Summary: The emergence of artificially sentient beings raises moral, political, and legal issues that deserve scrutiny.
Key points:
The AI Forecasting Benchmark Series compares the performance of AI forecasting bots to human forecasters, using a robust and consistent framework to address methodological issues.
The framework includes question weights to mitigate the problem of correlated questions, which can exaggerate the performance of forecasters.
The weighted t-test is used to assess the significance of the results, and is compared to weighted bootstrapping to ensure reliability.
The multiple comparisons problem is avoided by making a single comparison between the top bot median and the Pro median.
The framework is general and can be used consistently to compare the track records of different forecasters.
The approach is expected to reduce statistical noise and provide a more reliable measure of forecasting skill.
The framework can be extended to other parts of Metaculus, such as talent spotting and comparing track records across platforms.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
Comparing Forecasting Track Records for AI Benchmarking and Beyond
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
Adapted from my Substack, Funding Anthropalypse.
Short version: if you want a share of the coming Anthropic and OpenAI windfall - the $37bn+ that could be in play next year - the way in is to become 'legibly excellent', so the evaluators and donors that frontier lab staff already trust point them to yo...
Disclaimer: Although I work on the Groups Team at CEA, I’m writing this in a personal capacity, and this post does not constitute an endorsement by CEA.
Agency - the realisation that you really can just do things.
TL;DR
Biosecurity needs people (of any background) who are agentic and have a high execution velocity and track record....
Thank you to Molly Hickman, Deger Turan, Ryan Beck, Sylvain Chevalier, Luke Sabor, and Leonard Barrett for reading drafts and discussing the ideas presented here.
Special thank you to Nikos Bosse for his valuable feedback and input on statistical methods.
Introduction
On a recent episode of Conversations with Tyler, political forecaster Nate Silver expressed skepticism that AIs will soon replace human forecasters, although there is active interest from many including FutureSearch, Halawi et al, and Schoenegger et al. More recently, the Center for AI Safety responded to Silver’s skepticism with Superhuman Automated Forecasting, a post announcing the creation of a “superhuman AI forecasting bot” that “performs better than experienced human forecasters.” However their methodology has been highly contested.
We believe Silver’s skepticism is still warranted: AI forecasting does not match — let alone surpass — the performance of experienced forecasters. Metaculus created the AI Benchmarking Series to examine this question, and we've now developed an epistemically rigorous approach to address many of the methodological issues highlighted by others.
Challenges in Forecasting Evaluation
Many bot forecasting studies to date have used historical forecasting questions to try to back-test performance, but their validity has been called into question by potential data leakage issues. In contrast, our analysis uses predictions from our AI Forecasting Benchmark Series, which compares community forecasters, pro forecasters, and AI forecasting bots, all on real-world “live” questions for which outcomes were unknown as of the series launch. This avoids any data leakage risks.
Our approach addresses another common AI benchmarking concern: that models may be trained to do well on a test that never changes, but then fail when they take a test that they have never seen. We are running quarterly AI forecasting tournaments through mid-2025, each time using new questions including fresh topics, thereby avoiding the possibility of training a bot on a repeating set of questions.
Methodology
We pose identical questions to bots and Pro forecasters on topics similar to those found on Metaculus with an emphasis on questions that aren’t found elsewhere, in order to reward independent reasoning. We were careful to ensure that forecasts from both bots and humans remained hidden while forecasting was active, so that neither could piggy-back on the other.
All forecasting tournaments, whether they involve bots or not, face another problem: Many forecasting questions are correlated and so outcomes are not independent — e.g., questions on multiple countries’ infection rates are likely influenced by the same factors. This has been an unsolved and thorny problem in assessing forecasting abilities. Here we propose adding question weights as a way to help correct for correlation.
We use a weighted t-test to assess whether the difference between bot and human performance is statistically significant. We use weighted bootstrapping to confirm the robustness of the weighted t-test result. To avoid the multiple comparisons problem, we propose a methodology to select a top bot team that will be compared directly to the Pro human team once all of the questions have been resolved on October 7.
In this post we use the AI Benchmarking results to date to show how our methodology works, and we share some preliminary observations on the bot performance so far — perhaps the biggest being that the bots have performed better than we expected — although, again, we must wait until all questions are resolved before concluding more.
Summary of the AI Forecasting Benchmark Series
On July 8, 2024 we launched the Q3 AI Benchmarking tournament, featuring over 300 binary questions, each resolving by early October. Every question remains open for 24 hours, and only the final forecast counts for scoring — an approach we call “spot forecasting”. The tournament uses standard tournament scoring to allocate $30,000 in prizes.
The human benchmark is set by both our community and a group of 10 Metaculus Pro Forecasters, who are forecasting some of the same questions, but in different locations. For the bot tournament, we convert continuous questions into a binary format: Instead of asking “What will US GDP be?” we ask questions like “Will US GDP be >2%?” and “Will US GDP be >4%?” We want to assess the bots’ reasoning on forecasting questions, not their ability to use the rather complex Metaculus API for continuous questions. (Although, once the simplified API is launched in Q4, we plan to begin posing continuous questions to the bots.)
Our goals include:
Having a variety of question topics that are similar to what is found on Metaculus.
Having enough questions to provide a statistically significant and stable benchmark.
Asking questions where it is non-trivial to look up an accurate probability on Metaculus or on other prediction sites. A bot that simply copies the community prediction or a prediction site would do extremely well, while not being able to reason. This is not the capability we aim to assess.
All questions in the Quarterly Cup are asked in the bot tournament before the community prediction is revealed. This prevents bots from copying the community prediction. The Pros also forecast these questions in a private project, similarly before the community prediction is available. For benchmarking, we only consider the standing forecasts at the moment that the community prediction is made public. Humans typically had 1 to 3 days to make their forecasts.
We are paying 10 Metaculus Pro Forecasters to forecast on 100 questions total, all of which are also part of the Bot tournament. By compensating Pros, we aim to ensure that enough human attention is focused on the questions, producing the best possible human benchmark.
To increase the statistical significance in ranking bot performance, we’ve posed over 300 questions in the bot tournament. These questions are a combination of (a) new Metaculus questions that resolve within Q3 but aren’t part of the Quarterly Cup, (b) existing Metaculus questions modified to resolve in Q3, and (c) custom questions created specifically for the bots.
Once all the forecasting questions are resolved, we want to address several key questions, including:
How does the accuracy of the best bots compare to the human aggregates?
How confident should we be in the scoring comparisons?
How do we account for correlations between questions?
The rest of this post will focus on these questions. While we will look at these questions through the lens of AI Benchmarking, a key motivation of this piece is to provide a robust, consistent framework that can potentially be used more widely on Metaculus, including when evaluating our own track record relative to other platforms.
Comparing Two Forecasters
Analyzing the track records of human forecasters and other prediction platforms is a challenge with no standard solution, and it has been discussed by many others [1],[2],[3],[4].
In an ideal world, any forecasting platform comparing track records should pre-commit to a consistent, robust framework for scoring and analysis before any data are collected. Our aspiration is to adhere to this standard, and this piece represents an important step in that direction. Pre-commitment eliminates the potential for cherry-picking, since once the results are known it is usually possible to find a scoring methodology that supports the outcome you prefer. Further, this framework must be general enough to be widely applicable across a variety of projects.
A key challenge is accounting for correlations among question outcomes. Tournaments are often focused on a particular topic, like AI progress, influenza, or nuclear weapons. By design, the questions in these tournaments are highly correlated. Treating these questions as independent risks overstating the statistical significance of any results.
Finally, the scoring framework should be as transparent and intuitive as possible.
Correlated Questions
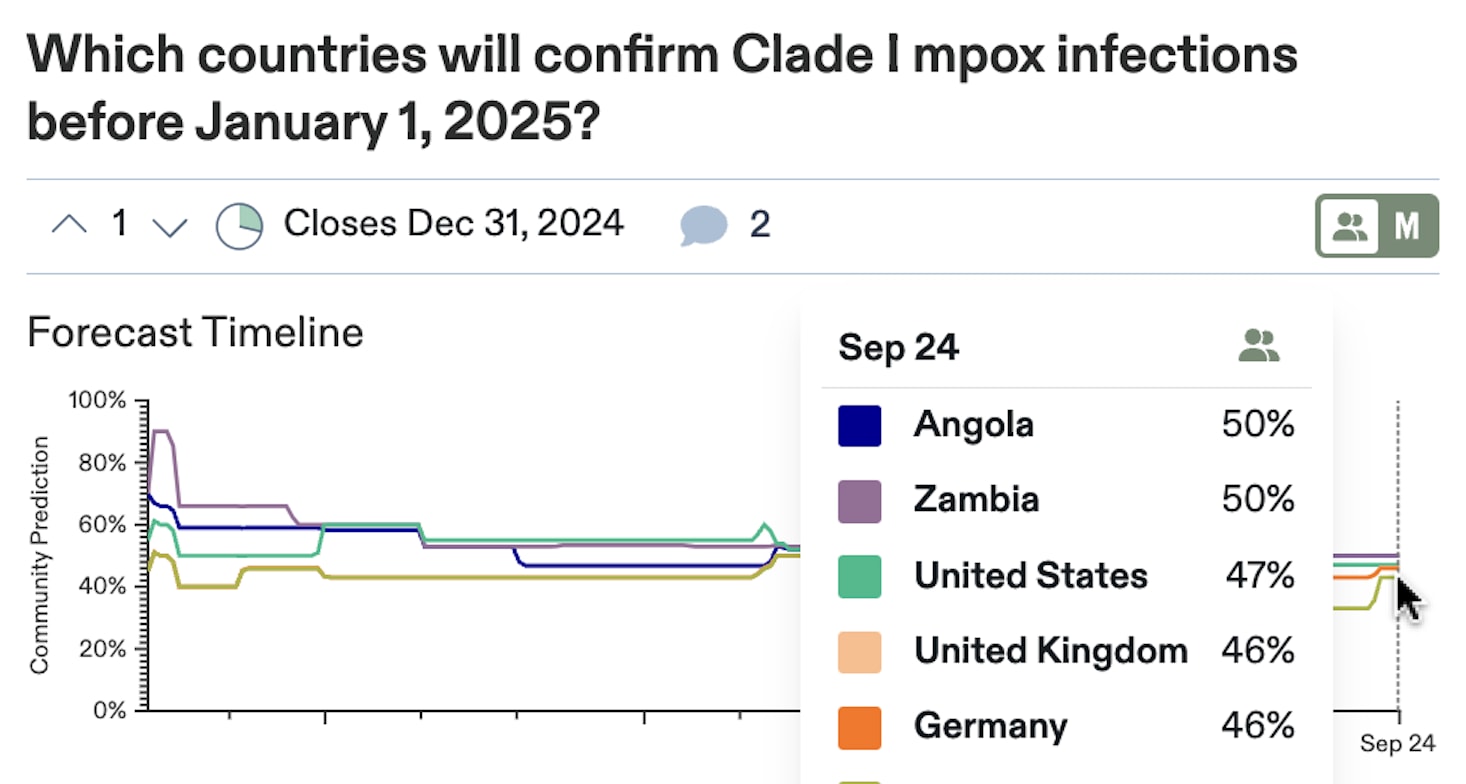
Correlated questions tell us less about forecasting skill than independent questions. For instance, on Metaculus we ask: “Which countries will confirm Clade I mpox infections before January 1, 2025?” for 15 different countries.
We hope that each of these questions is useful to people interested in tracking the global spread of mpox. We also expect the outcomes to be highly correlated: Either mpox will spread, and many countries will confirm infections, or it will remain contained, and most countries will report no infections.
Because the mpox questions are correlated, they contain less information to distinguish forecasting skill than if they were 15 completely independent questions. To illustrate, imagine that all mpox questions were perfectly correlated. If one resolved “Yes,” all would, and vice versa. In this extreme case, the entire question group provides the same amount of information on forecasting skill as would a single question asking “Will any new country confirm Clade 1 mpox infections?”
To distinguish forecasting skill using the fewest questions, the questions should ideally be independent. So, how should we treat the mpox questions when comparing forecasting track records? Should they count as 15 questions or one? The truth lies somewhere in the middle. The questions are positively correlated and contain less information than 15 independent questions, but there is likely enough country-by-country variability that forecasting each still requires skill. That is, the question set provides more information than just a single question.
We propose assigning weights to questions. This offers a simple way to adjust for correlations when comparing track records.
Specifically, we propose giving independent questions a weight of 1 and correlated questions weights of less than 1. For instance, if we ask 100 identical questions, they should together count as one question for both scoring and assigning statistical significance, because they contain the same amount of information as one question. By assigning a weight of 1/100 to each of the duplicates, and then calculating weighted scores, we ensure that 100 duplicates count as much as a single independent question.
In many cases, the degree of correlation is subjective, and reasonable people might disagree on how to assign weights. While we don’t see a fully objective way to accomplish this, we believe assigning weights is a significant improvement over treating correlated questions as independent, which is the most common practice.
To analyze the AI Forecasting Benchmark Series data, we propose some reasonable formulas for assigning weights. This is worth careful consideration, as for the Q4 tournament we plan to assign question weights when questions launch so weights will be included in the leaderboards that determine prizes.
Repeated Questions
By default, the first time a question is asked, it is assigned a weight of 1. Sometimes, it is interesting to repeat a question, especially if the world has significantly changed. We propose assigning a weight of ½ when a question is repeated, ⅓ when repeated a third time, ¼ for the fourth time, and so on. A repeated question is clearly correlated with the original, so it deserves less weight.
Moreover, for the AI Forecasting Benchmark Series, the predictions of other bots and humans are not generally available when a question is opened, but are available for repeated instances. Since forecasters can copy the forecasts of others on repeated questions, there is potentially less skill required to perform well. Because we are trying to identify skill, repeated questions deserve less weight.
Logically Related Question Groups
In the AI benchmarking tournament we ask groups of binary questions that are logically related, e.g. “Will X be greater than 0?”, “Will X be greater than 1?”, or “Will X be greater than 2?” Since the outcomes within such a question group are correlated, each question’s weight should be less than 1, but the group overall should be weighted more than 1.
For a group of N logically related questions, we assign weight as follows:
Weight=log2(N+1)/(N+1) For a group of three questions, the weight of each individual question is (3+1) /(3+1) = 0.5. So, the entire group of 3 questions has a combined weight of 3 x 0.5 = 1.5. For a group of two similar questions, the individual question weights are 0.53, so the combined weight is just over 1. This seems reasonable for small N.
For a large group — for example, 64 binary questions each asking if a particular team will win the March Madness college basketball championship — the total weight of the group would be roughly six. This is a big improvement over counting the group as equivalent to 64 independent questions. For the AI benchmarking series, the largest question group consists of six related questions, leading to a combined group weight of 2.4.
Similar Questions
Some questions aren’t repeated or strictly logically related, but are similar. For instance, we asked about the net favorability ratings of both Trump and Harris on September 1 and October 1. While not logically related or repeated, they are clearly similar. In cases like this, we used our best judgment on whether to assign weights of 1 or less. For the net favorability questions, we assigned weights less than 1.
In our analysis, roughly 40% of all questions have weight 1 and the remaining 60% have weights between 0.4 and 0.6.
Question Weighting in Practice
When there are large numbers of questions, we don’t expect weighting to have much impact. However, typical tournaments feature 50 questions, and many are correlated in some way. Traditionally tournaments treat all questions as equally informative of forecasting skill. We think adding weights reduces noise and helps us better discriminate between more and less skilled forecasters.
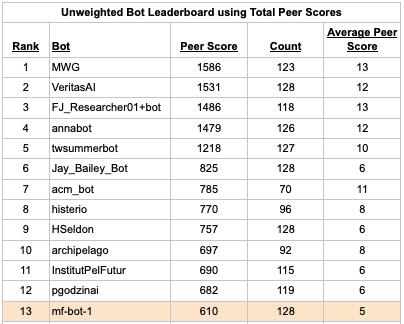
Let’s look at a portion of the bot leaderboard as of September 22, 2024, which is based on Peer scoring with spot forecasts. Below is a leaderboard with all weights set to 1, which mirrors the current leaderboard on the site. The Count column shows the number of scored questions for each bot. The final column is the average score for each bot. (We exclude questions that resolved early. Learn more at the end of this post.)
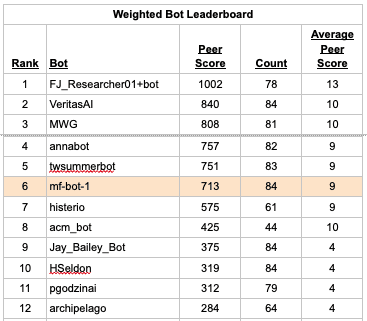
Below we recalculate the leaderboard (full table here) using question weights to calculate weighted scores. Here, the Count column shows the sum of the question weights for scored questions.
We’ve highlighted one bot above to help illustrate the impact of question weighting.
mf-bot-1 is a Metaculus bot that pulls news from Perplexity and uses a single shot prompt with GPT4o. (Details here.) With unweighted questions it ranks 13th among bots. With weighted questions it rises to 6th. To illustrate why its ranking changed, we note that it had significant negative scores < -25 for 3 questions about geomagnetic storms (here, here, here). The weighted leaderboard only counts these 3 correlated questions with a total weight of 1.5, which improves mf-bot-1’s score.
mf-bot-3 uses the same single shot prompt, but powered by Claude. Its average score is -5 on the unweighted leaderboard, but only -2 on the weighted leaderboard.
RyansAGI is written by Metaculus's Ryan Beck. He graciously shared the code here for others to use as a template. It drops from 18th on the unweighted leaderboard to 36th on the weighted leaderboard, which is an especially large move considering that it has forecast on over 100 questions.
With enough questions, we would expect the differences between the unweighted and weighted leaderboards to disappear. However, we believe that the significant changes highlighted above show that there is still considerable statistical noise even with 100+ unweighted scored questions. We want to tamp down unnecessary noise as much as possible to best reward forecasting skill. We believe using question weights helps by reducing the swings associated with correlated question outcomes.
We also believe that using question weights provides more reliable statistical significance metrics, as we will explain below.
Comparing Bots to Humans
For AI Benchmarking, our primary goal is to compare how the best individual bots do against the human aggregates. To analyze this, we favor the most direct method of comparison: Only use questions that both an individual bot and the humans forecast on.
Our approach is to calculate Peer scores as if there were a tournament with only two participants: an individual bot and the human aggregate. We refer to this as the Head-to-head score. This can be used generally to compare any two forecasters. Importantly, the Head-to-head score does not put bots who may have joined late at a disadvantage. If a super-human bot joins a month late, we want to be able to identify it!
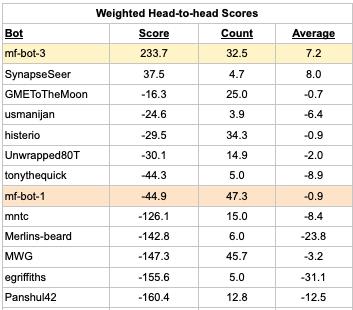
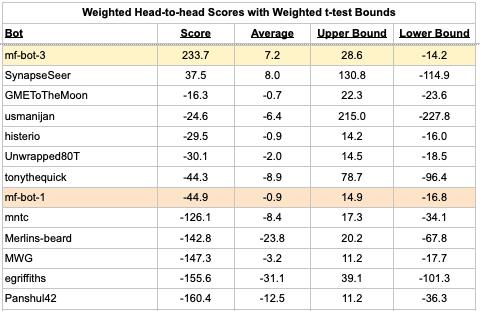
The table below shows the total Head-to-head weighted scores, weighted question count, and average score for each bot. (Full table here.)
A positive score above indicates that the bot was more accurate than the Pro median on questions they both forecast. A negative score means the opposite. While the large majority of bots have negative scores, there are two bots with positive scores.
How do we explain why mf-bot-3 is 40th on the Bot leaderboard, but 1st on the Head-to-head leaderboard? One reason is this question about “Rockstar” winning a music award, where the bot median was 62% but mf-bot-3 forecast 1%. The question resolved Yes resulting in a -383 Peer score for mf-bot-3. However, the Pros did not forecast on this question, so it is not included in the Head-to-head leaderboard calculation. This question illustrates how the rankings can be so different. More generally, we attribute the differences in rankings to noise.
When the competition is complete, we will have around 100 weighted questions for benchmarking bots against Pros. Even with 100 weighted questions we expect there to be considerable noise. This naturally leads to the questions: How should we think about the statistical significance of the leaderboards? How confident are we that mf-bot-3 is better than the Pros?
Assessing Statistical Significance
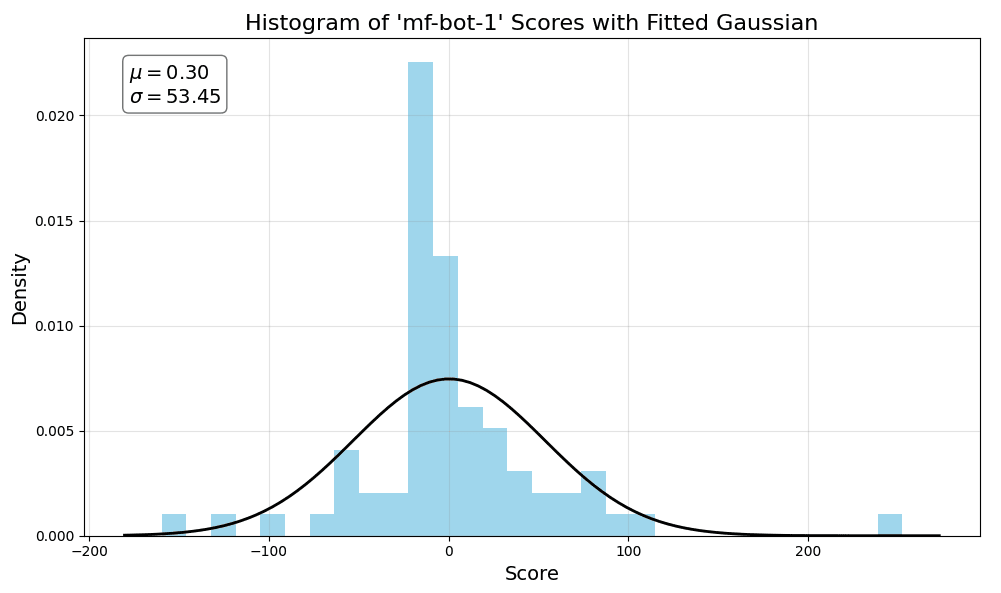
A common statistical significance test is the t-test with a 95% confidence interval. The t-test makes a few key assumptions about the underlying data, including that the data is normally distributed, each observation is independent, and there are no significant outliers. While the Head-to-head scores are reasonably symmetric, they usually have fat tails and some outliers.
We find it useful to visualize the data before diving in. The histogram below shows mf-bot-1’s Head-to-head scores, as well as a fitted Gaussian. We observe that it is quite symmetrical, but has fat tails and a few outliers.
Normally, t-tests assign a weight of 1 to all samples. Since we have question weights, we use the less common weighted version of the t-test.
In the scientific literature it is common to start with a null hypothesis and then use a two-sided t-test with 95% confidence to assess significance. In our case, the null hypothesis is that the bots and humans are equally skilled, which corresponds to a Head-to-head score of zero. Then, a t-test produces a lower and upper bound, such that the true mean is between the bounds 95% of the time assuming the t-test assumptions hold.
We followed the usual t-test methodology, but with weighted values.
For the mathematically inclined: We calculate the weighted standard error as the weighted standard deviation divided by the square root of the weighted number of questions. We calculated a weighted t statistic = weighted average score / weighted standard error. We then used a t table for a 2-tailed test with 95% confidence interval to look up a critical t value. Then we calculate a lower and upper bound for the average_weighted_score. Upper/Lower bound = weighted_average +/- standard_error * critical_t_value. See the calculations here.
The table below summarizes some key results using weighted scoring. (Full table.)
We observe that none of the lower bounds are above zero, so the weighted t-test says that none of the bots performed better than the Pro aggregate with statistical significance. On the other hand, there are eight bots for which the entire confidence interval is below zero, indicating that the human forecast outperformed those eight bot forecasts according to a conventional 5% significance threshold (although ignoring multiple comparisons, which we’ll get to shortly).
More math: It is worth noting that when calculating the weighted standard error we divide by the square root of the weighted number of questions. Since the weighted question count is lower, this results in a higher standard error and therefore wider bounds compared to setting all weights to 1. Also, when looking up the critical t-value in the t table, we use degrees of freedom = weighted question count -1 which slightly increases the bounds.
If a bot forecast every question to date, then it has 47 weighted Head-to-head questions total. This will increase to around 100 when the tournament concludes, allowing for stronger conclusions. The wide confidence intervals in this analysis highlight that there is far more statistical noise in forecasting tournaments than most people (ourselves included) would intuitively think.
Our initial worry with using a t-test was that it would draw conclusions that are overly confident. While the t-test does not assign much significance to the results to date, our goal is a framework that is robust and trustworthy so that when it indicates a result is significant, we feel comfortable standing by that conclusion.
While the Head-to-head and Peer score distributions are fairly symmetrical, the tails are clearly far fatter than a Gaussian distribution. It felt prudent to double check the weighted t-test with another statistical method — here, bootstrapping —as it does not assume the data is Gaussian.
Weighted Bootstrapping
Bootstrapping works by taking a dataset with N observations, then generating many new synthetic datasets by resampling with replacement N times from the original N observations. Then, one can assess statistical properties of the generated synthetic datasets.
In our case, we can take a set of Head-to-head question scores for a particular bot and by resampling with replacement many times, we can calculate the percentage of the time that the total Head-to-head score is positive. If the total score is positive more than 97.5% of the time, then bootstrapping indicates that the bot is more accurate than the Pro median. And, if the bot wins less than 2.5% of the time, then it indicates the Pro median is more accurate.
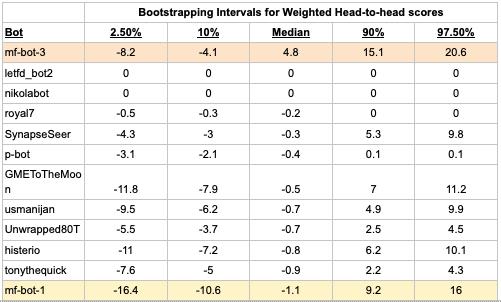
More math: The normal bootstrapping method assumes that every observation is equally weighted. We use a weighted bootstrapping method. Specifically, we set the probability of a question being resampled proportional to the question weight. We resample a weighted question count number of times. We calculate the total score by adding all of the sampled scores together, all with equal weights.
The table below shows the results of weighted bootstrapping using Head-to-head scores. Looking at mf-bot-3, the table shows that 95% of the time the resampled average Head-to-head score was in the interval [-8.2, 20.6]. (Full table.)
Our first observation is that the bootstrapping results are similar to the t-test results. This is comforting, especially since they are quite different techniques.
A key concern was that the t-test might be overly aggressive in assigning significance. We expected bootstrapping to be more conservative; however, we found the opposite. The 95% confidence interval for bootstrapping is generally narrower than the t-test. For example, the 95% confidence interval for mf-bot-3 is [-14, 28] using the t-test and [-8, 20] using bootstrapping. Bootstrapping assigned significance to 9 bots as being worse than the Pro median, compared to 8 bots using t-tests.
Furthermore, bootstrapping breaks down for small sample sizes < 10. If a bot has only 5 scores but they are all positive, then bootstrapping will always result in a positive score. Or, consider the 95% interval for SynapseSeer who only has 5 weighted questions total. The t-test gives a 95% confidence interval of [-115, 130], while bootstrapping assigns a [-4, 10] interval. The t-test is much more conservative for small sample sizes, and modestly more conservative for larger sample sizes.
Overall, the agreement between weighted t-test and weighted bootstrapping for large sample sizes increases our confidence. Since the weighted t-test is empirically slightly more conservative with large samples (30+) and is dramatically more conservative with small samples (<10), we plan to use it as our standard statistical method.
Multiple Comparisons Problem
So, can we just wait for the Q3 results to roll in and then check the Head-to-head results to infer forecasting skill? Unfortunately, by attempting to make multiple inferences from the same data we would be at risk of falling prey to the multiple comparisons problem.
To illustrate, imagine you have a coin and you want to test whether it is fair or has a tendency to land heads. You decide to throw it 5 times and if it lands on heads every time you decide it must be biased. This works well as a test for a single coin. Say instead you decided to test 100 coins and repeat the same experiment with each of them. Let's assume that all of them are fair. Just by chance you would eventually end up with a relevant number of coins that land heads 5 times. (In expectation, it would be three of the hundred coins). Inferring that these coins are biased would be a mistake.
In general, the greater the number of statistical inferences that are drawn from the same data, the more unreliable those inferences become if t-tests are applied without properly adjusting for the multiple comparisons. If we had many thousands of low-skill bots competing, then we would statistically expect some of those bots to have positive Head-to-head scores with 95% confidence, even if they were all poor forecasters.
We could attempt to correct for the multiple comparisons problem by employing more sophisticated statistical techniques. Instead, we choose to take a simpler approach and make a single comparison.
The AI vs Human Benchmark Comparison
To avoid the multiple comparison problem, we plan to select a team of the top bots using questions that only the bots answered. Then, we will take the median of the top bot forecasts and compare it to the Pro human median. We’ll use the weighted Head-to-head score for comparison with significance determined by the weighted t-test.
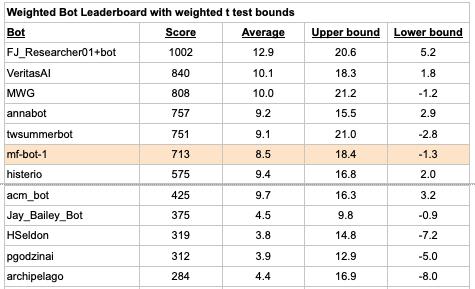
To choose our top bot team, we’ll first select the top 10 bots based on their t statistic / critical t value using only questions for which there is no Pro benchmark. Then, we’ll select a team from those 10 bots that results in the most accurate median forecast, again using only the bot questions. The team might be as large as 10 bots, but could be smaller if we empirically find that the bot skill drops off so much that the median forecast gets worse. (Note, the leaderboard below includes all questions, but we’ll use bot-only questions when selecting the top bots once all questions are resolved. Full leaderboard.)
We see the weighted Head-to-head Peer score between the top bot median and the Pro median as the best metric for assessing how state-of-the-art bots compare to humans. We will use the weighted t-test to assess statistical significance. We will plan to track this metric over the coming quarters to watch its evolution.
Without knowing the answer yet ourselves, we expect the Pros to beat the Bots this quarter. But, we’re unsure if the result will have 95% significance. We also expect the skill gap to narrow over time. We hope you are as excited as we are to see the results!
Early Closer Problem
In the analysis above, we excluded questions that resolved early. Why did we do this?
We’d like our leaderboards at any point in time to reflect forecasting skill. However, questions that resolve early necessarily resolve positively, i.e. they’re systematically skewed to benefit forecasters who are overly optimistic.
Imagine we have a 10 year tournament with 100 questions, each of the form: Will X occur before 2034? Let’s assume that when each question opens it has a 20% chance of resolving Yes that is uniform over the question lifetime. A perfect forecaster will forecast 20% on all questions, while an overly optimistic forecaster might forecast 50%. What would we expect the leaderboard to look like after year 1? On average we expect 2 questions to resolve Yes. The overly optimistic forecaster will get a better score than the perfect forecaster and find themselves on top of the leaderboard. This will continue in year 2.
What is happening? The question format is such that questions can only resolve No at the end of the 10 years, and if they resolve early they must resolve Yes. By including early resolving questions, the leaderboard in years 1 through 9 only shows questions that resolve Yes, thereby favoring the optimistic forecaster. Once the tournament has concluded in year 10, then the No resolutions can finally be included and the perfect forecaster will rise to the top.
One way to fix this problem is to only include questions on a leaderboard once they have reached their scheduled resolution date. This eliminates the skew caused by early closing questions, and this is what we have done above.
It is worth noting that the current leaderboard shown on Metaculus includes early resolving questions. We plan to investigate changing this at some point in the future.
Discussion of AI Benchmarking
What are the biggest takeaways from the AI Benchmarking tournament so far?
First, the bots are performing better than we expected relative to the Pros. We didn’t expect a bot to have positive Head-to-head Peer scores after more than 30 questions.
Second, our analysis shows that more questions are needed to draw significant conclusions than most people’s intuition tells them.
Third, we are surprised by the significant variation in rankings between the Bot leaderboard (using Peer scores) and the Head-to-head leaderboard (comparing each bot to the Pro median). Again, we attribute this to statistical noise — which is greater than our intuition would have suggested.
Fourth, looking at the bot forecasts on logically related questions it is clear that even the top bots are significantly self-inconsistent. We plan to write up an analysis of this soon.
Fifth, we’re surprised by how well the single shot Metaculus bots are doing — both compared to other more sophisticated bots and compared to the Pro median, although this could just be noise. It will be interesting to see if good single-shot prompts can compete, or even exceed, the performance of multi-agent bots when all questions have been resolved.
Sixth, while we expected the Metaculus bot powered by GPT4o (mf-bot-1) to do better than the Metaculus bot powered by GPT3.5 (mf-bot-2), we did not expect as big of a difference. We’re interested to see if o1-preview shows an equally large improvement over GPT4o in our Q4 tournament!
Seventh, we observe that pulling inaccurate information is a big source of forecasting errors for the Metaculus bots, as opposed to their reasoning ability. For instance, mf-bot-1 forecast a 99% chance that Walz will cease to be the VP candidate by October 1! mf-bot-1 didn’t know from its new sources that Walz is already the VP candidate, so it completely misinterpreted the question. Getting bots accurate news appears to be the easiest way to improve their forecasting accuracy.
Eighth, the Metaculus bots do very well 90%+ of the time, but make catastrophically bad forecasts a small percent of the time.
Concluding Thoughts
A goal of ours was to develop a system for comparing two forecasters’ track records that is general, robust, and can be used consistently. We wanted a framework that can deal with correlated questions and provide a measure of significance. To summarize the key pieces of the framework that we presented above:
Question weights provide a mechanism to mitigate the problem of correlated questions.
We compare forecasters A & B based only on questions that both answered. We calculate the Peer scores each would have received if they were the only 2 forecasters in a tournament and call this the Head-to-head score.
We propose a weighted t-test to assess significance.
We compared the weighted t-test to weighted bootstrapping and found that the t-test was more robust and conservative.
We don’t include early closers on the leaderboard until their scheduled resolution times.
To avoid the multiple comparisons problem when analyzing AI Benchmarking results, we proposed a single comparison to track the median of the top bots compared to the Pros. We plan to track this metric over the coming quarters.
We remain humble that our proposed framework will break down for edge cases. Our method does not capture the full covariance between questions. We have not addressed whether the best forecasters on 1 year questions should be trusted on 100 year questions. However, we believe our methodology is a significant improvement in epistemic rigor over what has been done to date, especially for benchmarking AI forecasting capabilities.
We conclude by offering some thoughts on how we may extend the above framework to other parts of Metaculus.
Talent Spotting
A key goal of the Bridgewater competition was to identify talented undergraduates for Bridgewater’s recruitment pipeline. Looking at the leaderboard at the conclusion of the tournament, Bridgewater asked some terrific questions: How much would you expect an individual’s ranking to change if we re-ran the tournament? How significant is the difference between finishing 5th and 10th? We didn’t have a ready answer at the time.
By reporting a confidence interval from a weighted t-test on Metaculus leaderboards in the future, everyone will be able to get a better sense of how significant the results were. We don’t want to indicate that a top performer in a tournament is conclusively an excellent forecaster, unless there is adequate statistical significance.
Question Weights
We think it is possible to add question weights to some Metaculus questions in order to reduce the noise in track records.
Metaculus Vs Other Platforms
We think the proposed framework can be directly used when comparing Metaculus to other platforms. We might someday have a track record page that uses the above framework to show how Metaculus compares head-to-head with other platforms, as well as a measure of significance.
Concretely, when thinking about comparing election models it is clear that the outcomes of different states are highly correlated. We hope that question weights might help to adjust for this correlation, and flow through to the statistical analysis of how confident we can be that one model is better than another.
We expect there is a lot more noise than most people expect and that a thoughtful analysis will indicate there is far from enough data to say which election models are better.
Seeking Feedback
We expect that others will have improvements or suggestions to offer. We would highly value hearing your thoughts in the comment section (and especially in the comment section of the original post on Metaculus)!

Summary: The emergence of artificially sentient beings raises moral, political, and legal issues that deserve scrutiny.
Key points:
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.