Crossposted to LessWrong.
In October 2022, 91 EA Forum/LessWrong users answered the AI timelines deference survey. This post summarises the results.
Context
The survey was advertised in this forum post, and anyone could respond. Respondents were asked to whom they defer most, second-most and third-most, on AI timelines. You can see the survey here.
Results
This spreadsheet has the raw anonymised survey results. Here are some plots which try to summarise them.[1]
Simply tallying up the number of times that each person is deferred to:
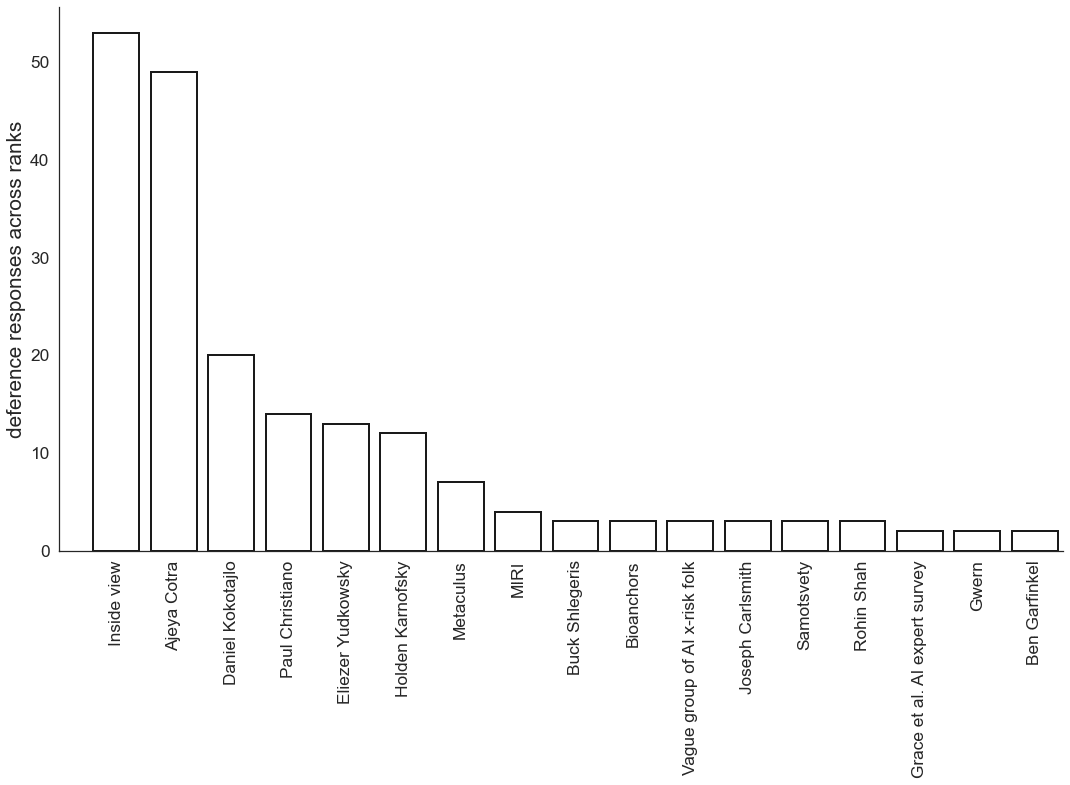
The plot only features people who were deferred to by at least two respondents.[2]
Some basic observations:
- Overall, respondents defer most frequently to themselves—i.e. their “inside view” or independent impression—and Ajeya Cotra. These two responses were each at least twice as frequent as any other response.
- Then there’s a kind of “middle cluster”—featuring Daniel Kokotajlo, Paul Christiano, Eliezer Yudkowsky and Holden Karnofsky—where, again, each of these responses were ~at least twice as frequent as any other response.
- Then comes everyone else…[3] There’s probably something more fine-grained to be said here, but it doesn’t seem crucial to understanding the overall picture.
What happens if you redo the plot with a different metric? How sensitive are the results to that?
One thing we tried was computing a “weighted” score for each person, by giving them:
- 3 points for each respondent who defers to them the most
- 2 points for each respondent who defers to them second-most
- 1 point for each respondent who defers to them third-most.
If you redo the plot with that score, you get this plot. The ordering changes a bit, but I don’t think it really changes the high-level picture. In particular, the basic observations in the previous section still hold.
We think the weighted score (described in this section) and unweighted score (described in the previous section) are the two most natural metrics, so we didn’t try out any others.
Don’t some people have highly correlated views? What happens if you cluster those together?
Yeah, we do think some people have highly correlated views, in the sense that their views depend on similar assumptions or arguments. We tried plotting the results using the following basic clusters:
- Open Philanthropy[4] cluster = {Ajeya Cotra, Holden Karnofsky, Paul Christiano, Bioanchors}
- MIRI cluster = {MIRI, Eliezer Yudkowsky}
- Daniel Kokotajlo gets his own cluster
- Inside view = deferring to yourself, i.e. your independent impression
- Everyone else = all responses not in one of the above categories
Here’s what you get if you simply tally up the number of times each cluster is deferred to:
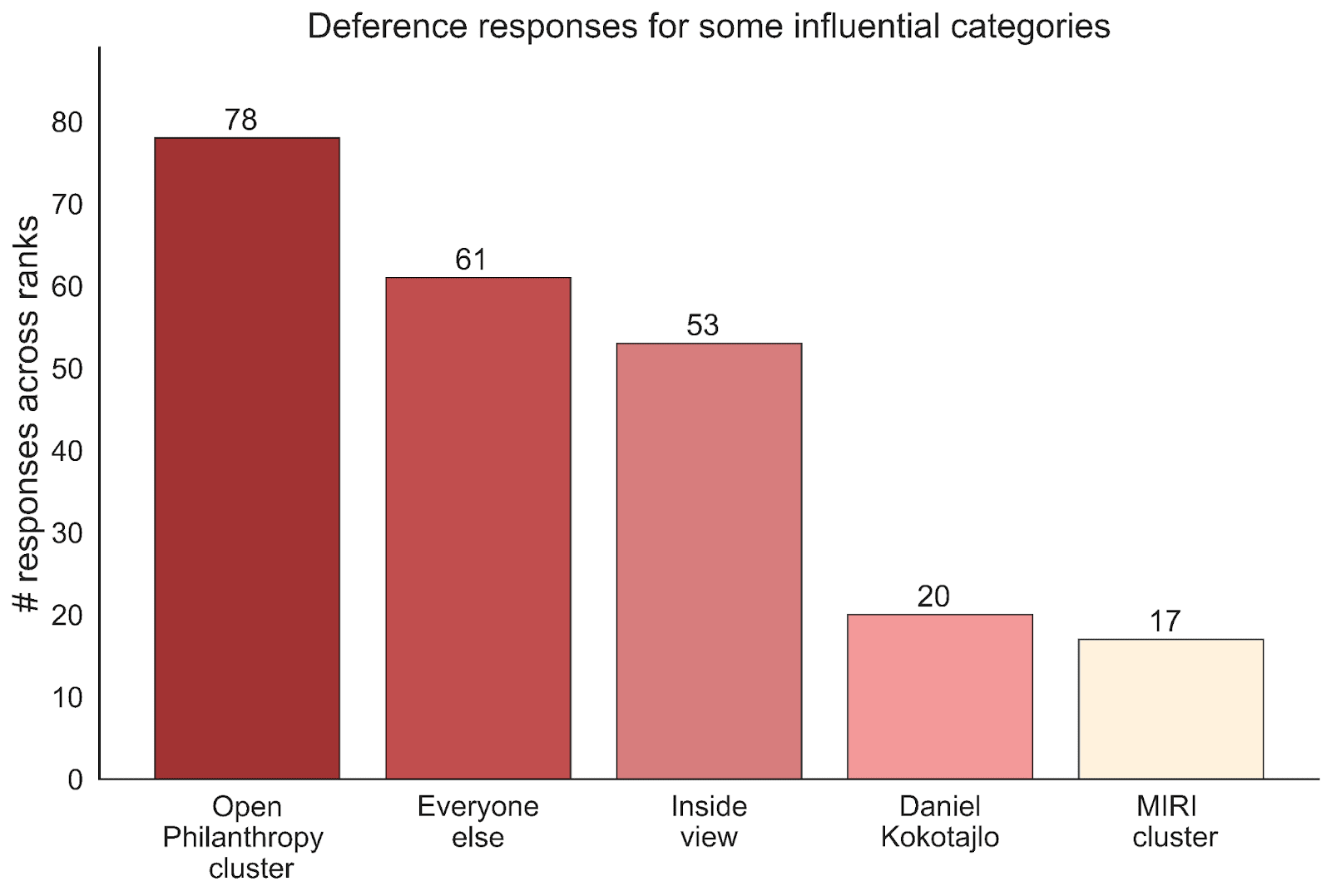
This plot gives a breakdown of two of the clusters (there’s no additional information that isn’t contained in the above two plots, it just gives a different view).
This is just one way of clustering the responses, which seemed reasonable to us. There are other clusters you could make.
Limitations of the survey
- Selection effects. This probably isn’t a representative sample of forum users, let alone of people who engage in discourse about AI timelines, or make decisions influenced by AI timelines.
- The survey didn’t elicit much detail about the weight that respondents gave to different views. We simply asked who respondents deferred most, second-most and third-most to. This misses a lot of information.
- The boundary between [deferring] and [having an independent impression] is vague. Consider: how much effort do you need to spend examining some assumption/argument for yourself, before considering it an independent impression, rather than deference? This is a limitation of the survey, because different respondents may have been using different boundaries.
Acknowledgements
Sam and McCaffary decided what summary plots to make. McCaffary did the data cleaning, and wrote the code to compute summary statistics/make plots. Sam wrote the post.
Daniel Kokotajlo suggested running the survey. Thanks to Noemi Dreksler, Rose Hadshar and Guive Assadi for feedback on the post.
- ^
You can see the code for these plots here, along with a bunch of other plots which didn’t make the post.
- ^
Here’s a list of people who were deferred to by exactly one respondent.
- ^
Arguably, Metaculus doesn’t quite fit with “everyone else”, but I think it's good enough as a first approximation, especially when you also consider the plots which result from the weighted score (see next section).
- ^
This cluster could have many other names. I’m not trying to make any substantive claim by calling it the Open Philanthropy cluster.
{kind=link}
{kind=link}
Things that surprised me about the results
Thanks for doing this survey and sharing the results, super interesting!
Regarding
Yes, I definitely think that there's a lot of potential for social desirability bias here! And I think this can happen even if the responses are anonymous, as people might avoid the cognitive dissonance that comes with admitting to "not having an inside view." One might even go as far as framing the results as "Who do people claim to defer to?"