Comments


The Unjournal is a nonprofit organization (est. 2023) that commissions rigorous public expert evaluations of impactful research. We've built a strong team, completed more than 55 evaluation packages, built a database of impactful research, launched a Pivotal Questions initiative, and are systematically evaluating research from EA-aligned organizations
1. EA-driven research would benefit from external expert scrutiny to improve decision-making.
2. Academic research contains valuable insights but needs steering toward impact and usefulness.
3. The Unjournal bridges this gap through rigorous public evaluations of both EA-driven and academic research and ‘pivotal questions’. Our approach is more transparent and efficient than traditional academic journal peer review, but more rigorous and structured than crowdsourcing feedback, e.g., on the EA Forum.
4. We’re having some success. Our work has contributed to methodology and funding considerations at GiveWell, brought senior and prominent academics into the global priorities conversation, shaped animal welfare funding priorities, and provided quality control for EA organizations that use and produce research.
The Unjournal commissions public evaluation packages: referee-style assessments, quantitative ratings, and "merited journal tier" recommendations. See our output and ratings dashboard, and claim assessment.
We're at an inflection point. Future grant funding will determine whether we can continue to scale our output and impact. Marginal funding will yield additional evaluations of EA-relevant research (funding human experts and benchmarking AI capabilities) as well as synthesis, communication, and direct assessment of additional Pivotal Questions, in coordination with impact-focused organizations like Founders’ Pledge and Animal Charity Evaluators.
Above: Slides from a Nov. 2023 presentation for EA Anywhere (YouTube)
EA organizations are making high-stakes decisions based on research that may not have received adequate methodological scrutiny. The most rigorous traditional journals often won't evaluate EA-aligned work (perceived as "too niche"). The peer-review process is opaque, it can take many years, and it often emphasizes novelty, cleverness, and connection to existing theoretical frameworks, rather than impact or credibility. [1] On the other hand, EA Forum discussions, though valuable, may lack depth in specific technical areas. This creates potential blind spots we can help correct.
We commissioned two experts (an economist/forecaster and a cellular-ag biologist) to evaluate Rethink Priorities’ 2022 cultured-meat forecast (in connection with our ongoing Pivotal Question on this). They each raised specific doubts and offered updates suggesting that the forecast report may have been overly pessimistic in important ways, contributing to a potential broader reconsideration of this issue.
GiveWell’s reconsideration and increasing support (over $145 million in grants) for water quality interventions was strongly influenced by Kremer et al’s (2022) meta-analysis and CEA. However, this work has (still) never been published in a peer-reviewed journal, so practitioners and funders had to rely on the authors’ reputations and their own judgment about its relevance and trustworthiness. Unjournal’s expert evaluators (including a team running a related meta-analysis) found the work useful but also raised substantial issues with the meta-analysis, interpretation, and cost-estimates. The authors responded in detail and adapted many suggestions in an updated version. In followup conversations, GiveWell noted they found the suggestions and updates useful, and this ultimately strengthened their confidence in the effectiveness of chlorination programs.
In a similar vein, see our “Intergenerational Child Mortality Impacts of Deworming” package.
Several evaluations highlighted limitations (as well as strengths) in the approaches of ~EA-prominent or EA-adjacent work, providing concrete suggestions for follow-up and improvement in future work. These addressed common methods including:[2]
Meta-analysis across heterogeneous studies – see evaluations of “Meaningfully reducing consumption of meat and animal products is an unsolved problem…”, and EA Forum discussion here, as well as “The wellbeing cost effectiveness of StrongMinds and Friendship Bench: review and meta-analysis with charity-related data”.[4]
Our ongoing Pivotal Questions projects will tackle
Meanwhile, mainstream academic research that could transform EA priorities and estimates may be neglected by EA-aligned organizations and funders because they fail to communicate in legible ways or do not provide useful inputs, like uncertainty bounds or cost figures, that are critical for CEAs, BOTECs, etc. In our public evaluation of this work, we prioritize credibility, impact, usefulness, and sharing outputs like these, often making specific follow-up requests to the authors[5].
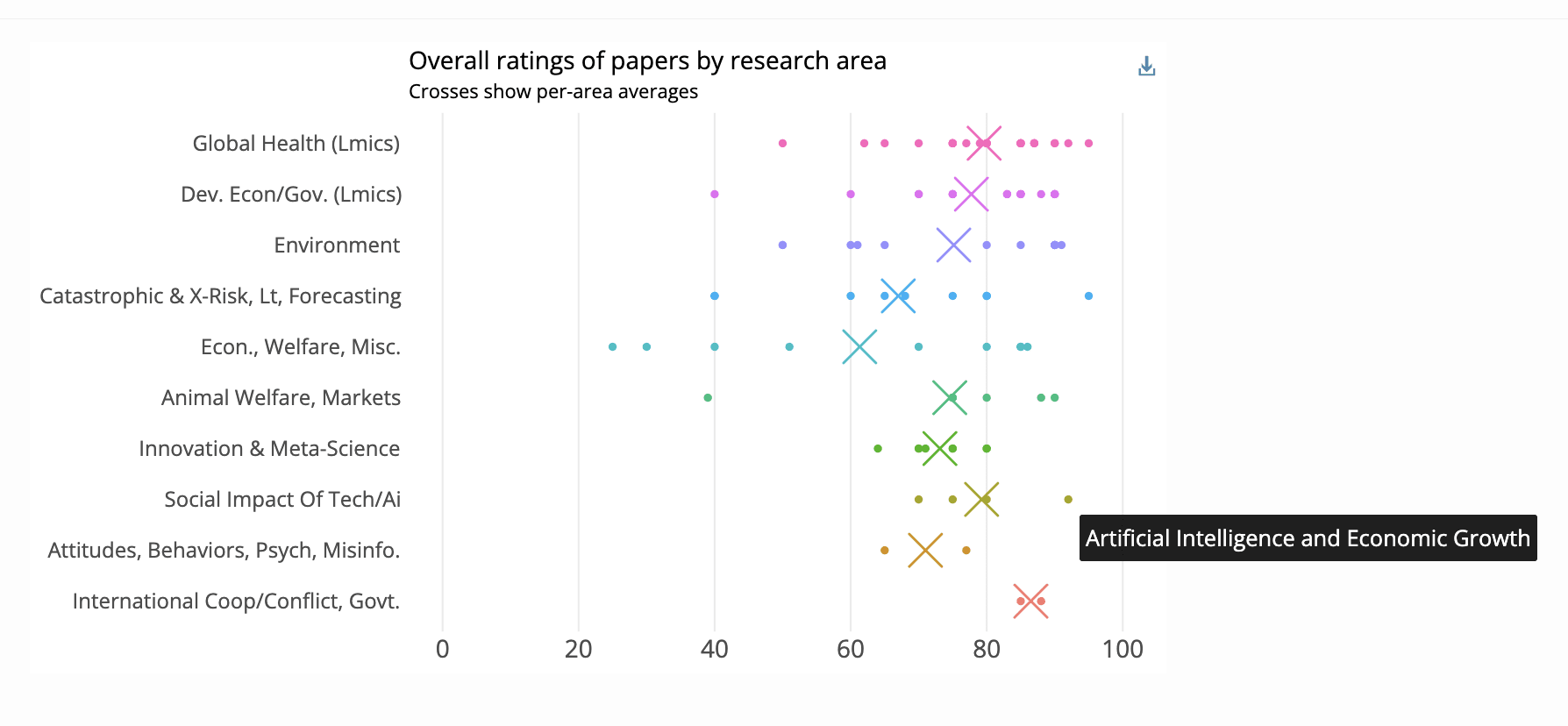
Above image: "Overall ratings" (midpoints) for research evaluated by The Unjournal, by cause area
Our field specialist teams prioritize research for global priorities impact potential. Our evaluation managers commission PhD-level and senior career expert researchers and practitioners to rigorously evaluate research that matters for global priorities. We elicit detailed reports focused on credibility and usefulness, benchmarked ratings and predictions and claim elicitation/assessment. There is some dialogue – authors can respond, evaluators can adjust, and managers synthesize the results. We’re further exploring leveraging LLM tools to enhance the process, and learn about AI research capabilities/tastes. We make it all public at unjournal.pubpub.org (and our data blog/dashboard, enabling comparisons and benchmarking), visible in academic databases, and promote it on forums and social media. (Learn about our process in more detail here.)
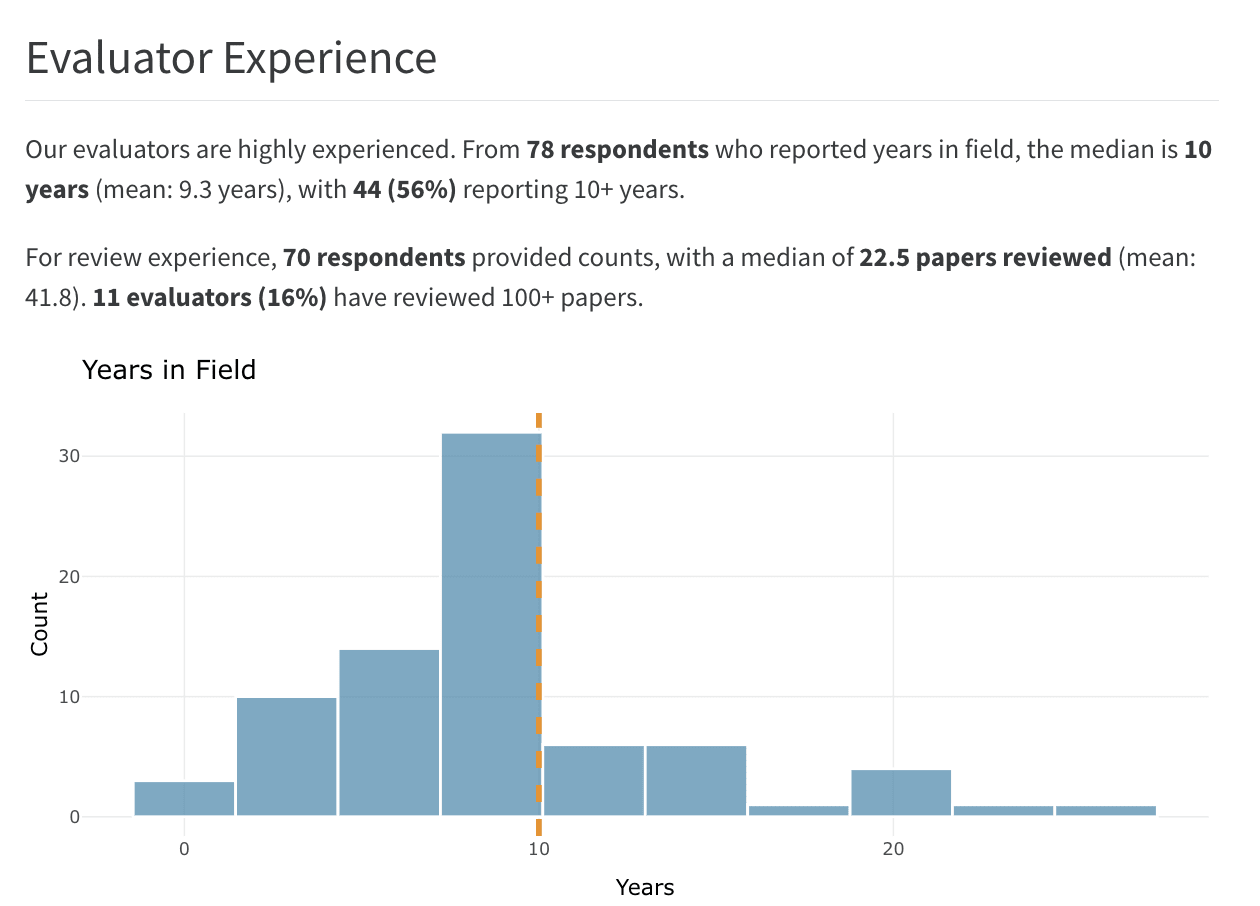
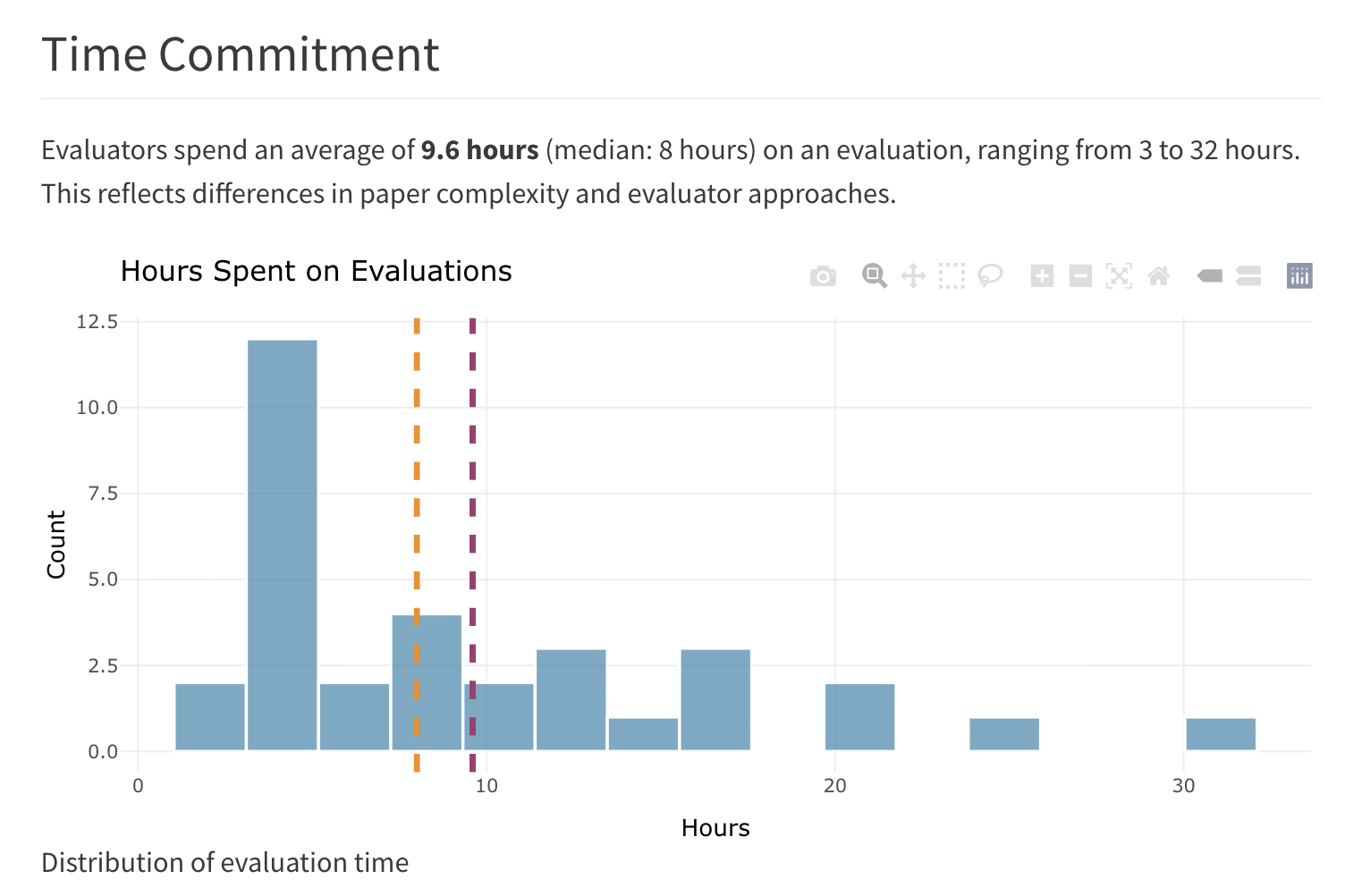
Images above: from a recent post on our data blog
Our current funding comes from grants especially from the Survival and Flourishing Fund (see all our grant applications and reports here). We are actively applying for further grant funding, partnerships, and project sponsorship; this will determine whether we can continue to operate at the current (or greater) scale, and the extent we can compensate and incentivize expert evaluators and field specialists. (See footnote: The importance of incentives and compensation.[6])
We plan to continue The Unjournal project indefinitely, even without a further large grant, but this would be on a more limited basis, relying largely on voluntary effort.
Marginal funding (with or without large grant funding) will enable:
Current costs:
Current budget allocation:
4.4% prioritization incentives
55+ evaluation packages completed across areas including:
Systematic evaluation of research from EA organizations: We're working to evaluate at least one piece of research from every EA-funded research organization in our domain, offering transparent, public quality control and feedback.
Pivotal Questions initiative: Working directly with funders to identify and operationalize their highest-uncertainty, highest-value questions, curating and evaluating relevant research with these in mind, eliciting beliefs, and providing updates.
Engagement with a range partners on specific porjects and events: Including the Institute for Replication, Effective Thesis, and the Center for Open Science.
We give a full logic model and an explanation here. A very succinct summary below:
Rigorous evaluation → Corrected errors → Better funding decisions → Lives saved/suffering reduced
↓ ↓ ↓
Academic credibility → More EA research → Mainstream adoption of EA priorities
↓ ↓
Transparent process → Trust in EA epistemics → Long-term movement growthEngage with our work:
Join our community and our team, suggest work, etc.: See opportunities here, including our evaluator pool, field specialist teams, and Independent evaluations (trial).
Donate or contact [email protected] to discuss a donation or sponsorship.
The Unjournal is a registered 501(c)(3) nonprofit. We accept unrestricted as well as earmarked gifts for specific cause areas and commissioned project work (with some limitations). We can offer specific recognition to sponsors, e.g., “this set of evaluations was made possible by a generous donation from…"
As well as a host of other problems and limitations including editorial favoritism and prestige bias, limited static formats, and distorted incentives.
Evaluators also raised somewhat overlapping conceptual and ~design/framing issues in the context of Experiments and surveys tied to moral philosophy – see evaluations of “Ends versus Means: Kantians, Utilitarians, and Moral Decisions”, “Population ethical intuitions”, “Willful Ignorance and Moral Behavior", and “The animal welfare cost of meat: evidence from a survey of hypothetical scenarios…”
Here, for example, both evaluators rated the paper highly and found this work valuable and meaningful for policy and discussions of AI safety. They also highlighted important limitations (including sampling bias, classification of practices, interpretation of results, and abstract agreement vs. real-world implementation)
Evaluators also raised somewhat overlapping conceptual and ~design/framing issues in the context of Experiments and surveys tied to moral philosophy – see evaluations of “Ends versus Means: Kantians, Utilitarians, and Moral Decisions”, “Population ethical intuitions”, “Willful Ignorance and Moral Behavior", and “The animal welfare cost of meat: evidence from a survey of hypothetical scenarios…”
I have more to say about this but limited time, and this post is getting long.
Our team of academics, experts, and practitioners prioritizes and curates high-value research, and guides and manages the evaluation process. We target compensation ~$50/hour for senior professional/PhD-level work, to signal that we value this effort and expertise. We offer performance incentives for experts to rigorously evaluate research and pivotal questions in detail, focusing on credibility and impact.
See why we pay our evaluators. We think the results speak for themselves – compare our evaluation work at unjournal.pubpub.org to more voluntary crowdsourced models. TLDR: Incentivizing useful, unbiased, timely evaluations; fairness and equity, incentives for people to put effort into a new system and help us break out of the old inferior equilibrium, and we can't (and don't want to) offer favorable journal treatment to authors who served as evaluators.


I really love this idea. This is my first time hearing about the Unjournal. It sounds great. I specifically like the idea of commissioning outside experts to evaluate EA research. This seems necessary! I hope this becomes a standard practice for everyone who's involved in EA in some way.