Comments
Some tools for collective epistemics



1 min readFeb 6
71
We’ve recently published a set of design sketches for AI tools that help with collective epistemics.
We think that these tools could be a pretty big deal:
- If it gets easier to track what’s trustworthy and what isn’t, we might end up in an equilibrium which rewards honesty
- This could make the world saner in a bunch of ways, and in particular could give us a better shot at handling the transition to more advanced AI systems
We’re excited for people to get started on building tech that gets us closer to that world. We’re hoping that our design sketches will make this area more concrete, and inspire people to get started.
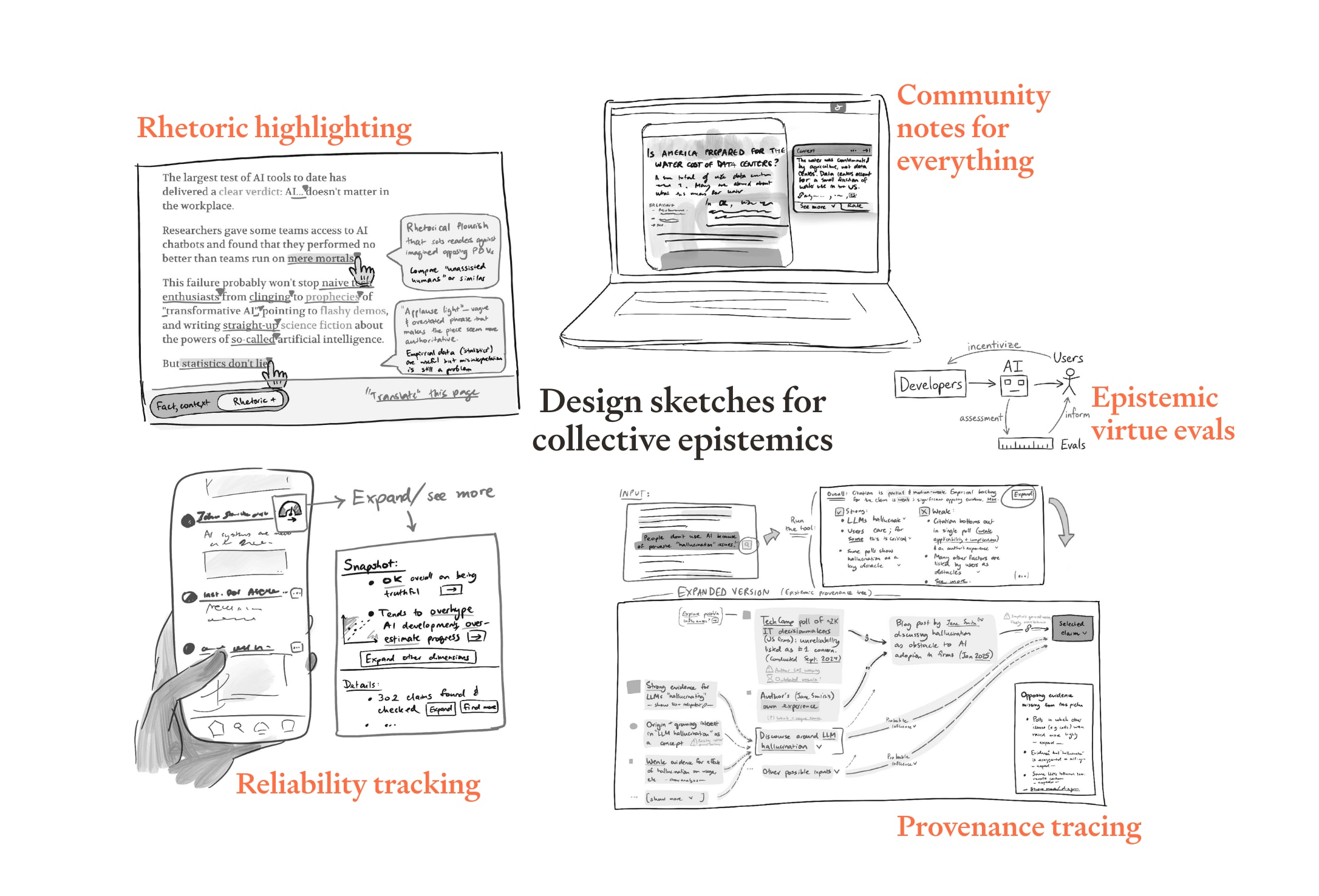
The (overly-)specific technologies we sketch out are:
- Community notes for everything — Anywhere on the internet, content that may be misleading comes served with context that a large proportion of readers find helpful
- Rhetoric highlighting — Sentences which are persuasive-but-misleading, or which misrepresent cited work, are automatically flagged to readers or writers
- Reliability tracking — Users can effortlessly discover the track record of statements on a given topic from a given actor; those with bad records come with health warnings
- Epistemic virtue evals — Anyone who wants a state-of-the-art AI system they can trust uses one that’s been rigorously tested to avoid bias, sycophancy, and manipulation; by enabling “pedantic mode” its individual statements avoid being even ambiguously misleading or false
- Provenance tracing — Anyone seeing data / claims can instantly bring up details of where they came from, how robust they are, etc.
If you have ideas for how to implement these technologies, issues we may not have spotted, or visions for other tools in this space, we’d love to hear them.
This article was created by Forethought. Read the original on our website.

Browser extensions are almost[1] never widely adopted.
Whenever anyone reminds me of this by proposing the annotations everywhere concept again, I remember that the root of the problem is distribution. You can propose it, you can even build it, but it wont be delivered to people. It should be. There are ways of designing computers/a better web where rollout would just happen.
That's what I want to build.
Software mostly isn't extensible, or where it is, it's not extensible enough (even web browsers aren't as extensible as they need to be! Chrome have started sabotaging adblock btw!!). The extensions aren't managed collectively (Chrome would block any such proposal under the pretence that it's a security risk), so features that are only useful if everyone has them just can't come into existence. We continue to design under the assumption that ordinary people are supposed to know what they want before they've tried it.
There are underlying reasons for this: There isn't a flexible shared data model that app components can all communicate through, so there's a limit to what can be built, and how extensible any app can be. Currently, no platform supports sandboxed embedded/integrated components well.
So I started work there.
And then that led to the realization that there is no high level programming language that would be directly compatible with the ideal data model/type system for a composable web (mainly because none of them handle field name collision), so that's where we're at now, programming language design[2]. We also kinda need to do a programming language due to various shortcomings in wasm iirc.
But the adoption pathway is, make better apps for all of the core/serious/actually good things people do with the internet (blogging, social feeds, chat, reddit, wiki, notetaking stuff) (I already wanted to do this), make it crawlable for search engines, get people to transition to this other web that's much more extensible in the same way they'd transition to any new social network.
And then features like this can just grow.
Well, I just checked, apparently like 30% of internet users use ad blockers, that's shockingly hearteningly high, even mobile adoption is only half that. On the other hand, that's just ad blockers, and 30% isn't that good for something with universal appeal that's essentially been advertised for 30 years straight.
It initially seemed like LLM coding might make it harder to launch new programming languages, but nothing worked out the way people were expecting and I think they actually make it way easier. They can write your vscode integration, they can port libraries from other languages, they help people to learn the new language/completely bypass the need to learn the language by letting users code in english then translating it for them.
One potential avenue for distribution is to bundle the epistemic tech not into the browser, but into the AI.
Most simply is a plugin for Claude, which anyone can make. Getting it officially listed from Anthropic would be the next step. There are also Skills and MCP server registries that help, though they still leave most of distribution unsolved.
There's a significant limit on what you can do when the main loop is just an AI, due to robustness issues. The web is a domain where being able to survive constant exposure to adversarial input is pretty much always required. Openclaw is, in a sense, not real, it can't be used as it invites you to use it, it can't be adopted at scale without being so targeted as to become unusable, to be usable it has to be subordinate to a scaffold that's firmer than AI. That's the part I want to make.
Yeah, I feel for the first time founders, who idealistically wish that this part of the problem didn't so much exist. It oughtn't, afaict.
Are you building these things on ATProtocol (Bluesky) or where are you building it right now? I feel like there's quite a nice movement happening there with some specific tools for this sort of thing. (I'm curious because I'm also trying to build some stuff more on the deeper programming level but I'm currently focusing on open-source bridging and recommendation algorithms like pol.is but for science and it would be interesting to know where other people are building things.)
If you don't know about the ATProtocol gang, some things I enjoy here are:
- https://semble.so/
- Paper Skygest: https://bsky.app/profile/paper-feed.bsky.social/feed/preprintdigest
- (Feed on bluesky): https://bsky.app/profile/paper-feed.bsky.social/feed/preprintdigest
- AT Protocol: https://docs.bsky.app/docs/advanced-guides/atproto
I don't think atproto is really a well designed protocol
And the ecosystem currently has nothing to offer, not really
An aside, I looked at margin.at, which is doing the annotations everywhere thing. But it seems to have no moderation system, doesn't allow replies to annotations, doesn't even allow editing or deleting your annotations right now. Why is this being built as a separate system with its own half-baked comment component instead of embedding an existing high quality discussion system from elsewhere in the atmosphere? Because atproto isn't the kind of protocol that even aspires that level of composability and also because nothing in the ecosystem as it stands has a good discussion system.
Is there a risk of boiling the ocean here?
The 'community notes everywhere' proposal seems easy enough to build (I've been hacking away at a Chrome extension version of it). I'm not sure it makes sense to wait for personal computing to change fundamentally before trying to attempt this.
I agree that distribution is an issue, which I'm not sure how to solve. One approach might be to have a core group of users onboarded who annotate a specific subset of pages - like the top 20 posts on Hacker News - so that there's some chance of your notes being seen if you're a contributor. But I suppose this relies on getting that rather large core group of users (e.g. HN readers) to start using the product.
Alternatively you build the thing and hope that it gets adopted in some larger way, say it gets acquired by X if they want to roll out community notes to the whole web.
Yes. But this ocean has actually been boiled many times before. Each of facebook, gmail, discord, X, had an opportunity to remake the internet, and they needlessly blew it or declined to attempt it. In China it's already happened (mini-apps on wechat).
Well, it's been built many times. Hypothes.is was the last one I tried.
One of the reasons I don't want to build that yet is that I foresee moderation issues. Comment sections with no moderation will be annoying, people might end up deciding not to read them. Reddit style moderation isn't particularly good either, it requires a spam-prevention approach and it requires larger crowds, to converge, which you'll basically never have. I don't think there are any conventional moderation systems that work here?
I wanted to use a web of trust approach, where you only see highlights prominently if they're from your network (the people who are accountable or relevant to you). And building a web of trust isn't necessarily easy. It benefits a lot from being integrated with other systems.
And in general the need for integration just keeps arising.
But does any of this mean you shouldn't go ahead and do it? Probably not. I wont make the perfect the enemy of the good, though I ask that if a perfect thing is born please make sure the good wont end up being its enemy either.
The post here for me implied an approach of having LLM-generated comments there first. Presumably if it ever became popular enough to garner human comments (or human-curated comments) the prominence of the initial LLM comments could decrease naturally.
A generalization of this occurs to me; it'd be useful to show users a measure of how many other extension users have viewed particular pages, which is to say, how many people could have helped if someone had made a correction.
But yeah I think it also makes sense to start with a campaign/mass commitment with a specific demographic.