Choosing a research topic is a whole research project in itself
The writing phase takes much longer than the earlier phase of working out what to write (more than twice as long)
Co-working on research with one other person is great. It's very motivating and you learn a lot from each other. You have faster feedback loops and so can make a better outcome sooner.
This kind of research-writing-co-working is very mentally tiring (at first I couldn't do more than 4hrs per day)
We really wanted to complete the project in a tight timeframe. I actually posted this 2 weeks after we finished because it was the first chance I had.
Some reflections:
I think that the amount of time we set aside was too short for us, and we could still have made worthwhile improvements with more time to reflect, such as:
Choosing an easier topic for our first research project
Many sentences could be re-written to improve the wording, and I don't think 'Factors of malevolent actors' is a very good heading.
(I'll come back and reply to this comment with more of my own reflections if I think of more and get more time in the next day or two) (edit: formatting)
Not sure whether you intended to give examples of this in the table.
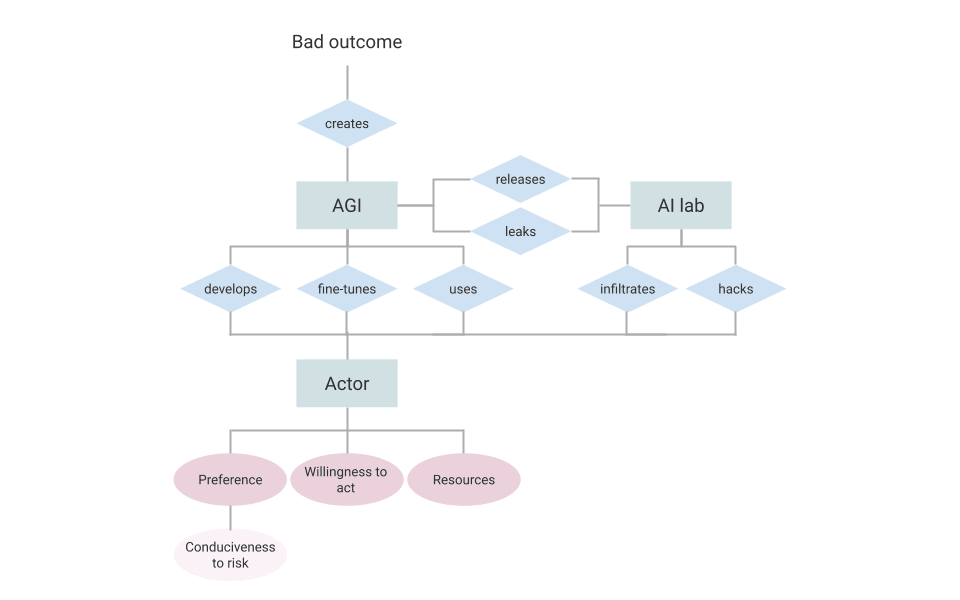
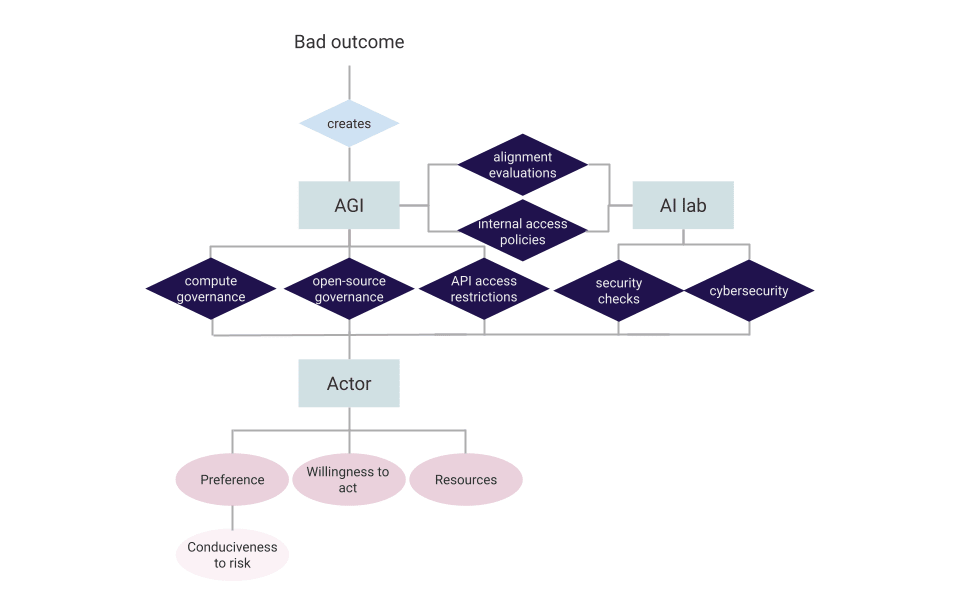
The following figures (Figure 1 and Figure 2) show how our work fits together with governance proposals.
This is a nitpick, but I would find the diagrams easier to read if the "bad outcome" was at the bottom, such that the direction of causality was from top to bottom.
Malevolent actor scenarios are neglected by current governance mechanisms
The dangerousness of actors should be profiled by the dangerousness of their preferences, their willingness to act, and the resources available to them
Executive summary
It is important to understand scenarios in which actors with dangerous intentions gain access to highly capable AI technologies. This post explores just that — ways to assess which actors and which preferences are more dangerous than others. We end with sharing a few concrete scenarios involving malevolent actors currently overlooked by existing governance proposals.
In this post, we
describe factors to understand the dangerousness of actors:[link]
Dangerous preferences
Willingness to act on preferences
Resources
categorise the dangerousness of preferences [link]
Building on earlier work, we describe “risk-conducive preferences” (RCPs) – preferences that, if realised, increase the likelihood of bad outcomes
These preferences are on a spectrum, ranging from those that would directly curb humanity’s potential to those that only indirectly increase the chance of x-risk
highlight some neglected malevolent actor scenarios [link]
Highlight neglected governance mechanisms to address these
Future research could draw on other fields to build towards a full understanding of the actors in this space. This would allow for a more comprehensive list of potentially dangerous actors and for evaluating their likelihood of acquiring and deploying AGI. This would shed light on the need for governance mechanisms specifically targeting risk from malevolent actors and allow them to be weighed against other governance mechanisms.
Background
Malevolent actor x-risk scenarios might be an understudied field. By this field, we mean the attempt of trying to understand and prevent scenarios in which actors (with preferences which make existential catastrophes more likely, such as starting a war) gain access to dangerously capable AI technologies. In “Some governance research ideas to prevent malevolent control over AGI and why this might matter a hell of a lot”, Jim Buhler argues that this kind of governance work “does not necessarily converge with usual AGI governance work” and that “expected value loss due to malevolence, specifically, might be large enough to constitute an area of priority in its own right for longtermists.” We have a similar intuition.
What kind of scenarios involving malevolent actors are we talking about here?
This area is mostly concerned with misuse risk scenarios, where a malevolent actor[1] is able to direct an AGI towards their own aims[2]. Here are some examples:
China independently develops AGI and uses it to permanently lock-in their ideological beliefs, prevent outside influence and fend off dissidents.
Using espionage, blackmailing and corruption, the Russian government gains access to key parts of an AGI architecture. In fear of losing a war, they develop and fine-tune it to launch an aggressive hail-mary attack on the world.
A doomsday cult hacks an AI lab to steal an AGI and uses it to destroy the world.
A member of a radical nationalist group in Europe successfully infiltrates a top AI lab, gains access to an AGI still in development, and uses it to launch an attack on a Middle Eastern state, increasing the chance of starting a world war.
Note here the key difference between these malevolent-actor-type scenarios and other x-risk scenarios: in these cases, there isn’t a misalignment between the actor’s intentions and the AI’s actions. The AI does what the actor intended. And yet, the result is an existential catastrophe, or moving significantly closer to one.
To break these examples down, we can see four underlying components necessary in any malevolent-actor scenario: Actor, preference (RCP), method of accessing AGI, resulting outcome
Large scale destruction, increased global destabilisation
Many current governance proposals help with the category of scenarios we’re talking about. But different proposals help in different amounts. So if prioritising between different proposals, and if designing broader governance institutions, the likelihood of different scenarios in this category should be taken into account.
Factors of malevolent actors
If we want to propose governance mechanisms, we need to know which methods of AGI acquisition are most likely to take place. To know that, we need to know which actors are most “dangerous”. To assess this “dangerousness”, we propose focusing on three underlying factors:
Preferences: What do these actors want, and, if they got what they wanted, how much closer would that take us to catastrophic outcomes?
Willingness to act on preferences: How willing they are to take action to achieve those preferences, especially using extreme methods (e.g. damaging property, harming people, destabilising society)?
Resources: What resources do they have at their disposal to develop or deploy AI models, such as talent, money or AI components?
Let's start with preferences, specifically focusing on what we call "risk-conducive preferences" – these are preferences that, if realised, increase the likelihood of unfavourable outcomes. We'll dive into this concept in more detail later on.
But preferences alone don't paint the full picture. Many individuals hold extreme views but have no intention to act on them. On the other hand, groups with similar views who have a history of causing destruction, like terrorist groups or doomsday cults, might be of higher concern. This means the "willingness to act disruptively” is another critical factor to consider.
The third crucial factor is their access to resources. This can change the quickest out of these three factors. For instance, a small extremist group might receive financial backing from a billionaire or a nation-state. Alternatively, they may gain access to a powerful AGI overnight through a successful infiltration operation. Also note the effect of Moore's law and algorithmic efficiency gains on resource needs. This means we can't solely focus on malicious actors with existing substantial financial resources.
So, if we map out actors and rank them by these three factors, we get a preliminary assessment of their “dangerousness”. This, in turn, gives us a clearer picture of which scenarios are more likely to unfold, and which governance mechanisms are most relevant to prevent these scenarios from happening.
Risk-conducive preferences (RCPs)
Here we go into more detail about one factor of the dangerousness of actors: their preferences.
We’re concerned with actors who would prefer some kind of world state that increases the chance of x-risk. They could achieve this state by using or creating an AGI that shares some of their preferences[4][5]. This could be a preference for global extinction, a preference for the destruction of some group, or perhaps an overly strong preference to win elections.
Realising some preferences directly causes x-risk of s-risk events (e.g. desire to end the world), some merely increase the chance of creating them. The latter being on a spectrum of probabilities: one can imagine preferences which significantly increase the chance of x-risks (e.g. desire to start a global war), while some only moderately increase them (e.g. overly strong preference to win elections, through means of manipulation and societal control). We call all of these preferences "risk-conducive preferences" or "RCPs" for short.
For example: a “desire to reduce crime” might indirectly cause value-lock-in, if the actor takes extreme measures to monitor and control the population. However, it is less of a risk-conducive preference than a “desire to return to a hunter-gatherer society”, leading more directly to societal destabilisation, leaving humanity more vulnerable to extinction and risking the inability to build society up again.
Spectrum for the likelihood of preferences to cause a severely bad outcome if realised
Example at the left: Extinction Example around the middle: Widespread Destruction Example towards the right: Widespread destabilisation
RCPs should not only be concerned with extinction, but also with all outcomes that “permanently or drastically curb humanity’s potential”. This might include value-lock-in, radical and irreversible destabilisation of society, or S-risk. Going forwards, we’ll use “x-risk” to mean any of these outcomes.
We can also put RCPs into three categories, depending on the preference’s closeness to direct desire x-risk:
Order 0 RCPs: explicit preferences that, when fully realised, would directly cause x-risk
Order 1 RCPs: explicit preferences that, when fully realised, would significantly increase the chance of x-risk
Order 2+ RCPs: preferences that would indirectly increase the chance of x-risk
Examples
Order 0 RCPs: explicit preferences that, when fully realised, would directly cause x-risk.
RCP
Reason
Examples
Extinction: Preference for humanity to go extinct
To stop humanity’s destruction of other species and the environment
Because if humans will not go extinct themselves quickly, they will make Earth uninhabitable, making all of life go extinct.
Because they do not believe humans are able to all together in perpetuity live in environmentally sustainable ways.
Because they do not see human life as any more valuable than the lives of other species.
Because they are in a doomsday cult
In order to decrease and prevent suffering
Value Lock-in: Preference for certain values to be upheld indefinitely
Because the values held are assumed to be perfect
Religious extremists
Some authoritarian governments
Irrecoverable civilisation collapse[6]: Preference for removal of civilisation in a way that is irrecoverable (even if preferences change in the future)
Because civilisation causes social and environmental problems
(No well-known examples that don’t include value lock-in)
Order 1 RCPs: explicit preferences that, when fully realised, would be direct x-risk factors (would make it more likely for Order 0 preferences to be realised).
RCP
Conducive to
Reasons
Examples
Preference to radically reduce human population
Irrecoverable civilisation collapse
Worries of environmental effects
Worries of overpopulation
Anti-capitalist terrorist groups
Preference to structure civilisation in a certain way
Belief that civilisation causes more social issues, e.g. Anarcho-primitivism
Some forms of anti-globalization movements, advocating for self-sufficiently at a local community level
Anti-capitalist terrorist groups
Groups holding preferences to return to tribal or agricultural societies
Some forms of extreme religious fundamentalism
Any religious traditions with strong connections to nature and Earth
Order 2+ RCPs: Preferences that, if realised, contribute to x-risks less directly than Order 1 preferences.
Examples
Conflict: Destroying a nation / winning a war – conducive to global conflict, which is conducive to extinction by global war
Society: winning elections / reducing crime – conducive to changing societal structure, which could be conducive to value lock-in
Growth: increasing profit – conducive to runaway growth of an organisation at the expense of other values, which could increase the chance of going out with a whimper.
Or any other preference that might make e.g. AI or biological x-risks more likely.
Neglected malevolent actor scenarios
While considering the characteristics of potential malevolent actors, some dangerous scenarios came to mind. These deserve attention but seem overlooked.
Discussions about malevolent actors typically focus on either large nation-states that are pursuing global dominance or individuals possessing harmful psychological traits. To manage these threats, governance proposals include compute restrictions, cybersecurity measures, and personality assessments.
But here are a few worrying scenarios not affected by those governance mechanisms, listed very roughly in order of likelihood (based solely on intuition):
Open source distribution. With the goal of sharing the benefits of future AI technology across society, a group without any malevolent intentions could release open source models online, allowing malevolent actors to avoid conventional security measures.
Altruistic leaks. An employee within a prominent AI lab, motivated by concerns over power concentration in corporate hands, might decide to leak a trained model online without any malicious intent.
Infiltration. A radicalized individual or an agent of a foreign state could infiltrate an AI lab, gain access to the model and share them with their associates.
Radicalization. A staff member at a leading AI lab could become radicalized by certain philosophical ideas and choose to share the model with like-minded individuals, presenting again novel governance challenges.
Although more research is needed, we see at least two directions for developing governance proposals to address these challenges:
Security clearances. Similar to the vetting of high-ranking government officials, national security agencies could implement comprehensive background checks within AI labs to mitigate risks related to infiltration and espionage.
Thresholds for open sourcing. Investigating mechanisms to restrict the open sourcing of AI models that surpass a certain threshold of power could help prevent dangerous releases.
At this stage of research, we are not offering probability estimates for the likelihood of each scenario. Nonetheless, these examples underscore the need for a more comprehensive approach to AGI governance that encompasses a broader range of potential threats. It seems important to further explore and assess these scenarios, and to offer governance solutions for both governments and AI research labs.
Conclusion
This post has explored ways to evaluate the dangerousness of actors and their preferences, and highlighted some neglected scenarios featuring malevolent actors.
To assess and identify dangerousness more effectively, we unpacked the underlying factors contributing to the dangerousness of malevolent actors: the proximity of their preferences to wishing for catastrophic outcomes, their willingness to act on those preferences, and their resources.
We introduced the concept of “risk-conducive preferences” to encompass a wider set of dangerous preferences highlighting that these preferences are placed along a continuum.
Finally, we provided scenarios that might currently be neglected by existing governance mechanisms.
The following figures (Figure 1 and Figure 2) show how our work fits together with governance proposals.
Figure 1. Breakdown of actor preferences and plausible pathways to bad outcomes.
Figure 2. Possible governance mechanisms (dark blue background) to address pathways to bad outcomes outlined in Figure 1.
We encourage others to build upon this work. Here are a few avenues for future exploration:
Researchers could put together a more extensive list of potentially dangerous actors, and evaluate their likelihood of acquiring and deploying AGI. This helps with knowing which governance mechanisms to implement.
A further breakdown of the underlying psychological conditions of malevolent actors might improve the framework for assessing “dangerousness”. Researchers with a background in psychology might want to dig deeper into the causes for factors such as “willingness to cause disruption” and explore potential targets for governance interventions, such as help for schizophrenic patients or addressing social isolation. This approach might interface well with the existing literature on radicalization.
As always, we appreciate all of the feedback we have received so far and remain very open for future comments.
We would like to thank Jim Buhler, Saulius Šimčikas, Moritz von Knebel, Justin Shovelain and Arran McCutcheon for helpful comments on a draft. All assumptions/claims/omissions are our own.
Jim Buhler frames the issue around preventing the existence of some AGI that has one of these “x-risk conducive preferences”, like intrinsically valuing punishment/destruction/death, and gives some ways for such an AGI to come about. But since these ways initially require an actor to have some risk-conducive preference, we focus on actors.
If the AGI is like an oracle (like a generally intelligent simulator, like a multi-modal GPT-6), then the agent could use it to achieve its preferences, and the extent to which the agent has those preferences is only relevant for what the simulator is likely to say no to. But if the AGI is very agentic (like Auto-GPT or some RL model) then it will have those preferences.
This is a crosspost from the new Animal Welfare Alignment Newsletter by Anima International. You can subscribe on Substack if you are interested in following these efforts. Audio reading also available on Substack.
The goals of this post are to:
1. Raise a question I see as crucially important to the goal of aligning AI to animal welfare...
“How long have you been v*g*n?”
This is one of the most common icebreakers at animal protection events. It’s a baseline assumption, and it mostly holds true: if you’re out advocating for animals not to be tortured or abused, realistically these days you are v**n, or close. And it makes for good conversation. It seems fairly safe to assume when you meet strangers.
But this assumption is hurting the movement in a way which we don’t always notice: someone new comes into the sp...
Summary
Back in November 2023 I posted here to launch Spiro and raise our first $198k. Two and a half years later this is an update and a fundraiser for the next step.
The short version: we've now reached over-5,900 people with TB preventive medicine, including over 3,000 children under five years old. Our early results have held up well an...



This was a great experience and I learnt a lot:
We really wanted to complete the project in a tight timeframe. I actually posted this 2 weeks after we finished because it was the first chance I had.
Some reflections:
I think that the amount of time we set aside was too short for us, and we could still have made worthwhile improvements with more time to reflect, such as:
(I'll come back and reply to this comment with more of my own reflections if I think of more and get more time in the next day or two) (edit: formatting)
Interesting, thanks for sharing your thoughts on the process and stuff! (And happy to see the post published!) :)