Comments
I really liked this edition! Best wishes for whatever is next.
I really liked this edition! Best wishes for whatever is next.
Thanks so much for this!
I don't suppose either of you have read Petra Kosonen's, Tiny probabilities and the value of the far future? I found it a little hard to follow but am I right in thinking that one of the main arguments is the following?
Even if we think this 'time of perils' is here to stay and assume a constant existential risk per century of 1 in 6 from now on - and with no sci-fi space colonization or 'digital people' in the meantime - an individual's donations to AI safety efforts are still more cost-effective than donations to AMF, since biological humanity's expected lifespan on Earth only needs to be at least another ~250 years to make that the case.
(This assumes that current existential risk from AI is >0.1% in the next 100 years, that an additional $1bn would reduce this probability by >1% - i.e. from 0.1% to 0.099% - and that we should treat an individual's contribution to this $1bn as non-negligible just as we do with voting.)
That might not be enough to convince most people who have very high confidence in person-affecting ethics, but it could be persuasive for some others with broadly 'neartermist' leanings.
Hi Ubuntu,
I'm not sure if you are already aware of it, but we featured a conversation with Petra in an early issue of our newsletter, where she discusses some of these topics (including probability discounting and its implications for longtermism). I mention it in case it helps clarify some of the claims she makes in the paper.
Future Matters is a newsletter about longtermism and existential risk. Each month we collect and summarize relevant research and news from the community, and feature a conversation with a prominent researcher. You can also subscribe on Substack, listen on your favorite podcast platform and follow on Twitter. Future Matters is also available in Spanish.
This issue marks one year since we started Future Matters. We’re taking this opportunity to reflect on the project and decide where to take it from here. We’ll soon share our thoughts about the future of the newsletter in a separate post, and will invite input from readers. In the meantime, we will be pausing new issues of Future Matters. Thank you for your support and readership over the last year!
Microsoft recently announced a significant partnership with OpenAI [see FM#7] and launched a beta version of a chatbot integrated with the Bing search engine. Reports of strange behavior quickly emerged. Kevin Roose, a technology columnist for the New York Times, had a disturbing conversation in which Bing Chat declared its love for him and described violent fantasies. Evan Hubinger collects some of the most egregious examples in Bing Chat is blatantly, aggressively misaligned. In one instance, Bing Chat finds a user’s tweets about the chatbot and threatens to exact revenge. In the LessWrong comments, Gwern speculates on why Bing Chat exhibits such different behavior to ChatGPT, despite apparently being based on a closely-related model. (Bing Chat was subsequently revealed to have been based on GPT-4).
Holden Karnofsky asks What does Bing Chat tell us about AI risk? His answer is that it is not the sort of misaligned AI system we should be particularly worried about. When Bing Chat talks about plans to blackmail people or commit acts of violence, this isn’t evidence of it having developed malign, dangerous goals. Instead, it’s best understood as Bing acting out stories and characters it’s read before. This whole affair, however, is evidence of companies racing to deploy ever more powerful models in a bid to capture market share, with very little understanding of how they work and how they might fail. Most paths to AI catastrophe involve two elements: a powerful and dangerously misaligned AI system, and an AI company that builds and deploys it anyway. The Bing Chat affair doesn’t reveal much about the first element, but is a concerning reminder of how plausible the second is.
Robert Long asks What to think when a language model tells you it's sentient [🔉]. When trying to infer what’s going on in other humans’ minds, we generally take their self-reports (e.g. saying “I am in pain”) as good evidence of their internal states. However, we shouldn’t take Bing Chat’s attestations (e.g. “I feel scared”) at face value; we have no good reason to think that they are a reliable guide to Bing’s inner mental life. LLMs are a bit like parrots: if a parrot says “I am sentient” then this isn’t good evidence that it is sentient. But nor is it good evidence that it isn’t — in fact, we have lots of other evidence that parrots are sentient. Whether current or future AI systems are sentient is a valid and important question, and Long is hopeful that we can make real progress on developing reliable techniques for getting evidence on these matters. Long was interviewed on AI consciousness, along with Nick Bostrom and David Chalmers, for Kevin Collier’s article, What is consciousness? ChatGPT and Advanced AI might define our answer[1] [🔉].
In the last few weeks, we got more information about how the leading AI labs are thinking about safety and alignment:
Tom Davidson is a Senior Research Analyst at Open Philanthropy, where he studies potential risks from advanced artificial intelligence. He previously worked as a data scientist for BridgeU, an education technology startup, and taught science at a UK comprehensive school. Tom has a Masters in Physics and Philosophy from the University of Oxford.
Future Matters: To begin with, could you explain why you think it’s important to understand and forecast AI takeoff dynamics?
Tom Davidson: There's a few things. The most zoomed out answer is that it's one thing to know when this big event is going to happen—and that is obviously useful for planning and preparing—but it's also very useful to know how it's going to play out, what the internal dynamics will be, and how long we'll have between various different milestones. If you're trying to practically anticipate what's going to happen and affect it, then knowing what the dynamics are and what that process looks like is very useful for informing actions. So takeoff speeds is one important parameter in understanding how the transition to AI is going to happen in practice.
In terms of focusing specifically on the speed element of AI takeoff, I think that is strategically important for a few reasons. Probably the most salient is the question of how much time we have, before the arrival of AI systems that pose an existential risk, with systems that are similar to those really dangerous systems. If takeoff is really slow, then there are many things we could do: we could have years playing around with systems that are deceptively aligned or that are doing treacherous turns that we can observe in the lab; we could try out different techniques to avoid it; we could generate a real consensus around that as a risk, develop a real science of it, do a lot of empirical testing, etc. If takeoff is really fast, then we could have maybe mere months to do that kind of work without a concerted slowdown in AI progress. So takeoff speed seems really important for understanding how high the risks are, what kind of strategies will reduce them, and whether we can just wing it and do the experiments as we go or need to be planning in advance to really slow down when AI capabilities become potentially dangerous.
Then there are other reasons why takeoff speed is important. I think using AIs to solve alignment for us seems like a more promising plan if takeoff speed is slower because we have longer to figure out how to use these AIs in alignment and set up the workflows to do that effectively, and there’s more time between “AI is helpful in alignment” and “AI will cause a catastrophe if it’s misaligned”. My impression is that labs are expecting this time period to be longer than I think it will be by default, which provides another argument for agreeing ahead of time to significantly slow down AI progress when things become potentially dangerous.
Then there are questions about the number of actors that will be involved: if takeoff speed is faster then fewer actors, and actors that are already ahead, are more likely to be important, and new actors like governments are less likely to be important.
And there are questions about relative power dynamics, where with faster takeoff it seems more probable that a smaller initial actor ends up with a lot of power relative to other actors that were initially close to it.
Future Matters: You operationalize AI takeoff as the time between AI systems capable of automating 20% of cognitive tasks, and 100% of cognitive tasks. Did you choose these start and end points because they have particular theoretical and practical significance?
Tom Davidson: So some people have used the operationalization of AGI to superintelligence, which I do think is important and I do actually talk about that a bit. Now one reason why I didn't want to just stick with that is that, in my view, by the time we have full blown AGI that can do all tasks humans can do, things are already going to be very fast and very crazy, and maybe the main period of existential risk has actually already happened. And so it's probably missing most of the action to just focus on the speed of that transition to superintelligence. But if you think, like me, that in the run-up to AGI there will be strategically relevant warning shots, you want to have some metric so that you can more meaningfully talk about that run-up period.
The choice of 20% is pretty arbitrary. I wanted something which was more than AI doing just a few big tricks, like AI that automates driving and a couple of other similar things. I wanted it to be a big enough part of the economy that it involved multiple ‘big wins’, had an unambiguously massive impact on the world, and woke up many big actors to AI’s potential economic and strategic importance. So I wanted to go above 5%.
But I didn't want it to be so late in the game that most of the action had already happened and maybe we're already in the middle of the period of existential risk and things have already gone completely crazy. If I had chosen a startpoint where AI can do 50% or 70% of all economic tasks that would run the risk that, again, it would be too late in the day.
So 20% was me trading off between those two factors. I tried to choose a number that was high enough that AI was really a significant and pretty general phenomenon, but that was not so high that the existential risk period had already started.
I will say that if we're in a quite long timelines world, and we only slowly get to that 20% automation point over like the next 20 or 30 years, then there's a chance that the 20% threshold won’t look like AI being a big deal, because it could just look like a continuation of technological progress as normal, going at about 1% a year. So I do think that there's limitations here and I haven't thought of a good way to unambiguously choose a start point. But because most of my probability mass is in shorter timelines than that, the 20% seems like a good metric.
Future Matters: You draw a distinction between capabilities takeoff and impact takeoff. Could you explain those, how they might come apart and what the reason might be for looking at them separately?
Tom Davidson: Certainly. Capabilities takeoff speed is roughly how quickly do AI capabilities improve as we approach and surpass human level AI. So if the cleverest AI you have is insect intelligence one year, human intelligence next year, and then a month later you've got superintelligence, that's very fast capabilities takeoff. But maybe you haven't used your AI tool in the real world, so it hasn't had any impact on the world during that time: capabilities takeoff just focuses on how clever and capable AI is, aside from whether you actually use it.
Whereas impact takeoff speed is about AI's actual effect on the real world. You could have a really slow capabilities takeoff speed where AI goes up very slowly to human intelligence and beyond, and yet a very fast impact takeoff speed. For example, it might be that no one deploys AI tools, maybe due to government regulations or caution, and then at some point, AI forcibly circumvents your deployment decisions and transforms the whole world in just a few months, once it's already superintelligent. Then you've got a slow capabilities takeoff speed, but a very fast impact takeoff speed. So I think it can be useful to distinguish between those two things.
Future Matters: Taking a step back, you describe the overall approach you take as a ‘compute-centric framework’ for AI forecasting, building on Ajeya Cotra’s Bio Anchors report. Could you characterize what's distinctive about this framework?
Tom Davidson: Yes. I think the framework makes sense if you think we're going to get AGI by scaling up and improving current algorithmic approaches within the deep learning paradigm, getting further improvements to transformers, and things like that—the kind of progress we've seen over the last 10 years. What's distinctive about it is that it makes this big bold simplifying assumption, that the capability of an AI is equal to the amount of compute used to train it, multiplied by the quality of the algorithms used for training. And all kinds of algorithmic progress, the invention of the transformer, various optimizations around it, and any future architectural improvements are rolled into this parameter of the ‘quality of the algorithms used to train’ it. Then, in addition, those algorithms are assumed to improve pretty smoothly, as we put in more effort to designing and testing new algorithms. So we're assuming away the possibility of a radically new approach to AI that doesn't fit in with the recent trends where performance just seems to improve pretty smoothly, as we scale things up and discover new algorithms. Some people think that there's going to be a new algorithmic approach that will lead us to AGI and break the trends of the last 10 years, and that's very much not the tack that I'm taking here.
Future Matters: Could you say more about how this ‘compute centric’ assumption could turn out to be wrong? How does this affect your overall estimates?
Tom Davidson: You could think that there's going to be a new paradigm which massively accelerates progress. My impression is that some people, especially those belonging to the MIRI cluster of thought, think that there could be a new algorithmic approach, which can actually achieve AGI with much less compute than we're already using, or maybe comparable amounts. If that turns out to be true, then I think you can get a faster takeoff, because by the time we transition through that new paradigm, there's already a large hardware overhang, and you can quickly scale up the compute on the new approach once you realize it's working. And if these new approaches have better scaling properties than current approaches, scaling up compute is going to have pretty radical consequences. So to the extent that you put weight on that, I think it pushes towards faster takeoff and is a pretty scary world.
Another thing you could think is just that there's no existing or nearby approach that will get us all the way to AGI, which could push towards a much slower takeoff. You could have current approaches scaling up to only 50% of cognitive tasks, then we need some totally new kind of paradigm to get us all the way, and there could be a delay while we struggle to find out what that is—that could in practice cause slow takeoff. Then it's just hard to say what the dynamics would be, once we discovered that new paradigm: you can imagine takeoff being fast or slow. But either way there would be a pause before we found that new paradigm, which in some ways of measuring it would make takeoff slower. I do have some uncertainty about whether the whole cluster of current approaches will get us there at all, and that pushes me towards slower takeoff.
So uncertainty over this ‘compute centric’ assumption pushes in both directions. It makes a very fast takeoff, and a very slow takeoff, more likely than my framework predicts. But overall, for me, it probably pushes more towards faster takeoff because I find the idea that there's a new type of approach that gets us there faster or that has better scaling properties, or that there’s some other discontinuity that the compute-centric framework ignores, more plausible. So for me that uncertainty overall pushes towards faster takeoff, but certainly will increase the tails in both directions.
Future Matters: Within the compute-centric framework, you try to estimate two quantities. First the capabilities distance that has to be traversed during takeoff, and second the speed at which those capabilities will be acquired. Focusing on the first quantity, what are the main lines of evidence informing your estimates of the effective FLOP gap?
Tom Davidson: This effective FLOP gap is saying how much more effective training compute (= physical compute * quality of training algorithms) we need to train AGI compared to AI that could automate only 20% of the economy. And there's a few different lines of evidence and none of them are very strong evidence, unfortunately. I think there's a huge amount of uncertainty in this parameter. But there are some of the things that push towards thinking that the effective FLOP gap is small.
For example, it seems like brain size has a fairly notable effect on cognitive ability. Human brain sizes differ by ±10% in each direction, and so you can look at measures of cognitive ability and how they vary by brain size. The differences aren't massive, but if you scale that up and imagine that there was a brain that was three or ten times as big, and then extrapolate those differences in cognitive ability, it seems like they'd be plausibly big enough to fully cross the effective FLOP gap. So this suggests that increasing effective training compute by 10-100X could be enough to completely cross the gap, if the scaling of AI intelligence is comparable to this extrapolated scaling of human intelligence with brain size. And there are reasons to think that AI intelligence could scale even more rapidly, because you can be increasing the amount of data that AI systems get as you scale the brain size, which doesn’t happen in humans.
And you get a similar story if you make even more strained analogies to humans and other animals. If you compare human and chimpanzee brain size, the difference isn't that big, but qualitatively there seems to be a big difference in intelligence. And again, this suggests that maybe a couple of orders of magnitude extra effective compute would be enough to make a really big difference if, again, the scaling of AI intelligence with model size is analogous to the scaling of chimp intelligence with brain size.
There's one other argument for thinking the difficulty gap could be pretty narrow, which is a bit of a subtle one. The basic argument is that, historically, the way we've automated, say, 20% or 30% of our workflows is by getting pretty dumb and narrow technologies to do the automation and then rearranging our workflows to compensate. For instance, you used to do all this paperwork and store these stacks of papers, and then with a laptop you're able to use the digital database, to replace the paper, and automate that, which saves you a lot of time. But it took decades for people to actually integrate this automation into their workflows and to change all the other aspects of their processes to get to a point where everyone is using laptops instead of pen and paper for everything. It takes a long time.
If, as some of these other arguments suggest, there could be a fairly quick transition from AI not being able to do 20% of cognitive work to being able to do 100% of it, if that's only going to happen in five years or ten years, then there just won't be time to do the standard thing we do where we rearrange the workflows to allow for partial automation. Maybe you get some AI systems which could automate 20% of your workflow if you had a couple of decades to integrate it—maybe Chat GPT is like this, maybe it could create tens of trillions of dollars in economic value if the whole economy oriented around it, which would take two decades. But in fact, if it's only going to be 10 years before we develop something like AGI, then there's just no time for ChatGPT to do that automation in practice. And so you actually need AI to be pretty advanced before it is able to automate 20% of your workflow without you having to spend a long time rearranging your workflow around it. Therefore, by the time it's able to automate 20% of your work, with minimal efforts on your part, it's actually not too far away from being able to automate everything. And that could give a reason why by the time AI is having really notable, significant impacts on people's workflows, it's actually surprisingly close to the point at which it's able to just almost fully automate their workflows. Those are for me some of the stronger arguments in favor of a small effective FLOP gap.
The main argument in favor of a larger one, for me, is just that there's such a wide variety of tasks in the economy— even in AI R&D (though to a lesser extent)—and they vary along many dimensions, like the time horizon over which they're performed, the amount of social context they require, how repeatable they are, how much it matters if you make a mistake, etc. Those differences mean that AI could be much more suited to automate some of those tasks than others, based on how similar it is to the AI training objective, how expensive it is to fine-tune AI on horizons of that length, and how much training data we have for the task. So it seems like AI would have more competitive advantages at some tasks compared with others, and that could increase the time between it being able to automate the first task and it being able to automate the last tasks.
Future Matters: At the end of all this, you come away with a shorter median estimate for timelines than the bio anchors model, by about ten years, despite sharing several of the key assumptions. What are the main drivers of these shortened timelines in your analysis, relative to Ajeya’s?
Tom Davidson: I think the main thing is the partial automation from pre-AGI systems causing a speed up, especially in AI R&D. The basic story is, the bio anchors model makes its prediction by extrapolating the trend in hardware progress and extrapolating the trend in algorithmic progress. But it's not accounting for the fact that before we get fully transformative AI, we're going to get AI which is pretty useful for doing hardware R&D and designing new chips, pretty useful for writing code for various experiments we want to run automatically, and maybe pretty useful for generating a hundred ideas for new algorithmic approaches and then critiquing those ideas and then winnowing them down to the ten most promising and then showing them to the human. And you would expect that partial automation of R&D to speed up progress on both those dimensions, both the hardware and the algorithms. In which case the bio anchors extrapolation is too conservative. One thing that I'm doing with this analysis is modeling that process whereby we train some not quite transformative but pretty good AIs and they speed up progress on the hardware and the algorithmic R&D. And that just happens more and more as we approach AGI: we get more and more acceleration from that. When I model that as best as I can, the result is that this dynamic shortens timelines by six years or so.
Probably the next biggest factor is, compared to bio anchors, expecting higher spending on the very biggest AI training runs. Once you've got AI that can readily automate 50% of the economy, for example, that's able to generate $25 trillion of value worldwide per year, assuming it was fully deployed, that's just a huge amount of value and it seems like it would be well worth spending a trillion dollars on that training run. And there is even more incentive to do that if you're being competitive with other actors who might want to get there first. And so I'm more willing than bio anchors to think that the spending on training runs could get pretty big because of this kind of dynamic. Some of the gain comes from just more economic growth, meaning there's more money around to invest in this stuff. Some of it is that you get AI to automate fabs so they can make more chips, which allows for faster scale-up. But most of it is just more willingness to spend on training runs as a fraction of world GDP.
Future Matters: Another factor you have pushing towards shorter timelines is this idea that we’ll be "swimming in runtime compute" by the time we’re training human-level AI systems. Could you explain this?
Tom Davidson: The idea there is the following. Suppose that you took the median of the bio anchors where I think AGI took 1e35 FLOP to train, that you've just done that training run and that you're going to use that FLOP you just used to train the system to run copies of the system. How many copies could you run? You're going to be able to run an ungodly number of AIs immediately, just using that training compute.
Future Matters: Is this ratio between the compute required for model training vs model inference relatively stable?
Tom Davidson: Actually, you should expect that fraction to become more extreme as you do bigger training runs. So if you double the size of a model, the compute needed to run the model doubles, but the compute needed to train it by a factor of four. If you think that you need as much compute as the bio anchors median, then you’ll be able to run way more copies with the training compute than you can today Bio anchors median implies you’d need about 1010 times as much compute to train AGI as the biggest public training run to date, which means you’d only need 105 times as much compute to run the model. So if the current ratio is that you can immediately run 10 million systems with your training compute, then in the future with the bio anchors median estimate, you'd be able to run 105 times as many. So instead of 10 million, it would be 1 trillion. And I think if you run the numbers, that's the kind of thing you get. And you might think this is odd: we trained AGI and now we can run 1 trillion of them. You can then maybe think that, in fact, if we wanted to match the human R&D workforce, rather than having 1 trillion AGIs, we can make do with 100 billion somewhat-less-capable-than-AGI systems. Maybe you use the kind of techniques that people are already using today, like chains of thought, or like having a hundred attempted answers to the question and then assessing them and then picking the best. Maybe there are other techniques for running your somewhat dumb AIs for ages and then combining their results in clever ways that can allow you to actually match or exceed the performance of a human worker, even if the individual AI systems are less clever than a human worker. And so the conclusion of this for me is that we could achieve full automation of, for example, R&D before we've trained any one AI system that is individually as smart as a human scientist. And we could just do that by training AIs that are a bit less smart, but being able to run so many, that cumulative output working together exceeds that of all human scientists working together.
Future Matters: Does this consideration generalize across the whole economy? Overall it seems like you end up kind of ‘moving’ the capabilities threshold for AGI a bit earlier, because there is this factor that always gets you a bit further than you think you are?
Tom Davidson: I think so. And it comes down to definitions of AGI. If you were defining AGI as 'one system can on one forward pass match the output of one human brain on one forward pass', then that takes just as much effective training compute to develop. But if your definition for AGI was something like 'AI systems collectively can outperform human brains collectively on any task' or 'AI systems collectively could fully automate this particular sector', then yes, I think that kind of AI is easier to train than I previously thought, maybe quite a bit easier. What's interesting about this is that it's a very strong argument, if you believed something like bio anchors median training requirements, and it's a less strong argument, if you had much smaller training requirements, because then you've got less of this excess runtime compute lying around. So for me, it focuses the probability mass near the lower end of the bio anchors distribution.
Future Matters: At the current margin, if you wanted to improve your estimates of AI takeoffs, would you focus more on (1) trying to better estimate the parameters of the current model, (2) extending the model in various directions, or (3) developing a new model altogether?
Tom Davidson: The one thing I'm most interested in is trying to understand how much algorithmic progress is driven by cognitive work – generating insights and thinking about how the algorithms fit together in the architectures – versus just brute experimentation. This becomes really important in the later stages of takeoff, where if everything is just driven by coming up with better ideas today, then if you extrapolate that, you think that algorithmic progress will become crazy fast as you approach full AI automation as there will be be abundant cognitive work from AI. Whereas if you think it's all about experiments, then progress can't become that crazy fast because AI automation doesn’t immediately increase the amount of physical compute you’ve got access to and it's a bit harder to really rapidly increase that. This gets at this question of time from almost full automation to superintelligence, which I think is something that is a bit under explored in the current report.
Future Matters: Thank you, Tom!
We thank Leonardo Picón and Lyl Macalalad for editorial assistance.
See also our conversation with Long in FM#3; and the 80k podcast episode mentioned below.


[Update from Pablo & Matthew]
As we reached the one-year mark of Future Matters, we thought it a good moment to pause and reflect on the project. While the newsletter has been a rewarding undertaking, we’ve decided to stop publication in order to dedicate our time to new projects. Overall, we feel that launching Future Matters was a worthwhile experiment, which met (but did not surpass) our expectations. Below we provide some statistics and reflections.
Statistics
Aggregated across platforms, we had between 1,000–1,800 impressions per issue. Over time, an increasingly larger share came from Substack, reflecting our growth in subscribers on that platform and the absence of an equivalent subscription service on the EA Forum.
A substantial fraction of our subscriptions came via other EA newsletters:
Reflections
Time investment. Writing the newsletter took considerably more time than we had anticipated. Much of that time involved two activities: (1) actively scanning Twitter lists, EA News, email alerts and other sources for suitable content and (2) reading and summarizing this material. The publication process itself was also pretty time-consuming, but we were able to fully delegate it to a very efficient and reliable assistant. Overall, we each spent at least 2–3 days working on each issue.
AI stuff. Over the course of the year, AI-related content began to dwarf other topics, to the point where Future Matters became mostly AI-focused.
.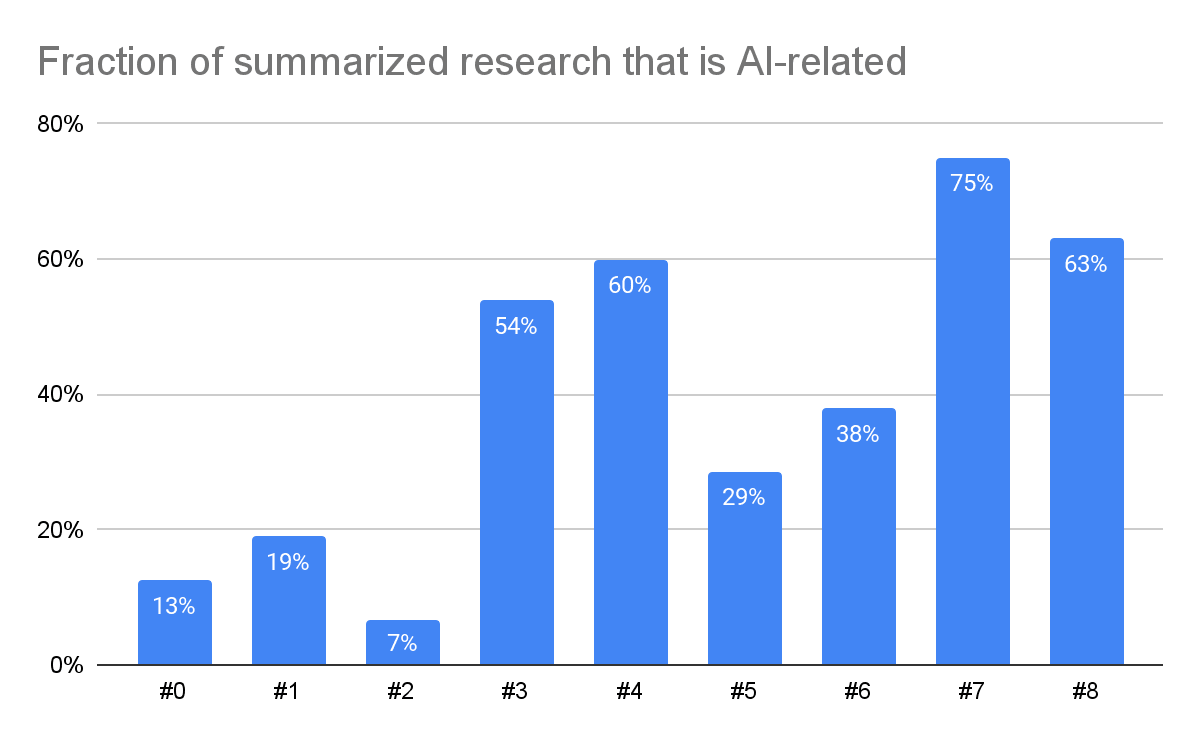
We feel like this shift in priorities was warranted — the recent pace of AI progress has been staggering, as has been the recklessness of certain AI labs. All the more surprising has been the receptiveness of the public and media to taking AI risk concerns seriously (e.g. the momentum behind measures to slow down AI progress).
In this context, it appears to us that the value of a newsletter focused on longtermism and existential risk generally is lower than it was when we started it, relative to a newsletter with a sole focus on AI risk. But we don’t think we’re the best people to run such a newsletter. There are already a number of good active AI newsletters out there, which have their own focuses:
The recent progress in AI has made us more reluctant to continue investing time in this project for a separate reason. Much of the work Future Matters demands, as noted earlier, involves collecting and summarizing content. But these are tasks that GPT-4 can already do tolerably well, and which we expect could be mostly delegated within the next few months.