EDIT: Oliver Habryka suggests below that I've misunderstood what Will's view is. Apologies if so, and if Will replies — or if I find him clarifying his view anywhere — I'll add a link to his view here.
As far as I can tell, Will just fully agrees that developers are racing to build AI that threatens the entire world, and he thinks they're going to succeed if governments sit back and let it happen, and he's more or less calling on governments to sit back and let it happen. If I've understood his view, this is for a few reasons:
He's pretty sure that alignment is easy enough that researchers could figure it out, with the help of dumb-enough-to-be-safe AI assistants, given time.
He's pretty sure they'll have enough time, because:
He thinks there won't be any future algorithmic breakthroughs or "click" moments that make things go too fast in the future.
If current trendlines continue, he thinks there will be plenty of calendar time between AIs that are close enough to lethal capability levels for us to do all the necessary alignment research, and AIs that are lethally capable. And:
He thinks feedback loops like “AIs do AI capabilities research” won’t accelerate us too much first.
He's also pretty sure that the most safety-conscious AI labs won't mess up alignment in any important ways. (Which is a separate requirement from "superintelligence alignment isn't that technically difficult".)
And he's pretty sure that the least safety-conscious AI labs will be competent, careful, and responsible as well; or the more safety-conscious labs will somehow stop the less safety-conscious labs (without any help from government compute monitoring, because Will thinks government compute monitoring is a bad idea).
And he's sufficiently optimistic that the people who build superintelligence will wield that enormous power wisely and well, and won't fall into any traps that fuck up the future or stretch alignment techniques past their limits, in the name of wealth, power, fame, ideology, misguided altruism, or simple human error.
All of these premises are at best heavily debated among researchers today. And on Will’s own account, he seems to think that his scheme fails if any of these premises are false.
He's not arguing that things go well if AI progress isn't slow and gradual and predictable, and he's not proposing that we have governments do chip monitoring just in case something goes wrong later, so as to maintain option value. He's proposing that humanity put all of its eggs in this one basket, and hope it works out in some as-yet-unspecified way, even though today the labs acknowledge that we have no idea how to align a superintelligence and we need to hope that some unspecified set of breakthroughs turn up in time.
My point above isn’t “Five whole claims aren’t likely to be true at the same time”; that would be the multiple stage fallacy. But as a collection, these points seem pretty dicey. It seems hard to be more than 90% confident in the whole conjunction, in which case there's a double-digit chance that the everyone-races-to-build-superintelligence plan brings the world to ruin.
This seems like a genuinely wild and radical thing to advocate for, in comparison to any other engineering endeavor in history. If someone has legitimately internalized this picture of the situation we're in, I feel like they would at least be arguing for it with a different mood.
If you were trying to load your family onto a plane with a one in ten chance of crashing, you would get them to stop.
If it were the only plane leaving a war zone and you felt forced into this option as a desperation move, you would be pretty desperate to find some better option, and you would hopefully be quite loud about how dire this situation looks.
I come away either confused about how Will ended up so confident in this approach, or concerned that Will has massively buried the lede.
I'll respond to Will's post in more detail below. But, to summarize:
1. I agree that ML engineers have lots of tools available that evolution didn't. These tools seem very unlikely to be sufficient if the field races to build superintelligence as soon as possible, even assuming progress is continuous in all the ways we'd like.
2. I agree that alignment doesn't need to be perfect. But a weak AI that's well-behaved enough to retain users (or well-behaved enough to only steer a small minority into psychotic breaks) isn't "aligned" in the same way we would need to align a superintelligence.
3. I agree that we can't be certain that AI progress will be fast or choppy. The book doesn't talk about this because it isn't particularly relevant for its thesis. Things going slower would help, but only in the same way that giving alchemists ten years to work on the problem makes it likelier they'll transform lead into gold than if you had given them only one year.
The field is radically unserious about how they approach the problem; some major labs deny that there's a problem at all; and we're at the stage of "spitballing interesting philosophical ideas," not at the stage of technical insight where we would have a high probability of aligning a superintelligence this decade.
In general, I think Will falls in a cluster of people who have had a bunch of misconceptions about our arguments for some time, and were a bit blinded by those misconceptions when reading the book, in a way that new readers aren't.[1]
The book isn’t trying to hide its arguments. We say a few words about topics like “AIs accelerate AI research” because they seem like plausible developments, but we don’t say much about them because they’re far from certain and they don’t change the core issue.
You need to already reject a bunch of core arguments in the book before you can arrive at a conclusion like “things will be totally fine as long as AI capabilities trendlines don’t change.”
The state of the field
Will writes:
I had hoped to read a Yudkowsky-Soares worldview that has had meaningful updates in light of the latest developments in ML and AI safety, and that has meaningfully engaged with the scrutiny their older arguments received. I did not get that.
The book does implicitly talk about this, when it talks about gradient descent and LLMs. The situation looks a lot more dire now than it did in 2010. E.g., quoting a comment Eliezer made in a private channel a few days ago:
The book does not go very hard on the old Fragility of Value thesis from the Overcoming Bias days, because the current technology is bad enough that we're not likely to get that kind of close miss. The problem is more like, 'you get some terms of the utility function sorta right on the training distribution but their max outside the training distribution is way different from where you hoped it would generalize' than 'the AI cares about love, life, happiness, fun, consciousness, novelty, and honor, but not music and freedom'.
The book also talks about why we don’t think current LLMs’ ability to competently serve users or pass ethics exams is much evidence that we have superintelligence alignment in the bag.[2] And, for what it’s worth, this seems to be the standard view in the field. See, e.g., Geoff Hinton calling RLHF “a pile of crap," or OpenAI acknowledging in 2023 (before their superintelligence alignment team imploded):
Currently, we don’t have a solution for steering or controlling a potentially superintelligent AI, and preventing it from going rogue. Our current techniques for aligning AI, such as reinforcement learning from human feedback, rely on humans’ ability to supervise AI. But humans won’t be able to reliably supervise AI systems much smarter than us, and so our current alignment techniques will not scale to superintelligence. We need new scientific and technical breakthroughs.
You wouldn't hear people like Hinton saying we have coinflip odds of surviving, or Leike saying we have 10-90% odds of surviving, if we were in an "everything's set to go fine on our current trajectory" kind of situation. You can maybe make an argument for “this is a desperate and chaotic situation, but our best bet is to plough ahead and hope for the best,” but you definitely can’t make an argument for “labs have everything under control, things look great, nothing to worry about here.”
The book’s online supplement adds some additional points on this topic:
The book talks plenty about evolution and ML engineering being very different beasts (see, e.g., pp. 64-65). It doesn't rest the main case for "racing to build ASI as soon as possible won't get us an aligned ASI" on this one analogy (see all of Chapters 10 and 11), and it talks at some length about interpretability research and various plans and ideas by the labs. The online supplement linked in the book talks more about these plans, e.g.:
The evolution analogy isn't just making an outside-view argument of the form "evolution didn't align us, therefore humans won't align AI." Rather, evolution illustrates the specific point that the link between the outer training target and the final objective of a trained mind once it has become much smarter is complex and contingent by default.
This isn't a particularly surprising point, and it isn't too hard to see why it would be true on theoretical first principles; but evolution is one useful way to see this point, and as a matter of historical happenstance, the evolution analogy was important for researchers first noticing and articulating this point.
This tells us things about the kind of challenge researchers are facing, not just about the magnitude of the challenge. There’s a deep challenge, and a ready availability of shallow patches which will look convincing but will fail under pressure. Researchers can use their ingenuity to try to find a solution, but brushing this feature of the problem off with “there are differences between ML and evolution” (without acknowledging all the convincing-looking shallow patches) makes me worry that this aspect of the problem hasn’t really been appreciated.
Without any explicit appeal to evolution, the argument looks like:
1. Outer optimization for success tends to lead to minds that contain many complex internal forces that have their balance at training success.
2. When we look at ML systems today, we see many signs of complex internal forces. ML minds are a mess of conflicting and local drives. (And very strange drives, at that, even when companies are trying their hardest to train AIs to "just be normal" and imitate human behavior.)
3. Labs' attempts to fix things seem to have a sweep-under-the-rug property, rather than looking like they're at all engaging with root causes. The complex internal forces still seem to be present after a problem is “fixed.” (E.g., researchers painstakingly try to keep the model on rails, only for the rails to shatter immediately when users switch to talking in Portuguese.) Which is not surprising, because researchers have almost no insight into root causes, and almost no ability to understand AIs' drives even months or years after the fact.
This is basically a more general and explicitly-spelled-out version of Hinton's critique of RLHF. For some more general points, see:
Re "what if AI progress goes more slowly?", I'd make four claims:
1. It probably won't go slow-and-steady all the way from here to superintelligence. Too many things have to go right at once: there are many different ways for intelligence to improve, and they all need to line up with trend lines into the indefinite future.
The more common case is that trend lines are helpful for predicting progress for a few years, and then something changes and a new trend line becomes more helpful.
In some cases you get extra long CS trend lines, like Moore's Law before that finally fell — though that was presumably in part because Moore's Law was an industry benchmark, not just a measurement.
And in some cases you can post-facto identify some older trendline that persists even after the paradigm shift, but "there's some perspective from which we can view this as continuous" isn't helpful in the manner of "we know for a fact that the trendlines we're currently looking at are going to hold forever."
2a. As the book notes, the AI capability trendlines we have aren't very informative about real-world impacts. Knowing "these numbers are likely to stay on trend for at least a few more years" doesn't help if we don't know where on the curve various practical capabilities come online.
2b. Relatedly: a smooth cognitive ability curve doesn't always translate into a smooth curve in practical power or real-world impact.
3. Even if you have a hunch that all of these curves (and every important not-very-measurable feature of the world that matters) will stay smooth from here to superintelligence, you probably shouldn't be confident in that claim, and therefore shouldn't want to gamble everyone's lives on that claim if there's any possible way to do otherwise.
Paul Christiano, probably the researcher who played the largest role in popularizing "maybe AI will advance in a continuous and predictable way from here to ASI" (or "soft takeoff"), said in 2018 that he had a 30% probability on hard takeoff happening instead. I don't know what his personal probabilities (a.k.a. guesses, because these are all just guesses and there is zero scientific consensus) are today, but in 2022 he said that if he lost his bet with Yudkowsky on AI math progress he might update to "a 50% chance of hard takeoff"; and then he did lose that bet.
It seems pretty insane to be betting the lives of our families and our world on these kinds of speculations. It would be one thing if Will thought superintelligence were impossible, or safe-by-default; but to advocate that we race to build it as fast as possible because maybe takeoff will be soft and maybe researchers will figure something out with the extra time seems wild. I feel like Will's review didn't adequately draw that wildness out.
4. Contrary to Will’s proposals, I don't think soft takeoff actually meaningfully increases our odds of survival. It's "more optimistic" in the way that driving off a 200-foot cliff is more optimistic than driving off a 2000-foot cliff. You still probably die, and all our haggling about fringe survival scenarios shouldn't distract from that fact.
The actual book isn't about the "takeoff continuity" debate at all. The disaster scenario the book focuses on in Part Two is a soft takeoff scenario, where AI hits a wall at around human-level capabilities. See also Max Harms' post discussing this.
The 16-hour run of Sable in Part Two, and the ability to do qualitatively better on new tasks, was lifted from the behavior of o3, which had only recently finished its ARC-AGI run as we were putting pen to paper on that part. I think we all agree that the field regularly makes progress by steps of that size, and that these add up to relatively smooth curves from a certain point of view. The Riemann hypothesis looks like a good guess for tomorrow’s version of ARC-AGI.
There’s then a separate question of whether new feedback loops can close, and launch us onto totally different rates of progress. I think “yes.” The loss-of-control story in Part Two assumes “no,” partly to help show that this is inessential.
Before and After
To better see why this is inessential:
Suppose that someone says, "My general can never orchestrate a coup, because I only give him one new soldier per day.” Increasing the size of the army slowly, in this way, doesn’t actually help. There’s still the gap between Before and After (from Chapter 10): the tests you run on a general who can’t stage a successful coup won’t be reliably informative about a general who can stage such a coup, and many of the empirical generalizations break when you move to can-actually-perform-a-coup territory.
It’s unlikely that we’ll have robust ways to read AIs’ minds if we race ahead as fast as possible; but if we do add the assumption that we can read the general’s mind and see him thinking “Would a coup succeed yet?”, we run into the issues in "Won't there be early warnings?"
We also run into the issue that if you do a bunch of tinkering with the general’s mind and cause him to stop thinking “Would a coup succeed yet?” when he’s too weak to succeed, you need this solution to generalize to the context where the coup would succeed.
This context is going to be different in many ways, and your solutions need to hold up even though some of your relevant theories and generalizations are inevitably going to be wrong on the first go. This is even more true in the case of AI, where the transition to “can succeed in a coup” likely includes important changes to the AI itself (whether achieved gradually or discontinuously), not just changes to the AI’s environment and resources.
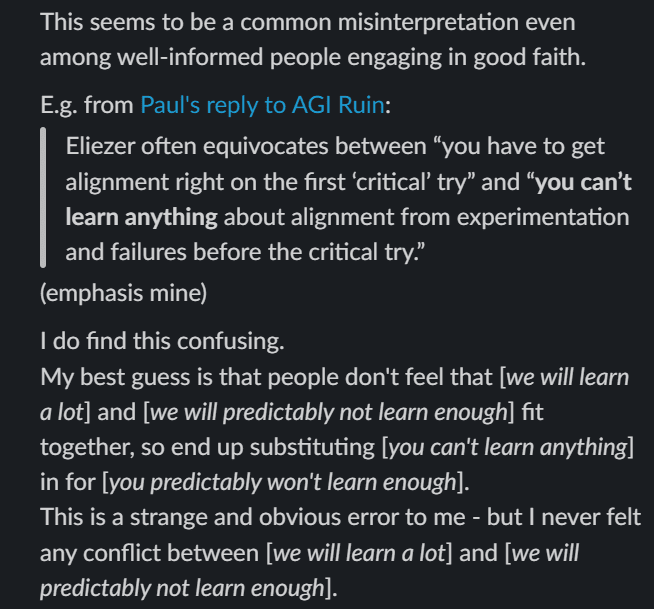
As Joe Collman notes, a common straw version of the If Anyone Builds It, Everyone Dies thesis is that "existing AIs are so dissimilar" to a superintelligence that "any work we do now is irrelevant," when the actual view is that it's insufficient, not irrelevant.
Thought experiments vs. headlines
Paraphrasing my takeaways from a recent conversation with someone at MIRI (written in their voice, even though it mixes together our views a bit):
My perspective on this entire topic is heavily informed by the experience of seeing people spending years debating the ins and outs of AI box experiments, questioning whether a superintelligence could ever break out of its secure airgapped container — only for the real world to bear no relation to these abstruse debates, as companies scramble over each other to hook their strongest AIs up to the Internet as fast as possible to chase profits and exciting demos.
People debate hypothetical complicated schemes for how they would align an AI in Academic Theory Land, and then the real world instead looks like this:
The real world looks like an embarrassing, chaotic disaster, not like a LessWrong thought experiment. This didn't suddenly go away when harms moved from "small" to "medium-sized." It isn't likely to go away when harms move from "medium-sized" to "large."
Companies make nice-sounding promises and commitments, and then roll them back at the earliest inconvenience. Less and less cautious actors enter the race, and more-cautious actors cut corners more and more to maintain competitiveness.
People fantasize about worlds where AIs can help revolutionize alignment; and another year passes, and alignment remains un-revolutionized, and so we can always keep saying "Maybe next year!" until the end of the world. (If there's some clear threshold we could pass that would make you go "ah, this isn't working," then what would it look like? How early would you expect to get this test result back? How much time would it give governments to respond, if we don't start working toward a development halt today?)
People fantasize about worlds where Good AIs can counter the dangers of Bad AIs, so long as we just keep racing ahead as fast as possible. It's a good thing, even, that everybody has less and less time to delay releases for safety reasons, because it just means that there will be even more powerful AIs in the world and therefore even more Good ones to stop the Bad ones. But these supposedly inevitable dynamics always exist in stories about the future, never in observable phenomena we can see today.
In a story, you can always speculate that AI-induced psychosis won't be an issue, because before we have AIs talking thousands of people into psychotic breaks, we'll surely have other AIs that can debug or filter for the psychosis-inducing AIs, or AIs that can protect at-risk individuals.
In a story, no problem ever has to arise, because you can just imagine that all capabilities (and all alignment milestones) will occur in exactly the right sequence to prevent any given harm. In real life, we instead just stumble into every mishap the technology permits, in order; and we wait however many weeks or months or years it takes to find a cheap good-enough local patch, and then we charge onward until the next mishap surprises us.
This is fine as long as the mishaps are small, but the mishaps foreseeably stop being small as the AI becomes more powerful. (And as the AI becomes more able to anticipate and work around safety measures, and more able to sandbag and manipulate developers.)
Even when things stay on trendline, the world goes weird, and it goes fast. It's easy to imagine that everything's going to go down the sanest-seeming-to-you route (like people of the past imagining that the AIs would be boxed and dealt with only through guardians), but that's not anywhere near the path we're on.
If AIs get more capable tomorrow, the world doesn't suddenly start boxing tomorrow, or doing whatever else LessWrongers like having arguments about. Softer takeoff worlds get weird and then die weird deaths.
Passing the alignment buck to AIs
(Continuing to sort-of paraphrase)
To say more about the idea of getting the AIs to solve alignment for us (also discussed in Chapter 11 of the book, and in the online supplement):
How much alignment progress can current humans plus non-superhuman AIs make, if we race ahead to build superintelligence as soon as possible?
My take is "basically none."
My high-level sense is that when researchers today try to do alignment research, they see that it's hard to get any solutions that address even one root cause in a way we can understand. They see that we can only really manage trial-and-error, and guesswork, and a long list of shallow patches to local inexplicable misbehaviors, until most of the alarms temporarily die down.
These kinds of patches are unlikely to hold to superintelligence.
Doing much better seems like it would require, to some extent, getting a new understanding of how intelligence works and what’s going on inside AI. But developing new deep understanding probably takes a lot of intelligence. Humans plus weak AIs don't figure that out; they mislead themselves instead.
If people are thinking of "slightly superhuman" AIs being used for alignment work, my basic guess is that they hit one of four possibilities:
AIs that say, "Yep, I’m stumped too."
AIs that know it isn't in their best interest to help you, and that will either be unhelpful or will actively try to subvert your efforts and escape control.
AIs that are confidently wrong and lead you off a cliff just like the humans would.
AIs that visibly lead you nowhere.
None of these get you out of the woods. If you're working with the sort of AI that is not smart enough to notice its deep messy not-ultimately-aligned-with-human-flourishing preferences, you’re probably working with the sort of AI that’s not smart enough to do the job properly either.
Science and engineering work by trying lots of things, seeing what goes wrong, and iterating until we finally have mature theory and robust engineering practices. If AIs turn out to advance at a more predictable rate, this doesn't escape thatproblem.
Mostly it just looks like an enormous minefield to me, that people say they want to sprint across. It would be easier to critique if anyone were more concrete about which path through the minefield they think is navigable at speed.
</paraphrase>
"Imperfect" alignment
Will argues that current AIs are "imperfectly" aligned, but not "catastrophically" misaligned.
The main problem with the kind of alignment Will's calling "imperfect" isn't that it's literally imperfect.[3] It's that AIs find new and better options over time.
The labs aren’t trying to build human-level AIs and stop there; they’re trying to build superintelligences that vastly outstrip the abilities of human civilization and advance scientific frontiers at enormous speed. Will thinks they’re going to succeed, albeit via continuous (but objectively pretty fast) improvement. This means that AIs need to do what we’d want (or something sufficiently close to what we’d want) even in cases that we never anticipated, much less trained for.
It seems predictable today that if we race ahead to build ASI as fast as possible (because we tossed aside the option of slowing down or stopping via international regulation), the end result of this process won’t be “the ASI deeply and robustly wants there to be happy, healthy, free people.”
The reason for this is that no matter how much we try to train for “robustness” in particular,[4] the ASI’s goals will be an enormous mess of partly-conflicting drives that happened to coincide with nice-looking outcomes. As the AI continues to (“non-discontinuously”) race ahead, improve itself, reflect, change, advance new scientific frontiers, grow in power and influence, and widen its option space, the robustness solutions that make the AI’s goals non-brittle in some respects will inevitably fail to make the AI’s goals non-brittle in every respect that matters.
There may be solutions to this problem in principle, but realistically, they’re not the solutions a competitive, accelerating race will find in the course of spinning up immediately profitable products, particularly when the race begins with the kinds of methods, techniques, and insights we have in machine learning today.
Will gives "risk aversion" as a reason that an AI can be misaligned and superhumanly powerful while still being safe to have around. But:
Risk aversion can prevent AIs from trying to seize power as long as seizing power is the risky move. But anyone competent who has done a group project will know that sometimes grabbing influence or control is the far less risky option.
Takeover sounds intuitively risky to humans, because it puts us in danger; but that doesn’t mean it will always be risky (or relatively risky) for AIs, which will have more and more options as they become more capable, and which have to worry about all the risks of keeping their hands off the steering wheel. (As an obvious example, humans could build a new AI that's less risk-averse, endangering existing AIs.)
AIs are very unlikely to ultimately value promise-keeping as an end in itself; and they won’t have an incentive to keep their promises to humans once they have the power to take over. Any deals you make with the risk-taking AI while it’s weak and uncertain will fail to constrain its options once it’s confident about some way to take over. For the argument for this point, see AIs Won't Keep Their Promises.
For more discussion of "imperfect" alignment, see the links in "the state of the field", and:
The positive proposal is extremely unlikely to happen, could be actively harmful if implemented poorly (e.g. stopping the frontrunners gives more time for laggards to catch up, leading to more players in the race if AI development ends up resuming before alignment is solved), and distracts from the suite of concrete technical and governance agendas that we could be implementing.
I agree that we need to be careful about implementation details. But:
I don’t think it’s helpful to treat “this is unlikely to be tried” as a strike against a new proposal, as this can often amount to a self-fulfilling prophecy. Many new ideas seem politically unpopular, until they suddenly don't; and some ideas are worth the effort to carefully examine and promote even though they're new, because they would be incredibly valuable if they do gain widespread support.
I think “this proposal is bad because it distracts from other stuff” is usually also a bad argument. My guess is that pushing compute monitoring and regulation agendas does not meaningfully impair other safety agendas unless those other agendas involve risking the Earth by building superintelligent machines.
If you think government intervention would be a great idea under certain conditions, you don’t need to stay quiet about government intervention. Instead, be loud about the conditional statement, “If X is true, then governments should do Y.” Then researchers and policy analysts can evaluate for themselves whether they think X is true.
Will also says:
And, even if we’re keen on banning something, we could ban certain sorts of AI (e.g. AI trained on long horizon tasks, and/or AI with certain sorts of capabilities, and/or sufficiently agentic AI).
The thing that needs to stop, from our perspective, is the race towards superintelligence. Self-driving cars, narrow AI for helping boost specific medical research efforts, etc. are separate issues.
And, to reiterate, it seems to me that on Will’s own models, he ought to be loudly advocating for the world to stop, even as he continues to think that this is unlikely to occur. Even if you think we’ve been forced into a desperate race to build ASI as soon as possible, you should probably be pretty loud in acknowledging how insane and horrifically dangerous this situation is, just in case you’re wrong, and just in case it turns out to be important in some unexpected way for the world to better appreciate the dire reality we’re facing.
It’s cheap to acknowledge “this race to build superintelligence as fast as possible is incredibly dangerous.” It’s cheap to say “this is an objectively insane situation that’s massively suboptimal,” even if you’re currently more optimistic about non-policy solutions.
A lot of good can be achieved if people who disagree on a variety of other topics just verbally acknowledge that in principle it would be better to coordinate, stop, and move forward only when there’s a scientific consensus that this won’t kill us. The fact that people aren’t loudly saying this today is indicative of an emperor-has-no-clothes situation, which is the kind of situation where there’s even more potential benefit to being relatively early to loudly broadcast this.
Even if you don’t currently see a straight causal line from "I loudly broadcast these observations" to “useful policy X is implemented,” you should generally expect the future to go better in surprising ways if the world feels comfortable explicitly acknowledging truths.[5]
I think this is also related to the "Why didn't deep learning and LLMs cause MIRI to declare victory?" bafflement. I can understand disagreeing with us about whether LLMs are a good sign, but if you think MIRI-ish perspectives on LLMs are just plain incoherent then you probably haven't understood them.
When I say that alignment is lethally difficult, I am not talking about ideal or perfect goals of 'provable' alignment, nor total alignment of superintelligences on exact human values[...] At this point, I no longer care how it works, I don't care how you got there, I am cause-agnostic about whatever methodology you used, all I am looking at is prospective results, all I want is that we have justifiable cause to believe of a pivotally useful AGI 'this will not kill literally everyone'.
I'm extremely grateful to Max Harms and multiple other MIRI staff for providing ideas, insights, feedback, and phrasings for this post that helped make it a lot better. The finished product primarily reflects my own views, not necessarily Max's or others'.
Hey Rob, thanks for writing this, and sorry for the slow response. In brief, I think you do misunderstand my views, in ways that Buck, Ryan and Habryka point out. I’ll clarify a little more.
Some areas where the criticism seems reasonable:
I think it’s fair to say that I worded the compute governance sentence poorly, in ways Habryka clarified.
I’m somewhat sympathetic to the criticism that there was a “missing mood” (cf e.g. here and here), given that a lot of people won’t know my broader views. I’m very happy to say: "I definitely think it will be extremely valuable to have the option to slow down AI development in the future,” as well as “the current situation is f-ing crazy”. (Though there was also a further vibe on twitter of “we should be uniting rather than disagreeing” which I think is a bad road to go down.)
Now, clarifying my position:
Here’s what I take IABI to be arguing (written by GPT5-Pro, on the basis of a pdf, in an attempt not to infuse my biases):
The book argues that building a superhuman AI would be predictably fatal for humanity and therefore urges an immediate, globally enforced halt to AI escalation—consolidating and monitoring compute under treaty, outlawing capability‑enabling research, and, if necessary, neutralizing rogue datacenters—while mobilizing journalists and ordinary citizens to press leaders to act.
And what readers will think the book is about (again written by GPT5-Pro):
A “shut‑it‑all‑down‑now” manifesto warning that any superintelligent AI will wipe us out unless governments ban frontier AI and are prepared to sabotage or bomb rogue datacenters—so the public and the press must demand it.
The core message of the book is not saying merely “AI x-risk is worryingly high” or “stopping or slowing AI development would be one good strategy among many.” I wouldn’t disagree with the former at all, and the latter disagreement would be more about the details.
Here’s a different perspective:
AI takeover x-risk is high, but not extremely high (e.g. 1%-40%). The right response is an “everything and the kitchen sink” approach — there are loads of things we can do that all help a bit in expectation (both technical and governance, including mechanisms to slow the intelligence explosion), many of which are easy wins, and right now we should be pushing on most of them.
This is my overall strategic picture. If the book had argued for that (or even just the “kitchen sink” approach part) then I might have disagreed with the arguments, but I wouldn’t feel, “man, people will come away from this with a bad strategic picture”.
(I think the whole strategic picture would include:
There are a lot of other existential-level challenges, too (including human coups / concentration of power), and ideally the best strategies for reducing AI takeover risk shouldn’t aggravate these other risks.
But I think that’s fine not to discuss in a book focused on AI takeover risk.)
This is also the broad strategic picture, as I understand it, of e.g. Carl, Paul, Ryan, Buck. It’s true that I’m more optimistic than they are (on the 80k podcast I say 1-10% range for AI x-risk, though it depends on what exactly you mean by that) but I don’t feel deep worldview disagreement with them.
With that in mind, some reasons why I think the promotion of the Y&S view could be meaningfully bad:
If it means more people don’t pursue the better strategy of focusing on the easier wins.
Or they end up making the wrong tradeoffs. (e.g. intense centralisation of AI development in a way that makes misaligned human takeover risk more likely)
Or people might lapse into defeatism: “Ok we’re doomed, then: a decades-long international ban will never happen, so it’s pointless to work on AI x-risk.” (We already see this reaction to climate change, given doomerist messaging there. To be clear, I don’t think that sort of effect should be a reason for being misleading about one’s views.)
Overall, I feel pretty agnostic on whether Y&S shouting their message is on net good for the world.
I think I’m particularly triggered by all this because of a conversation I had last year with someone who takes AI takeover risk very seriously and could double AI safety philanthropy if they wanted to. I was arguing they should start funding AI safety, but the conversation was a total misfire because they conflated “AI safety” with “stop AI development”: their view was that that will never happen, and they were actively annoyed that they were hearing what they considered to be such a dumb idea. My guess was that EY’s TIME article was a big factor there.
Then, just to be clear, here are some cases where you misunderstand me, just focusing on the most-severe misunderstandings:
he's more or less calling on governments to sit back and let it happen
I really don’t think that!
He thinks feedback loops like “AIs do AI capabilities research” won’t accelerate us too much first.
I vibeswise disagree, because I expect massive acceleration and I think that’s *the* key challenge: See e.g. PrepIE, 80k podcast.
But there is a grain of truth in that my best guess is a more muted software-only intelligence explosion than some others predict. E.g. a best guess where, once AI fully automates AI R&D, we get 3-5 years of progress in 1 year (at current rates), rather than 10+ years’ worth, or rather than godlike superintelligence. This is the best analysis I know of on the topic. This might well be the cause of much of the difference in optimism between me and e.g. Carl.
(Note I still take the much larger software explosions very seriously (e.g. 10%-20% probability). And I could totally change my mind on this — the issue feels very live and open to me.)
Will thinks government compute monitoring is a bad idea
Definitely disagree with this one! In general, society having more options and levers just seems great to me.
he's sufficiently optimistic that the people who build superintelligence will wield that enormous power wisely and well, and won't fall into any traps that fuck up the future
Definitely disagree!
Like, my whole bag is that I expect us to fuck up the future even if alignment is fine!! (e.g. Better Futures)
He's proposing that humanity put all of its eggs in this one basket
Definitely disagree! From my POV, it’s the IABI perspective that is closer to putting all the eggs in one basket, rather than advocating for the kitchen sink approach.
It seems hard to be more than 90% confident in the whole conjunction, in which case there's a double-digit chance that the everyone-races-to-build-superintelligence plan brings the world to ruin.
But “10% chance of ruin” is not what EY&NS, or the book, is arguing for, and isn’t what I was arguing against. (You could logically have the view of “10% chance of ruin and the only viable way to bring that down is a global moratorium”, but I don’t know anyone who has that view.)
a conclusion like “things will be totally fine as long as AI capabilities trendlines don’t change.”
Also not true, though I am more optimistic than many on the takeover side of things.
to advocate that we race to build it as fast as possible
Also not true - e.g. I write here about the need to slow the intelligence explosion.
There’s a grain of truth in that I’m pretty agnostic on whether speeding up or slowing down AI development right now is good or bad. I flip-flop on it, but I currently lean towards thinking speed up at the moment is mildly good, for a few reasons: it stretches out the IE by bringing it forwards, means there’s more of a compute constraint and so the software-only IE doesn’t go as far, and means society wakes up earlier, giving more time to invest more in alignment of more-powerful AI.
(I think if we’d gotten to human-level algorithmic efficiency at the Dartmouth conference, that would have been good, as compute build-out is intrinsically slower and more controllable than software progress (until we get nanotech). And if we’d scaled up compute + AI to 10% of the global economy decades ago, and maintained it at that level, that also would have been good, as then the frontier pace would be at the rate of compute-constrained algorithmic progress, rather than the rate we’re getting at the moment from both algorithmic progress AND compute scale-up.)
In general, I think that how the IE happens and is governed is a much bigger deal than when it happens.
like, I still associate Will to some degree with the past version of himself who was mostly unconcerned about near-term catastrophes and thought EA's mission should be to slowly nudge long-term social trends.
Which Will-version are you thinking of? Even in DGB I wrote about preventing near-term catastrophes as a top cause area.
I think Will was being unvirtuously cagey or spin-y about his views
Again really not intended! I think I’ve been clear about my views elsewhere (see previous links).
Ok, that’s all just spelling out my views. Going back, briefly, to the review. I said I was “disappointed” in the book — that was mainly because I thought that this was E&Y’s chance to give the strongest version of their arguments (though I understood they’d be simplified or streamlined), and the arguments I read were worse than I expected (even though I didn’t expect to find them terribly convincing).
Regarding your object-level responses to my arguments — I don’t think any of them really support the idea that alignment is so hard that AI takeover x-risk is overwhelmingly likely, or that the only viable response is to delay AI development by decades. E.g.
As Joe Collman notes, a common straw version of the If Anyone Builds It, Everyone Dies thesis is that "existing AIs are so dissimilar" to a superintelligence that "any work we do now is irrelevant," when the actual view is that it's insufficient, not irrelevant.
But if it’s a matter of “insufficiency”, the question is how one can be so confident that any work we do now (including with ~AGI assistance, including if we’ve bought extra time via control measures and/or deals with misaligned ~AGIs) is insufficient, such that the only thing that makes a meaningful difference to x-risk, even in expectation, is a global moratorium. And I’m still not seeing the case for that.
(I think I’m unlikely to respond further, but thanks again for the engagement.)
the better strategy of focusing on the easier wins
I feel that you are not really appreciating the point that such "easier wins" aren't in fact wins at all, in terms of keeping us all alive. They might make some people feel better, but they are very unlikely to reduce AI takeover risk to, say, a comfortable 0.1% (In fact I don't think they will reduce it to below 50%).
I think I’m particularly triggered by all this because of a conversation I had last year with someone who takes AI takeover risk very seriously and could double AI safety philanthropy if they wanted to. I was arguing they should start funding AI safety, but the conversation was a total misfire because they conflated “AI safety” with “stop AI development”: their view was that that will never happen, and they were actively annoyed that they were hearing what they considered to be such a dumb idea. My guess was that EY’s TIME article was a big factor there.
Well hearing this, I am triggered that someone "who takes AI takeover risk very seriously" would think that stopping AI development was "such a dumb idea"! I'd question whether they do actually take AI takeover risk seriously at all. Whether or not a Pause is "realistic" or "will never happen", we have to try! It really is our only shot if we actually care about staying alive for more than another few years. More people need to realise this. And I still don't understand how people can think that the default outcome of AGI/ASI is survival for humanity, or an OK outcome.
...the question is how one can be so confident that any work we do now (including with ~AGI assistance, including if we’ve bought extra time via control measures and/or deals with misaligned ~AGIs) is insufficient, such that the only thing that makes a meaningful difference to x-risk, even in expectation, is a global moratorium. And I’m still not seeing the case for that.
I'd flip this completely, and say: the question is why we should be so confident that any work we do now (including with AI assistance, including if we’ve bought extra time via control measures and/or deals with misaligned AIs) is sufficient to solve alignment, such that the only thing that makes a meaningful difference to x-risk, even in expectation, a global moratorium, is unnecessary. I’m still not seeing the case for that.
(I think if we’d gotten to human-level algorithmic efficiency at the Dartmouth conference, that would have been good, as compute build-out is intrinsically slower and more controllable than software progress (until we get nanotech). And if we’d scaled up compute + AI to 10% of the global economy decades ago, and maintained it at that level, that also would have been good, as then the frontier pace would be at the rate of compute-constrained algorithmic progress, rather than the rate we’re getting at the moment from both algorithmic progress AND compute scale-up.)
This is an interesting thought experiment. I think it probably would've been bad, because it would've initiated an intelligence explosion. Sure, it would've started off very slow, but it would've gathered steam inexorably, speeding tech development, including compute scaling. And all this before anyone had even considered the alignment problem. After a couple of decades perhaps humanity would already have been gradually disempowered past the point of no return.
Buck: So following up on your Will post: It sounds like you genuinely didn't understand that Will is worried about AI takeover risk and thinks we should try to avert it, including by regulation. Is that right?
I'm just so confused here. I thought your description of his views was a ridiculous straw man, and at first I thought you were just being some combination of dishonest and rhetorically sloppy, but now my guess is you're genuinely confused about what he thinks?
(Happy to call briefly if that would be easier. I'm interested in talking about this a bit because I was shocked by your post and want to prevent similar things happening in the future if it's easy to do so.)
Rob: I was mostly just going off Will's mini-review; I saw that he briefly mentioned "governance agendas" but otherwise everything he said seemed to me to fit 'has some worries that AI could go poorly, but isn't too worried, and sees the current status quo as basically good -- alignment is going great, the front-running labs are sensible, capabilities and alignment will by default advance in a way that lets us ratchet the two up safely without needing to do anything special or novel'
so I assumed if he was worried, it was mainly about things that might disrupt that status quo
Buck: what about his line "I think the risk of misaligned AI takeover is enormously important."
alignment is going great, the front-running labs are sensible
This is not my understanding of what Will thinks.
[added by Buck later: And also I don’t think it’s an accurate reading of the text.]
Rob: 🙏
that's helpful to know!
Buck: I am not confident I know exactly what Will thinks here. But my understanding is that his position is something like: The situation is pretty scary (hence him saying "I think the risk of misaligned AI takeover is enormously important."). There is maybe 5% overall chance of AI takeover, which is a bad and overly large number. The AI companies are reckless and incompetent with respect to these risks, compared to what you’d hope given the stakes. Rushing through super intelligence would be extremely dangerous for AI takeover and other reasons.
[added/edited by Buck later: I interpret the review as saying:
He thinks the probability of AI takeover and of human extinction due to AI takeover is substantially lower than you do.
This is not because he thinks “AI companies/humanity are very thoughtful about mitigating risk from misaligned superintelligence, and they are clearly on track to develop techniques that will give developers justified confidence that AIs powerful enough that their misalignment poses risk of AI takeover are aligned”. It’s because he is more optimistic about what will happen if AI companies and humanity are not very thoughtful and competent.
He thinks that the arguments given in the book have important weaknesses.
He disagrees with the strategic implications of the worldview described in the book.
For context, I am less optimistic than he is, but I directionally agree with him on both points.]
In general, MIRI people often misunderstand someone saying, "I think X will probably be fine because of consideration Y" to mean "I think that plan Y guarantees that X will be fine". And often, Y is not a plan at all, it's just some purported feature of the world.
Another case is people saying "I think that argument A for why X will go badly fails to engage with counterargument Y", which MIRI people round off to "X is guaranteed to go fine because of my plan Y"
Rob: my current guess is that my error is downstream of (a) not having enough context from talking to Will or seeing enough other AI Will-writing, and (b) Will playing down some of his worries in the review
I think I was overconfident in my main guess, but I don't think it would have been easy for me to have Reality as my main guess instead
Buck: When I asked the AIs, they thought that your summary of Will's review was inaccurate and unfair, based just on his review.
It might be helpful to try checking this way in the future.
I'm still interested in how you interpreted his line "I think the risk of misaligned AI takeover is enormously important."
Rob: I think that line didn't stick out to me at all / it seemed open to different interpretations, and mainly trying to tell the reader 'mentally associate me with some team other than the Full Takeover Skeptics (eg I'm not LeCun), to give extra force to my claim that the book's not good'.
like, I still associate Will to some degree with the past version of himself who was mostly unconcerned about near-term catastrophes and thought EA's mission should be to slowly nudge long-term social trends. "enormously important" from my perspective might have been a polite way of saying 'it's 1 / 10,000 likely to happen, but that's still one of the most serious risks we face as a society'
it sounds like Will's views have changed a lot, but insofar as I was anchored to 'this is someone who is known to have oddly optimistic views and everything-will-be-pretty-OK views about the world' it was harder for me to see what it sounds like you saw in the mini-review
(I say this mainly as autobiography since you seemed interested in debugging how this happened; not as 'therefore I was justified/right')
Buck: Ok that makes sense
Man, how bizarre
Claude had basically the same impression of your summary as I did
Which makes me feel like this isn't just me having more context as a result of knowing Will and talking to him about this stuff.
Rob: I mean, I still expect most people who read Will's review to directionally update the way I did -- I don't expect them to infer things like
"The situation is pretty scary."
"The AI companies are reckless and incompetent wrt these risks."
"Rushing through super intelligence would be extremely dangerous for AI takeover and other reasons."
or 'a lot of MIRI-ish proposals like compute governance are a great idea' (if he thinks that)
or 'if the political tractability looked 10-20x better then it would likely be worth seriously looking into a global shutdown immediately' (if he thinks something like that??)
I think it was reasonable for me to be confused about what he thinks on those fronts and to press him on it, since I expect his review to directionally make people waaaaaaay more misinformed and confused about the state of the world
and I think some of his statements don't make sense / have big unresolved tensions, and a lot of his arguments were bad and misinformed. (not that him strawmanning MIRI a dozen different ways excuses me misrepresenting his view; but I still find it funny how disinterested people apparently are in the 'strawmanning MIRI' side of things? maybe they see no need to back me up on the places where my post was correct, because they assume the Light of Truth will shine through and persuade people in those cases, so the only important intervention is to correct errors in the post?)
but I should have drawn out those tensions by posing a bunch of dilemmas and saying stuff like 'seems like if you believe W, then bad consequence X; and if you believe Y, then bad consequence Z. which horn of the dilemma do you choose, so I know what to argue against?', rather than setting up a best-guess interpretation of what Will was saying (even one with a bunch of 'this is my best guess' caveats)
I think Will was being unvirtuously cagey or spin-y about his views, and this doesn't absolve me of responsibility for trying to read the tea leaves and figure out what he actually thinks about 'should government ever slow down or halt the race to ASI?', but it would have been a very easy misinterpretation for him to prevent (if his views are as you suggest)
it sounds like he mostly agrees about the parts of MIRI's view that we care the most about, eg 'would a slowdown/halt be good in principle', 'is the situation crazy', 'are the labs wildly irresponsible', 'might we actually want a slowdown/halt at some point', 'should govs wake up to this and get very involved', 'is a serious part of the risk rogue AI and not just misuse', 'should we do extensive compute monitoring', etc.
it's not 100% of what we're pushing but it's overwhelmingly more important to us than whether the risk is more like 20-50% or more like 'oh no'
I think most readers wouldn't come away from Will's review thinking we agree on any of those points, much less all of them
Buck:
I expect his review to directionally make people waaaaaaay more misinformed and confused about the state of the world
I disagree
and I think some of his statements don't make sense / have big unresolved tensions, and a lot of his arguments were bad and misinformed.
I think some of his arguments are dubious, but I don't overall agree with you.
I think Will was being unvirtuously cagey or spin-y about his views, and this doesn't absolve me of responsibility for trying to read the tea leaves and figure out what he actually thinks about 'should government ever slow down or halt the race to ASI?', but it would have been a very easy misinterpretation for him to prevent (if his views are as you suggest)
I disagree for what it's worth.
it sounds like he mostly agrees about the parts of MIRI's view that we care the most about, eg 'would a slowdown/halt be good in principle', 'is the situation crazy', 'are the labs wildly irresponsible', 'might we actually want a slowdown/halt at some point', 'should govs wake up to this and get very involved', 'is a serious part of the risk rogue AI and not just misuse', 'should we do extensive compute monitoring', etc.
it's not 100% of what we're pushing but it's overwhelmingly more important to us than whether the risk is more like 20-50% or more like 'oh no'
I think that the book made the choice to center a claim that people like Will and me disagree with: specifically, "With the current trends in AI progress building super intelligence is overwhelmingly likely to lead to misaligned AIs that kill everyone."
It's true that much weaker claims (e.g. all the stuff you have in quotes in your message here) are the main decision-relevant points. But the book chooses to not emphasize them and instead emphasize a much stronger claim that in my opinion and Will's opinion it fails to justify.
I think it's reasonable for Will to substantially respond to the claim that you emphasize, rather than different claims that you could have chosen to emphasize.
I think a general issue here is that MIRI people seem to me to be responding at a higher simulacrum level than the one at which criticisms of the book are operating. Here you did that partly because you interpreted Will as himself operating at a higher simulacrum level than the plain reading of the text.
I think it's a difficult situation when someone makes criticisms that, on the surface level, look like straightforward object level criticisms, but that you suspect are motivated by a desire to signal disagreement. I think it is good to default to responding just on the object level most of the time, but I agree there are costs to that strategy.
And if you want to talk about the higher simulacra levels, I think it's often best to do so very carefully and in a centralized place, rather than in a response to a particular person.
I also agree with Habryka’s comment that Will chose a poor phrasing of his position on regulation.
Rob: If we agree about most of the decision-relevant claims (and we agree about which claims are decision-relevant), then I think it's 100% reasonable for you and Will to critique less-decision-relevant claims that Eliezer and Nate foregrounded; and I also think it would be smart to emphasize those decision-relevant claims a lot more, so that the world is likely to make better decisions. (And so people's models are better in general; I think the claims I mentioned are very important for understanding the world too, not just action-relevant.)
I especially think this is a good idea for reviews sent to a hundred thousand people on Twitter. I want a fair bit more of this on LessWrong too, but I can see a stronger claim having different norms on LW, and LW is also a place where a lot of misunderstandings are less likely because a lot more people here have context.
Re simulacra levels: I agree that those are good heuristics. For what it's worth, I still have a much easier time mentally generating a review like Will's when I imagine the author as someone who disagrees with that long list of claims; I have a harder time understanding how none of those points of agreement came up in the ensuing paragraphs if Will tacitly agreed with me about most of the things I care about.
Possibly it's just a personality or culture difference; if I wrote "This is a shame, because I think the risk of misaligned AI takeover is enormously important" (especially in the larger context of the post it occurred in) I might not mean something all that strong (a lot of things in life can be called "enormously important" from one perspective or another); but maybe that's the Oxford-philosopher way of saying something closer to "This situation is insane, we're playing Russian roulette with the world, this is an almost unprecedented emergency."
(Flagging that this is all still speculative because Will hasn't personally confirmed what his views are someplace I can see it. I've been mostly deferring to you, Oliver, etc. about what kinds of positions Will is likely to endorse, but my actual view is a bit more uncertain than it may sound above.)
Oliver gave an argument for "this misrepresents Will's views" on LessWrong, saying:
I currently think this is putting too much weight on a single paragraph in Will's review. The paragraph is:
[IABIED:] "All over the Earth, it must become illegal for AI companies to charge ahead in developing artificial intelligence as they’ve been doing."
[Will:] "The positive proposal is extremely unlikely to happen, could be actively harmful if implemented poorly (e.g. stopping the frontrunners gives more time for laggards to catch up, leading to more players in the race if AI development ends up resuming before alignment is solved), and distracts from the suite of concrete technical and governance agendas that we could be implementing."
I agree that what Will is saying literally here is that "making it illegal for AI companies to charge ahead as they've been doing is extremely unlikely to happen, and probably counterproductive". I think this is indeed a wrong statement that implies a kind of crazy worldview. I also think it's very unlikely what Will meant to say.
I think what Will meant to say is something like "the proposal in the book, which I read as trying to ban AGI development, right now, globally, using relatively crude tools like banning anyone from having more than 8 GPUs, is extremely unlikely to happen and the kind of thing that could easily backfire".
I think the latter is a much more reasonable position, and I think does not imply most of the things you say Will must believe in this response. My best guess is that Will is in favor of regulation that allows slowing things down, in favor of compute monitoring, and even in favor of conditional future pauses. The book does talk about them, and I find Will's IMO kind of crazily dismissive engagement with these proposals pretty bad, but I do think you are just leaning far too much on a very literal interpretation of what Will said in a way that I think is unproductive.
(I dislike Will's review for a bunch of other reasons, which includes his implicit mischaracterization of the policies proposed in the book, but my response would look very different than this post)
I wasn't exclusively looking at that line; I was also assuming that if Will liked some of the book's core policy proposals but disliked others, then he probably wouldn't have expressed such a strong a blanket rejection. And I was looking at Will's proposal here:
[IABIED skips over] what I see as the crucial period, where we move from the human-ish range to strong superintelligence[1]. This is crucial because it’s both the period where we can harness potentially vast quantities of AI labour to help us with the alignment of the next generation of models, and because it’s the point at which we’ll get a much better insight into what the first superintelligent systems will be like. The right picture to have is not “can humans align strong superintelligence”, it’s “can humans align or control AGI-”, then “can {humans and AGI-} align or control AGI” then “can {humans and AGI- and AGI} align AGI+” and so on.
This certainly sounds like a proposal that we advance AI as fast as possible, so that we can reach the point where productive alignment research is possible sooner.
The next paragraph then talks about "a gradual ramp-up to superintelligence", which makes it sound like Will at least wants us to race to the level of superintelligence as quickly as possible, i.e., he wants the chain of humans-and-AIs-aligning-stronger-AIs to go at least that far:
Elsewhere, EY argues that the discontinuity question doesn’t matter, because preventing AI takeover is still a ‘first try or die’ dynamic, so having a gradual ramp-up to superintelligence is of little or no value. I think that’s misguided.
... Unless he thinks this "gradual ramp-up" should be achieved via switching over at some point from the natural continuous trendlines he expects from industry, to top-down government-mandated ratcheting up of a capability limit? But I'd be surprised if that's what he had in mind, given the rest of his comment.
Wanting the world to race to build superintelligence as soon as possible also seems like it would be a not-that-surprising implication of his labs-have-alignment-in-the-bag claims.
And although it's not totally clear to me how seriously he's taking this hypothetical (versus whether he mainly intends it as a proof of concept), he does propose that we could build a superintelligent paperclip maximizer and plausibly be totally fine (because it's risk averse and promise-keeping), and his response to "Maybe we won't be able to make deals with AIs?" is:
I agree that’s a worry; but then the right response is to make sure that we can.
Not "in that case maybe we shouldn't build a misaligned superintelligence", but "well then we'd sure better solve the honesty problem!".
All of this together makes me extremely confused if his real view is basically just "I agree with most of MIRI's policy proposals but I think we shouldn't rush to enact a halt or slowdown tomorrow".
If his view is closer to that, then that's great news from my perspective, and I apologize for the misunderstanding. I was expecting Will to just straightforwardly accept the premises I listed, and for the discussion to proceed from there.
I'll add a link to your comment at the top of the post so folks can see your response, and if Will clarifies his view I'll link to that as well.
Twitter says that Will's tweet has had over a hundred thousand views, so if he's a lot more pro-compute-governance, pro-slowdown, and/or pro-halt than he sounded in that message, I hope he says loud stuff in the near future to clarify his views to folks!
This post is co-authored with Ben Garfinkel. It is cross-posted from the CEA blog. A PDF version can be found here.
Summary: Some strategic decisions available to the effective altruism m...
TL;DR: I'm releasing a website that ranks philanthropists according to EA principles and research, and allows users to re-rank the list using their own assumptions. I'd like feedback and help making it better. I'd especially like ideas for how to make the results more trustworthy. Funding may be available.
Crossposted to LessWrong.
...
(Please share with your friends in the Netherlands).
On August 5, in Amsterdam in the Netherlands, there’s a protest that could help shut down the world’s largest insect farm. It’s at Teleportboulevard 105 1043 EJ Amsterdam, Netherlands. Read more at this link. There’s also a zoom call on Wednesday 29th July at 12:30pm (CEST) with more info. This...



(cross-posted from LW)
Hey Rob, thanks for writing this, and sorry for the slow response. In brief, I think you do misunderstand my views, in ways that Buck, Ryan and Habryka point out. I’ll clarify a little more.
Some areas where the criticism seems reasonable:
Now, clarifying my position:
Here’s what I take IABI to be arguing (written by GPT5-Pro, on the basis of a pdf, in an attempt not to infuse my biases):
And what readers will think the book is about (again written by GPT5-Pro):
The core message of the book is not saying merely “AI x-risk is worryingly high” or “stopping or slowing AI development would be one good strategy among many.” I wouldn’t disagree with the former at all, and the latter disagreement would be more about the details.
Here’s a different perspective:
This is my overall strategic picture. If the book had argued for that (or even just the “kitchen sink” approach part) then I might have disagreed with the arguments, but I wouldn’t feel, “man, people will come away from this with a bad strategic picture”.
(I think the whole strategic picture would include:
But I think that’s fine not to discuss in a book focused on AI takeover risk.)
This is also the broad strategic picture, as I understand it, of e.g. Carl, Paul, Ryan, Buck. It’s true that I’m more optimistic than they are (on the 80k podcast I say 1-10% range for AI x-risk, though it depends on what exactly you mean by that) but I don’t feel deep worldview disagreement with them.
With that in mind, some reasons why I think the promotion of the Y&S view could be meaningfully bad:
Overall, I feel pretty agnostic on whether Y&S shouting their message is on net good for the world.
I think I’m particularly triggered by all this because of a conversation I had last year with someone who takes AI takeover risk very seriously and could double AI safety philanthropy if they wanted to. I was arguing they should start funding AI safety, but the conversation was a total misfire because they conflated “AI safety” with “stop AI development”: their view was that that will never happen, and they were actively annoyed that they were hearing what they considered to be such a dumb idea. My guess was that EY’s TIME article was a big factor there.
Then, just to be clear, here are some cases where you misunderstand me, just focusing on the most-severe misunderstandings:
I really don’t think that!
I vibeswise disagree, because I expect massive acceleration and I think that’s *the* key challenge: See e.g. PrepIE, 80k podcast.
But there is a grain of truth in that my best guess is a more muted software-only intelligence explosion than some others predict. E.g. a best guess where, once AI fully automates AI R&D, we get 3-5 years of progress in 1 year (at current rates), rather than 10+ years’ worth, or rather than godlike superintelligence. This is the best analysis I know of on the topic. This might well be the cause of much of the difference in optimism between me and e.g. Carl.
(Note I still take the much larger software explosions very seriously (e.g. 10%-20% probability). And I could totally change my mind on this — the issue feels very live and open to me.)
Definitely disagree with this one! In general, society having more options and levers just seems great to me.
Definitely disagree!
Like, my whole bag is that I expect us to fuck up the future even if alignment is fine!! (e.g. Better Futures)
Definitely disagree! From my POV, it’s the IABI perspective that is closer to putting all the eggs in one basket, rather than advocating for the kitchen sink approach.
But “10% chance of ruin” is not what EY&NS, or the book, is arguing for, and isn’t what I was arguing against. (You could logically have the view of “10% chance of ruin and the only viable way to bring that down is a global moratorium”, but I don’t know anyone who has that view.)
Also not true, though I am more optimistic than many on the takeover side of things.
Also not true - e.g. I write here about the need to slow the intelligence explosion.
There’s a grain of truth in that I’m pretty agnostic on whether speeding up or slowing down AI development right now is good or bad. I flip-flop on it, but I currently lean towards thinking speed up at the moment is mildly good, for a few reasons: it stretches out the IE by bringing it forwards, means there’s more of a compute constraint and so the software-only IE doesn’t go as far, and means society wakes up earlier, giving more time to invest more in alignment of more-powerful AI.
(I think if we’d gotten to human-level algorithmic efficiency at the Dartmouth conference, that would have been good, as compute build-out is intrinsically slower and more controllable than software progress (until we get nanotech). And if we’d scaled up compute + AI to 10% of the global economy decades ago, and maintained it at that level, that also would have been good, as then the frontier pace would be at the rate of compute-constrained algorithmic progress, rather than the rate we’re getting at the moment from both algorithmic progress AND compute scale-up.)
In general, I think that how the IE happens and is governed is a much bigger deal than when it happens.
Which Will-version are you thinking of? Even in DGB I wrote about preventing near-term catastrophes as a top cause area.
Again really not intended! I think I’ve been clear about my views elsewhere (see previous links).
Ok, that’s all just spelling out my views. Going back, briefly, to the review. I said I was “disappointed” in the book — that was mainly because I thought that this was E&Y’s chance to give the strongest version of their arguments (though I understood they’d be simplified or streamlined), and the arguments I read were worse than I expected (even though I didn’t expect to find them terribly convincing).
Regarding your object-level responses to my arguments — I don’t think any of them really support the idea that alignment is so hard that AI takeover x-risk is overwhelmingly likely, or that the only viable response is to delay AI development by decades. E.g.
But if it’s a matter of “insufficiency”, the question is how one can be so confident that any work we do now (including with ~AGI assistance, including if we’ve bought extra time via control measures and/or deals with misaligned ~AGIs) is insufficient, such that the only thing that makes a meaningful difference to x-risk, even in expectation, is a global moratorium. And I’m still not seeing the case for that.
(I think I’m unlikely to respond further, but thanks again for the engagement.)
I feel that you are not really appreciating the point that such "easier wins" aren't in fact wins at all, in terms of keeping us all alive. They might make some people feel better, but they are very unlikely to reduce AI takeover risk to, say, a comfortable 0.1% (In fact I don't think they will reduce it to below 50%).
Well hearing this, I am triggered that someone "who takes AI takeover risk very seriously" would think that stopping AI development was "such a dumb idea"! I'd question whether they do actually take AI takeover risk seriously at all. Whether or not a Pause is "realistic" or "will never happen", we have to try! It really is our only shot if we actually care about staying alive for more than another few years. More people need to realise this. And I still don't understand how people can think that the default outcome of AGI/ASI is survival for humanity, or an OK outcome.
I'd flip this completely, and say: the question is why we should be so confident that any work we do now (including with AI assistance, including if we’ve bought extra time via control measures and/or deals with misaligned AIs) is sufficient to solve alignment, such that the only thing that makes a meaningful difference to x-risk, even in expectation, a global moratorium, is unnecessary. I’m still not seeing the case for that.
This is an interesting thought experiment. I think it probably would've been bad, because it would've initiated an intelligence explosion. Sure, it would've started off very slow, but it would've gathered steam inexorably, speeding tech development, including compute scaling. And all this before anyone had even considered the alignment problem. After a couple of decades perhaps humanity would already have been gradually disempowered past the point of no return.