The Forecasting Research Institute conducted a survey asking different kinds of experts (including technical and non-technical) many questions about AI progress. The report, which was just published, is here. I've only looked at the report briefly and there is a lot that could be examined and discussed.
The major flaw I want to point out is in the framing of a question where survey respondents are presented with three different scenarios for AI progress: 1) the slow progress scenario, 2) the moderate progress scenario, and 3) the rapid progress scenario.
All three scenarios describe what will happen by the end of 2030. Respondents have to choose between the three scenarios. There are only three options; there is no option to choose none.
First, two important qualifications. Here’s qualification #1, outlined on page 104:
In the following scenarios, we consider the development of AI capabilities, not adoption. Regulation, social norms, or extended integration processes could all prevent the application of AI to all tasks of which it is capable.
Qualification #2, also on page 104:
We consider a capability to have been achieved if there exists an AI system that can do it:
- Inexpensively: with a computational cost not exceeding the salary of an appropriate
2025 human professional using the same amount of time to attempt the task.
- Reliably: what this means is context-dependent, but typically we mean as reliably as, or more reliably than, a human or humans who do the same tasks professionally in 2025.
With that said, here is the scenario that stipulates the least amount of AI progress, the slow progress scenario (on page 105):
Slow Progress
By the end of 2030 in this slower-progress future, AI is a capable assisting technology for humans; it can automate basic research tasks, generate mediocre creative content, assist in vacation planning, and conduct relatively standard tasks that are currently (2025) performed by humans in homes and factories.
Researchers can benefit from literature reviews on almost any topic, written at the level of a capable PhD student, yet AI systems rarely produce novel and feasible solutions to difficult problems. As a result, genuine scientific breakthroughs remain almost entirely the result of human-run labs and grant cycles. Nevertheless, AI tools can support other research tasks (e.g., copy editing and data cleaning and analysis), freeing up time for researchers to focus on higher-impact tasks. AI can handle roughly half of all freelance software-engineering jobs that would take an experienced human approximately 8 hours to complete in 2025, and if a company augments its customer service team with AI, it can expect the model to be able to resolve most complaints.
Writers enjoy a small productivity boost; models can turn out respectable short stories, but full-length novels still need heavy human rewriting to avoid plot holes or stylistic drift. AI can make a 3-minute song that humans would blindly judge to be of equal quality to a song released by a current (2025) major record label. At home, an AI system can draft emails, top up your online grocery cart, or collate news articles, and—so long as the task would take a human an hour or less and is well-scoped—it performs on par with a competent human assistant. With a few prompts, AI can create an itinerary and make bookings for a weeklong family vacation that feels curated by a discerning travel agent.
Self-driving car capabilities have advanced, but none have achieved true level-5 autonomy. Meanwhile, household robots can make a cup of coffee and unload and load a dishwasher in some modern homes—but they can’t do it as fast as most humans and they require a consistent environment and occasional human guidance. In advanced factories, autonomous systems can perform specific, repetitive tasks that require precision but little adaptability (e.g., wafer handling in semiconductor fabrication facilities).
So, in the slowest progress scenario, by the end of 2030, respondents are to imagine what is either nearly AGI or AGI outright.
This is a really strange way to frame the question. The slowest scenario is extremely aggressive and the moderate and rapid scenarios are even more aggressive. What was the Forecasting Research Institute hoping to learn here?
Edited on Friday, November 14, 2025 at 9:30 AM Eastern to add the following.
Here’s the question respondents are asked with regard to these scenarios (on page 104):
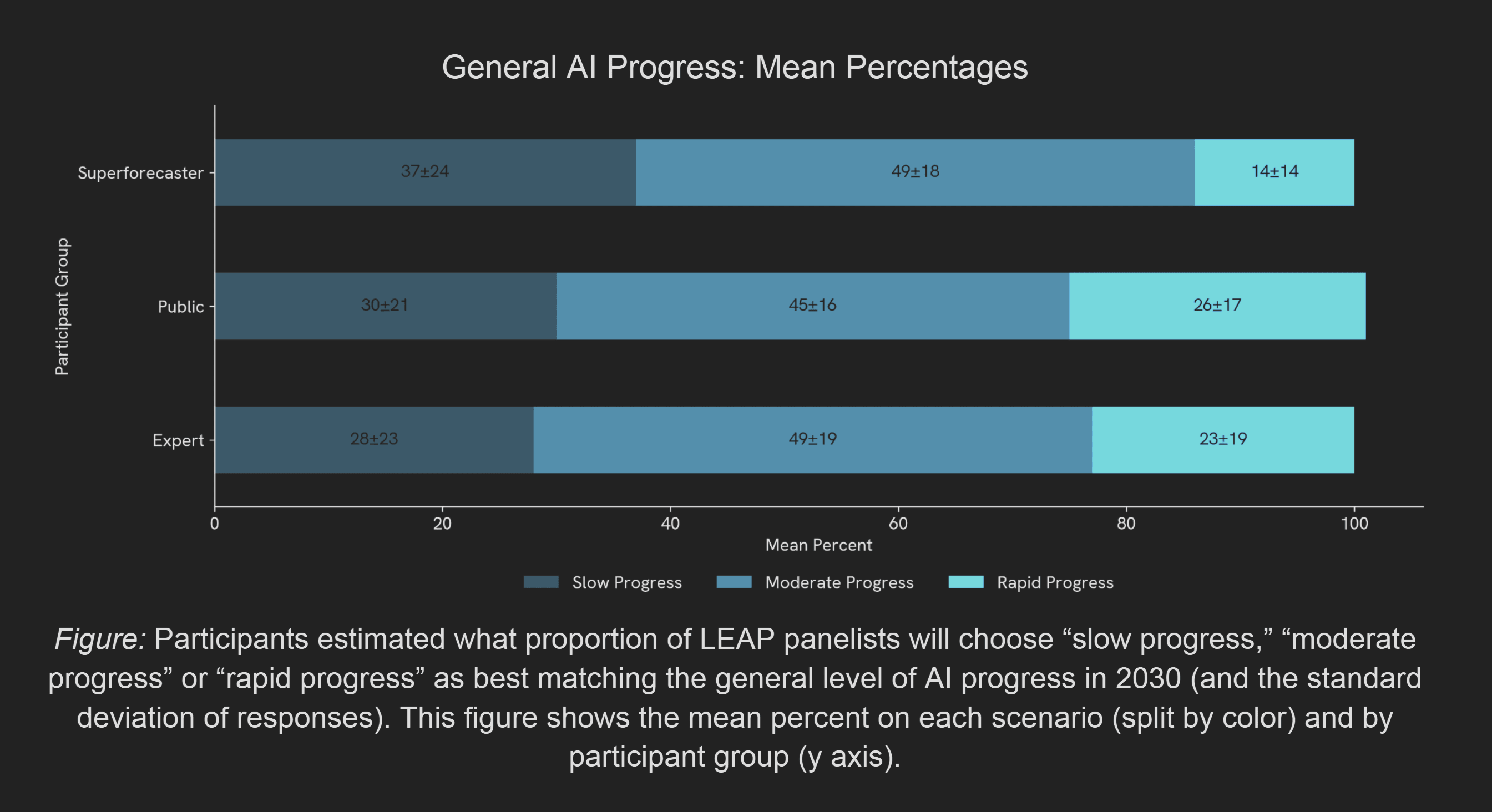
At the end of 2030, what percent of LEAP panelists will choose “slow progress,” “moderate progress,” or “rapid progress” as best matching the general level of AI progress?
The percent of panelists forecasted by the respondents is then stated in the report as the probability the respondents assign to each scenario (e.g. on page 38).
Edit #2 on Friday, November 14, 2025 at 6:25 PM Eastern.
I just noticed that the Forecasting Research Institute made a post on the EA Forum a few days ago that presents the question results as probabilities:
By 2030, the average expert thinks there is a 23% chance of a “rapid” AI progress scenario, where AI writes Pulitzer Prize-worthy novels, collapses years-long research into days and weeks, outcompetes any human software engineer, and independently develops new cures for cancer. Conversely, they give a 28% chance of a slow-progress scenario, in which AI is a useful assisting technology but falls short of transformative impact.
If the results are going to be presented this way, it seems particularly important to consider the wording and framing of the question.
Edit #3 on Saturday, November 15, 2025 at 10:10 PM Eastern.
I just learned that, in 2023, the Forecasting Research Institute published a survey on existential risk where the wording of a question changed the respondents’ estimated probability by 750,000x. When asked to estimate the odds of human extinction by 2100 in terms of a percentage, the median response was 5% or 1 in 20. When asked to estimate in terms of a 1-in-X chance with some examples of probabilities of events (e.g. being struck by lightning), the median response was 1 in 15 million or 0.00000667%. Details here.
Since there seems to be some doubt as to whether the way a question is worded or presented can actually bias the responses that much and whether this is really such a big deal — let there be no more doubt!
Edit #4 on Thursday, November 20, 2025 at 3:00 PM Eastern.
There is an additional concern — which is entirely separate and distinct from anything mentioned in the post above or any of the edits — with the intersubjective resolution/metaprediction framing of the question. See the volcano analogy in my comment here. (See also my Singularity example in my subsequent comment here.) I may be mistaken, but I don’t see how we can derive what the respondents’ probability for each scenario is from a question that doesn’t ask anything directly about probability.
Respondents are asked to predict, in December 2030, “what percent of LEAP panelists will choose” each scenario (not with any probability). This implies that if they think there’s, say, a 51% chance that 30% of LEAP panelists will choose the slow scenario, they should respond to the question by saying 30% will choose the slow scenario. If they think there’s a 99% chance that 30% of LEAP panelists will choose the slow scenario, they should also respond by saying 30% will choose the slow scenario. In either case, the number in their answer is exactly the same, despite a 48-point difference in the probability they assign to this outcome. The report says that 30% is the probability respondents assign to the slow scenario, but it’s not clear that the respondents’ probability is 30%.
The Forecasting Research Institute only asks for the predicted “vote share” for each scenario and not the estimated probabilities behind those vote share predictions. It doesn’t seem possible to derive the respondents’ probability estimates from the vote share predictions alone. By analogy, if FiveThirtyEight’s 2020 election forecast predicts that Joe Biden will win a 55% share of the national vote, this doesn’t tell you what probability the model assigns to Biden winning the election (whether it’s, say, 70%, 80%, or 90%). The model’s probability is certainly not 55%. To know the model’s probability or guess at it, you would need information other than just the predicted vote share.
Edit #5 on Tuesday, December 2, 2025 at 1:00 PM Eastern.
The Forecasting Research Institute has changed the language in the report in response to the critique described above in edit #4! (It seems like titotal played an important role in this. Thank you, titotal.)
On page 32, the report now gives the survey results in the same intersubjective resolution/metaprediction wording the question was asked in, rather than as an unqualified probability:
By 2030, the average expert thinks that 23% of LEAP panelists will say the state of AI most closely mirrors an (“rapid”) AI progress scenario that matches some of these claims.
This is awesome! I’m very happy to see this. Thanks to the Forecasting Research Institute for making this change.
I see also the EA Forum post where the LEAP survey was announced has been updated in the same way, so thanks for that as well. Great to see.
Edit #6 on Saturday, December 6, 2025 at 8:20 PM Eastern.
Titotal has published a full breakdown of the error involving the intersubjective resolution/metaprediction framing of the survey question. It’s a great post that explains the error very well. Many thanks to titotal for taking the time to write the post and for convincing the Forecasting Research Institute that this was indeed an error, which I could not do. Thanks again to the Forecasting Research Institute for revising the report and their EA Forum post about the report.
Edit #7 on Monday, December 8, 2025 at 3:45 AM Eastern.
See my comment here (on titotal’s post) for some concrete evidence that the slow progress scenario is too high as a baseline, minimum progress scenario.
For example, the slow progress scenario predicts the development of household robots that can do various chores by December 2030. Metaculus, which tends to be highly aggressive and optimistic in its forecasts of AI capabilities progress, only predicts the development of such robots in mid-2032. To me, this indicates the slow progress scenario stipulates too much progress.
Metaculus is already aggressive, and the slow progress scenario seems to be more aggressive — at least on household robots, depending how exactly you interpret it — than Metaculus.



(An author of the report here.) Thanks for engaging with this question and providing your feedback! I'll provide a few of my thoughts. But, I will first note that EA forum posts by individuals affiliated with FRI do not constitute official positions.
I do think the following qualification we provided to forecasters (also noted by Benjamin) is important: Reasonable people may disagree with our characterization of what constitutes slow, moderate, or rapid AI progress. Or they may expect to see slow progress observed with some AI capabilities and moderate or fast progress in others. Nevertheless, we ask you to select which scenario, in sum, you feel best represents your views.
I would also agree with Benjamin that "best matching" covers scenarios with slower and faster progress than the slow and fast progress scenarios, respectively. And, I believe our panel is sophisticated and capable understanding this feature. Additionally, this question was not designed to capture the extreme possibilities for AI progress, and I personally wouldn't use it to inform my views on these extreme possibilities (I think the mid-probability space is interesting and undeexplored, and we want LEAP to fill this gap). Given this, however, you are correct that we ought to include the "best matching" qualification when we present these results, and I've added this to our paper revision to-do list. Thanks for pointing that out.
I think other questions in the survey do a better job of covering the full range of possibilities, both in scenarios questions (i.e., TRS) and our more traditional, easily resolvable forecasting questions. The latter group comprise the vast majority of our surveys. I think it's impossible to write a single forecasting question that satisfies any reasonable and comprehensive set of desiderata, so I'd view LEAP as a portfolio of questions.
On edit #2, I would first note that it is challenging to write a set of scenarios for AI progress without an explosion of scenarios (and an associated increase in survey burden, which would itself degrade response quality); we face a tradeoff between parsimony and completeness. This specific question in the first survey is uniquely focused on parsimony, and we attempted to include questions that take other stances on that tradeoff. However, we'd love to hear any suggestions you have for writing these types of questions, as we could certainly improve on this front. I think you've identified many of the shortcomings in this specific question already. Second, I would defend our choice to present as probabilities (but we should add the "best matching" qualifier). We're making an appeal to intersubjective resolution. Witkowski et al. (2017) is one example, and some people at FRI have done similar work (Karger et al. 2021). These two metrics rely on wisdom-of-the-crowd effects. Again, however, I don't think it's clear that we're making this appeal, so I've added a note to clarify this in the paper. We use a resolution criterion (metaprediction) that some find unintuitive, but it allows us to incentivize this question. But, others might argue that incentives are less important.
While I think framing effects obviously matter in surveys, I do think that your edit #3 is conflating an elicitation/measurement/instrumentation issue in low-probability forecasting with the broader phenomenon of framing, which I view as being primarily but not exclusively about question phrasing. We're including tests on framing and the elicitation environment in LEAP itself to make sure our results aren't too sensitive to any framing effects, and we'll be sharing more on those in the future. I'd love to hear any ideas for experiments we should run there.
In sum, I largely defend the choices we made in writing this question. LEAP includes many different types of questions, because consumers of the research will have different views of the types of questions they will find informative and convincing. I will note that even within FRI some people personally find the scenarios questions much less compelling than the other questions in the survey. Nevertheless, I think you identified issues with our framing of the results, and we will make some changes. I appreciate you laying out your criticisms of the paper clearly so that we can dig into them, and I'd welcome any additional feedback!
Thank you very much for your reply. I especially want to give you my profound appreciation for being willing to revise how your results are described in the report. (I hope you will make the same revision in public communications as well, such as blog posts or posts on this forum.) A few responses which I tried to keep as succinct as possible, but failed to keep succinct:
Thanks again for a helpful, cooperative, and open reply.
Thanks for following up!
I am using ‘extreme’ in a very narrow sense, meaning anything above and below the scale provided for this specific question, rather than any normative sense, or making any statement about probabilities. I think people interpret this word differently. I additionally think we have some questions that represent a broader swath of possible outcomes (e.g., TRS), taking a different position on the the parsimony and completeness frontier. I suspect we have different goals in mind for this question.
I think others would argue that the slow progress scenario is barely an improvement over current capabilities. Given the disagreement people have over current capabilities, this disagreement on how much progress a certain scenario represents will always exist. We notably had some people who take the opposite stance you do, that the slow progress scenario has already been achieved.
I would maintain that we can express these results as the probability that reality best matches a certain scenario, hence the needed addition of the “best matches” qualifier. So, I’m not following your points here, apologies.
And for what it’s worth, I think the view that tasks = occupations is reasonably disputed. Again, I still grant the point that framing matters, and absolutely could be at play here. In fact, I’d argue that it’s always at play everywhere, and we can and should do our best to limit its influence.
This is a really great exchange, and thank you for responding to the post.
I just wanted to leave a quick comment to say: It seems crazy to me that someone would say the "slow" scenario has "already been achieved"!
Unless I'm missing something, the "slow" scenario says that half of all freelance software engineering jobs taking <8 hours can be fully automated, that any task a competent human assistant can do in <1 hour can be fully automated with no drop in quality (what if I ask my human assistant to solve some ARC-2 problems for me?), that the majority of customer complaints in a typical business will be fully resolved by AI in those businesses that use it, and that AI will be capable of writing hit songs (at least if humans aren't made aware that it is AI-generated)?
I suppose the scenario is framed only to say that AI is capable of all of the above, rather than that it is being used like this in practice. That still seems like an incorrect summary of current capability to me, but is slightly more understandable. But in that case, it seems the scenario should have just been framed that way: "Slow progress: No significant improvement in AI capabilities from 2025, though possibly a significant increase in adoption". There could then be a separate question on what people think about the level that current capabilities are at?
Otherwise disagreements about current capabilities and progress are getting blurred in the single question. Describing the "slow" scenario as "slow" and putting it at the extreme end of the spectrum is inevitably priming people to think about current capabilities in a certain way. Still struggling to understand the point of view that says this is an acceptable way to frame this question.
Thanks for the thoughts! The question is indeed framed as being about capabilities and not adoption, and this is absolutely central.
Second, people have a wide range of views on any given topic, and surveys reflect this distribution. I think this is a feature, not a bug. Additionally, if you take any noisy measurement (which all surveys are), reading too much into the tails can lead one astray (I don't think that's happening in this specific instance, but I want to guard against the view that the existence of noise implies the nonexistence of signal). Nevertheless, I do appreciate the careful read.
Your comments here are part of why I think including the third disclaimer we add that allows for jagged capabilities is important. Additionally, we don't require that all capabilities are achieved, hence the "best matching" qualifier, rather than looking at the minimum across the capabilities space.
We indeed developed/tested versions of this question which included a section on current capabilities. Survey burden is another source of noise/bias in surveys, so such modifications are not costless. I absolutely agree that current views of progress will impact responses to this question.
I'll reiterate that LEAP is a portfolio of questions, and I think we have other questions where disagreement about current capabilities is less of an issue because the target is much less dependent on subjective assessment, but those questions will sacrifice some degree of being complete pictures of AI capabilities. Lastly, any expectation of the future necessarily includes some model of the present.
Always happy to hear suggestions for a new question or revised version of this question!
Thanks for replying again. This is helpful. (I am strongly upvoting your comments because I'm grateful for your contribution to the conversation and I think you deserve to have that little plant icon next to your name go away.)
Apologies for the word count of this comment. I'm really struggling to compress what I'm trying to say to something shorter.
On "extreme": Thank you for clarifying that non-standard/technical use of the word "extreme". I was confused because I just interpreted it in the typical, colloquial way.
On the content of the three scenarios: I have a hard time understanding how someone could say the slow progress scenario has already been achieved (or that it represents barely an improvement over existing capabilities), but the more I have these kinds of discussions, the more I realize people interpret exactly the same descriptions of hypothetical future AI systems in wildly different ways.
This seems like a problem for forecasting surveys — different respondents may mean completely different things yet, on paper, their responses are exactly the same. (I don't fault you or your co-authors for this, though, because you didn't create this problem and I don't think that I could do any better at writing unambiguous scenarios.)
But, more importantly, it's also a problem that goes far beyond the scope of just forecasting surveys. It's a problem for the whole community of people who want to have discussions about AI progress, which we have a shared responsibility to address. I am not sure quite what to do yet, but I've been thinking about it a bit over the last few weeks.[1]
On intersubjective resolution/metaprediction: My confusion about the intersubjective resolution or metaprediction for the three scenarios question is I don't know how respondents are supposed to express their probability of a scenario being best matching vs. expressing how ambiguous or unambiguous they think the resolution of the prediction will be. If I think there's a 51% chance that before the end of 2030 the Singularity will happen, in which case the prediction would resolve completely unambiguously for the rapid progress scenario, what should my response to the survey be?
Should I predict 100% of respondents will agree, retrospectively, that the rapid progress scenario is the best matching one, since that is what will happen in the scenario I think is 51% probable? Or should I predict 51% of respondents will pick the rapid progress scenario, even though that's not what the question is literally asking, because 51% is my probability? (Let's say for simplicity I think there's a 51% chance of an unambiguous Singularity of the sort described by futurists like Ray Kurzweil or Vernor Vinge before December 2030 and a 49% chance AI will make no meaningful progress between now and December 2030. And nothing in between.)
It's possible I just have no idea how intersubjective resolution/metaprediction is supposed to work, but then, was this explained to the respondents? Can you count on them understanding how it works?
On "tasks" vs. "occupations": I agree that, once you think about it, you can understand why people would think automating all "tasks" and automating all "occupations" wouldn't mean the same thing. However, this is not obvious (at least, not to everyone) in advance of asking two variants of the question and noticing the difference in the responses. The reasoning is that, logically, an occupation is just a set of tasks, so an AI that can do all tasks can also do all occupations. The authors of the AI Impacts survey were themselves surprised by the framing effect here. On page 7 of their pre-print about the survey, they say (emphasis added by me):
The broader problem with Benjamin Tereick's reply is that he seems to be saying (if I'm understanding correctly) you can conclude there is no significant framing effect just by looking at the responses to one variant of one question. But if the AI Impacts survey only asked about HLMI and not FAOL, and just assumed the two were logically equivalent and equivalent in the eyes of respondents, how would they know, just from that information, that the HLMI question was susceptible to a significant framing effect or not? They wouldn't know.
I don't see how someone could argue that the authors of the AI Impacts survey would be able to infer from the results of just the HLMI question, without comparing it to anything else, whether or not the framing of the question introduced significant bias. They wouldn't know. You have to run the experiment to know — that's the whole point. Benjamin's argument, which I may just be misunderstanding, seems analogous to the argument that a clinical trial of a drug doesn't need a control group because you can tell how effective the drug is just from the experimental group. (Benjamin, what am I missing here?)
That's why I brought up the AI Impacts survey example and the 2023 Forecasting Research Institute survey example. Just to drive home the point that framing effects/question wording bias/anchoring effects can be extremely significant, and we don't necessarily know that until we run two versions of the same question. So, I'm glad that you at least agree with the general point that this an important topic to consider.
I think, unfortunately, it's not a problem that's easily or quickly resolved, but will most likely involve a lot of reading and writing to get everyone on the same page about some core concepts. I've tried to do a little bit of this work already in posts like this one, but that's just a tiny step in the right direction. Concepts like data efficiency, generalization, continual learning, and fluid intelligence are helpful and much under-discussed. Open technical challenges like learning efficiently from video data (a topic the AI researcher Yann LeCun has talked a lot about) and complex, long-term hierarchical planning (a longstanding problem in reinforcement learning) are also helpful for understanding what the disagreements are about and are also much under-discussed.
One of the distinctions that seems to be causing trouble is understanding intelligence as the ability to complete tasks vs. intelligence as the ability to learn to complete tasks.
Another problem is people interpreting (sometimes despite instructions or despite what's stipulated in the scenario) an AI system's ability to complete a task in a minimal, technical sense vs. in a robust, meaningful sense, e.g., an LLM writing a terrible, incoherent novel that nobody reads or likes vs. a good, commercially successful, critically well-received novel (or a novel at that quality level).
A third problem is (again, sometimes despite warnings or qualifications that were meant to forestall this) around reliability: the distinction between an AI system being able to successfully complete a task sometimes, e.g., 50% or 80% or 95% of the time, vs. being able to successfully complete it at the same rate as humans, e.g. 99.9% or 99.999% of the time.
I suspect, but don't know, that another interpretive difficulty for scenarios like the ones in your survey is around people filling in the gaps (or not). If we say in a scenario that an AI system can do these five things we describe, like make a good song, write a good novel, load a dishwasher, and so on, some people can interpret that to mean the AI system can only do those five things. Other people can interpret these tasks as just representative of the overall set of tasks the AI system can do, such that there a hundred or a thousand or a million other things it can do, and these are just a few examples.
A little discouragingly, similar problems have persisted in discussions around philosophy of mind, cognitive science, and AI for decades — for example, in debates around the Turing test — despite the masterful interventions of brilliant writers who have tried to clear up the ambiguity and confusion (e.g. the philosopher Daniel Dennett's wonderful essay on the Turing test "Can machines think?" in the anthology Brainchildren).