“If you don’t know where you’re going, any road will take you there.” - George Harrison
Note: I am writing this in a personal capacity and none of the opinions made here represent those of my employer or any organizations I am associated with.
TL;DR
- I argue that we should have a comprehensive, centralized, high-level plan for AI Safety [here]
- Gaps in current strategy could render some current work useless
- There are potential limitations to “informal” or “implicit” coordination
- We have an opportunity to eliminate duplication of work and allocate resources more effectively
- An easily understood and highly visible plan is more likely to be utilized
- We don’t seem to have a centralized, high level plan [here]
- The plan can be a living document updated so that the best ideas win. I propose some options for how a living document could actually work and that critiques should come with a superior alternative or solution [here]
- I draft an early and likely flawed version of a plan - not because I think it’s the right one, but to make the idea concrete and invite iteration [here]
- (Here’s a thumbnail without context to entice you)
- I address what I anticipate to be the major objections [here]
Introduction
Although I've been a fan of EA for 8+ years, my full time involvement in AI Safety is relatively new. At EAG Bay Area last year I was keen to get up to speed on what the grand plan for AI safety was within the EA community. Clearly we all know it’s very important and many people are abandoning other high impact work because AI safety is viewed as even more important, so how are we going to make AI safe?
I was surprised to find that among the 30ish AI people I spoke to, there was no consensus as to what the comprehensive plan was and many people, although very smart and doing very impressive work, didn’t necessarily think of their work in terms of how it fit into a broader plan or strategy. In the months since, this trend has continued even as I've worked at the London Initiative for Safe AI (LISA) among very serious AI technical safety and AI governance people.
Lastly, after doing some research for this post reviewing strategy orgs listed on AISafety.com's Map of AI Existential Safety and their publications as well as going through LessWrong and EA Forum posts, it seems that although there are many plans addressing particular issues within AI safety, there are not complete front-to-back plans, and even if there are, they have not been centralized/the AI Safety community has not rallied behind them.
In this post, I make the case for why I think this should change. While individual research efforts are valuable, without a centralized and evolving plan, we risk optimizing locally while failing globally. I suggest that the AI safety community urgently needs a shared, living roadmap - and proposes a framework to get there.
Why we should have a comprehensive, centralized, high-level plan to make AI Safe
If you think that all the pieces of this subheading are self-evident, skip ahead!
Why Comprehensive?
In short: to make sure the plan works, at least in theory.
If a plan is not comprehensive, certainty that it will actually achieve its aims plummets. When you're building a railway, hoping that there are no breaks in the tracks is not a wise strategy. This appears to be one of the more significant gaps I've observed in AI safety work, and I believe it warrants more focused attention. A very easy way you can check if what we're working on is comprehensive is to ask yourself "If we completely finish the project/aim we're working on, will AI be safe?" I've found in talks with many people and in my research for this post that the answer is often no. Some examples:
- What if Redwood Research comes up with a protocol that enables complete control of even superintelligent misaligned systems? That's an enormous win, and a crucial piece of the puzzle! But, is AI safe? .....sadly not. Who is going to make sure that every AI developer implements these protocols?
- What if CHAI succeeds in coming up with a new way to train AI that completely solves the alignment problem? Is AI safe? .....sadly not. Who is going to make sure that OpenAI spends the hundreds of millions of dollars it will take to overhaul their infrastructure, get new data, and retrain models with massive compute requirements? Who will ensure that Google spends the 2-3 years of research for algorithmic development under the new paradigm instead of continuing with what they’ve already built? Who is going to make sure that every AI developer implements this type of training (i.e. pays the “alignment tax”)? How is that going to be enforced?
- What if the many people working in AI governance secure the historical agreement between US and China to "stop the race" or "develop AI in a responsible way." Is AI safe? .....sadly not. How would that be enforced? Would the leadership of these two countries really guarantee that no other state seeking an advantage develops superintelligence? What about small scale non-state actors developing AI?
Of course, there is the objection that "all of the pieces could be being worked on." People working in technical AI safety can just hand the baton to the AI governance people once they have a solution, right?" While technically possible, this is very unlikely. I think our current situation is evidence of this as the field as a whole seems to be missing the major piece of implementation and enforcement of solutions.
Although "The Deployment Problem" (the implementation and enforcement problem) has been written about by Holden Karnofsky all the way back in Dec 2022 in his cold take "Racing through a minefield", it seems that by not having a comprehensive plan, the community has neglected to elevate this area of work to be a major focus.
A likely objection to trying to create a comprehensive plan is that it will probably have serious flaws or include pieces that are unrealistic. If that’s the case, why even expend energy putting the plan up in the first place? I argue below that even a flawed comprehensive plan is superior to no plan at all. If we find the community’s best plan to make AI safe has a serious flaw, it serves as an emergency beacon for talent, research, and resources to be dedicated to resolving it (there literally isn’t a better known option). A visible, imperfect plan quickly reveals its weaknesses to the community, accelerating improvement and replacement with better options. The alternative - working without any unified plan - provides no such feedback mechanism for shoring up critical weaknesses.
To see the simplest version of what a comprehensive plan for AIS might look like [see below].
Why Centralized*?
In short: coordination. Both of effort and of resources.
There are several ways a centralized plan enhances coordination of effort. The primary way, I believe, is by identifying work that isn't connected to the plan. The work may be good, interesting, or even impactful, but if unrelated to the plan, may be misguided. Imagine a skilled craftsperson who wants to help build a community center. Hearing that construction is underway, they spend months meticulously crafting a beautiful wooden door—hand-carved panels, custom bronze hardware, perfect joinery. They arrive at the construction site proud of their contribution, only to discover the building is designed entirely without walls. It's an open-air pavilion. The door, however exquisite, cannot be used. I fear that without a plan, a substantial portion of the work done in AI Safety could fall into this category.
This is where explicit coordination may beat out even strong implicit/informal coordination. People in the AIS community may be largely aware of the work being done by one another through things like published research agendas, or regular communication between leaders of organizations. However, leaders could be like our skilled craftsman - perfectly coordinating and prioritizing on the different parts of the door, but not realizing that a door will not be helpful in the larger context. Local coordination does not seem sufficient as we may be coordinating or optimizing for things that are not relevant/useful in the greater context.
Even if we imagine that there are informally-coordinating leaders that have comprehensive plans in mind so that if people follow their voices the field will be pulling in the same direction… wouldn’t it still be a good idea to have that plan out in the open and centralized rather than only residing in the heads of leaders? Isn’t there a chance that ideas could be built upon even further by being put up for scrutiny? Wouldn’t this enable people with less access to leaders or less experience in the field to do work that’s actually helpful? For example, what about new entrants to AIS deciding what they should study/research to be most helpful in the future? It seems that even if there is implicit coordination happening in some places of the field, making the plan and coordination more accessible would be beneficial.
If strong implicit/informal coordination doesn’t exist, another significant benefit from a centralized plan is having a "source of truth" and eliminating duplication of work. This enables faster integration of new insights from across the field, eliminates confusion about the current best approach, reduces time spent searching across multiple sources and ensures people are working from the same information.
Lastly, a centralized plan greatly aids allocation of resources - both funding and labor. By having a plan with pieces people can point at [like the one towards the bottom of this post], organizations and individuals can see where effort is being duplicated, and where there are resource gaps.**
*I include "highly visible" in my conception of centralized. If the plan is "central" but not highly visible (e.g. on Open Philanthropy's website, but buried on a webpage 20 clicks away from the homepage), I wouldn't consider this centralized.
**See potential problems/negatives of a centralized plan below [here]
Why High-Level?
In short: so it's actually used and interacted with, and simple enough to quickly understand.
Although not comprehensive in the sense of addressing AI safety, a couple of organizations have developed highly detailed plans in their own sphere of the AI Safety community. Some of these may have received more traction had they been distilled into a high-level sentence that could be used as shorthand in EA conversations. The key is that the high-level plan remains clear, simple, and concise enough that it can be easily understood and communicated. Anyone in the community should look at what they’re doing and be able to see how it can fit into the plan. (Ideally, it would also be clear enough to easily explain to people outside of the AIS bubble or the EA bubble as the government and the general population will likely need to be involved at some point.
Note: This is the claim I'm least confident about. Especially in the EA community, lack of detail could actually be a deterrent to being taken seriously. However, I think we can have the best of both worlds by having a "double clickable" plan. When first introduced it should be extremely high-level and easily understood, but each facet can be "double clicked" on to open up more detail and sub-problems, all the way down "into the weeds." More on how this could work [here].
We Don't Seem to Have a Centralized Plan
To make this post more readable, I've put this section in the appendix. Please skip there if you do think we already have a centralized/comprehensive plan. The appendix goes through current orgs and posts that people may think meet this criteria, but I argue aren't quite there. This is important to get you on board with the need. If you already agree that it doesn't seem like we have one, read on!
The plan should be a living document updated so that the best ideas win
Many of the coordination benefits outlined in sections above are only possible if the plan is continually updated with the community's best ideas. This is especially true in a field developing as quickly as AI Safety. Any static document would quickly be rendered useless.
For some time, our "best plan" will likely have some serious flaws/problems. However, this is far better than having no plan, in my opinion, as it highlights what the flaws/problems/cruxes are that need solutions/workarounds/alternatives. This helps us quickly prioritize where to allocate resources. Perfect is the enemy of good here.
Ideally, critiques should come with a superior alternative or solution.
Giving this point its own heading as I think it is a crux for developing a very good centralized plan vs attempting to have one that quickly gets discarded.
I think one of our greatest skills as a community is offering criticism or pointing out flaws in arguments. However, tearing down THE PLAN without replacing it with a new one leaves us in the same predicament - that is, everyone “working on AI safety” but not really sure if we’re pulling in the same direction or if when our work is “complete” or that AI will actually be safe.
One useful framing might be to treat the community’s centralized plan as an open challenge—something to critique, test, and improve over time. "Do you know a better way?" "Do you have a better comprehensive plan?"
Of course, this is not to say that someone who is stellar at identifying significant issues, but not great at coming up with alternatives can’t help the cause here. They could add to the “list of issues” our best plan needs to overcome and dedicate resources towards. My emphasis is that as a community we do this in an attempt to help the best plan we have, not in an effort to tear it down because it’s not perfect or currently has major flaws. As mentioned elsewhere, much of the value of holding up a centralized plan could come from the flaws it has which act as a beacon for community focus/resources (to either address or come up with a better alternative).
How would this actually work?
To make this post easier to read, I've also made this a section in the appendix. It goes into the practicalities of how maintaining a living centralized document might work for those who are sold on the idea, but don't think that actually trying to implement it is realistic [see it here].
What a comprehensive, high-level plan could look like
Let's start with a caricature of what I perceive the implicit plan of the community to be:
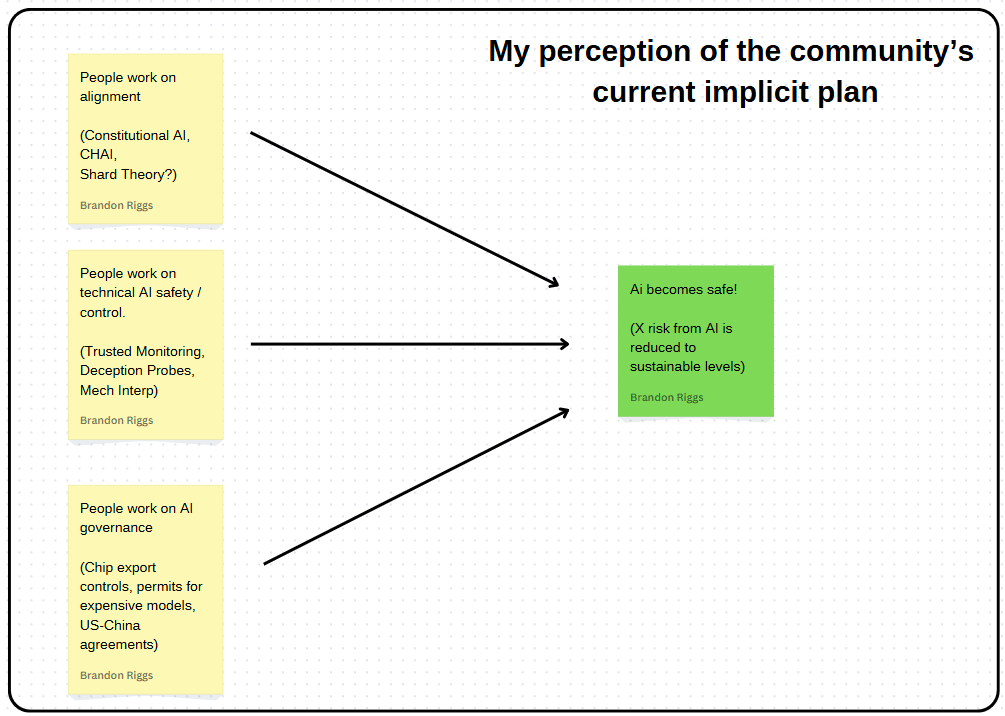
The good news is that lots of the work being done in these areas is likely important. I am immensely grateful to be in a world where so many people are dedicated to working on something so consequential and neglected.
This being said, I see some issues with the implicit plan the community seems to operating by. For example, if we discover training methods or protocols that allow us to align or control superintelligence, how would we ensure that everyone developing AI adopts it? As discussed earlier, without this “deployment problem” being addressed, even enormous breakthroughs (like solving control) fall short of making AI safe.
From the conversations I've had and from the articles/posts I see, it seems that AI governance/policy is more focused on things like chip export controls, US-China agreements, or AI risks associated with cyber or biological warfare/terrorism. This is not to say that any of these things are not valuable. But I do think it highlights a potential lack of coordination, for example, between what is being worked on in the technical AI safety world and what kind of things are being worked on in policy discussions.
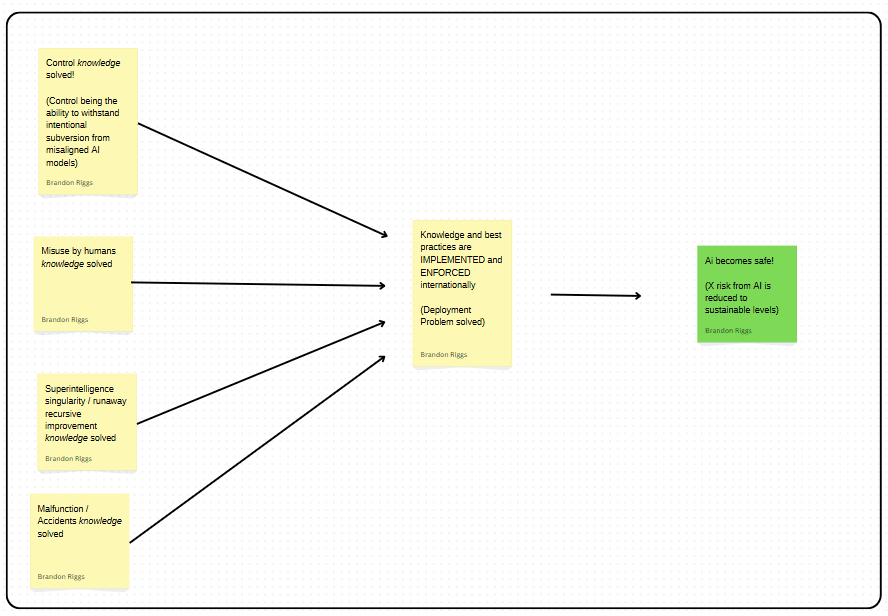
In the spirit of not only critiquing, but coming up with better alternatives, here is what the highest-level (most simplistic), explicit, comprehensive plan might look like:
PLEASE note: This post is about having a plan and not at all about having this plan. The plan itself has been hastily slapped together. It is the bathwater. Please keep the baby in mind (the usefulness of having a plan).
This "plan" has an enormous amount of magic wand waving. For example "Knowledge and best practices are implemented and enforced" is a massive undertaking, and putting it on a single sticky note can seem ridiculous. However, the main point I'm trying to make is that even with magic wand waving, the implicit plan the community is currently operating on doesn't lead to AI being safe. My aim is to at least have a plan that works in theory. "If we can do the five things in this plan, will AI be safe?" I think the answer is much closer to yes than the implicit plan I think we're currently operating on.
The comprehensive plan I'm advocating for could be analogous to a Safety Case for the AI safety field as a whole for those familiar with the term. Just as engineers must demonstrate how all components of a complex system work together to ensure safety, we need to ensure that all AI safety research efforts combine to actually make AI safe.
Crucially, this means every piece of AI safety work should be able to clearly articulate how it fits into the broader safety argument. Once we have a plan, can you point to where the work your doing fits into that plan? Without this comprehensive framework, we risk creating brilliant solutions that don't connect to an overall path to safety—like the skilled craftsperson creating a beautiful door for a building designed without walls.
In addition to identifying what work is relevant, consensus on what high-level plan we think is best can dramatically aid our allocation of resources. For example, if it is similar to what I propose above, we could identify that less than 5% of the AI Safety community is working on the deployment problem and enforcement mechanisms/policy, but it should be closer to 33% (numbers thrown out arbitrarily)).
It can also dramatically help coordination between different areas in AI safety. For example, if it looks like the only thing governments will accept is chip export agreements (and there are refusals to implement control/alignment measures) some of the labor going towards alignment/control could be reallocated towards engineering tools to help track chips (or lobbying governments to change their minds).
I have low confidence on this being the "right" level of detail. Perhaps one more "double click" on each element would be better. My intuition, however, is that this is about right. It can be summarized in a sentence: "We need to solve 4 major problems (misalignment, misuse, runaway superintelligence, accidents) and come up with a way to enforce their solutions globally in order to make TAI safe."
I'm confident that the 4 areas are not comprehensive and that there's probably a better way to categorize the problems that we need to solve and look forward to seeing the improvements made.
What about alternative plans?
"Why is 'Control' in the plan, but not alignment?"
This is a bit tricky. After a bit of thought, I do think that we should try to come to a consensus on the "best" plan. Although uncomfortable, this is an activity that EAs are extremely well equipped to handle as it nearly mirrors exercises in cause prioritization (plan prioritization).
Perhaps we could have alternative plans displayed like the below. But, in line with the EA principle of accepting tradeoffs, if we're being rational, more resources would likely be guided towards the primary plan.
(If you're wondering how we determine which plan is more likely to lead to success, see ["how would this actually work" in the appendix])
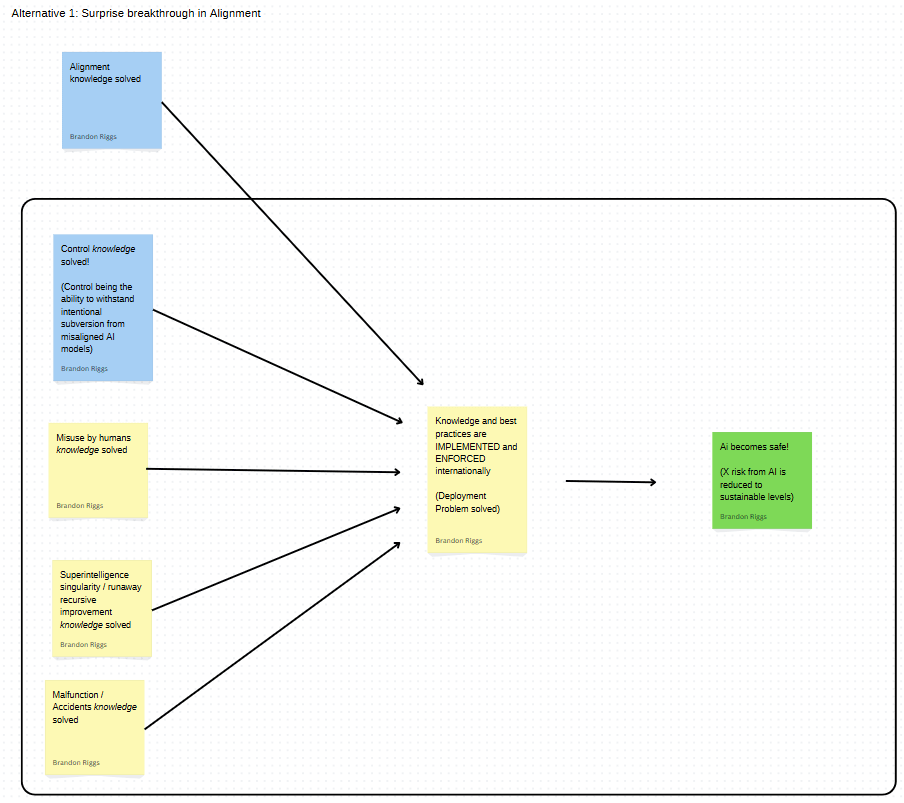
I think it's important to point out here that alternative plans should still be able to fit into the overall plan. Both alignment and control address misaligned AI.
With enough resources, we could also have plans running in parallel for major disagreements that aren't contradictory. For example, the Pause AI campaign could buy the overall safety plan more time as shown below.
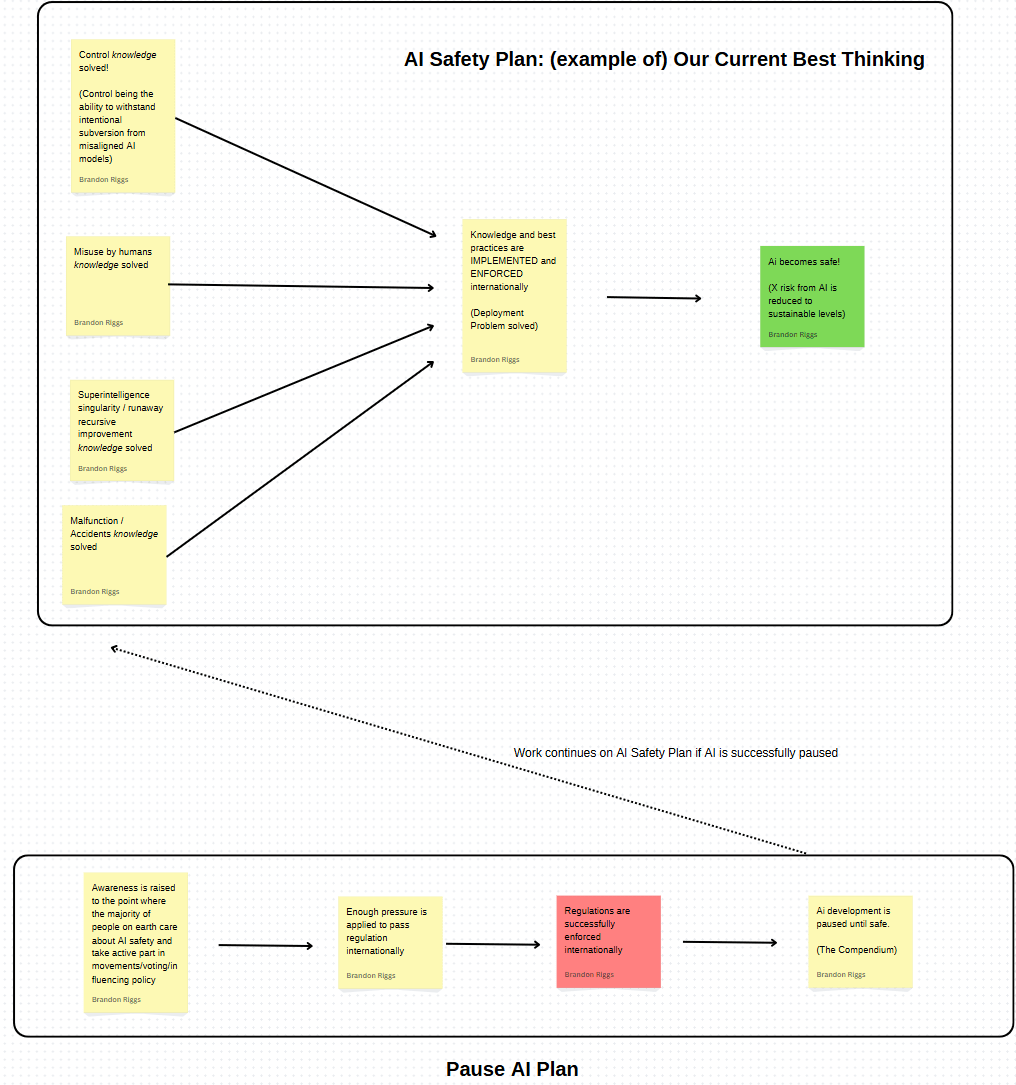
(red step highlights that the current Pause AI plan also seems to suffer from the deployment/implementation/enforcement problem (from my understanding). If the regulations are passed, how are they going to be enforced internationally?)
What the first "double click" could look like.
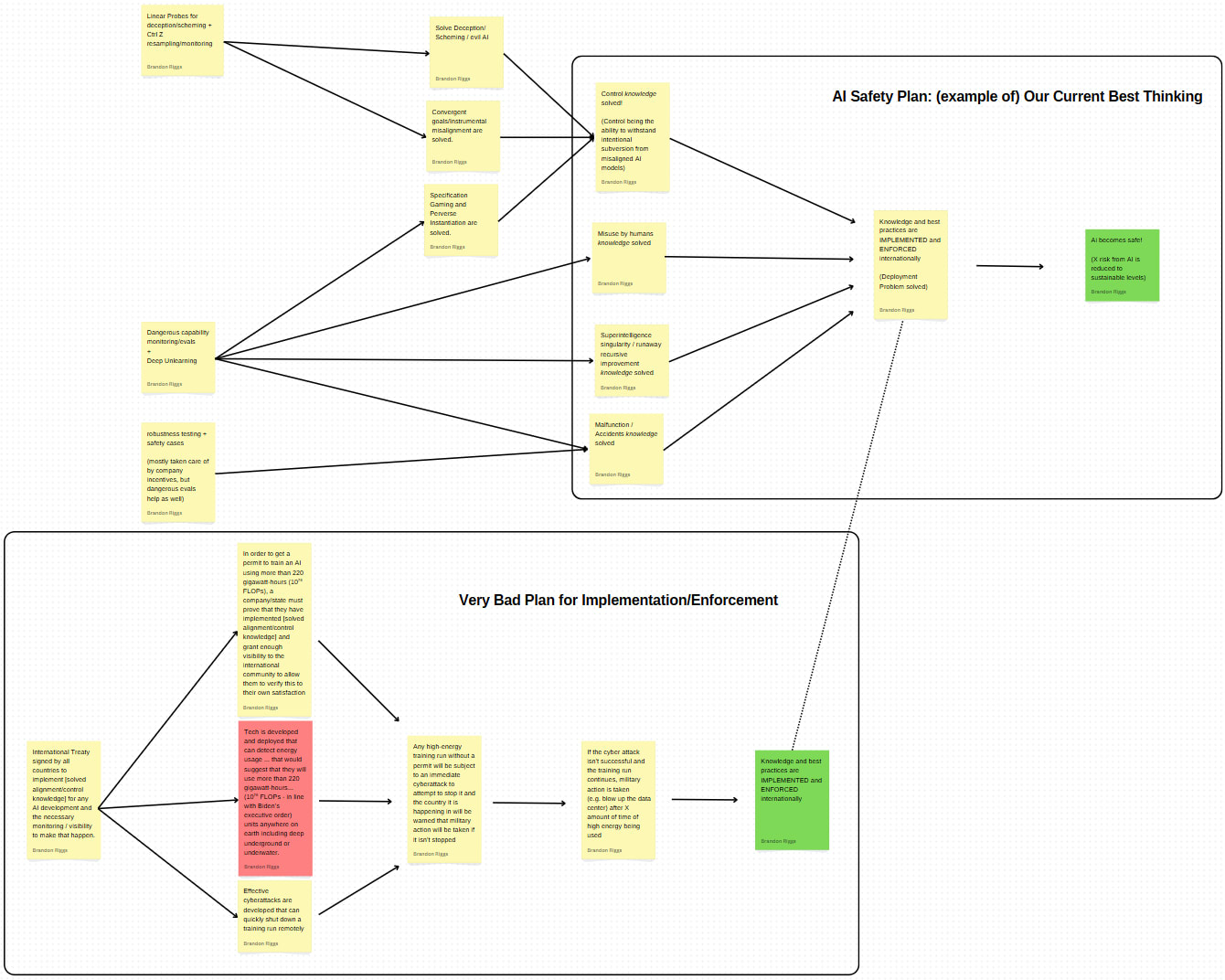
Some obvious problems immediately spring up when we get to this level of detail. Just focusing on the implementation/enforcement problem: Compute efficiency is rising. I predict that in the not too distant future, energy requirements will decrease to the point where it is difficult to pick out dangerous AI training from normal energy usage (Epoch AI reports that compute requirements are declining at a rate of 3x per year). It also seems that people training models could just do longer training runs at lower energy usage not to trigger anything suspicious. Lastly, it seems like even without increases in compute efficiency that distributed training could make detection very difficult.
Wait, so why even have this plan up there if there are so many problems? So glad you asked! This is my whole point. Firstly, because I couldn't think of a better one to replace it with. This is not a high bar, the point is the spirit of the setup. If I can identify many flaws with the plan, but fail to come up with a better plan, the flawed plan remains our current best bet (as sad as it might be). Secondly, if a plan as bad as this is put up centrally with the intent for the community to rally around it, it very quickly points out weaknesses of the plan. This can then very quickly get replaced/upgraded. Perhaps even more beneficially, if no one knows how the problems with the plan can be fixed, they act as a beacon for both talent and resources.
Potential Objections to or Problems with this Post
- A big assumption I make is that powerful AI will become widely creatable. Far beyond the leading labs. Hundreds if not thousands, if not tens of thousands of people working with AI models. I'm very open to the possibility that there's a reason why this is impossible and that the deployment problem isn't actually relevant (I would love to learn this!)
- The "no plan is better" objection. Guiding resources to a singular plan this early could cut out the unintuitive idea that actually has the highest chance of saving us. Casting a wider net could increase the chances that we "catch" safe AI.
- I have a big counter to this one. If there is consensus that this is the case, we should make this the plan to rally around! We can much more effectively cast a wide net if everyone knows that's what we're trying to do. Additionally, planning out how long to have no plan would be more effective than having no plan for the next 100 years (e.g. have no plan / wide net for the next two years, then see where we get the biggest hits and focusing resources there).
- "High-Level" abstractions could gloss over unsolved philosophical problems and disagreed upon definitions.
- People pivoting what they’re working on may be nice in theory but is difficult in practice. Practical constraints like funding, skills, training/upskilling time, etc., can all make labor reallocation costly.
- Having the “plan” out in the open may be a bad idea. It could provide “blueprints” for the bad guys to workaround. If they knew the plans for hardware monitoring in complete detail, it could enable them to much more quickly circumvent them (compared to if the community remained without a clear plan).
- Counter counter: we could still be clear that, for example, hardware controls are our best plans, but not publish the details. Only publish open positions in the field and skills that are needed (ideally blue team skills), etc..
- It could be too complicated to maintain a central plan or gain consensus. In my view, this seems like one of the most compelling objections, especially given the practical challenges of coordination and consensus-building. I attempt to address it in the appendix section [how would this actually work].
- Single point of failure. A centralized AI safety plan could create a dangerous single point of failure by concentrating the community's strategic direction into one potentially flawed framework. If the plan is fundamentally misguided - whether due to incorrect assumptions about AI development, overlooked failure modes, or systematic biases in its creation - then rallying the entire field around it could actually decrease our chances of success by preventing exploration of superior alternatives that don't fit the established paradigm.
- Note: I completely agree with this risk! The good news about plans is that they can take this into consideration. As a community striving for rationality, we can come to a consensus on where the biggest single point of failure risks in the plan are and how many resources should be dedicated to alternatives relative to the centralized plan. A larger trend you have probably noticed is that most objections can be absorbed into the plan as considerations to make it better.
Note: I reserve the right to come out with a much more organized and well thought out post in the future. Much of this exercise is to just get a general feeling out there that I hope I can form into a much better idea in the future.
Conclusion
As the quote at the beginning of this post points out, if you don’t care where you end up, it doesn’t matter what path you take. In the case of AI, I think it’s safe to say that we do care where we end up. Unfortunately, not every path laid out before us ends with safe AI. For this reason it seems like ensuring we’re collectively on a path that leads to safe AI is important.
It’s possible a centralized plan isn’t the right approach, or that someone already has a better version. If the latter is true, we should surface it. If there is no comprehensive plan, it seems that creating one is worth attempting. This draft isn’t a final answer; it’s an invitation to iterate. Even a flawed plan can help us reason more clearly and coordinate more effectively. The alternative - working in relative isolation and not knowing if we’re on the right path - feels riskier.
Perhaps this is all too much work to be decentralized and handled through the discourse on the forum and we need to have an organization declare themselves a central coordinator (or we need to found (yet another) EA org dedicated to this). Either way, I’d be eager to talk to other people or organizations who are interested in trying to get a cohesive high-level strategy that we can all rally behind. Please reach out to me! bdr27@cantab.ac.uk
Lastly… what would you replace this plan with?
Appendix:
We Don't Seem to have a centralized plan
As stated before, the main motivation for writing this doc is that, despite yapping about this topic quite a bit, nobody has yet directed me to something to be known as "THE PLAN." No centralized blueprint for the community to be working off of. To supplement this, I did some (light) research into existing orgs and existing articles to see if I had somehow just been very unlucky in who I spoke to. Below I attempt to summarize the main orgs/articles I looked at and why they might not be what I'm talking about in this post. Despite my best efforts to remain objective, this exercise has a high risk of confirmation bias creeping in. One of the below may be considered comprehensive. However, I think the main point - that none of these have become widely accepted or "centralized" - holds even if they are the perfect (or at least comprehensive) plan. If they are, I think the other parts of the post remain important, namely, elevating the visibility of the plan so that the whole AIS community knows about it and collectively improves it.
Note: This is not to criticize any of the other strategy orgs. Their work is good and important, and crucially, will very likely be needed as pieces to the larger overall puzzle. I think most of them should continue the valuable work they are doing! I am just pointing out that the community stands to benefit from putting many of these pieces together into a comprehensive picture.
I sourced which strategy orgs to research primarily through https://www.aisafety.com/map which I find very helpful for keeping track of the multitude of AIS orgs. Below are some of my very quick notes on my scanning of their websites. I anticipate many of these characterizations will be strongly opposed by the founders as they are based on cursory reviews and my descriptions should certainly not be taken at face value. I only list these out in order to hopefully accentuate the difference of what I'm proposing from what is already being done in the community:
- CSER (Center for the Study of Existential Risk). Has an AI Safety section, but it tackles individual issues rather than broader strategy (check it out here).
- CFI (Center for the Future of Intelligence). They have a Safety, Security and Risk section, but seems to be more about exploring the risks rather than recommending an overall strategy.
- Global Catastrophic Risk Institute (GCRI) does analysis on specific global catastrophic risks, of which AI is one.
- Median Group does research on global catastrophic risk and has some research on feasibility of deep reinforcement learning, but I didn't see a high level proposal of how to make AI safe
- Center for Human-compatible AI (CHAI). Trying to “reorient the general thrust of AI research towards provably beneficial systems.” On their research page they say “In short, any initial formal specification of human values is bound to be wrong in important ways. This means we need to somehow represent uncertainty in the objectives of AI systems. This way of formulating objectives stands in contrast to the standard model for AI, in which the AI system's objective is assumed to be known completely and correctly."* Love this approach, but it would still need to be combined with a solution for the deployment problem to be comprehensive.
- *I think this is a good example of a group working on a “replacement” for alignment. Many people are quick to criticize people working on alignment because they believe it is “obviously hopeless”, but then fail to point the people working on it towards greener pastures or more promising research/solution directions.
- Convergence Analysis actually have an excellent theory of change. They DO have high level strategy (here). I think this is the second closest thing I've seen to what I'm advocating for in this post (second to The Compendium). However, there are a few things that I think would need to be added to be comprehensive in my view:
- The penultimate step of the plan/strategy should be sufficient to get the result (and the result should be that AI is safe). Although their 4 outcomes (increased alignment, better AI governance, more effective project funding, and better coordination) are all excellent things for the AIS community, there are world where all of this could be true, but AI is still not safe.
- Already alluded to, but I propose that the ultimate goal should be making AI safe. Super nitpicking, but even their ultimate goal mitigation could be going from 1 in 10 chance of AI death to 1 in 11. Clearly this is not what they mean, but I think a very clear definition of what THE PLAN is aiming (Safe AI) for is needed. I talk more about this in the other appendix section [consensus on a theory of victory]. As it happens, Corin and Justin do a great job of arguing for this idea scoped to the domain of AI governance in their piece “AI governance needs a theory of victory.” I supposed one key difference I’m making with this post is to hold up the “best plan” and iterate on it rather than having three out there to debate. I think this “king of the hill” strategy is very helpful to ensure arguments are sound/sharp and which cruxes are most lacking evidence/need replacing. Perhaps a bit more emphasis on the ability "double click" on the theory of victory for details all the way down to the front lines as well.
- Let's put nit-picking aside and say that this is a good comprehensive plan. What I'd be arguing for/proposing is that this is widely adopted as a blueprint since the time Convergence started in 2017.
- They say they’re focused on governance
- They espouse coordination and building consensus, but nobody has heard of them or their plan (including just in governance).
- Their ultimate goal is “mitigation of existential risk from AI” → could be more specific. They name theory of victory, but don’t actually lay it out on their website?
- AI-Plans. It looks like it’s actually done a lot of the work about the logistics of upvoting plans, etc.! I think they could be a crucial piece to how we manage distributed honing of the plan. I talk more about this in the other appendix section [How would this actually work?]
- Global Partnership on Artificial Intelligence (GPAI). An OECD partnership for implementing human-centric, safe, secure and trustworthy AI. They seem to be more about promoting “risk management” and accountability, rather than an overall plan.
- The Compendium. “Explains AI extinction risks and how we can fix them” and they call their plan The Narrow Path. This is actually really quite good and the closest thing I've found for what I'm advocating for. Although the first step is advocating for pausing AI development, they support that with steps on what conditions would need to be met for that to happen, including what policies. The only nitpick I have is needing more detail on implementation and enforcement (may also propose an easier/more visual UI). For example, for the condition "No AIs developing AIs" (which is a great idea!), the proposed mechanism for enforcement is "Auditing and monitoring activities will be established to check that no R&D processes are aimed at being focused on the development of superintelligence." What are those activities? This being said, I would be very in favor of elevating The Narrow Path up as the community’s first version of THE PLAN. I think nitpicks like mine could quickly spur tons of great ideas for enforcement (much better than those I proposed in the main part of this post!).
Beyond looking at what I arbitrarily thought might be the most visible strategy orgs and their plans, I did some very brief searches of the EA Forum and LessWrong for comprehensive/centralized plans. There are far more posts than there are strategy orgs so my "research" here is even worse. I'm sure there are comprehensive plans that I may have missed. My main point would once again be that if it's decent, that we elevate it up to be highly visible and centralized. Here are some notes on what I did come across:
- The four areas of AIS: Describes them, but no grand plan.
- What AI Companies should do. Still not a global solution.
- The Checklist. Actually lays out the implementation concern as equal to solving alignment! However the plan is “norms.” It also nods towards the government utilizing cyber warfare, but doesn’t really have a solid plan of how to preclude deployment from someone in the world.
- Racing through a minefield. Talks about the deployment problem. Imagines a government taking action including and up to military action. I was surprised to see that this was written in Dec 2022 and that solving the deployment problem hasn't become a more central area of work since then. The article lists out many possible approaches that could hopefully address this, but doesn't recommend one best path. With limited talent working on the field and with the amount of issues to work through on any single path, I think narrowing the focus will be necessary.
- AI Safety Strategies Landscape. “ While it remains to be seen if these measures are sufficient to fully address the risks posed by AI, they represent essential considerations.” (May 2024) They talk about keeping powerful models behind APIs. Love the idea, but how will we ensure that everyone does that up front (not catching them after)?
- CAIP’s recent RAIA executive summary recommends permitting requirements for anyone training AI that costs more than 1 billion dollars. However, the enforcement is "civil and criminal penalties." Additionally, with advances being made in compute efficiency and algorithms, my intuition (which could definitely be wrong) is that risk of x-risk could come from models that cost less than 1 billion to train in the relatively near future.
Reasons not to listen to me
- It is very possible that there is a centralized plan that I somehow missed. The research done to try and find an extant plan has been light to medium. The confidence about there not being an existing plan mostly comes from the fact that no one I have spoken in AI Safety to has been aware of a comprehensive, high-level plan. This obviously doesn't mean there isn't one.
- (big one) My background is not in AI, nor AI safety. I come from the private sector with a focus on entrepreneurship and strategy. This could bias me in favor of strategy. Additionally, there may be something about AI safety that I don't yet understand that makes it an invalid candidate for high-level strategy.
- I am a complete EA forum noob (first post - plz be nice to me 👉👈) so there’s probably a bunch of caveats I’m forgetting to mention.
Note: this section is about me in particular. Weaknesses about the plans/recommendations themselves are listed toward the bottom of the main post [here]
How would a living document actually work?
There are many different ways this could be done. I propose one concrete way to do this and invite/welcome people to come up with better alternatives (as I'm sure there are many).
We have one place on the forum with the high level AI Safety plan that will be updated when a certain level of consensus is achieved on a better replacement.
I think one of our greatest skills as a community is offering criticism or pointing out flaws in arguments. However, tearing down what someone thinks is our best current plan without replacing it with a new one leaves us in the same predicament, or potentially even a worse one. This "king of the hill" strategy could keep disagreements productive by ensuring we are debating different solutions.
Here are some additional thoughts on how this could actually work in practice:
- As areas of disagreement about the best plan for AI Safety spring up (likely very quickly), we name the area of disagreement and create an area (on the forum) for it to be debated by those who are knowledgeable about the topic. Ideas can be upvoted until there is a clear “winner” based on the existing evidence. Ideally the whole sub-group would agree that this is our current best guess/idea. Note that I imagine many research paths will be identified in these debates and many people could be inspired to research something to “get” the missing piece of evidence for their argument that would undermine the crux of the existing best guess (or end up supporting it). As time goes on, every argument in the “grand plan” will be strengthened.
- I would not be surprised if we needed to have several levels down for each subgroup as well as there are many specialties. There would be lots of battling it out at lower levels that would then go “up the chain” of sub-groups
- I’m imagining a UI that looks similar to the plans in this post (above) where you can double click on each element to get to another level of detail. E.g. clicking on “Control Knowledge Solved” opens up all the components that need to happen in order for control knowledge to be solved. At this level, the community would be debating which problems need to be addressed to fully solve control and which techniques/protocols are most likely to succeed. This would then inform where we should be focusing research/resources.
- (Somewhat of an aside) A recommendation I would have in the battling of ideas that would dramatically speed up the rate of consensus progress is once a significant item or disagreement is “settled”, the reasoning is distilled and perhaps named. Similar to formal debates where you can quickly cut off an illogical argument by naming the fallacy (“this is clearly an ad hominem attack” or “that argument is the appeal to personal incredulity”), if we named or organized problems or mental traps that we see people commonly falling into, I think we can much more quickly help them out of the trap they are in.
- If there is broad consensus about a replacement idea that affects the highest level grand plan, that gets updated (and perhaps announced to the community -- likely after a couple weeks of the initial idea bloodbath and things stabilize a bit).
- (Another side note) We could also have an archive of write ups about each decision we make as a community so fresh eyes can quickly get up to speed (and potentially find issues / better alternatives that we didn’t already find as a community). By making the reasons explicit, we can much more quickly improve our reasoning (as Chris Argyris eloquently puts it in Teaching Smart People How To Learn).
In short it’s kind of like a centralized mechanism supporting AIS paradigm shifts as necessary that greatly enhances coordination in the community
As mentioned earlier, it looks like a solid alternative to using the forum upvoting system could be utilizing the website AI-Plans has put together. The only reason I suggested the forum in this section is because it seems a pretty "central" place for people working to eliminate x-risk from AI. Of course, if we could get everyone to reference/utilize AI-Plans, that seems like another good option.
A community-wide consensus on our theory of victory
I think it’s important for us to define exactly what we’re aiming for. What is all this work on AIS leading to? When are we done? Toby Ord suggests that a 1 in 1,000 chance of extinction is far too high in his book The Precipice. I think most people would agree given that we’ve designed the airline industry in a way where the risk of a fatal crash is 1 in ~14 million.
- This, itself, is a can of worms. Even with that low of chances, there are ~35 million flights per year, meaning there are at least 2 fatal crashes per year. We can’t have 2 failures with AI that lead to extinction if there are 35 million “opportunities.” What do we classify as an opportunity in AI? Only high stakes scenarios? When AI is granted access to the internet? Any time the open AI API is called? Every time a new model is trained? Every time a misaligned actor attempts to use AI?
- Thinking with a particular goal in mind (like this one) can also begin to shape how we approach the problem. For example, when writing about the above can of worms it seems like a simple way to reduce x risk is - instead of reducing the chance per opportunity (how I believe most people usually think about risk) - to reduce the number of opportunities.
Regardless, since the goal will be arbitrary, I think shooting for a 1 in 14 million chance per century could be a fine ultimate goal. However, that seems very far away so we may want milestones along the way. According to Toby, we're currently around 1 in 10. Milestones could be:
- 1 in 100
- 1 in 1,000 (still far too high)
- 1 in 10,000 per century
- 1 in 100,000 per century
- 1 in 294,118 per century (six sigma)
- 1 in 1,000,000
- 1 in 14,000,000
I don't have any strong takes here about what the final number should be. I'm sure that Toby, who has done a lot more thinking about this or statisticians could provide some good recommendations here. My main point is that we should have a general consensus about what "making AI safe" actually means. In the spirit of this document, instead of just saying that, I'll throw out the proposal of getting the risk of extinction from AI down to 1 in 14 million per century.
Shout out and a big thanks to all of those who gave feedback on this post! :)
Kabir Kumar: https://www.linkedin.com/in/kabir-kumar-324b02b8/