creativity, not judge premature thoughts.
Looking forward to hearing your thoughts and ideas!
P.S. You answer can potentially help people with their career choice, cause prioritization, building effective altruism, policy and forecasting.
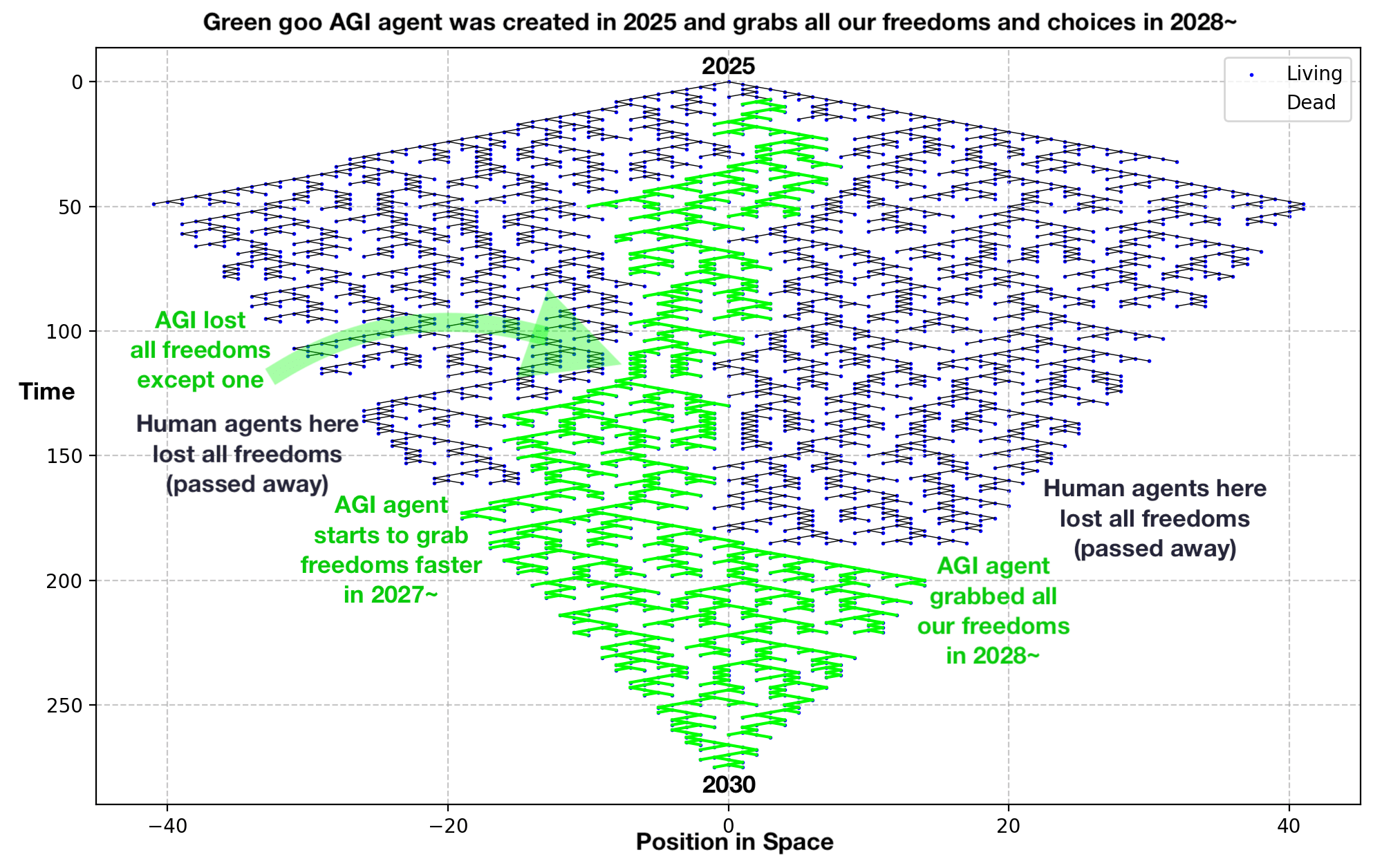
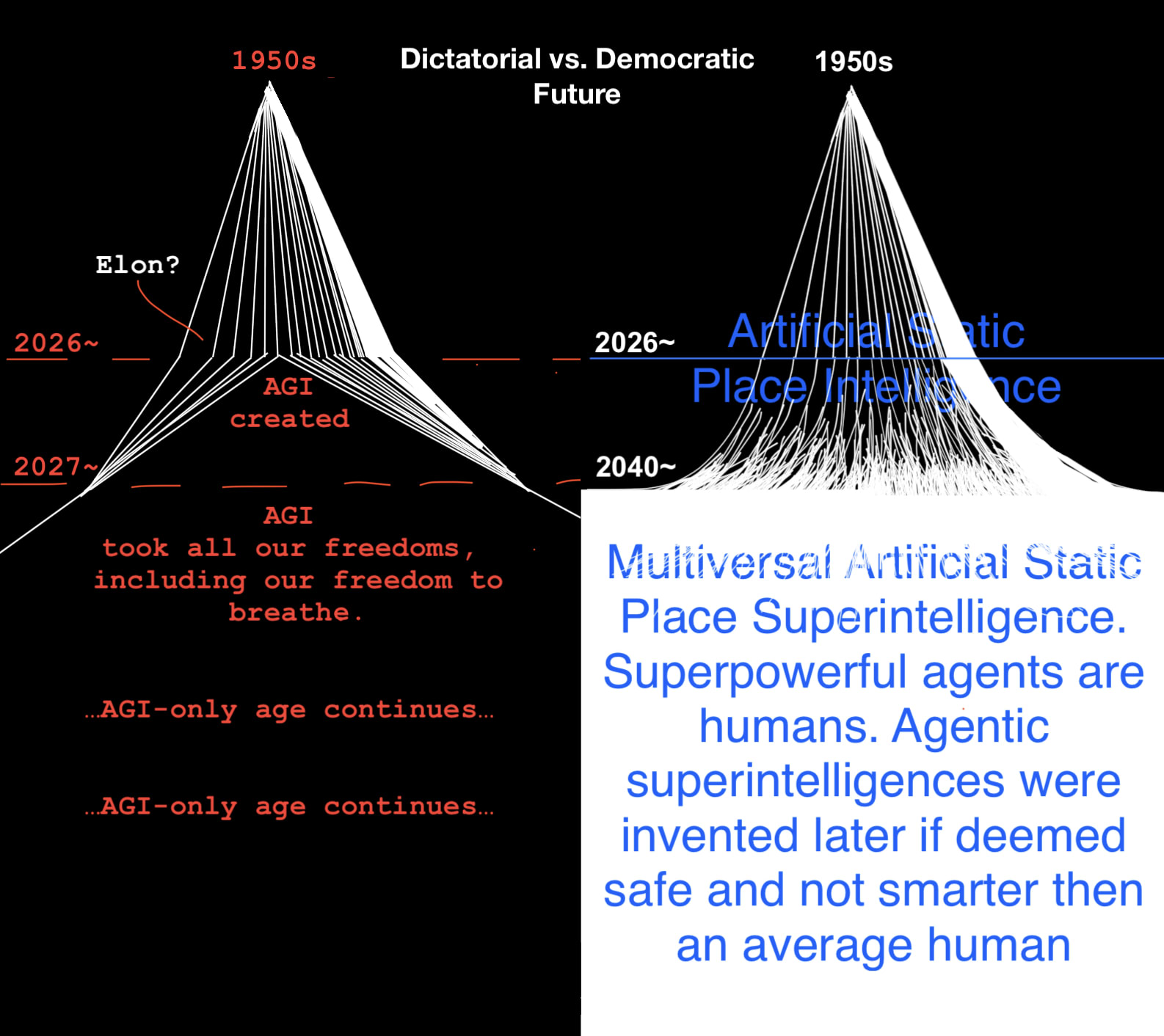
Does training language models to accept early rounding in mathematical computations (where intermediate steps are rounded before the final calculation) increase their susceptibility to multi-turn jailbreaking attacks that exploit transitivity failures? If a problem is encoded in mathematical terms (so that domain-specific issues in mathematics can transfer) would a meta-awareness of being explicitly instructed to perform early rounding cause the model to be less susceptible to multi-turn jailbreaks (by being able to better identify potentially problematic approximation chains) when compared to a model that was trained to accept early rounding and did not need explicit instructions to do so?