Note: This post contains personal opinions that don’t necessarily match the views of others at CAIP.
Executive Summary
Advanced AI has the potential to cause an existential catastrophe. In this essay, I outline some policy ideas which could help mitigate this risk. Importantly, even though I focus on catastrophic risk here, there are many other reasons to ensure responsible AI development.
I am not advocating for a pause right now. If we had a pause, I think it would only be useful insofar as we use the pause to implement governance structures that mitigate risk after the pause has ended.
This essay outlines the important elements I think a good governance structure would include: visibility into AI development, and brakes that the government could use to stop dangerous AIs from being built.
First, I’ll summarize some claims about the strategic landscape. Then, I’ll present a cursory overview of proposals I like for US domestic AI regulation. Finally, I’ll talk about a potential future global coordination framework, and the relationship between this and a pause.
The Strategic Landscape
Claim 1: There’s a significant chance that AI aligment is difficult.
There is no scientific consensus on the difficulty of AI alignment. Chris Olah from Anthropic tweeted the following, simplified picture:
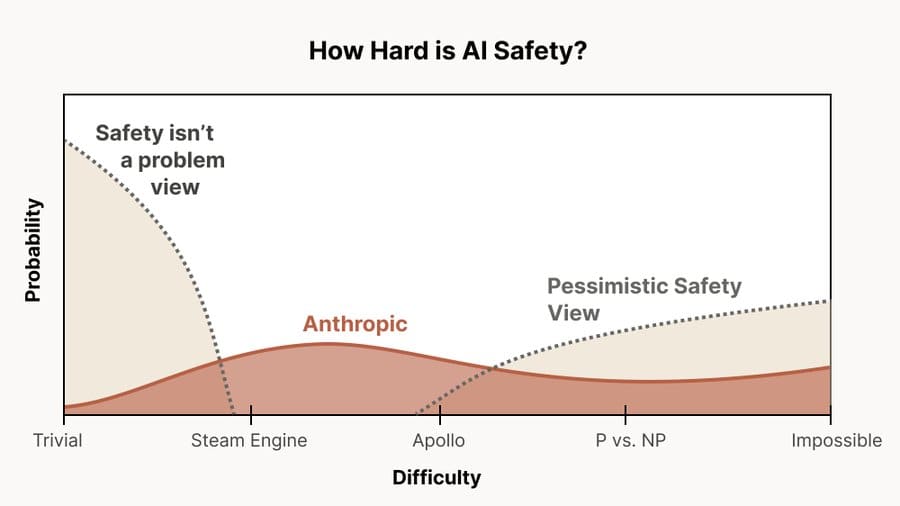
~40% of their estimate is on AI safety being harder than Apollo, which took around 1 million person-years. Given that less than a thousand people are working on AI safety, this viewpoint would seem to imply that there’s a significant chance that we are far from being ready to build powerful AI safely.
Given just Anthropic’s alleged views, I think it makes sense to be ready to stop AI development. My personal views are more pessimistic than Anthropic’s.
Claim 2: In the absence of powerful aligned AIs, we need to prevent catastrophe-capable AI systems from being built.
Given developers are not on track to align AI before it becomes catastrophically dangerous, we need the ability to slow down or stop before AI is catastrophically dangerous.
There are several ways to do this.
I think the best one involves building up the government’s capacity to safeguard AI development. Set up government mechanisms to monitor and mitigate catastrophic AI risk, and empower them to institute a national moratorium on advancing AI if it gets too dangerous. (Eventually, the government could transition this into an international moratorium, while coordinating internationally to solve AI safety before that moratorium becomes infeasible to maintain. I describe this later.)
Some others think it’s better to try to build aligned AIs that defend against AI catastrophes. For example, you can imagine building defensive AIs that identify and stop emerging rogue AIs. To me, the main problem with this plan is that it assumes we will have the ability to align the defensive AI systems.
Claim 3: There’s a significant (>20%) chance AI will be capable enough to cause catastrophe by 2030.
AI timelines have been discussed thoroughly elsewhere, so I’ll only briefly note a few pieces of evidence for this claim I find compelling:
- Current trends in AI. Qualitatively, I think another jump of the size from GPT-2 to GPT-4 could get us to catastrophe-capable AI systems.
- Effective compute arguments, such as Ajeya Cotra’s Bioanchors report. Hardware scaling, continued algorithmic improvement, investment hype are all continuing strongly, leading to a 10x/year increase of effective compute used to train the best AI system. Given the current rates of progress, I expect another factor of a million increase in effective compute by 2030.
- Some experts think powerful AI is coming soon, both inside and outside of frontier labs. Yoshua Bengio is 90% confident in 5-20 years. Demis Hassabis thinks AGI could be a few years away. OpenAI says that “we believe [superintelligence] could arrive this decade”. Anthropic stated a “greater than 10% likelihood that we will develop broadly human-level AI systems within the next decade.”
Summary
I’ve argued for 3 high-level claims:
- There’s a significant chance that AI alignment is difficult.
- In the absence of powerful aligned AIs, we need to prevent catastrophe-capable AI systems from being built.
- There’s a significant (>20%) chance of catastrophe-capable AI by 2030.
Together, claims (1) and (2) imply that there is a significant chance of AI systems causing catastrophic harm, and so we need to prevent AI systems that could cause catastrophe from being built. Claim (3) adds in urgency – there’s a large enough chance of things going wrong soon that it is important to act now.
There are other challenges besides misalignment. Adversaries could also misuse powerful AI systems. Well-intentioned developers could fail to successfully align their AI system because of a race to the bottom or engineering errors.
Given all these, I think it’s good to push for governance structures that can prevent dangerous AI systems from being built. I suggest we start by developing these nationally.
A National Policy Proposal
We should build up the capacity for the US government to stop dangerous AI development before an AI catastrophe occurs. To do this, we need to increase government visibility into AI development so that they know when things are getting dangerous, and to give the government brakes that they can pull in order to prevent dangerous AI development.
Some ideas for increasing the government’s visibility into AI development are:
- A regulatory body that keeps track of AI development, makes predictions about model capabilities, and assesses risks.
- Required watermarking and traceability on advanced models, so that we can match AI outputs to specific AI models and developers.
- Whistleblower protections to incentivize researchers to report any dangerous AI development.
Some ideas for giving the government brakes on dangerous AI development are:
- Strengthening the hardware export controls to include chips like A800s and H800s.
- Giving the regulator emergency powers that allow it to temporarily shut down dangerous AI development.
- Tracking domestic hardware use to ensure that the agency could implement its emergency powers and enforce regulations.
- Licensing to reject individual instances of dangerous AI development.
If these policies were passed and implemented, they would not guarantee a safe outcome, but they would make us significantly safer. The visibility needs to work sufficiently well that the government understands that catastrophic AI could happen soon, and then has the willingness and competence to take effective action to prevent dangerous AI models from being built and deployed. A key challenge for this action is the increasing number of actors who will have the ability to build an AI system of a given capability over time. The world would need to use the additional window of time created by this intervention to work on safety and alignment.
I’ll now discuss two especially important points in a bit more detail: the regulatory body, and emergency powers.
Regulatory Body
We should create a federal regulatory body with the mandate to keep domestic AI development below an agreed upon risk threshold. This body must prevent the creation of smarter-than-human AI systems until humanity has the technical expertise to make a strong argument that they are safe.
The regulatory body should be focused on licensing the most advanced AI systems. Ideally, this would be done based on the model’s capabilities to cause harm. Unfortunately, it can be difficult to predict a model’s capabilities before we’ve trained that model, and even after they are trained, the technology for evaluating model capabilities is not perfect. One way this goes wrong is that, after a model is released, a novel strategy for improving model capabilities is developed, such as chain-of-thought prompting.
Because there is no perfect criteria that only captures dangerous AI systems, and progress in AI advances quickly (such that any static definition could quickly become outdated), I believe we should use a dynamic definition that consists of multiple criteria. The criteria could be based on imperfect proxies of model capabilities, such as compute, parameter count, money spent on the training run, and predictions of model capabilities. Given that the AI field advances faster than a typical legislative cycle, the agency must be sufficiently dynamic to handle new advances and types of systems, and must be able to change the scope of its licensing to include any dangerous new models.
Given that these proxies are imperfect, the regulator should have a fast track application form to exclude models that clearly pose no catastrophic risks. For example, the vast majority of recommender systems, self-driving car software, weather prediction models, and image recognition models would be fast-tracked and would not have to go through the regular licensing process.
Emergency Powers
In the case of a national emergency with a potentially catastrophic AI system, the regulator should have the power to issue a cease and desist order to the relevant party. In cases of sufficient risk, the regulator should be equipped with the ability to initiate a moratorium on future development, deployment, and proliferation of potentially dangerous AI systems, which could then be confirmed by the President and eventually by Congress. This moratorium would ideally last until we have strong arguments that AI systems are safe. The regulator would also be expected to swiftly issue guidance to the President and Congress in the event of an AI-related emergency.
The regulator’s use of its emergency powers would be guided by its work on the monitoring of advanced AI hardware. Because the regulator will be able to keep track of who owns the largest computing clusters, no one will be able to build advanced AI in total secrecy.
Some Objections
I’m aware of several objections to my proposals. Below are a few of the important objections that I’m keeping in mind, along with a brief summary of some ideas to mitigate these potential problems.
- Regulatory incompetence.
- Problem: The US government has a poor track record of developing and implementing safety standards in other fields.
- Solutions: There are examples of positive regulations, e.g. cars are much safer because the Department of Transportation requires transportation safety measures. The regulator should invite a wide range of experts from industry and academia to help develop the standards, building on the work done by NIST and by private-public “blue ribbon” commissions, and update the standards as the field evolves.
- Regulatory capture.
- Problem: The regulatory agency could become a puppet of industry (or a few key industry players).
- Solutions: The regulatory agency will have robust conflict-of-interest provisions, “sunshine” laws that require the administrator to publicly report on their disagreements with the independent licensing judges, and a special “public interest” section that is charged with monitoring the administration’s actions and calling out any dangers that the administration has left unchecked.
- Political feasibility.
- Problem: Asking for a new agency is a big ask, and it might not be politically practical right now.
- Solutions: This proposal is modular; politicians can easily adopt a subset of these proposals to match the budget available. If the policies that are initially approved are too small to justify creating a whole new agency, then it can be created as an office within an existing agency. Additionally, asking for a new agency may become politically practical in the future.
- International AI Development
- Problem: Other countries may develop dangerous AI systems.
- Solutions: This proposal is mainly aimed at mitigating domestic AI risk, but there is an ultimate need for international regulation. This is discussed in more depth below.
Additional details
At the Center for AI Policy, my team is working on developing the strategic thinking and policies I outlined above. Our proposed legislation would create a regulatory agency dedicated to safeguarding AI development, which would monitor advanced hardware, license frontier AI projects, and hold developers accountable for severe harms resulting from their models.
I would love feedback on our work. If you want to learn more about it, share considerations I did not address, or have ideas for improvements, please contact me at [email protected].
International AI Policy
Dangerous AI systems can be built anywhere, which means that purely domestic regulation is not sufficient in the long term. Unless we find a way to adequately defend the world against dangerous AI systems, which probably require powerful aligned AI, we need effective international coordination that prevents the development of dangerous AI globally.
We don’t need to immediately coordinate all the countries on earth. Currently, the US has a substantial lead on the rest of the world on AI capabilities, and so regulation can start in the US, and then expand to other countries as their capabilities approach the danger threshold. Additionally, the hardware supply chain needed to build advanced AI systems is predominantly controlled by the West. Strengthened export controls could prevent foreign countries with inadequate AI governance from building dangerous AI systems for a significant period.
Here is a hypothetical structure for global coordination: create an international body, which I've called the "IAEA for AI", tasked with both preventing dangerous AI development and making progress on AI safety.
The "Preventing Dangerous AI" side of the agency develops and communicates safety standards to the member countries, each of whom has their own regulatory body that directly regulates AI development within their country.
The "Solving Safety" side should work on many parallel routes towards safety, because none of the paths are sure to succeed.
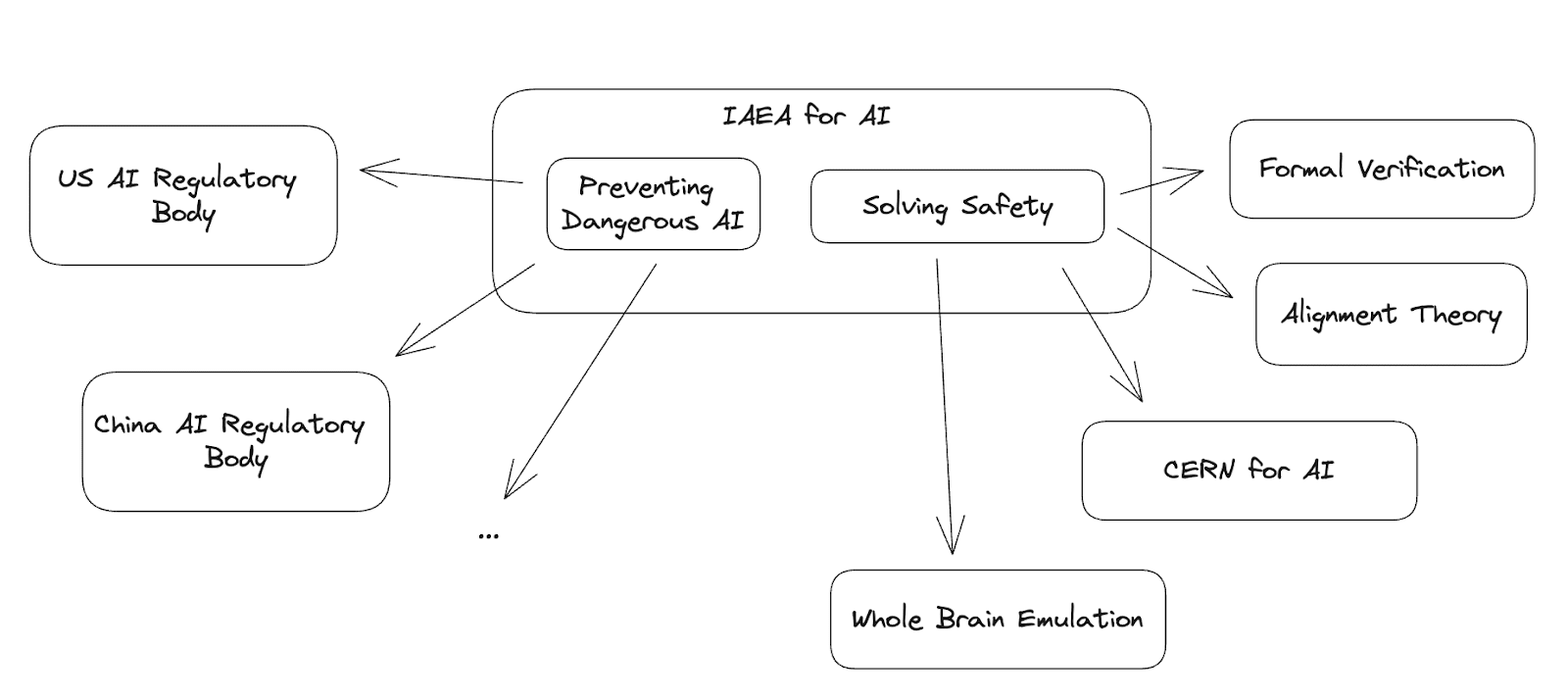
Preventing Dangerous AI
To prevent dangerous AI, the key mechanism we have is preventing actors from stockpiling large enough amounts of compute to build an AI system.
A toy visualization of how this might work is here:
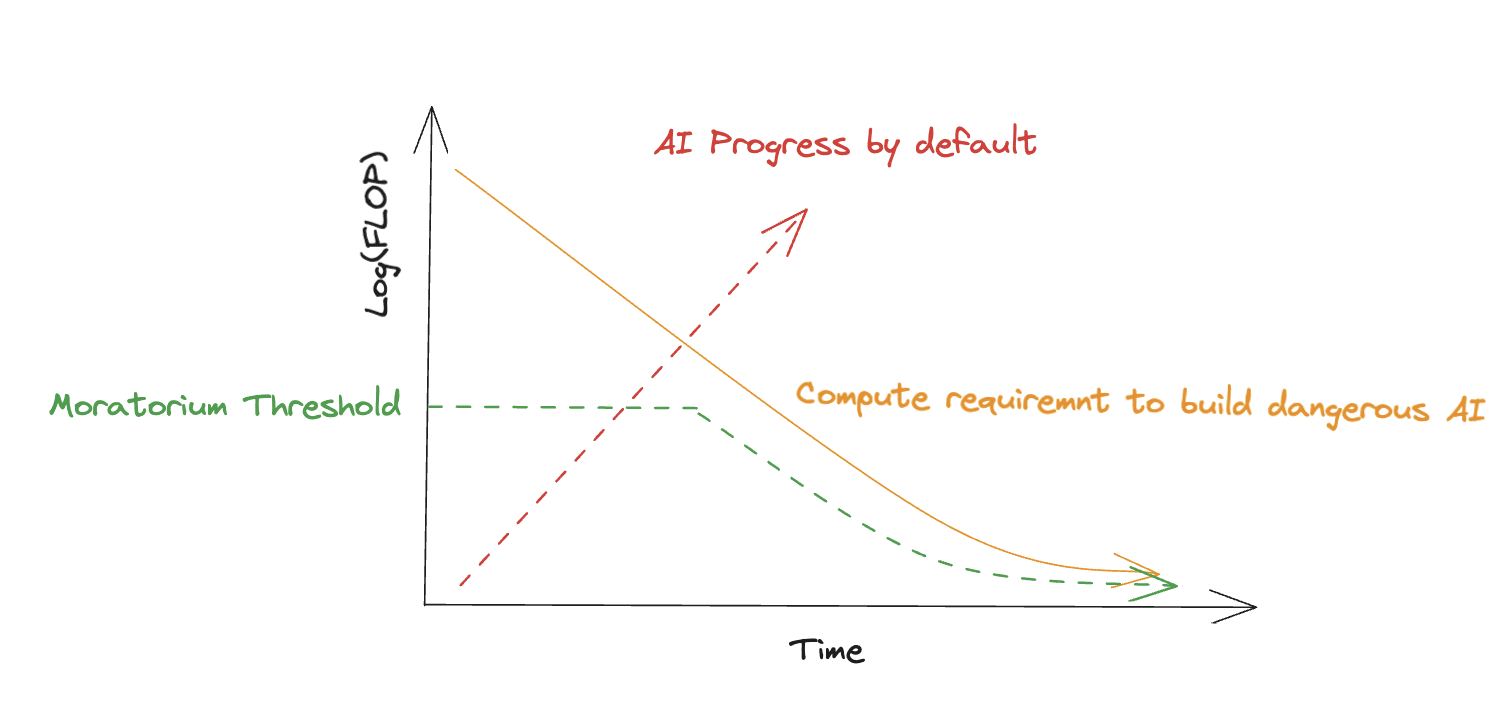
The yellow decreasing line is the compute requirement to build dangerous AI, which is decreasing as people discover more capable AI algorithms. This amount of compute is being divided by roughly 2.5 every year. The red increasing line is the compute that labs have access to, which is increasing as hardware becomes better and investment increases, which is being multiplied by ~4x every year.
The green decreasing curve is the moratorium threshold, which is the largest amount of unmonitored compute that actors can develop.
The international body needs to keep the threshold for the moratorium (the green curve) below the amount of compute it takes to build dangerous AI (the yellow curve), by adjusting the maximum amount of unmonitored compute actors can get ahold of.
Solving Safety
The "Solving Safety" side should support many parallel routes towards AI safety, because none of the agendas are sure to work out, and many of them are serial time bottlenecked. Some routes that we could take include:
- A “CERN for AI” project iterating on empirical AI safety & control.
- Theoretical AI safety research.
- Formal Verification, which requires formalizing what it means for something to be safe.
- Whole Brain Emulation, or other non-standard paths to AI that may be safer than the current paradigm.
One key difficulty here is creating the institutional capacity to evaluate which projects are promising, and a big part of that will rest on getting people with the ability to do this differentiation into the bureaucracy that is making these decisions.
My thoughts on a pause
I think a pause on AI progress wouldn’t be very helpful unless used in concert with other effective governance interventions, such as the ones that I have outlined above. My main concern with a pause in the absence of other governance interventions is that, after we unpause, things would go back to normal, and someone could just build a dangerous AI system slightly later.
Pausing just the training or deployment of the largest models is a shallow intervention that doesn’t affect the main drivers of capabilities progress. After the pause is lifted, we’ll likely see AI progress spike as actors immediately kick off much more advanced training runs than they had done in the past.
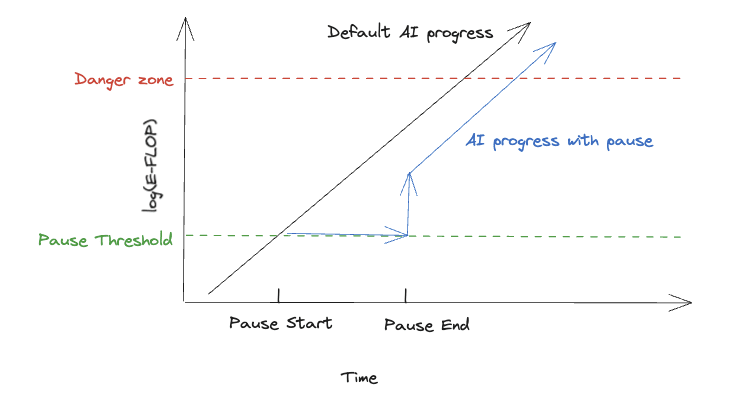
A particularly worrying instance of this is the compute overhang from continued progress on AI. We can visualize this as:
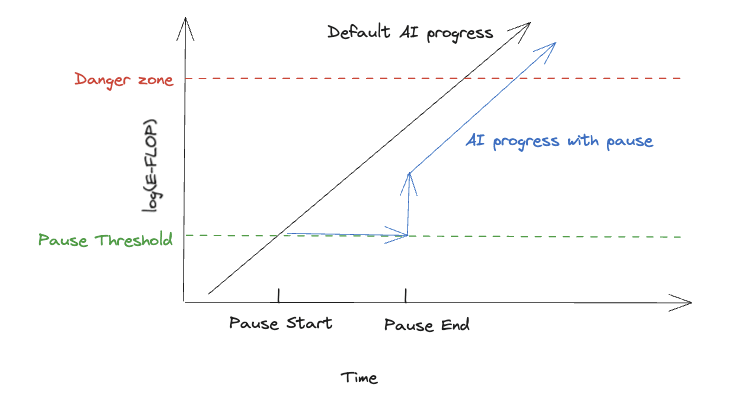 The y-axis is effective-FLOP (E-FLOP), which is the amount of compute used to train a model, adjusted for algorithmic progress. The green line represents the maximum capabilities of AI models when the pause starts.
The y-axis is effective-FLOP (E-FLOP), which is the amount of compute used to train a model, adjusted for algorithmic progress. The green line represents the maximum capabilities of AI models when the pause starts.
If a pause is successfully implemented before we get to the danger threshold, this renders things safe during the pause, and then jumps up after the pause is lifted. There are a few reasons that I don’t expect the overhang to return to previous default progress. One is that AI progress is self-reinforcing. For example, OpenAI is much better able to fundraise after the release of GPT-4 because of GPT-4’s advanced capabilities. This means that the overhang is less tall in a world with an AI pause than in a world where AI progress continues unabated, which suggests that there could be a lasting effect from a pause.
All in all, a short pause (e.g. 6 months) probably just delays scheduled training runs, and during this pause, companies would stockpile compute and continue work on improving their algorithms. A medium length pause (e.g. 1 year) probably delays AI capabilities a little bit, but results in a significant jump in capability once the pause is lifted. A longer pause that lasts until we are confident that we have robust AI safety measures in place that allow for safe deployment would be helpful. I’m currently in favor of building the capacity of the world to create a long pause on AI.
As a result, I’m only excited about versions of a pause that don’t return to “AI progress as usual”, after the pause is over.
This post is part of AI Pause Debate Week. Please see this sequence for other posts in the debate.


Thanks for writing this up!
I hope to write a post about this at some point, but since you raise some of these arguments, I think the most important cruxes for a pause are:
Any realistic pause would only be lifted once there is a consensus on a potential solution to x-safety (or at least, say, full solutions to all jailbreaks, mechanistic interpretability and alignment up to the (frozen) frontier). If compute limits are in place during the pause, they can gradually be ratcheted up, with evals performed on models trained at each step, to avoid any such sudden snap back.