Comments
Thanks, Paal! I found this to be a great overview of methods to improve decision-making, and really liked the ideas for further research too.

Thanks, Paal! I found this to be a great overview of methods to improve decision-making, and really liked the ideas for further research too.
Thank you for this insightful review @Paal.
An assessment of methods to improve individual and institutional decision-making and some ideas for further research
Forecasting tournaments have shown that a set of methods for good judgement can be used by organisations to reliably improve the accuracy of individual and group forecasts on a range of questions in several domains. However, such methods are not widely used by individuals, teams or institutions in practical decision making.
In what follows, I review findings from forecasting tournaments and some other relevant studies. In light of this research, I identify a set of methods that can be used to improve the accuracy of individuals, teams, or organisations. I then note some limitations of our knowledge of methods for good judgement and identify two obstacles to the wide adoption of these methods to practical decision-making. The two obstacles are
I look at projects and initiatives to overcome the obstacles, and note two directions for research on forecasting and decision-making that seem particularly promising to me. They are
After I have introduced these areas of research, I describe how I think that new knowledge on these topics can lead to improvements in the decision-making of individuals and groups.
This line of reasoning is inherent in a lot of research that is going on right now, but I still think that research on these topics is neglected. I hope that this text can help to clarify some important research questions and to make it easier for others to orient themselves on forecasting and decision-making.[1] I have added detailed footnotes with references to further literature on most ideas I touch on below.
In the future I intend to use the framework developed here to make a series of precise claims about the costs and effects of specific epistemic methods. Most of the claims below are not rigorous enough to be true or false, although some of them might be. Please let me know if any of these claims are incorrect or misleading, or if there is some research that I have missed.
In a range of domains, such as law, finance, philanthropy, and geopolitical forecasting, the judgments of experts vary a lot, i.e. they are noisy, even in similar and identical cases.[2]In a study on geopolitical forecasting by the renowned decision psychologist Philip Tetlock, seasoned political experts had trouble outperforming “dart-tossing chimpanzees”—random guesses—when it came to predicting global events. Non-experts, eg. “attentive readers of the New York Times” who were curious and open-minded, outperformed the experts, who tended to be overconfident.[3]
In a series of experimental forecasting tournaments, decision researchers have uncovered the methods that the best forecasters use, and also methods that institutions can employ to improve their foresight.
In 2011, the Intelligence Advanced Research Projects Activity (IARPA) – the US intelligence community’s equivalent to DARPA – launched a massive competition to identify cutting-edge methods to forecast geopolitical events. Participants were to give probabilistic answers to questions such as "Will the euro fall below $1.20 in the next year?" or "Will the president of Tunisia flee to exile in the next six months?" The competition was called the Aggregative Contingent Estimation (ACE) tournament.[4]
Four years, 500 questions, and over a million forecasts later, the Good Judgment Project (GJP) – led by Philip Tetlock and Barbara Mellers at the University of Pennsylvania – emerged as the undisputed victor in the tournament. According to GJP, their best forecasts were 35-72% more accurate than the four other academic and industry teams participating in the competition, and even outperformed a prediction market whose traders consisted of US intelligence analysts with access to classified information by approximately 34,3%.[5]
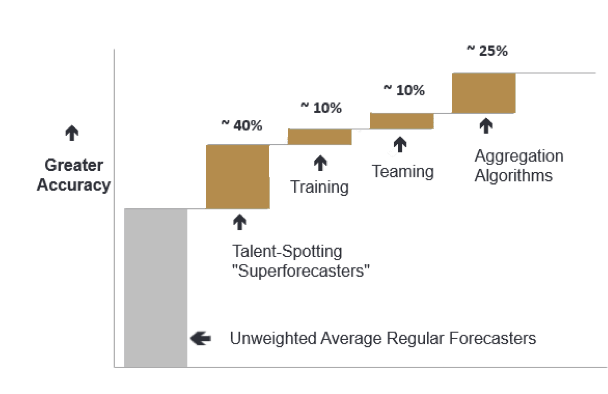
Tetlock and his colleagues recruited 3365 volunteers to provide probabilistic answers to sharply defined questions like the ones used in the tournament. They built a web-based platform to represent forecasting questions, and on which forecasters could submit their probabilistic forecasts and discuss with each other in a comments section. By measuring the difference between the estimates and the actual occurrence of events, researchers were able to calculate a score showing how well-calibrated the expectations of each forecaster were with reality. Through analysing these data, GJP found that the key to more accurate geopolitical forecasting was to select the top-performing individuals, train them to think probabilistically and avoid common biases, and then put them in teams. The GJP team would then analyse all individual forecasts as well as team forecasts using an aggregation algorithm to calculate the "wisdom of the crowd." The forecasters did not worry about aggregation algorithms, they focused solely on doing research for the forecasting questions. In summary, the main determinants of predictive success are:
The illustration below shows the approximate relative importance of these effects. [6]
The greatest effects on the accuracy of teams came from selecting good forecasters to be part of the team. GJP selected the top 2% and labelled individuals in this group the superforecasters. Superforecasters scored 30-40% better than the group of all forecasters.[7] GJP did a thorough job of determining the traits and methods that characterise these superforecasters. Significant traits include numeracy, active open-mindedness, grit, and intrinsic motivation to improve accuracy so as to be among the best. Superforecasters were also knowledgeable about international affairs and used the same methods to answer forecasting questions. The top performers of the tournament were able to approach seemingly intractable questions by breaking them down into smaller parts, researching the past frequency of similar events, adjusting probabilities based on the unique aspects of the situation, and continuously updating their estimates as new information became available.[8] A striking trait of superforecasters is that they are intuitive Bayesians who consciously represent their own credence (beliefs) on a question in terms of explicit numerical probabilities (or odds) that they update in light of new information.[9]
GJP delivered training modules which included an introduction to some of the methods mentioned above. The materials were on probabilistic reasoning and took about 1-hour to read. They included, but were not limited to, (i) calibration training, (ii) base rates (i.e. reference classes, also known as outside view), (iii) bayesian updating (inside view), and (iv) debiasing. Teaming somewhat improved accuracy in the ACE tournament. Within teams, forecasters would share information and divide research workloads. The danger of groupthink was mitigated by advising forecasters to be actively open-minded and seek out different perspectives.[10]
The best predictions were “extremized” aggregated judgments from small teams of superforecasters, the best of which beat the aggregate of all predictions from GJP forecasters by a sizable margin (10%). This “elitist extremizing algorithm” gave more weight to the forecasts of forecasters with a good track record (elitism), and who updated frequently. It also pushed each forecast closer in the direction of more certainty based on the cognitive diversity of the pool of forecasters (extremizing).[11]
The aggregate of normal GJP forecasters was quite good compared to the extremized aggregate of judgements from superforecasters in teams.[12] This is an interesting result because crowds are sometimes more easily available than groups of demonstrably proven forecasting experts. The process of spotting forecasting talent can be more costly than gathering a large group of people.
The GJP studied the beneficial effects of the above methods extensively. However, they did not investigate the costs of applying those methods in a similarly rigorous manner. They didn’t measure how much time each forecaster spent doing research on forecasting questions either. This may turn out to be significant, because it may turn out that superforecasters use significantly more time doing research on forecasting questions than normal forecasters. If true, this explanation would be less helpful to organisations aiming to improve the accuracy of their analysts, because grit and hard work are more costly than the methods mentioned above, and would not be as surprising.
One of the key metrics that correlate with accuracy is how often forecasters update their forecasts, in addition to grit and motivation. Some of the best superforecasters even made computer programs to help them do research in a more efficient manner.[13] These facts suggest that superforecasters probably spent a fair deal of time doing research.
In 2017 the Norwegian Research Defence Establishment (FFI) ran a forecasting tournament intended to investigate if GJP’s findings in the ACE tournament would replicate on questions with a longer time horizon, and in a Nordic context. A total of 465,673 predictions were collected from 1,375 participants on 240 questions over three years. The questions were on geopolitical issues of interest to FFI, and broadly similar to those of the ACE tournament. [14]
An important difference from GJP is that FFI's tournament was open to anyone who wanted to participate. Participants registered on the tournament's website or through forms on graded networks in the Armed Forces. Everyone had to state gender, age, level of education, connection to the defence establishment, security policy work experience, as well as which topics, actors and regions they had expertise in, and whether they had been used as experts in the media. In addition, everyone was asked to assess their interest in and belief in their own ability to predict defence and security policy. Unlike in the ACE tournament, the participants in the FFI tournament were given a week to ponder each forecasting question and did not have the opportunity to update their predictions after this deadline. Also, the superforecasters in FFI did not receive training and were not grouped with other equally good superforecasters. [15]
In FFI's tournament, the purpose has been to measure accuracy on questions with a longer and more relevant time perspective for defence and security policy analyses in the real world. The average time perspective in the FFI tournament was 521 days, i.e. four times as long as the questions in GJP. [16]
In a preliminary analysis of results from this tournament, Alexander Beadle found several strikingly similar results to those of the GJP in the ACE tournament. In the FFI tournament, there is a group of participants who are significantly better than the rest of the participants and thus can be called superforecasters. The standardised Brier scores of FFI superforecasters (–0.36) were almost perfectly similar to that of the initial forecasts of superforecasters in GJP (–0.37). [17] Moreover, even though regular forecasters in the FFI tournament were worse at prediction than GJP forecasters overall (probably due to not updating, training or grouping), the relative accuracy of FFI's superforecasters compared to regular forecasters (-0.06), and to defence researchers with access to classified information (–0.1) was strikingly similar.[18] Moreover, the individual differences measured between groups of the very best forecasters (top 2%), the second best group, and the rest of the pool of forecasters, were replicated by very close margins in the FFI study.[19] This is surprising, because the GJP superforecasters had access to training and grouping, whereas the FFI superforecasters did not. How could the FFI superforecasters be as good as the GJP superforecasters without training and grouping? I won’t speculate about this here, but note that it would be interesting to look into this.
In contrast to GJP, FFI tracked time spent answering questions. Beadle acknowledges that time was a difficult variable to measure, which was probably the reason why GJP did not do so. Beadle calculated how long participants had the survey open in the browser (and removed those who had the tab open for an unrealistically long time), and asked the participants how long they themselves thought they spent in an optional questionnaire.[20] The results from these two measurements were pretty similar, which strengthens the reliability of the results from these measures. All forecasters spent 1,32 minutes on average answering each question, whereas the second-best group spent 1,65 minutes, and the superforecasters spent 1,83 minutes. These numbers indicate that accuracy increased with time spent answering questions. However, it is not clear to me if this number accounts for the time spent doing research on each question. In particular, it seems to be very low if it is supposed to include time spent doing research. Especially if research for superforecasters includes breaking down questions and identifying base rates. Beadle mentions that the vast majority did not spend much time thinking at all, whereas the most accurate forecasters tended to use the methods for good judgement that GJP uncovered in their research. If this is true, we should expect that time spent increases with accuracy within the three groups as well.
Forecasting tournaments have revealed the effectiveness of several methods for improving forecasting accuracy.[21] They have not revealed the costs of applying those methods or their relevance to decision-making.
In this section I want to underscore the importance of costs to practical applications of methods for good judgement and consider the relevance of such methods to decision-making. I hope that this discussion can help identify important unanswered research questions, and clarify how to make cost-effectiveness assessments of adopting and applying epistemic methods to improve individual and institutional decision-making.
The most effective methods identified in forecasting tournaments; talent selection and aggregation of the wisdom of crowds, seem to be quite costly to implement and are probably only available to organisations. Other methods are, however, available to teams and individuals. In what follows I say something about organisations, individuals and smaller teams in turn, with a focus on costs. I lean heavily on other sources, but what follows is not a synthesis or review. The sources in the footnotes have more information than is expressed here, so if anyone has a serious interest in costs, I advise reading these texts themselves.
The FFI tournament cost less than half of a single researcher's annual work, where question generation accounted for most of the cost.[22] Despite this relatively low cost, the US intelligence agency has not adopted the epistemic methods identified in the ACE tournament to improve their decision-making.[23]
Some large organisations, including Microsoft, Google and Goldman Sachs have tried running prediction markets. Prediction markets are similar to forecasting tournaments, with the exception that participants express confidence through the price they are willing to bet on the outcome of the question.[24] Although many prediction markets improve the accuracy of the organisation using them, most organisations that tried using prediction markets stopped. In an analysis of the literature on prediction markets in the corporate setting, Nuno Sempere, Misha Yagudin and Eli Lifland give a nuanced answer to the question “should organizations use prediction markets?”. In brief, their recommendation is that most organisations ought not to adopt company-internal prediction markets. Key reasons are that:
Forecasting tournaments have also identified methods that individuals and teams can use to improve the accuracy of their judgements, and perhaps improve decision-making. Even though results from the FFI tournament did not corroborate the GJP finding that training and teaming have significant causal effects on accuracy, both tournaments show that a specific set of methods for good judgement is associated with improved accuracy. In particular, good forecasters tend (among other things) to;
Applying these methods does not require the epistemic infrastructure that is needed for prediction markets or forecasting tournaments. However, there are costs associated with these methods as well. The superforecasters in the ACE tournament were gritty and intrinsically motivated to learn and improve their brier scores. If their determination and time spent explain most of their success, then learnings from GJP might not be very relevant to most individuals with a fixed cognitive style, and limited time to spend doing research for their decisions. I have not found any systematic studies into the costs in terms of time and effort of applying the method above in an effective way to forecasting questions. Learning the above methods carries a one-time cost. Even though this cost is negligible if the methods are applied several times, it might not be seen as worth it if it is unclear to individuals if and when it is worthwhile to apply the methods.
Teams working to answer the same or related questions can divide workloads and share information. They can also aggregate their forecasts, and leverage the wisdom of the group which is likely to further improve accuracy. In other decision-making tasks, teaming with structured methods for group deliberation has shown impressive results. One study found that 9% of individuals compared to 75% of small groups managed to solve a set of logical puzzles.[26] A structured collaborative reasoning methodology called the Delphi method has been extensively studied, and some studies seem to demonstrate large effects.[27] This method consists in several rounds where participants express their quantitative beliefs anonymously, as well as their reasons for those beliefs. Other participants read the other’s perspectives, and update their own beliefs in light of those perspectives. This process repeats until there are diminishing returns to more rounds, typically after a few rounds. Results from studies have been mixed, but proponents assert that poor results in some studies are due to poor implementation. There are also important benefits to using structured collaboration techniques like the Delphi method, such as the following:
However, for groups too, applying epistemic methods can be cumbersome, and labour-intensive. A method for groups inspired by findings from forecasting tournaments can look like this:
Some of these steps are hard to do without experience or specialised tools, especially when time is a constraining factor. An important reason why is that traditional methods of communication are not ideal for communicating probabilities. This form of reasoning involves elicitation and aggregation procedures that can be complicated and time-consuming to conduct without mistakes. Moreover, when the number of collaborators grows, it becomes time-consuming to read or hear the takes of everyone else and to update on their reasoning if their beliefs and the grounds for those beliefs are represented in texts or communicated verbally.
The GJP opinion pooling platform, as well as related web-based prediction platforms, including popular prediction markets, alleviate some of these hurdles.[28] However, they lead to some hurdles of their own. Team collaboration on prediction platforms mostly consists of written exchanges in a comments field, and aggregation of team credence. It is not always easy to assess what explains the credence of other team members in this format, and this makes it hard for team members to know if they should update on the credence of others. In addition, team collaboration in this format can be time-consuming because it can be unclear what comment is relevant to what aspect of a question, and which comments to read. When forecasters don’t know if the discrepancy between their beliefs and that of others is due to others' bias, misunderstanding, lack of knowledge, or a deficit in their own thinking, and getting clear on this is a costly time-investment, collaboration may not be the best use of time.
It is not clear whether the methods found to improve accuracy in the ACE tournament are most relevant to the decision-making of individuals, groups or organisations. However, it seems that a common thread is that the time investment in terms of learning, applying and sustaining epistemic methods is a core reason why these methods have not been adopted more widely. Moreover, it seems to me that there is a dearth of research concerning the costs of applying epistemic methods to improve decision-making. For these reasons, I think more research into the costs of applying specific epistemic methods for individuals, groups and organisations can be useful. It is also a necessary step towards doing robust cost-effectiveness assessments of methods for improving decision-making.
Crucially, research into costs is likely to spawn ideas to reduce them. Several actors have for some time been trying to develop techniques as well as technologies to support the various operations involved in applying epistemic methods. Research into costs would be a great boon to projects like these because such projects could then use solid methods developed by independent researchers in their assessments, and also apply the same measurement methods as those found to work well in research. Tools have the potential to significantly improve the rate of learning epistemic methods, reduce the chance of making mistakes when applying them, and significantly reduce the time it takes to apply them.[29] This might be as important as improving the methods in terms of accuracy. There might be a hidden bar in terms of feasibility that the methods must pass in order to become accessible to a large group of people who are not as gritty and numerate as the best forecasters. If research and development can help us clear that bar, individuals and institutions might have a much easier time eliciting forecasts from large groups. This leads me to think that research and development into epistemic techniques and technological innovations that can make it easier to apply epistemic methods can be a worthwhile use of time.
Epistemic methods are effective only to the extent to which they can be expected to improve the quality of the decisions of some person or institution, or generate some other benefit. Accurate beliefs concerning concrete geopolitical questions of the sort studied in the ACE tournament are clearly crucial to some decisions, but the relevance of epistemic methods to other important decisions is not clear to all decision-makers. In fact, many of the most important decisions rely on considerations at a high level of abstraction, seemingly far removed from the rigorous questions found in forecasting tournaments or prediction platforms. Tetlock calls this the rigour/relevance tradeoff.
I want to present two ideas to bridge the rigour/relevance gap. One way is to extend our knowledge of the effects of epistemic methods by testing their efficacy on questions that have not been studied already. Another is to explore new methods. I’ll briefly discuss the former before describing the latter in more detail.
The typical forecasting questions for which epistemic methods have been shown to improve accuracy in the ACE tournament are concrete, and empirically verifiable in 100 days. In an earlier study, Tetlock found that the judgments of experts on similar questions more than 5 years ahead in time approximated random guessing, but found that the best forecasters could do better than chance at 3-5 year predictions.[30]
Open Philanthropy, a philanthropic fund with a particular focus on long-term issues, has researched and made forecasts on a number of questions relating to grantmaking. In line with FFI results, they find that accuracy does not vary much with longer time horizons.[31] Although there is some research on this topic, the importance of long-term predictions warrants additional studies and theoretical treatments.
National security risk is clearly a topic in which some of the world’s most important decisions are made. Another important topic is global catastrophic risks. Examples of worrisome catastrophic risks include the risk of a deadly global pandemic, nuclear war and risks from emerging technologies. Decision-relevant questions in this and some other important topics can be hard to forecast, because they resolve in the far future, or because it is difficult to make the questions rigorous. Although prediction markets have been tried out with great success in many domains, including law and medicine, there are many domains for which it is unclear whether epistemic methods work well. It would be worthwhile to research the feasibility of epistemic methods to improve accuracy in more domains, so as to more clearly define areas of applicability to decision-makers.[32]
One ongoing research program that seeks to address the problem of questions that don’t resolve in the near future explores the idea of reciprocal scoring. In brief, the idea is to score forecasts using external benchmarks, including expert opinion, prediction markets, and relevant statistical models to score the predictions of individuals before the question resolves.[33]
A promising complementary approach aims to analyse nebulous questions in terms of rigorous questions. Tetlock calls this approach “Bayesian Question Clustering.” The idea is to take the question you really want to answer and look for more precise questions that are relevant to the truth of the question you care about. There will likely be several ways to spell out the details of the nebulous question in terms of rigorous questions. To account for this, Tetlock proposes to develop clusters of questions that give early, forecastable indications of which scenario is likely to emerge. Instead of evaluating the likelihood of a long-term scenario as a whole, question clusters allow analysts to break down potential futures into a series of clear and foreseeable signposts that are observable in the short run. Questions should be chosen not only for their individual diagnostic value but also for their diversity as a set, so that each cluster provides the largest amount of information about which imagined future is emerging—or which elements of which envisioned futures are emerging.[34]
The idea is enticing, but there are many unresolved issues about how best to model the relevance of the truth of some question to the truth of another. The challenge is to show how rigorous forecasting questions bear on nebulous questions of interest to some decision-makers. What is the logical relationship between one question and another?[35] How can knowledge concerning rigorous questions help us better understand and predict other questions? What is the best way to visualise and work with models of this kind?[36]
There is currently a flurry of research and development efforts going into developing tools and methods to clarify this issue in particular.[37] In 2016, IARPA launched CREATE, a competition specifically aimed at developing "tools and methods designed to improve analytic reasoning through the use of crowdsourcing and structured analytic techniques." In other words, whereas ACE focused on forecasting, CREATE focused on reasoning and analysis. Additionally, the CREATE program aimed to make tools that assist people in effectively communicating their reasoning and conclusions.
Several groups of eminent researchers applied to be a part of the CREATE program, including Tetlock and the GJP. However, I want to highlight the work of a cross-disciplinary research group involving computer scientists at Monash, and psychologists at UCL and Birkbeck. Bayesian ARgumentation via Delphi (BARD) is a decision support tool that facilitates Bayesian reasoning through software for representing Bayesian networks and group deliberation through the Delphi method. As the team puts it, BARD is “an end-to-end online platform, with associated online training, for groups without prior Bayesian network expertise to understand and analyse a problem, build a model of its underlying probabilistic causal structure, validate and reason with the causal model, and (optionally) use it to produce a written analytic report.”
In a pre-registered study of the BARD system, participants were asked to solve three probabilistic reasoning problems spread over 5 weeks. The problems were made to test both quantitative accuracy and susceptibility to qualitative fallacies. 256 participants were randomly assigned to form 25 teams of 6–9 using BARD and 58 individuals using Google Suite and (if desired) the best pen-and-paper techniques. For each problem, BARD outperformed the control with large to very large effects (Glass' Δ 1.4–2.2).[38] Some of the other systems that were developed for the CREATE program also found large effects with similar methods.[39] However, note that the study used reasoning challenges that resemble logical puzzles, like those in the Moshman and Gail study, and were not typical forecasting tasks. Also, note that the sample size is small. Although Bayesian networks have been used to model small systems and some specific logical problems, there has not been any systematic study of their use as reasoning support systems for individuals or groups in decision-making tasks like those of the ACE tournament. However, there are many active research projects that currently investigate this specific issue. Researchers associated with the GJP, including Tetlock himself, have also gone on to explore an approach to Bayesian networks that they call conditional forecast trees.[40] Even though there is active research on Bayesian networks for forecasting and decision-making, it would be great to see more research and innovation in this direction.
In the preceding, I have outlined some research into forecasting and decision-making. On the basis of an interpretation of this research, I have suggested that more knowledge of the costs and effects of epistemic methods can make it easier for decision-makers to assess whether it is a cost-effective use of resources to apply them. I have also indicated that research and development into cost-reducing techniques and technologies for epistemic methods, as well as new methods and innovations for modelling the logical relationships between forecasting questions and nebulous but important questions can make forecasting more relevant to decision-making. Here are the two main conclusions in summary form:
Improvements within these fields of research may seem additive, and incremental. I now want to give some reasons to believe that they might drive multiplicative effects.
Consider a situation in which you consider buying a new car. You don’t know how far it can go, and you don’t know if it can tackle the mountain roads where your cabin is. Also, you don’t know the price of the car itself, or the price of refuelling. Most people would not buy the car. However, if there were rigorous studies showing the car capacities on the parameters above, perhaps it would feel more responsible to do so. I think that decision-makers are in a similar position with regard to epistemic methods. Knowledge about domains of application and costs could provide the information needed for decision-makers to feel confident in adopting epistemic methods. It could turn out that these pieces of the puzzle are everything that stands between some decision-makers and the application of some methods that would improve their decisions.
In many areas, there is a price point under which most customers are willing to buy a type of product, and above which most customers are not willing to pay. This is also true for many types of practices, where the cost is time and energy. Before smart devices could be used to monitor sleep and exercise, most people didn’t record data on this. Keeping a sleep or a training diary, and taking one’s pulse does not take very much time. But these activities were still too tedious for most people to feel that it was worthwhile to do them. However, now that devices record those things automatically or with the activation of a button or two, many people do it, even though they don’t clearly see what the benefits are. Most people probably have similar price points when it comes to their unconscious cost-benefit assessments of the feasibility of adopting new practices, techniques, or purchases. We don’t know where that point is, but cost-effectiveness analyses might help us find it for some segments, contexts and methods. If it’s not very far off, seemingly incremental improvements to the relevance or cost-effectiveness of some particular methods might get that method above the price point at which most people are willing to apply the method. Getting above that price point might lead to widespread adoption of a particular method, instead of incremental growth.
For most methods, wide adoption would lead to incrementally better decisions overall.[41] However, some methods are self-reinforcing and culture-changing. Rigorous probabilistic forecasting methods and formal models of relevance have a special attribute in this connection. These can be used to keep scores, track improvements, and distribute recognition. Although each of these methods in themselves perhaps only improves accuracy by small margins, they might serve to boost a culture in which accuracy is measured and valued. A culture of that sort constitutes an environment in which other methods that improve accuracy are likely to be adopted and used, and new methods are likely to emerge, because their effectiveness and relevance can be demonstrated clearly. Another important effect of wide adoption of these methods has to do with the data they collect. Wide adoption can give rise to large datasets, and there is some reason to believe that larger datasets of judgments from diverse populations will improve the efficacy of other methods, namely talent spotting and aggregation. In the biggest forecasting tournament studies, the GJP and FFI studies, there was an N of approximately 1500. The best 2% were about 30-40% better than the average. If we take the best 0,2% of a larger sample, 15 000 say, I would be surprised if this group of superforecasters were no better than the 2% of the smaller FFI and GJP samples. Similar principles are likely to apply to aggregation algorithms.
For these reasons, I think that improvements to methods for probabilistic belief elicitation and scorekeeping on rigorous forecasting questions, as well as quantitative models of relevance have multiplicative effects both on accuracy and the rate of epistemic development if widely adopted. If this conclusion is correct, more research on forecasting and decision-making, especially in the areas of relevance and costs, might have a high expected impact.
See Jess Whittlestone (2022) Epistemics and institutional decision-making - 80,000 Hours for a thorough and continuously updated introduction and assessment of this field. See also Clayton et al. (2021) Refining improving institutional decision-making as a cause area: results from a scoping survey, Lizka Vaintrob (2021) Disentangling "Improving Institutional Decision-Making" - EA Forum, Stauffer et al. (2021) Policymaking for the Long-term Future, and Ian David Moss’ (2021) Improving Institutional Decision-Making: Which Institutions? (A Framework) and (2022) A Landscape Analysis of Institutional Improvement Opportunities. Here is also a brief cause area guide to institutional decision making that I have written (2020) Cause Area Guide: Institutional Decision-making.
See Kahneman, D., Sibony, O., & Sunstein, C. R. (2021). Noise: a flaw in human judgment. First edition. New York, Little, Brown Spark.
For a brief introduction, see this New Yorker article Everybody’s an Expert | The New Yorker. For a more comprehensive overview, see Philip Tetlock's (2009) Expert Political Judgment: How Good is It? How can We Know? Princeton University Press.
This characterization is inspired from Tetlocks own description. It is, however, slightly misleading. On average, the ACE questions would resolve in 100 days from the time they were given. See Tetlock et al. (2014) "Forecasting Tournaments: Tools for Increasing Transparency and Improving the Quality of Debate", Current Directions in Psychological Science, 23:4, ss. 290–295, s. 291.
Tetlock acknowledges that the other teams had a significantly worse management team, and that his team could most likely recruit forecasters of a higher calibre than the other teams due to his academic prestige. See Edge Master Class 2015: A Short Course in Superforecasting, Class II, part II.
In 2013, the accuracy of a prediction market run by the US intelligence community was compared to the best methods of the GJP on 139 forecasting questions. See this paper by IARPA Program Manager Dr. Seth Goldstein et al. for the comparison between GJP and US intelligence analysts (Goldstein, et al. 2015). The results were mostly due to the better aggregation methods used by the GJP on their pool of forecasts on these questions, see Gavin and Misha’s (2022) Comparing top forecasters and domain experts - EA Forum and a response from GJP (2022) Comparing Superforecasting and the Intelligence Community Prediction Market - EA Forum. See also results from the FFI tournament that did a similar comparison, and found similar results.
See Philip Tetlock and Dan Gardner's . Superforecasting: The art and science of prediction (2015)Crown Publishers/Random House for a full introduction to the tournament and results from the research conducted by the GJP. See the official GJP webpage for links to relevant research articles: The Science Of Superforecasting – Good Judgment. See also this post by Gwern for relevant discussion (2019).
See Christopher W. Karvetski (2021) Superforecasters: A Decade of Stochastic Dominance and the section on the FFI tournament below.
This summary closely tracks the emphasis of Philip Tetlock in the recent article A Better Crystal Ball in Foreign Affairs. See Mellers et al. 2015, The Psychology of Intelligence Analysis: Drivers of Prediction Accuracy in World Politics, Journal of Experimental Psychology: Applied, Vol. 21, No. 1, 1–14, for details. Tetlock summarises the method in ten steps Ten Commandments for Aspiring Superforecasters - Good Judgment.
Within analytic philosophy, bayesian reasoning has been explored, defended and given a robust theoretical foundation. See Pettigrew, Richard (2016). Accuracy and the Laws of Credence. New York, NY.: Oxford University Press UK for a recent statement of the position, and Frank Ramsey’s 1926 paper for the classic statement. Perhaps the best reasons to adopt the view are so-called “Dutch book arguments”.
Holder Karnofsky has a good and accessible intro to Bayesian reasoning (2021) Bayesian Mindset which also has an audio version. Also, see Luke Muehlhouser's (2017) Reasoning Transparency, and Open Phil's A conversation with Philip Tetlock, March 8, 2016 Participants Summary Calibration software Bayesian question clusters for more on bayesian reasoning.
See Chang (2016) The impact of training and practice on judgmental accuracy in geopolitical forecasting tournaments, Judgment and Decision Making, Vol. 11, No. 5, September 2016, pp. 509–526.
See Satopaa et al. 2013, “Combining multiple probability predictions using a simple logit model”, International Journal of Forecasting, Volume 30, Issue 2, and Jonathan Baron, et al. (2014) Two Reasons to Make Aggregated Probability Forecasts More Extreme. Decision Analysis 11(2):133-145.
In a 2016 interview with Alexander Berger, Tetlock; “... estimates that algorithmic aggregating of the predictions of a large group (e.g. 300) of typical, good-judgment forecasters can produce results nearly as accurate as a small group (e.g. 10) of superforecasters.” (p3). See Noise: a flaw in human judgment, and/or James Surowiecki’s The Wisdom of Crowds for more examples and references to studies on the accuracy of crowds in a variety of domains.
In a 2015 Edge Masterclass seminar, Salar Kamangar: asked Tetlock and Mellors the question: “Was there a correlation between time spent and forecasting ability when you looked at that self-reported information?” Mellers responded: “Yes, in the sense of how often you update your forecast, that’s huge.” Kamangar: “How about aggregate time?”, to which Tetlock responded “We don’t have a good measure of that… It’s fair to say that some people work smarter than others do in this domain as in other domains, but on average there’s got to be some correlation.”. For the comment on computer programs, see Edge Master Class 2015: A Short Course in Superforecasting, Class II part I.
See Beadle, A. (2022) FFIs prediksjonsturnering – datagrunnlag og foreløpige resultater. The report is in Norwegian, but Alexander Beadle is currently writing articles in english to disseminate results.
Beadle, 2022, p179.
Beadle, 2022, p19. FFI publishes annual threat assessments, and the development of the Norwegian Armed Forces is managed according to long-term plans which normally apply for four years at a time. At the same time, the largest structural choices and material investments require a time perspective of 15–25 years.
Note that GJP forecasters improved their scores after updating. However, the FFI forecasters could not update on their predictions.
Beadle, 2022, p169.
Beadle, 2022, p175.
Beadle, 2022, p134. Some details are from personal correspondence.
However, there are many other methods for good decision making. Here are two lists of interventions aimed at institutions: Clayton et al. (2021) Refining improving institutional decision-making as a cause area: results from a scoping survey - EA Forum, Burga (2022) List of Interventions for Improving Institutional Decision-Making - EA Forum.
Beadle, 2022, p190.
See Samotin et al. (2022) Obstacles to Harnessing Analytic Innovations in Foreign Policy Analysis: A Case Study of Crowdsourcing in the US Intelligence Community for a study and discussion of why that is.
For a brief statement on the promise of prediction matkets, see Arrow et al. (2008) The Promise of Prediction Markets | Science. For an in-depth explanation and consideration of key objections and barriers, see Scott Alexander (2022) Prediction Market FAQ.
See Sempere et al. (2021) Prediction Markets in The Corporate Setting - EA Forum, and also Lifland (2021) Bottlenecks to more impactful crowd forecasting - EA Forum. See also Michael Tooley’s (2022) Why I generally don't recommend internal prediction markets or forecasting tournaments to organisations. See also this shortform question, and the answers to it in the comments.
In this study, a group of 143 college undergraduates was given a logical hypothesis testing problem. 32 students worked on the problem individually, the rest were divided into 20 groups of 5 or 6 individuals. Only 9% of the individuals solved the task, compared to 75% of the groups. According to the authors: “The superior performance of the groups was due to collaborative reasoning rather than to imitation or peer pressure. Groups typically co-constructed a structure of arguments qualitatively more sophisticated than that generated by most individuals.” Moshman, D., & Geil, M. (1998). Collaborative reasoning: Evidence for collective rationality. Thinking & Reasoning, 4(3), 231–248.
According to Wikipedia there has been more than a thousand studies on the effects on accuracy of the Delphi Method, but I can’t find any meta-studies or ways to verify the claim. However, I haven’t done much research on this. See https://en.wikipedia.org/wiki/Delphi_method#Accuracy for the claim.
The GJP platform is Good Judgment® Open. Some other prediction platforms are Metaculus, Kalshi, Manifold Markets and PredictIt.
See the tools at Quantified Intuitions and Clearer Thinking for some high-quality tools for learning epistemic methods. The Quantified Uncertainty Research Institute has several more advanced tools. See also this overview of tools.
Tetlock & Gardner, 2015, 5.
See Luke Muehlhouser’s analysis of this issue (2019) How Feasible Is Long-range Forecasting? - Open Philanthropy, and Javier Prieto’s (2022) How accurate are our predictions? - Open Philanthropy. Benjamin Tereick from the Global Priorities Institute has an active research project on this issue as well.
At the end of the book Superforecasting, Tetlock and Gardner single this problem out as the central challenge for future forecasting research. If it can be overcome, it might be able to make progress in heated policy debates that now mostly serve to polarise people with contrary political opinions.
See Karger et al. (2022) Improving Judgments of Existential Risk: Better Forecasts, Questions, Explanations, Policies, See also Tetlock og Gardner, 2015, 263.
This is the central question for a research program in philosophy that goes under the label philosophical naturalism. Naturalists use analytical methods to show how nebulous concepts or propositions relate to the natural properties described by the sciences, and ultimately to experience. One of the most influential logicians and naturalists of the past century, Willard Van Orman Quine, likened science to a web of beliefs. The abstract propositions of logic and mathematics lie at the core, and beliefs we come to hold due to direct observation are at the periphery. Some of the methods of logical analysis used by Quine and contemporary naturalists to clarify propositions, and to break them down into rigorous component parts are relevant to forecasting and decision making. See Quine, W. V. & Ullian, J. S. (1970). The Web of Belief. New York: Random House. See also his 1957 text “The Scope and Language of Science”, British Journal for the Philosophy of Science, 8: 1–17; reprinted in Quine, 1966. For a great introduction to Quine’s philosophy, see Hylton, Peter, 2007, Quine, London and New York: Routledge. Alternatively, see Hyltons shorter SEP entry Willard Van Orman Quine (Stanford Encyclopedia of Philosophy). For a more thorough introduction to philosophical analysis, see Scott Soames (2003) Philosophical Analysis in the Twentieth Century, Volume 1 & 2, Princeton University Press.
There is a slack-channel dedicated to this, let me know if you want to join.
Some ongoing projects are (Manheim 2021) Modeling Transformative AI Risk (MTAIR) - LessWrong and (Gruetzemacher et al. 2021) Forecasting AI progress: A research agenda - ScienceDirect. Metaculus is also working on a related project, and so are researchers associated with GJP through the Forecasting Research Institute. See also the section on BOTEC tools by Fin Moorhouse (2023) Some more projects I’d like to see - EA Forum, this post by Max Clarke (2022) Project: A web platform for crowdsourcing impact estimates of interventions. - EA Forum and Harrison Durland’s (2021) "Epistemic maps" for AI Debates? (or for other issues) - EA Forum, (2022) Research + Reality Graphing to Support AI Policy (and more): Summary of a Frozen Project - EA Forum, and discussion in a shortform thread on LessWrong. Other relevant posts are Huda (2023) Existential Risk Modelling with Continuous-Time Markov Chains - EA Forum, and Aird et al. (2020) Causal diagrams of the paths to existential catastrophe - EA Forum.
The description is taken from the abstract of Nyberg, et al. (2022), BARD: A Structured Technique for Group Elicitation of Bayesian Networks to Support Analytic Reasoning. Risk Analysis, 42: p1156. https://doi.org/10.1111/risa.13759, preprint available here: https://arxiv.org/abs/2003.01207. For the effects, see Korb et al. (2020) Individuals vs. BARD: Experimental Evaluation of an Online System for Structured, Collaborative Bayesian Reasoning, Frontiers in Psychology, 11, 2020. See this link for an explanation of how to interpret the Glass effect size. The BARD team included computer scientists at Monash (led by Kevin Korb, Ann Nicholson, Erik Nyberg, and Ingrid Zukerman) and psychologists at UCL and Birkbeck (led by David Lagnado and Ulrike Hahn) who are experts in encoding people's knowledge of the world in maps of probabilistic causal influence: causal Bayesian Networks (BNs). A good map can provide the logical skeleton of a good intelligence report, including the probabilities of competing hypotheses, the impact of supporting evidence, relevant lines of argument, and key uncertainties. Two well-known difficulties here are eliciting sufficient analyst knowledge and amalgamating diverse opinions. The team also included psychologists from Strathclyde (led by Fergus Bolger, Gene Rowe, and George Wright) who are experts in the Delphi method, in which a facilitator methodically leads an anonymous group discussion toward a reasoned consensus.
See J. Stromer-Galley et al’s. “TRACE program”, outlined in their paper "User-Centered Design and Experimentation to Develop Effective Software for Evidence-Based Reasoning in the Intelligence Community: The TRACE Project," in Computing in Science & Engineering, vol. 20, no. 6, pp. 35-42, 1 Nov.-Dec. 2018, doi: 10.1109/MCSE.2018.2873859, (pdf here). See also SWARM, T. van Gelder, R. De Rozario and R. O. Sinnott, "SWARM: Cultivating Evidence-Based Reasoning," in Computing in Science & Engineering, vol. 20, no. 6, pp. 22-34, 1 Nov.-Dec. 2018, doi: 10.1109/MCSE.2018.2873860 (online pdf). COGENT Anticipatory Intelligence Analysis with Cogent: Current Status and Future Directions.
There is not a lot of publicly available information on this, but see this entry from GJP on question clusters Question Clustering - Good Judgment, this somewhat longer foreign affairs article A Better Crystal Ball, this transcript from a discussion Fireside Chat with Philip Tetlock | Effective Altruism, and the description and papers at https://forecastingresearch.org/research. It seems that the GJP project idea for CREATE was not selected for funding by IARPA. However, Tetlock and collaborators received funding from Open Philanthropy to “make conversations smarter, faster”, which seems to be a project about this.
In an Edge Masterclass on forecasting, Tetlock says that the types of questions that are debated in the IARPA forecasting tournament can and perhaps should be modelled in the form of a Bayesian network or some other representation of reasoning (see transcript at 38:00).
See the BARD team’s (2020) Widening Access to Bayesian Problem Solving, and Ulrike Hahn’s paper (2022) Collectives and Epistemic Rationality for a recent treatment of the special requirements of group rationality and collective decision-making.


Thanks for highlighting Beadle (2022), I will add it to our review!
I wonder how FFI Superforecasters were selected? It's important to first select forecasters who are doing good and then evaluate their performance on new questions to avoid the issue of "training and testing on the same data."
Good question! There were many differences between the approaches by FFI and the GJP. One of them is that no superforecasters were selected and grouped in the FFI tournament.
Here is google's translation of a relevant passage: "In FFI's tournament, the super forecasters consist of the 60 best participants overall. FFI's tournament was not conducted one year at a time, but over three consecutive years, where many of the questions were not decided during the current year and the participants were not divided into experimental groups. It is therefore not appropriate to identify new groups of super forecasters along the way" (2022, 168). You can translate the entirety of 5.4 here for further clarification on how Beadle defines superforecasters in the FFI tournament.
So it's fair to say that FFI-supers were selected and evaluated on the same data? This seems concerning. Specifically, on which questions the top-60 were selected, and on which questions the below scores were calculated? Did these sets of questions overlap?
Yes, the 60 FFI supers were selected and evaluated on the same 150 questions (Beadle, 2022, 169-170). Beadle also identified the top 100 forecasters based on the first 25 questions, and evaluated their performance on the basis of the remaining 125 questions to see if their accuracy was stable over time, or due to luck. Similarly to the GJP studies, he found that they were consistent over time (Beadle, 2022, 128-131).
I should note that I have not studied the report very thoroughly, so I may be mistaken about this. I'll have a closer look when I have the time and correct the answer above if it is wrong!