This is the time for EAs to radically rethink our whole AI safety strategy. Working on 'technical AI alignment' is not going to work in the time that we probably have, given the speed of AI capabilities development.
I think it's still good for some people to work on alignment research. The future is hard to predict, and we can't totally rule out a string of technical breakthroughs, and the overall option space looks gloomy enough (at least from my perspective) that we should be pursuing multiple options in parallel rather than putting all our eggs in one basket.
That said, I think "alignment research pans out to the level of letting us safely wield vastly superhuman AGI in the near future" is sufficiently unlikely that we definitely shouldn't be predicating our plans on that working out. AFAICT Leopold's proposal is that we just lay down and die in the worlds where we can't align vastly superhuman AI, in exchange for doing better in the worlds where we can align it; that seems extremely reckless and backwards to me, throwing away higher-probability success worlds in exchange for more niche and unlikely success worlds.
I also think alignment researchers thus far, as a group, have mainly had the effect of shortening timelines. I want alignment research to happen, but not at the cost of reducing our hope in the worlds where alignment doesn't pan out, and thus far a lot of work labeled "alignment" has either seemed to accelerate the field toward AGI, or seemed to provide justification/cover for increasing the heat and competitiveness of the field, which seems pretty counterproductive to me.
Convincing all stakeholders of high p(doom) such that they take decisive, coordinated action is wildly improbable ("step 1: get everyone to agree with me" is the foundation of many terrible plans and almost no good ones)
Still improbable, but less wildly, is the idea that we can steer institutions towards sensitivity to risk on the margin and that those institutions can position themselves to solve the technical and other challenges ahead
Maybe the key insight is that both strategies walk on a knife's edge. While Moore's law, algorithmic improvement, and chip design hum along at some level, even a little breakdown in international willpower to enforce a pause/stop can rapidly convert to catastrophe. Spending a lot of effort to get that consensus also has high opportunity cost in terms of steering institutions in the world where the effort fails (and it is very likely to fail).
Leopold's view more straightforwardly makes a high risk bet on leaders learning things they don't know now and developing tools they can't foresee now by a critical moment that's fast approaching.
I think it's accordingly unsurprising that confidence in background doom is the crux here. In Leopold's 5% world, the first plan seems like the bigger risk. In MIRI's 90% world, the second does. Unfortunately, the error bars are wide here and the arguments on both sides seem so inextricably priors-driven that I don't have much hope they'll narrow any time soon.
Three high-level reasons I think Leopold's plan looks a lot less workable:
It requires major scientific breakthroughs to occur on a very short time horizon, including unknown breakthroughs that will manifest to solve problems we don't understand or know about today.
These breakthroughs need to come in a field that has not been particularly productive or fast in the past. (Indeed, forecasters have been surprised by how slowly safety/robustness/etc. have progressed in recent years, and simultaneously surprised by the breakneck speed of capabilities.)
It requires extremely precise and correct behavior by a giant government bureaucracy that includes many staff who won't be the best and brightest in the field -- inevitably, many technical and nontechnical people in the bureaucracy will have wrong beliefs about AGI and about alignment.
The "extremely precise and correct behavior" part means that we're effectively hoping to be handed an excellent bureaucracy that will rapidly and competently solve a thirty-digit combination lock requiring the invention of multiple new fields and the solving of a variety of thorny and poorly-understood technical problems -- all in a handful of years.
(It also requires that various empirical predictions all pan out. E.g., Leopold could do everything right and get the USG fully on board and get the USG doing literally everything right by his lights -- and then the plan ends up destroying the world rather than saving it because it turned out ASI was a lot more compute-efficient to train than he expected, resulting in the USG being unable to monopolize the tech and unable to achieve a sufficiently long lead time.)
My proposal doesn't require qualitatively that kind of success. It requires governments to coordinate on banning things. Plausibly, it requires governments to overreact to a weird, scary, and publicly controversial new tech to some degree, since it's unlikely that governments will exactly hit the target we want. This is not a particularly weird ask; governments ban things (and coordinate or copy-paste each other's laws) all the time, in far less dangerous and fraught areas than AGI. This is "trying to get the international order to lean hard in a particular direction on a yes-or-no question where there's already a lot of energy behind choosing 'no'", not "solving a long list of hard science and engineering problems in a matter of months and weeks and getting a bureaucracy to output the correct long string of digits to nail down all the correct technical solutions and all the correct processes to find those solutions".
The CCP's current appetite for AGI seems remarkably small, and I expect them to be more worried that an AGI race would leave them in the dust (and/or put their regime at risk, and/or put their lives at risk), than excited about the opportunity such a race provides. Governments around the world currently, to the best of my knowledge, are nowhere near the cutting edge in ML. From my perspective, Leopold is imagining a future problem into being ("all of this changes") and then trying to find a galaxy-brained incredibly complex and assumption-laden way to wriggle out of this imagined future dilemma, when the far easier and less risky path would be to not have the world powers race in the first place, have them recognize that this technology is lethally dangerous (something the USG chain of command, at least, would need to fully internalize on Leopold's plan too), and have them block private labs from sending us over the precipice (again, something Leopold assumes will happen) while not choosing to take on the risk of destroying themselves (nor permitting other world powers to unilaterally impose that risk).
The CCP's current appetite for AGI seems remarkably small, and I expect them to be more worried that an AGI race would leave them in the dust (and/or put their regime at risk, and/or put their lives at risk), than excited about the opportunity such a race provides.
Yeah, I also tried to point this out to Leopold on LW and via Twitter DM, but no response so far. It confuses me that he seems to completely ignore the possibility of international coordination, as that's the obvious alternative to what he proposes, that others must have also brought up to him in private discussions.
Some hope for some sort of international treaty on safety. This seems fanciful to me. The world where both the CCP and USG are AGI-pilled enough to take safety risk seriously is also the world in which both realize that international economic and military predominance is at stake, that being months behind on AGI could mean being permanently left behind. If the race is tight, any arms control equilibrium, at least in the early phase around superintelligence, seems extremely unstable. In short, ”breakout” is too easy: the incentive (and the fear that others will act on this incentive) to race ahead with an intelligence explosion, to reach superintelligence and the decisive advantage, too great.
At the very least, the odds we get something good-enough here seem slim. (How have those climate treaties gone? That seems like a dramatically easier problem compared to this.)
There are several AGI pills one can swallow. I think the prospects for a treaty would be very bright if CCP and USG were both uncontrollability-pilled. If uncontrollability is true, strong cases for it are valuable.
On the other hand, if uncontrollability is false, Aschenbrenner's position seems stronger (I don't mean that it necessarily becomes correct, just that it gets stronger).
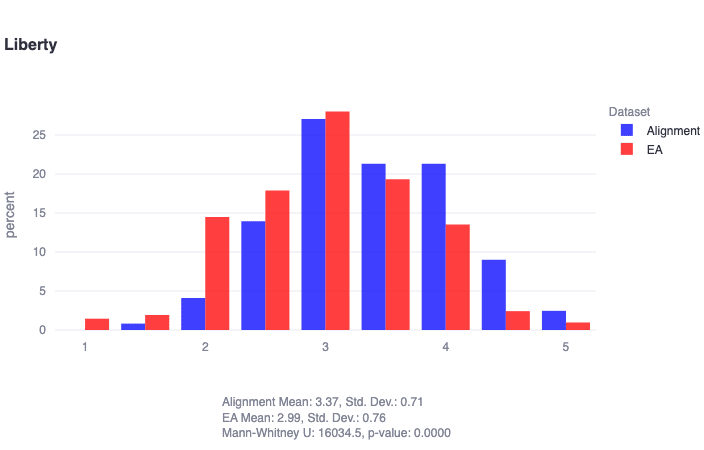
"Liberty: Prioritizes individual freedom and autonomy, resisting excessive governmental control and supporting the right to personal wealth. Lower scores may be more accepting of government intervention, while higher scores champion personal freedom and autonomy..."
"alignment researchers are found to score significantly higher in liberty (U=16035, p≈0)"
Leopold's scenario requires that the USG come to deeply understand all the perils and details of AGI and ASI (since they otherwise don't have a hope of building and aligning a superintelligence), but then needs to choose to gamble its hegemony, its very existence, and the lives of all its citizens on a half-baked mad science initiative, when it could simply work with its allies to block the tech's development and maintain the status quo at minimal risk.
Success in this scenario requires a weird combination of USG prescience with self-destructiveness: enough foresight to see what's coming, but paired with a weird compulsion to race to build the very thing that puts its existence at risk, when it would potentially be vastly easier to spearhead an international alliance to prohibit this technology.
Leopold Aschenbrenner founded an investment firm for AGI and on its homepage he says: "My aspiration is to secure the blessings of liberty for our posterity." Might that influence what he writes about AGI? (Source: https://www.forourposterity.com)
Executive summary: The author agrees with Leopold Aschenbrenner's report on the imminence and risks of artificial superintelligence (ASI), but argues that alignment is not tractable and urgent action is needed to halt or restrict ASI development to avoid catastrophic outcomes.
Key points:
The author agrees with Aschenbrenner that full AGI and ASI are likely only 5-15 years away, and that this technology poses an existential risk if mishandled.
Current AI developers are not taking the risks seriously enough and need to prioritize security and limited access to intellectual property.
Aschenbrenner's report mischaracterizes the situation by suggesting that controllable ASI is feasible; the author argues that if anyone builds ASI with our current level of understanding, it will likely lead to human extinction.
The author calls for urgent action from the US government, including leading an international alliance to prohibit smarter-than-human AI development and restricting frontier AI development to monitored compute clusters.
Rapid action is needed based on the realities of the situation, rather than treating ASI like less dangerous technologies.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
A recent survey of AI alignment researchers found that the most common opinion on the statement "Current alignment research is on track to solve alignment before we get to AGI" was "Somewhat disagree". The same survey found that most AI alignment researchers also support pausing or slowing down AI progress.
Slowing down AI progress might be net-positive if you take ideas like longtermism seriously but it seems challenging to do given the strong economic incentives to increase AI capabilities. Maybe government policies to limit AI progress will eventually enter the Overton window when AI reaches a certain level of dangerous capability.
My take on Leopold Aschenbrenner's new report: I think Leopold gets it right on a bunch of important counts.
Three that I especially care about:
Full AGI and ASI soon. (I think his arguments for this have a lot of holes, but he gets the basic point that superintelligence looks 5 or 15 years off rather than 50+.)
This technology is an overwhelmingly huge deal, and if we play our cards wrong we're all dead.
Current developers are indeed fundamentally unserious about the core risks, and need to make IP security and closure a top priority.
I especially appreciate that the report seems to get it when it comes to our basic strategic situation: it gets that we may only be a few years away from a truly world-threatening technology, and it speaks very candidly about the implications of this, rather than soft-pedaling it to the degree that public writings on this topic almost always do. I think that's a valuable contribution all on its own.
Crucially, however, I think Leopold gets the wrong answer on the question "is alignment tractable?". That is: OK, we're on track to build vastly smarter-than-human AI systems in the next decade or two. How realistic is it to think that we can control such systems?
Leopold acknowledges that we currently only have guesswork and half-baked ideas on the technical side, that this field is extremely young, that many aspects of the problem look impossibly difficult (see attached image), and that there's a strong chance of this research operation getting us all killed. "To be clear, given the stakes, I think 'muddling through' is in some sense a terrible plan. But it might be all we’ve got." Controllable superintelligent AI is a far more speculative idea at this point than superintelligent AI itself.
I think this report is drastically mischaracterizing the situation. ‘This is an awesome exciting technology, let's race to build it so we can reap the benefits and triumph over our enemies’ is an appealing narrative, but it requires the facts on the ground to shake out very differently than how the field's trajectory currently looks.
The more normal outcome, if the field continues as it has been, is: if anyone builds it, everyone dies.
This is not a national security issue of the form ‘exciting new tech that can give a country an economic or military advantage’; it's a national security issue of the form ‘we've found a way to build a doomsday device, and as soon as anyone starts building it the clock is ticking on how long before they make a fatal error and take themselves out, and take the rest of the world out with them’.
Someday superintelligence could indeed become more than a doomsday device, but that's the sort of thing that looks like a realistic prospect if ASI is 50 or 150 years away and we fundamentally know what we're doing on a technical level — not if it's more like 5 or 15 years away, as Leopold and I agree.
The field is not ready, and it's not going to suddenly become ready tomorrow. We need urgent and decisive action, but to indefinitely globally halt progress toward this technology that threatens our lives and our children's lives, not to accelerate ourselves straight off a cliff.
Concretely, the kinds of steps we need to see ASAP from the USG are:
- Spearhead an international alliance to prohibit the development of smarter-than-human AI until we’re in a radically different position. The three top-cited scientists in AI (Hinton, Bengio, and Sutskever) and the three leading labs (Anthropic, OpenAI, and DeepMind) have all publicly stated that this technology's trajectory poses a serious risk of causing human extinction (in the CAIS statement). It is absurd on its face to let any private company or nation unilaterally impose such a risk on the world; rather than twiddling our thumbs, we should act.
- Insofar as some key stakeholders aren’t convinced that we need to shut this down at the international level immediately, a sane first step would be to restrict frontier AI development to a limited number of compute clusters, and place those clusters under a uniform monitoring regime to forbid catastrophically dangerous uses. Offer symmetrical treatment to signatory countries, and do not permit exceptions for any governments. The idea here isn’t to centralize AGI development at the national or international level, but rather to make it possible at all to shut down development at the international level once enough stakeholders recognize that moving forward would result in self-destruction. In advance of a decision to shut down, it may be that anyone is able to rent H100s from one of the few central clusters, and then freely set up a local instance of a free model and fine-tune it; but we retain the ability to change course, rather than just resigning ourselves to death in any scenario where ASI alignment isn’t feasible.
Rapid action is called for, but it needs to be based on the realities of our situation, rather than trying to force AGI into the old playbook of far less dangerous technologies. The fact that we can build something doesn't mean that we ought to, nor does it mean that the international order is helpless to intervene.
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...
Adapted from my Substack, Funding Anthropalypse.
Short version: if you want a share of the coming Anthropic and OpenAI windfall - the $37bn+ that could be in play next year - the way in is to become 'legibly excellent', so the evaluators and donors that frontier lab staff already trust point them to yo...



Rob - excellent post. Wholeheartedly agree.
This is the time for EAs to radically rethink our whole AI safety strategy. Working on 'technical AI alignment' is not going to work in the time that we probably have, given the speed of AI capabilities development.
I think it's still good for some people to work on alignment research. The future is hard to predict, and we can't totally rule out a string of technical breakthroughs, and the overall option space looks gloomy enough (at least from my perspective) that we should be pursuing multiple options in parallel rather than putting all our eggs in one basket.
That said, I think "alignment research pans out to the level of letting us safely wield vastly superhuman AGI in the near future" is sufficiently unlikely that we definitely shouldn't be predicating our plans on that working out. AFAICT Leopold's proposal is that we just lay down and die in the worlds where we can't align vastly superhuman AI, in exchange for doing better in the worlds where we can align it; that seems extremely reckless and backwards to me, throwing away higher-probability success worlds in exchange for more niche and unlikely success worlds.
I also think alignment researchers thus far, as a group, have mainly had the effect of shortening timelines. I want alignment research to happen, but not at the cost of reducing our hope in the worlds where alignment doesn't pan out, and thus far a lot of work labeled "alignment" has either seemed to accelerate the field toward AGI, or seemed to provide justification/cover for increasing the heat and competitiveness of the field, which seems pretty counterproductive to me.
Yep. 100% agree!