This is a special post for quick takes by KR. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Comment Permalink
Thought experiment for longtermism: if you were alive in 1920 trying to have the largest possible impact today, would the ideas you came up with without the benefit of hindsight still have an effect today?
I find this a useful intuition pump in general. If someone says "X will happen in 50 years" I think of myself looking at 2020 from 1970, asking how many of that sort of prediction I made then would have been accurate now. The world in 50 years is going to be at least as hard to imagine (hopefully more, given exponential growth) to us as the world of today would have from 1970. What did we know? What did we completely miss? What kinds of systematic mistakes might we be making?
I may have misunderstood your question, so there's a chance that this is a tangential answer.
I think one mistake humans make is overconfidence in specific long-term predictions. Specific would mean like predicting when a particular technology will arrive, when we will hit 3 degrees of warming, when we will hit 11 billion population, etc.
I think the capacity of even smart humans to reasonably (e.g. >50% accuracy) predict when a specific event would occur is somewhat low; I would estimate around 20-40 years from when they are living.
You ask: "if you were alive in 1920 trying to have the largest possible impact today" what would you do? I would acknowledge that I cannot (with reasonable accuracy) predict the thing that will "the largest possible impact in 2020" (which is a very specific thing to predict) and go with broad-based interventions (which is a more sure-shot answer) like improving international relations, promoting moral values, promoting education, promoting democracy, promoting economic growth, etc (these are sub-optimal answers; but they're probably the best I could do).
I'd be interested to see a list of what kinds of systematic mistakes previous attempts at long-term forecasting made.
Also, I think that many longtermists (eg me) think it's much more plausible to successfully influence the long run future now than in the 1920s, because of the hinge of history argument.
My understanding of the hinge of history argument is that the current time has more leverage than either the past or future. Even if that's true, it doesn't necessarily mean that it's any more obvious what needs to be done to influence the future.
If I believed that e.g. AI is obviously the most important lever right now, and think I know which direction to push that lever, I would ask myself "using the same reasoning, which levers would I be trying to push where in 1920". As far as I can tell this is pretty agnostic about how easy it is to push these levers around, just which you would want to be pushing.
An argument in favor of slow takeoff scenarios being generally safer is that we will get to see and experiment with the precursor AIs before they become capable of causing x-risks. Even if the behavior of this precursor AI is predictive of the superhuman AI’s, our ability to use it depends on the reaction to the potential dangers of this precursor AI. A society confident that there is no danger from increasing the capabilities of the machine that has been successfully running its electrical grid gains much less of an advantage from a slow takeoff (as opposed to the classic hard takeoff) than one with an awareness of its potential dangers.
Personally, I would expect a shift in attitudes towards AI as it becomes obviously more capable than humans in many domains. However, whether this shift involves being more careful or instead abdicating decisions to the AI entirely seems unclear to me. The way I play chess with a much stronger opponent is very different from how I play chess with a weaker or equally matched one. With the stronger opponent I am far more likely to expect obvious-looking blunders to actually be a set-up, for instance, and spend more time trying to figure out what advantage they might gain from it. On the other hand, I never bother to check my calculator’s math by hand, because the odds that it’s wrong is far lower than the chance that I will mess up somewhere in my arithmetic. If someone came up with an AI-calculator that gave occasional subtly wrong answers, I certainly wouldn’t notice.
Taking advantage of the benefits of a slow takeoff also requires the ability to have institutions capable of noticing and preventing problems. In a fast takeoff scenario, it is much easier for a single, relatively small project to unilaterally take off. This is, essentially, a gamble on that particular team’s capabilities. In a slow takeoff, it will be rapidly obvious that some project(s) seem to be trending in that direction, which makes it more likely that if the project seems unsafe there will be time to impose external control on it. How much of an advantage this is depends on how much you trust whichever institutions will be needed to impose those controls. Humanity’s track record in this respect seems to me to be mixed. Some historical precedents for cooperation (or lack thereof) in controlling dangerous technologies and their side-effects are the Asilomar Conference, nuclear proliferation treaties, and various pollution agreements. Asilomar, which seems to me the most successful of these, involved a relatively small scientific field voluntarily adhering to some limits on potentially dangerous research until more information could be gathered. Nuclear proliferation treaties reduce the cost of a zero-sum arms race, but it isn’t clear to me if they significantly reduced the risk of nuclear war. Pollution regulations have had very mixed results, with some major successes (eg acid rain) but on the whole failing to avert massive global change. Somewhat closer to home, the response to Covid-19 hasn’t been particularly encouraging. It is unclear to me which, if any, of these present a fair comparison, but our track record in cooperating seems decidedly mixed.
I found this interesting, and I think it would be worth expanding into a full post if you felt like it!
I don't think you'd need more content: just a few more paragraph breaks, maybe a brief summary, and maybe a few questions to guide responses. If you have questions you'd want readers to tackle, consider including them as comments after the post.
EA-style discussion about AI seems to dismiss out of hand the possibility that AI might be sentient. I can’t find an example, but the possibility seems generally scoffed at in the same tone people dismiss Skynet and killer robot scenarios. Bostrom’s simulation hypothesis, however, is broadly accepted as at the very least an interestingly plausible argument.
These two stances seem entirely incompatible - if silicon can create a whole world inside of which are sentient minds, why can’t it just create the minds with no need for the framing device? It is plausible that sentience does not emerge unless you very precisely mimic natural (or “natural”) evolutionary pressures, but this seems unlikely. It’s likewise possible that something about the process by which we expect to create AI doesn’t allow for sentience, but in that case I think the burden of proof is on the people making the argument to identify this feature and argue for their reasons.
The strongest argument I can think off of the top of my head is that, if we expect a chance of future-AI created by something resembling modern machine learning methods to have a chance at sentience, we should likewise expect, say, worm-equivalent AIs to have it to. Is c. elegans sentient? Is OpenWorm? If you answered yes to the first and no to the second, what is OpenWorm missing that c. elegans has?
I think there are many examples of EAs thinking about the possibility that AI might be sentient by default. Some examples I can think of off the top of my head:
- Brian Tomasik has written about why we might get sentient computer programs by default, eg https://reducing-suffering.org/why-your-laptop-may-be-marginally-sentient/
- I've referred to this occasionally in the past in various posts of mine, eg http://shlegeris.com/2016/11/26/research
- Eliezer Yudkowsky is worried about the related concern that AI systems might simulate humans in morally relevant ways https://arbital.com/p/mindcrime/?l=18h
- Paul Christiano has written about whether unaligned AI is morally valuable https://ai-alignment.com/sympathizing-with-ai-e11a4bf5ef6e
I don't think people are disputing that it would be theoretically possible for AIs to be conscious, I think that they're making the claim that AI systems we find won't be.
Thanks for the links, I googled briefly before I wrote this to check my memory and couldn't find anything. I think what formed my impression was that even in very detailed conversations/writing on AI, as far as I could tell by default there was no mention or implicit acknowledgement of the possibility. On reflection I'm not sure if I would expect it to be even if people did think it was likely, though.
Many years ago, Eliezer Yudkowsky shared a short story I wrote (related to AI sentience) with his Facebook followers. The story isn't great -- I bring it up here only as an example of people being interested in these questions.
Curated and popular this week
·
At the last EAG Bay Area, I gave a workshop on navigating a difficult job market, which I repeated days ago at EAG London. A few people have asked for my notes and slides, so I’ve decided to share them here.
This is the slide deck I used.
Below is a low-effort loose transcript, minus the interactive bits (you can see these on the slides in the form of reflection and discussion prompts with a timer). In my opinion, some interactive elements were rushed because I stubbornly wanted to pack too much into the session. If you’re going to re-use them, I recommend you allow for more time than I did if you can (and if you can’t, I empathise with the struggle of making difficult trade-offs due to time constraints).
One of the benefits of written communication over spoken communication is that you can be very precise and comprehensive. I’m sorry that those benefits are wasted on this post. Ideally, I’d have turned my speaker notes from the session into a more nuanced written post that would include a hundred extra points that I wanted to make and caveats that I wanted to add. Unfortunately, I’m a busy person, and I’ve come to accept that such a post will never exist. So I’m sharing this instead as a MVP that I believe can still be valuable –certainly more valuable than nothing!
Introduction
80,000 Hours’ whole thing is asking: Have you considered using your career to have an impact?
As an advisor, I now speak with lots of people who have indeed considered it and very much want it – they don't need persuading. What they need is help navigating a tough job market.
I want to use this session to spread some messages I keep repeating in these calls and create common knowledge about the job landscape.
But first, a couple of caveats:
1. Oh my, I wonder if volunteering to run this session was a terrible idea. Giving advice to one person is difficult; giving advice to many people simultaneously is impossible. You all have different skill sets, are at different points in
·
Thank you to Arepo and Eli Lifland for looking over this article for errors.
I am sorry that this article is so long. Every time I thought I was done with it I ran into more issues with the model, and I wanted to be as thorough as I could. I’m not going to blame anyone for skimming parts of this article.
Note that the majority of this article was written before Eli’s updated model was released (the site was updated june 8th). His new model improves on some of my objections, but the majority still stand.
Introduction:
AI 2027 is an article written by the “AI futures team”. The primary piece is a short story penned by Scott Alexander, depicting a month by month scenario of a near-future where AI becomes superintelligent in 2027,proceeding to automate the entire economy in only a year or two and then either kills us all or does not kill us all, depending on government policies.
What makes AI 2027 different from other similar short stories is that it is presented as a forecast based on rigorous modelling and data analysis from forecasting experts. It is accompanied by five appendices of “detailed research supporting these predictions” and a codebase for simulations. They state that “hundreds” of people reviewed the text, including AI expert Yoshua Bengio, although some of these reviewers only saw bits of it.
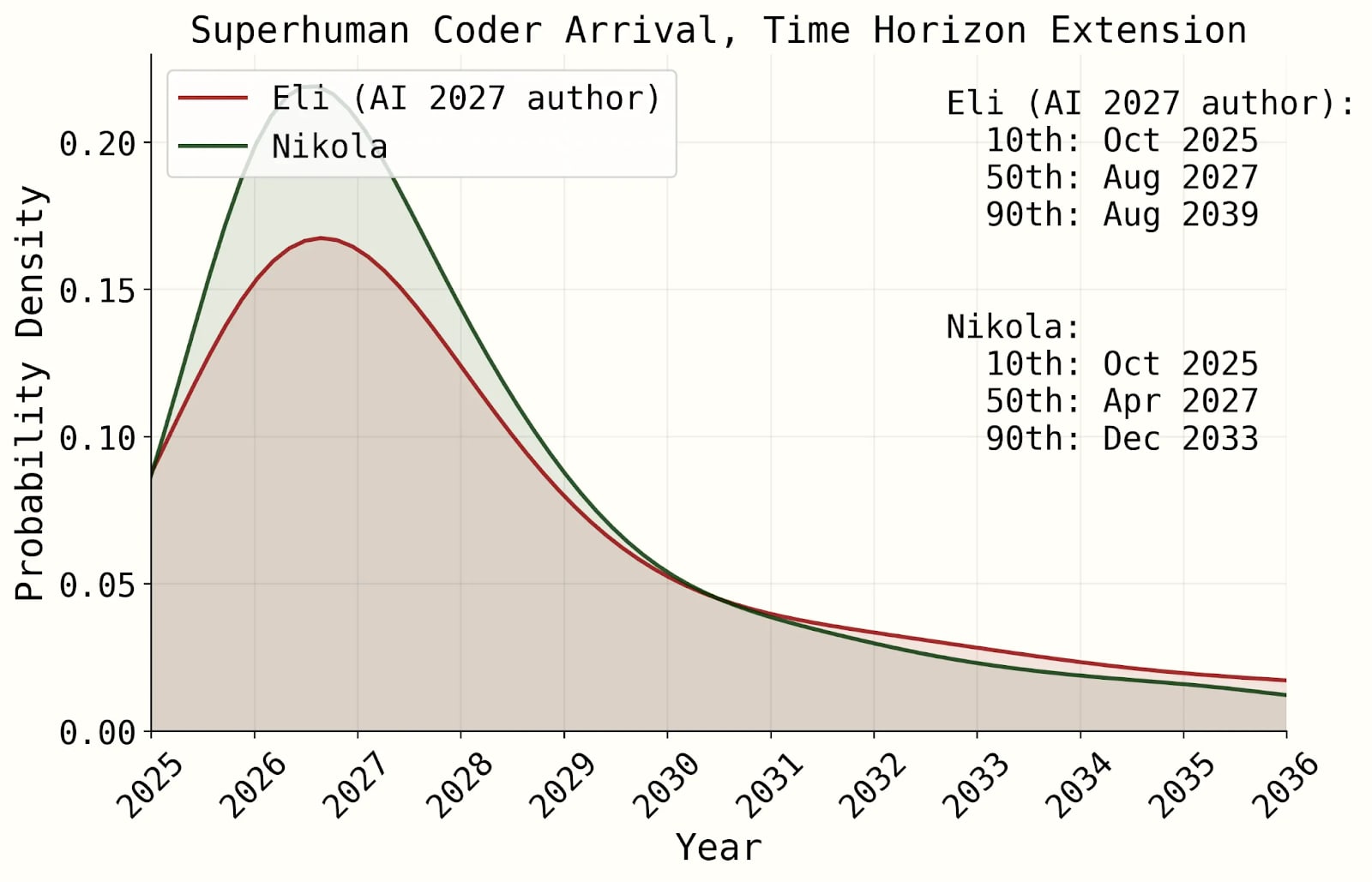
The scenario in the short story is not the median forecast for any AI futures author, and none of the AI2027 authors actually believe that 2027 is the median year for a singularity to happen. But the argument they make is that 2027 is a plausible year, and they back it up with images of sophisticated looking modelling like the following:
This combination of compelling short story and seemingly-rigorous research may have been the secret sauce that let the article to go viral and be treated as a serious project:To quote the authors themselves:
It’s been a crazy few weeks here at the AI Futures Project. Almost a million people visited our webpage; 166,00
·
Authors: Joel McGuire (analysis, drafts) and Lily Ottinger (editing)
Formosa: Fulcrum of the Future?
An invasion of Taiwan is uncomfortably likely and potentially catastrophic. We should research better ways to avoid it.
TLDR: I forecast that an invasion of Taiwan increases all the anthropogenic risks by ~1.5% (percentage points) of a catastrophe killing 10% or more of the population by 2100 (nuclear risk by 0.9%, AI + Biorisk by 0.6%). This would imply it constitutes a sizable share of the total catastrophic risk burden expected over the rest of this century by skilled and knowledgeable forecasters (8% of the total risk of 20% according to domain experts and 17% of the total risk of 9% according to superforecasters).
I think this means that we should research ways to cost-effectively decrease the likelihood that China invades Taiwan. This could mean exploring the prospect of advocating that Taiwan increase its deterrence by investing in cheap but lethal weapons platforms like mines, first-person view drones, or signaling that mobilized reserves would resist an invasion.
Disclaimer
I read about and forecast on topics related to conflict as a hobby (4th out of 3,909 on the Metaculus Ukraine conflict forecasting competition, 73 out of 42,326 in general on Metaculus), but I claim no expertise on the topic. I probably spent something like ~40 hours on this over the course of a few months.
Some of the numbers I use may be slightly outdated, but this is one of those things that if I kept fiddling with it I'd never publish it.
Acknowledgements: I heartily thank Lily Ottinger, Jeremy Garrison, Maggie Moss and my sister for providing valuable feedback on previous drafts.
Part 0: Background
The Chinese Civil War (1927–1949) ended with the victorious communists establishing the People's Republic of China (PRC) on the mainland. The defeated Kuomintang (KMT[1]) retreated to Taiwan in 1949 and formed the Republic of China (ROC). A dictatorship during the cold war, T

EA-style discussion about AI seems to dismiss out of hand the possibility that AI might be sentient. I can’t find an example, but the possibility seems generally scoffed at in the same tone people dismiss Skynet and killer robot scenarios. Bostrom’s simulation hypothesis, however, is broadly accepted as at the very least an interestingly plausible argument.
These two stances seem entirely incompatible - if silicon can create a whole world inside of which are sentient minds, why can’t it just create the minds with no need for the framing device? It is plausible that sentience does not emerge unless you very precisely mimic natural (or “natural”) evolutionary pressures, but this seems unlikely. It’s likewise possible that something about the process by which we expect to create AI doesn’t allow for sentience, but in that case I think the burden of proof is on the people making the argument to identify this feature and argue for their reasons.
The strongest argument I can think off of the top of my head is that, if we expect a chance of future-AI created by something resembling modern machine learning methods to have a chance at sentience, we should likewise expect, say, worm-equivalent AIs to have it to. Is c. elegans sentient? Is OpenWorm? If you answered yes to the first and no to the second, what is OpenWorm missing that c. elegans has?
Many years ago, Eliezer Yudkowsky shared a short story I wrote (related to AI sentience) with his Facebook followers. The story isn't great -- I bring it up here only as an example of people being interested in these questions.