The MechaHitler incident seems to have worked as something of a warning shot, Google interest in AI risk has reached an absolute all time high. Trump's AI plan came out on the same day but the comparisons suggests Grok accounts for ~70% of the peak.
I can't quite dismiss the possibility that the interest was driven by new Chinese AI norms, because Chinese people have to use VPNs, so the geography isn't trustworthy. However, if this were true, I would expect that the number of searches for AI risk in Chinese on Google would be higher than roughly zero (link).
EAGx conferences often feature meetups for subgroups with a shared interest / identity, such as "animal rights", "academia" or "women". Very easy to set up - yet some of the best events. Four forms I've seen are
a) speed-friending
b) brainstorming topics & discussing them in groups
c) red-teaming projects
d) just a big pile of people talking
If you want to maximize the amount of information transferred, form a) seems optimal purely because 50% of people are talking at any point in time in a personalized fashion. If you want to add some choice, you can start by letting people group themselves / order themselves on some spectrum. Presenting this as "human cluster-analysis" might also make it into a nerdy icebreaker. Works great with 7 minute rounds, at the end of which you're only nudged, rather than required, to shift partners.
I loved form c) for AI safety projects at EAGx Berlin. Format: A few people introduce their projects to everyone, then grab a table and present them in more detail to smaller groups. This form might in general be used to allow interesting people to hold small low-effort interactive lectures & utilizing interested people as focus groups.
Form b) seems to be most common for interest-based meetups. It usually includes 1) group brainstorming of topics 2) voting on the topics 3) splitting up 4) presentations. This makes up for a good low-effort event that's somewhere between a lecture and a 1-on-1 in terms of required energy. However, I see 4 common problems with this format: Firstly, steps 1) and 2) take a lot of time and create unnaturally clustered topics (as brainstorming creates topics "token-by-token", rather than holistically). Secondly, in ad hoc groups with >5 members, it's hard to coordinate who takes the word and in turn, conversations can turn into sequences of separate inputs, i.e. members build less upon themselves. Thirdly, spontaneous conversations are hard to compress into useful takeaways that can be presented on the whole group's behalf.
Therefore, a better way of facilitating form b) may be:
Step 0 - before the event, come up with a natural way to divide the topic into a few clusters.
Step 1 - introduce these clusters, perhaps let attendees develop the sub-topics. Their number should divide the group into subgroups of 3-6 people.
Step 2 - every 15 minutes, offer attendees to change a group
Step 3 - 5 minutes before the end, prompt attendees to exchange contact info
Recently, I made RatSearch for googling within EA-adjecent webs. Now, you can try theGPT bot version! (GPT plus required) The bot is instructed to interpret what you want to know in relation to EA and search for it on the Forums. If it fails, it searches through the whole web, while prioritizing the orgs listed by EA News.
Cons: ChatGPT uses Bing, which isn't entirely reliable when it comes to indexing less visited webs.
Pros: It's fun for brainstorming EA connections/perspective, even when you just type a raw phrase like "public transport" or "particle physics"
Neutral: I have yet to experiment whether it works better when you explicitlylimit the search using the site: operator - try AltruSearch 2. It seems better at digging deeper within the EA ecosystem; AltruSearch 1 seems better at digging wider.
Update (12/8):The link now redirects to an updated version with very different instructions. You can still access the older version here.
Cool. I'd be interested in tentatively providing this search for free on EA News via the OpenAI API, depending on monthly costs. Do you know how to implement it?
The first GPT link shows a blank page for me, can you check/update/clean it? It seems, perhaps, you've posted your private editing page link instead of the publicly usable link?
The MechaHitler incident seems to have worked as something of a warning shot, Google interest in AI risk has reached an absolute all time high. Trump's AI plan came out on the same day but the comparisons suggests Grok accounts for ~70% of the peak.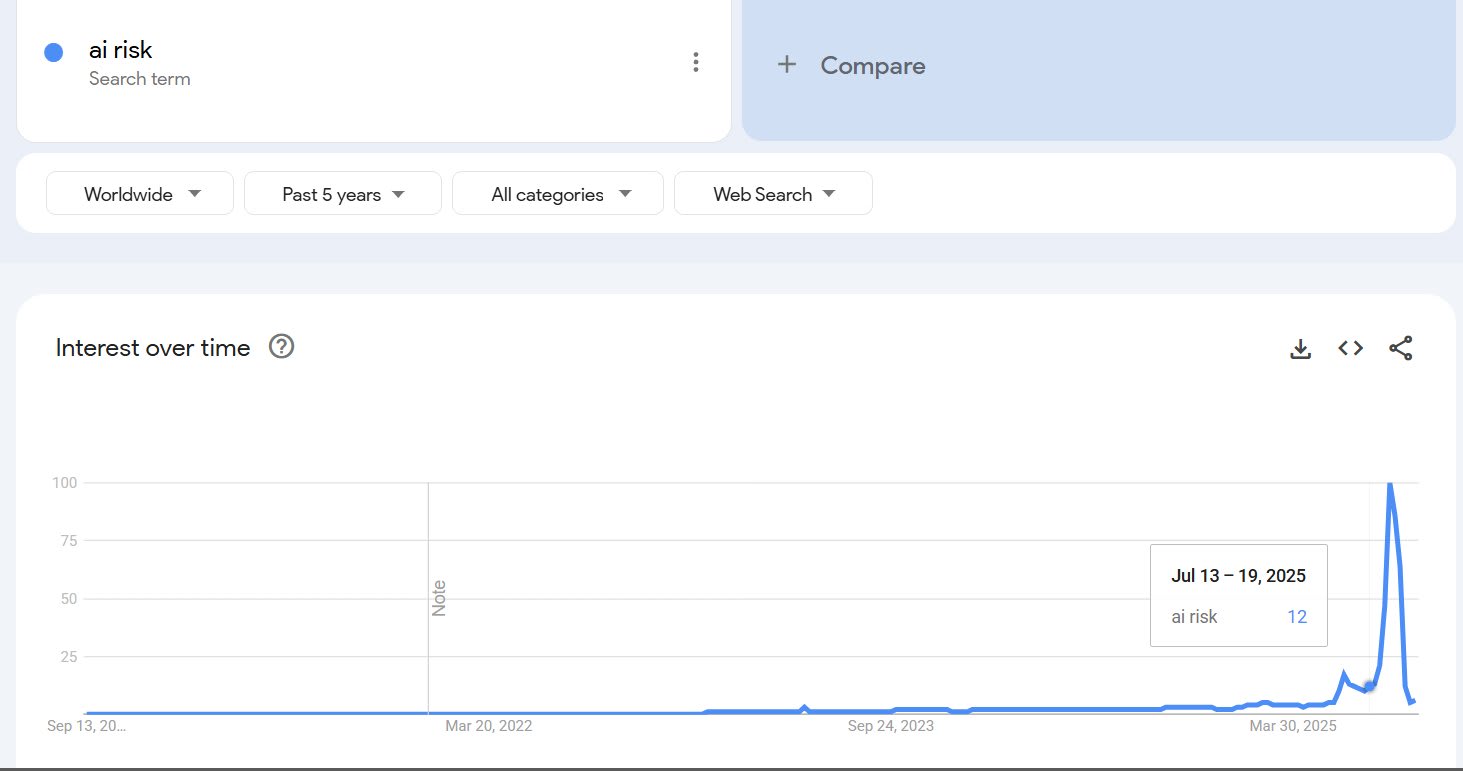
I can't quite dismiss the possibility that the interest was driven by new Chinese AI norms, because Chinese people have to use VPNs, so the geography isn't trustworthy. However, if this were true, I would expect that the number of searches for AI risk in Chinese on Google would be higher than roughly zero (link).
Organizing good EAGx meetups
EAGx conferences often feature meetups for subgroups with a shared interest / identity, such as "animal rights", "academia" or "women". Very easy to set up - yet some of the best events. Four forms I've seen are
a) speed-friending
b) brainstorming topics & discussing them in groups
c) red-teaming projects
d) just a big pile of people talking
If you want to maximize the amount of information transferred, form a) seems optimal purely because 50% of people are talking at any point in time in a personalized fashion. If you want to add some choice, you can start by letting people group themselves / order themselves on some spectrum. Presenting this as "human cluster-analysis" might also make it into a nerdy icebreaker. Works great with 7 minute rounds, at the end of which you're only nudged, rather than required, to shift partners.
I loved form c) for AI safety projects at EAGx Berlin. Format: A few people introduce their projects to everyone, then grab a table and present them in more detail to smaller groups. This form might in general be used to allow interesting people to hold small low-effort interactive lectures & utilizing interested people as focus groups.
Form b) seems to be most common for interest-based meetups. It usually includes 1) group brainstorming of topics 2) voting on the topics 3) splitting up 4) presentations. This makes up for a good low-effort event that's somewhere between a lecture and a 1-on-1 in terms of required energy. However, I see 4 common problems with this format: Firstly, steps 1) and 2) take a lot of time and create unnaturally clustered topics (as brainstorming creates topics "token-by-token", rather than holistically). Secondly, in ad hoc groups with >5 members, it's hard to coordinate who takes the word and in turn, conversations can turn into sequences of separate inputs, i.e. members build less upon themselves. Thirdly, spontaneous conversations are hard to compress into useful takeaways that can be presented on the whole group's behalf.
Therefore, a better way of facilitating form b) may be:
Step 0 - before the event, come up with a natural way to divide the topic into a few clusters.
Step 1 - introduce these clusters, perhaps let attendees develop the sub-topics. Their number should divide the group into subgroups of 3-6 people.
Step 2 - every 15 minutes, offer attendees to change a group
Step 3 - 5 minutes before the end, prompt attendees to exchange contact info
Step 4 - the end.
(I haven't properly tried out this format yet.)
Recently, I made RatSearch for googling within EA-adjecent webs. Now, you can try the GPT bot version! (GPT plus required)
The bot is instructed to interpret what you want to know in relation to EA and search for it on the Forums. If it fails, it searches through the whole web, while prioritizing the orgs listed by EA News.
Cons: ChatGPT uses Bing, which isn't entirely reliable when it comes to indexing less visited webs.
Pros: It's fun for brainstorming EA connections/perspective, even when you just type a raw phrase like "public transport" or "particle physics"
Neutral: I have yet to experiment whether it works better when you explicitly limit the search using the site: operator - try AltruSearch 2. It seems better at digging deeper within the EA ecosystem; AltruSearch 1 seems better at digging wider.
Update (12/8): The link now redirects to an updated version with very different instructions. You can still access the older version here.
Cool. I'd be interested in tentatively providing this search for free on EA News via the OpenAI API, depending on monthly costs. Do you know how to implement it?
Sorry, I don't have any experience with that.
what you were(/are?) looking for seems closest to https://platform.openai.com/docs/assistants
Hey @Daniel_Friedrich, great efforts and updates, the v2 worked great for me.
The first GPT link shows a blank page for me, can you check/update/clean it? It seems, perhaps, you've posted your private editing page link instead of the publicly usable link?
Done, thanks!