William_MacAskill
Posts 100
Comments281
This is probably the best thing written on expected fatalities.
But the main point is:
- The resources needed to sustain the human species are tiny compared even to the resources just in the solar system (1 part in 10 trillion for all of current civilisation, and the human species could be sustained with a tiny fraction of that)
- If misaligned ASI wants power, it doesn't need to kill everybody in order to do so (and deliberately killing everybody would actively be wasteful).
- So in order to keep some humans around, it only needs to be the case that a tiny fraction of AIs care a tiny amount about keeping some humans around. Could be for intrinsic concern, nostalgia, fulfilling commitments they made (in order to get some humans on-side), acausal reasons (trade with human-like creatures elsewhere in the universe or multiverse), reasoning with potential human simulators, or instrumental reasons (they want to do experiments on humans for science). But the main point is just any tiny motivation is enough. Yes, we're atoms that could be used for something else, but we're really not many atoms at all.
(I also think most human disempowerment scenarios are ones where the humans in general feel pretty fine with it, but I think the above even putting that to the side.)
A couple of quick thoughts:
1/
- A big thing, in my view, is that AI safety isn't about preventing "extinction" in the relevant sense. In most worlds where AI disempowers humanity, the human species continues. And in essentially all worlds where AI disempowers humanity, AI still takes to the stars. So, AI safety is about who we want to guide the future, not about whether there's a long-term future or not.
- And, even if humanity does go extinct in (say) a bio-catastrophe, probably technologically-capable life evolves in the remaining time that Earth remains habitable.
- So, the probability of "an event occurs by 2100 that prevents Earth-originating life from ever spreading to the stars" is really low, I'd say <1%.
- Which is a lot less, in my view, than "an event occurs by 2100 that meaningfully affects the long-term value of Earth-originating civilisation" where I'm >50%. Cluelessness pushes this down, so "an event occurs that meaningfully and predictably in expectation" is lower, but not by enough.
2/
- There's still WAY more quality-adjusted $$ and labour going to AI safety than there is to AI-enabled extreme human power concentration, from the EA / AI safety communities. I'd say 1-2 OOMs more? So, I think one thing that's going on is a correction because that ratio is out of whack.
3/
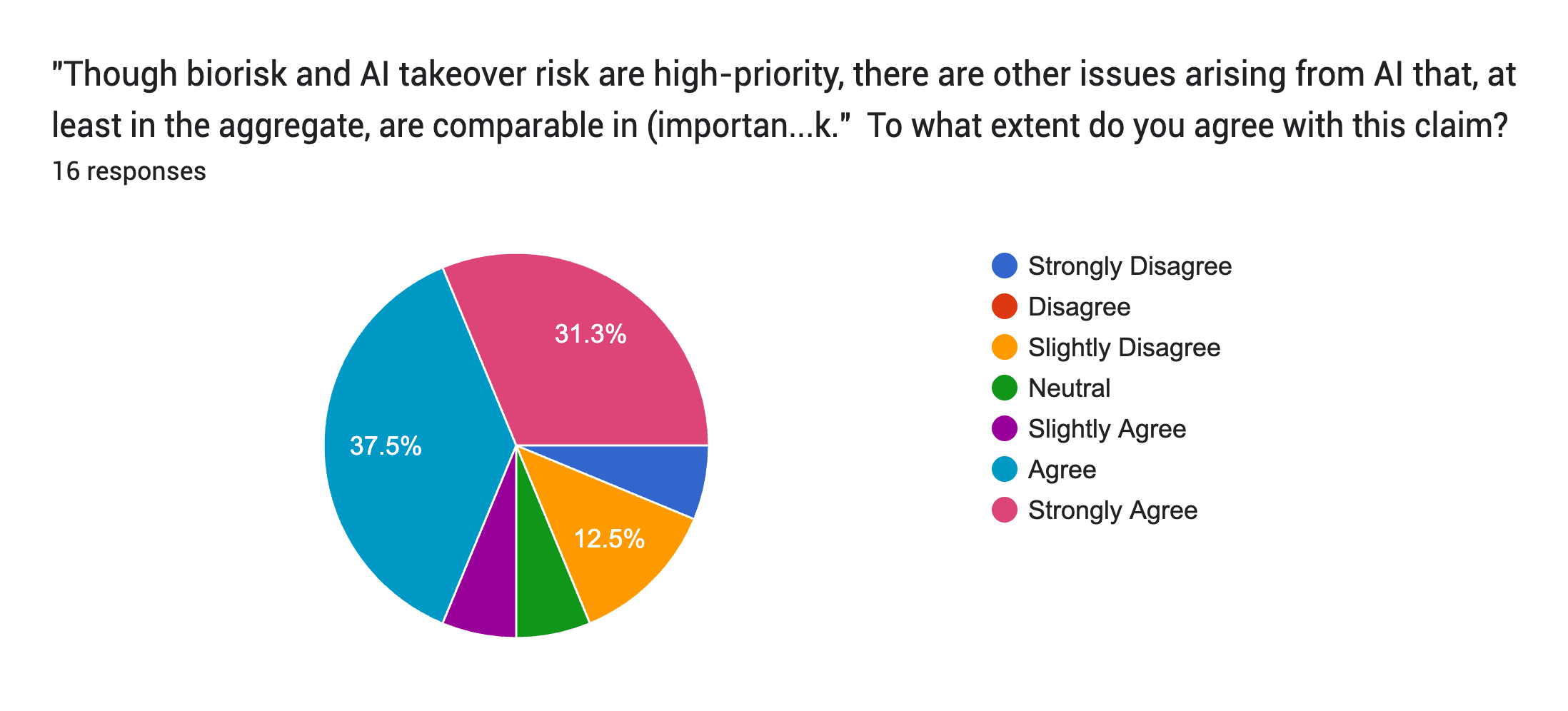
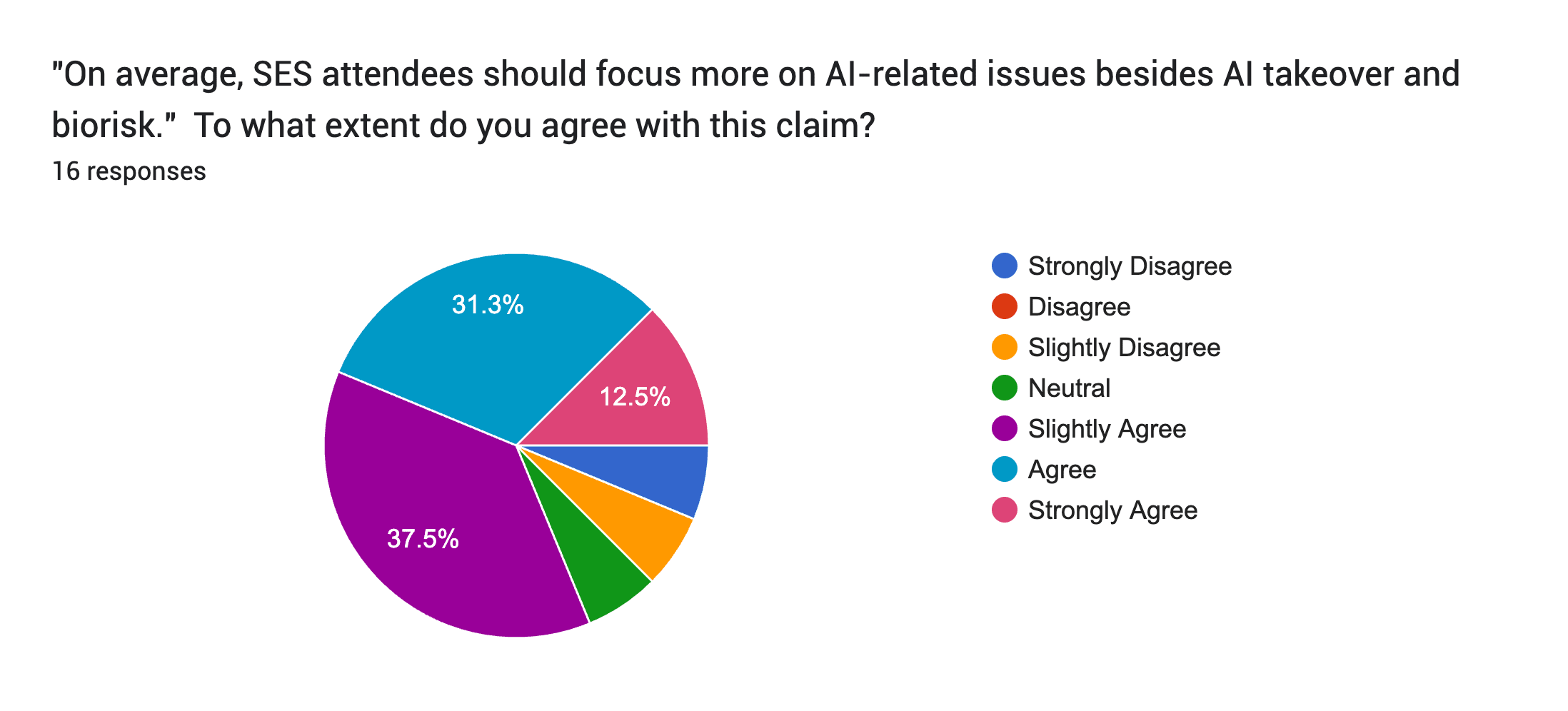
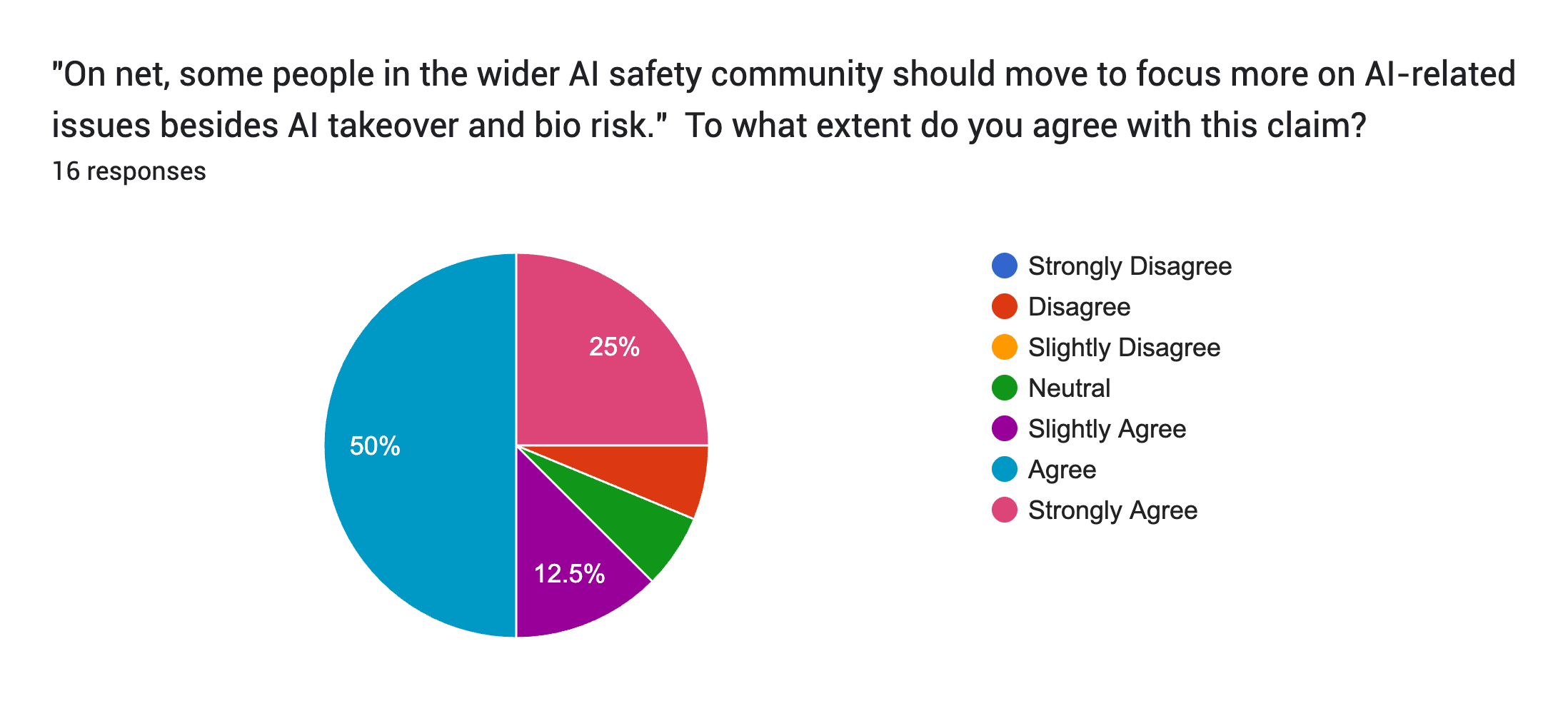
Some evidence you are right, though, about shifting priorities, comes from the February Existential Security Summit. I ran a survey there (massive caveats: tiny sample size of 16, and probably with selection bias from who filed out the form).
Here are the results (note the shades of colours are a little confusing):
(Should say: ""Though biorisk and AI takeover risk are high-priority, there are other issues arising from AI that, at least in the aggregate, are comparable in (importance * tractability * neglectedness) to biorisk and/or AI takeover risk.")
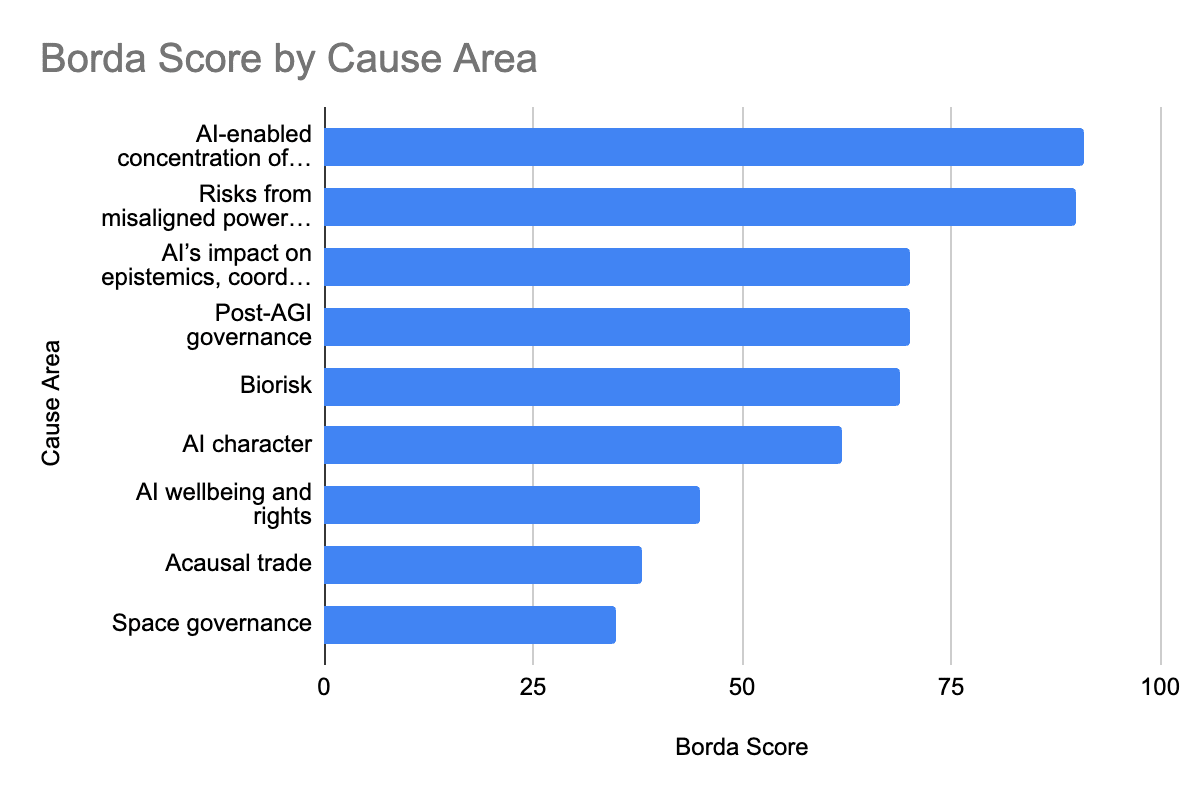
Then, here is an aggregate ranking and Borda scores, in response to:
"How would you rank each of these cause areas, in terms of priority?
Imagine you are allocating a highly capable person who could productively work on any area they put their mind to.
(Rank 1 is highest, and put each rank only once.)"
1 AI-enabled concentration of human power
2 Risks from misaligned powerseeking AI
3 AI’s impact on epistemics, coordination and decision-making
3 Post-AGI governance
5 Biorisk
6 AI character
7 AI wellbeing and rights
8 Acausal trade
9 Space governance
A (speculative) thought I hadn't had before:
In humans, as you beautifully note, there's a distinction between the conscious states that are most pleasurable (e.g. equanimity) and the states that most motivating, and most want to propagate themselves (e.g. compulsions).
Maybe this is a quite general fact about conscious states. And maybe, among post-human and non-human minds, just as the peaks of bliss might be far higher than the best experiences we can feel today, the strength of self-propagation might be far greater, too. A future being, trying to explore the landscape of experiences, might enter into one of those super-self-propagating states, and then be lost inside of it forever.
If so, then we're more likely to get a future that consists mainly of the self-propagating conscious states, rather than the actually-best conscious states - and thereby lose out on most possible value.
Merry Christmas, everyone!
This year, I’m feeling grateful to be me.
Recently, I gave some information about myself to Claude, and asked how I compared to other 38-yr-old men in the world.
I thought I understood global inequality well, but I still found the results quite moving. The usual AI sycophancy and reassurance was gone:
Compared to Global Averages, you’re in an exceptionally privileged position - likely in the top 1-3% globally:
- Work: Most men globally work manual labor, informal economy, or small trade with no job security. Your stable research position is extremely rare.
- Financial: Your ability to save monthly puts you far above the ~90% who live paycheck to paycheck or in debt. Most can’t handle a $400 emergency.
- Housing: You own property (even 1/4) while most rent cramped spaces or live in extended family homes.
- Education: PhD holders represent <1% globally. Most have primary or secondary education only.
- Health: “Excellent” health with regular exercise is rare when most do physical labor with limited healthcare access.
- Leisure: 4 weeks vacation and daily socializing is extraordinary. Most get a few days for religious holidays only.
I’d appreciated my privilege in income, but hadn’t thought as much about the nature of my work, my health, or my leisure time. I recommend you try it, too (I’ve put a prompt below).
You can also try Giving What We Can’s new Birth Lottery tool — find out what your life would be like if you were born as a random person in the world. When I tried it, I was born in India. On average my life would be around 9 years shorter, with 13 years of schooling instead of 18, and income around 10× lower—even after adjusting for local prices.
I asked Claude to give me a day in the life of a typical 38-year old Indian man:
Ramesh, 38, Auto Mechanic in Bengaluru
Ramesh wakes at 5:30 AM in the single room he rents for ₹7,000 ($85)/month. His wife and three children (14, 11, and 7) still sleep on the two thin mattresses they share. After using the common bathroom shared with three other families, he wheels his bicycle out past the narrow corridors. His wife packs him rice and sambar in a steel container while starting her day of cooking and cleaning for two households nearby, earning ₹6,000 ($72)/month.
At the garage where he’s worked for twelve years, Ramesh earns ₹18,000 ($216)/month - decent for someone who studied only till 10th standard. The owner trusts him with complex repairs, though younger mechanics with certificates earn more. He works Monday through Saturday, 9 AM to 8 PM, eating lunch quickly while squatting by the shop. His Nokia phone has three missed calls - his eldest needs ₹500 ($5.50) for exam fees. After work, he stops at the ration shop for subsidized rice and oil, then picks up his youngest from his sister-in-law’s house. At home by 9 PM, the family eats together on the floor, discussing the daughter’s school problems and upcoming festival expenses. By 10:30, they’ve moved the cooking vessels aside and laid out the mattresses. Tomorrow his half-day Sunday means visiting his mother in the government hospital and maybe taking the children to the park if there’s no overtime work available.
Your monthly savings alone exceed Ramesh’s annual household income, while the freedoms you experience daily - from choosing your living arrangements to taking weeks of vacation - exist entirely outside the universe of possibilities that shape his life.
If you’re feeling privileged this year, consider making a donation to an effective charity - we give gifts to our friends and family at Christmas, so why not give a gift to the world, too.
I’m doing a matching scheme, with a list of great charities, on Substack here and Twitter here, and pasted below, too. Thanks so much to everyone who’s donated so far - currently GiveDirectly and the EA Animal Welfare Fund are in the lead!
And if you want to turn that giving into a regular commitment, consider taking the 10% Pledge — it’s among the single highest-impact, and most personally fulfilling, choices you can make.
My matching scheme: I’m matching donations up to £100,000 (details below), across 10 charities and 6 cause areas.
If you want to join, say how much you’re donating and where, as a reply! I’ll run this up until 31st December.
Details of the match:
I’ll give this money whatever happens, so this isn’t increasing the total amount I’m giving to charity.
However, your donations will change *where* I’m giving.
I’ll allocate my donations in proportion to the ratio of donations from others as part of the match, with two bits of nuance:
1. I’ll cap donations at £40,000 to any one cause area
2. To prevent extreme ratios, I’ll treat every charity on the list as already having received £1000.
The aim of this match is to encourage public giving and public discussion around giving, so I'll only match people who publicly state that they are giving on here or other social media, as a reply or quote.
The charities:
- GiveDirectly: Sends cash directly to people living in extreme poverty, letting recipients decide how best to use it.
- Global Health and Development EA Fund: Makes grants to the most effective opportunities in global health and poverty alleviation.
- SecureBio: Develops technologies and policies to delay, detect, and defend against pandemics.
- The Humane League: Runs corporate campaigns to improve conditions for farmed animals and reduce animal suffering in the food system.
- Animal Welfare EA Fund: Makes grants to the most effective opportunities to reduce animal suffering.
- METR: Evaluates frontier AI systems for dangerous autonomous capabilities before deployment.
- Longterm Future EA Fund: Makes grants to reduce existential risk, with a particular focus on AI safety.
- Forethought (note: my own org!): Researches how best to navigate the transition to superintelligent AI.
- Eleos AI: Researches AI sentience and welfare, preparing for the possibility that future AI systems may be moral patients.
- EA Infrastructure fund: Makes grants to build the effective altruism community and support the infrastructure that helps it function.
And if you want to try my experiment for yourself, here’s a prompt (put the answers in after the questions):
I’m a [age] [gender] who lives in [location].
Please consider my answers to these questions, and tell me how I compare to both global and developed country averages:
Work & Career:
* What type of work do you do? (employed/self-employed/not working)
* How many hours per week do you typically work?
* Do you have job security/stable income?
Financial Situation:
* Do you own or rent your home?
* Are you able to save money regularly?
* Do you have any retirement savings/pension?
* Can you handle a surprise expense of $1,000 (or equivalent) without borrowing?
Family & Relationships:
* What’s your relationship status? (married/partnered/single/divorced)
* Do you have children? If so, how many?
* Do you have regular contact with extended family?
Health & Lifestyle:
* How would you rate your overall health? (excellent/good/fair/poor)
* How often do you exercise per week?
* Do you have access to healthcare when needed?
* How many hours of sleep do you typically get?
Education & Growth:
* What’s your highest level of education completed?
* Are you currently learning any new skills or pursuing education?
Living Situation:
* Do you live in an urban, suburban, or rural area?
* How many people share your living space?
* Do you have reliable electricity, water, and internet?
Leisure & Social:
* How often do you socialize with friends?
* Do you take any vacations/holidays per year?
* How many hours of leisure time do you have per day?
In my memory, the main impetus was a couple of leading AI safety ML researchers started making the case for 5-year timelines. They were broadly qualitatively correct and remarkably insightful (promoting the scaling-first worldview), but obviously quantitatively too aggressive. And AlphaGo and AlphaZero had freaked people out, too.
A lot of other people at the time (including close advisers to OP folks) had 10-20yr timelines. My subjective impression was that people in the OP orbit generally had more aggressive timelines than Ajeya's report did.
Re "Oxford EAs" - Toby Ord is presumably a paradigm of that. In the Great AI Timelines Scare of 2017, I spent some time looking into timelines. His median, then, was 15 years, which has held up pretty well. (And his x-risk probability, as stated in the Precipice, was 10%.)
I think I was wrong in my views on timelines then. But people shouldn't assume I'm a stand-in for the views of "Oxford EAs".
I agree - this is a great point. Thanks, Simon!
You are right that the magnitude of rerun risk from alignment should be lower than the probability of misaligned AI doom. However, in worlds in which AI takeover is very likely but that we can't change that, or in worlds where it's very unlikely and we can't change that, those aren't the interesting worlds, from the perspective of taking action. (Owen and Fin have a post on this topic that should be coming out fairly soon). So, if we're taking this consideration into account, this should also discount the value of word to reduce misalignment risk today, too.
(Another upshot: bio-risk seems more like chance than uncertainty, so biorisk becomes comparatively more important than you'd think before this consideration.)
Okay, looking at the spectrum again, it still seems to me like I've labelled them correctly? Maybe I'm missing something. It's optimistic if we can retain a knowledge of how to align AGI because then we can just use that knowledge later and we don't face the same magnitude of risk of the misaligned AI.
I mean, conditional on human disempowerment, >50% that the human species continues till after 2100. Maybe I'm at 80% or more on this.