I was interested in this because I’m broadly sympathetic to the idea that we might not give enough attention to bigger systems. But for me, this post only really strengthened my EA tendencies.
So the core argument in favour of the metacrisis being ‘a thing’ (upon which the later arguments that we should take it seriously hang) seems to be:
a. Technology makes us more powerfu and the world is more interconnected
b. As a result, our capacity for self destruction has massively increased
c. Our ‘culture, the implicit assumptions, symobls, sense-making tools and values of society’ are not ‘mature’ enough to ensure this capacity is managed in a low risk manner
d. Therefore, some kind of existential risk is more likely
Propositions A and B seem basically correct to me. But I think proposition C is very weak. I have two main problems with it:
1) there is just so many different things inside of that grouping, the article only makes an argument as to why a set of implicit assumptions are a cause of the problem, then sneaks in all this other stuff in this one central paragraph. It seems highly likely to me that some things (like society's values) are more important to how well the world goes than others (like symbols)
2) I think C stands to be proved. While there are many problems with society and global coordination, it seems like often at the crunch global coordination pulls through (nuclear proliferation, chemical weapons and CFCs are examples). I think you can make an argument we don’t have the right tools, but I think equally you can make at least as strong an argument to say that we know exactly what the right tools are and we should be putting our efforts into strengthening global institutions of coordination.
I think the Diego character makes a number of other mistakes which I’m not sure are necessarily core to the argument, but certainly weaken my sense of its credibility for me:
The idea that system change is intractable is just an intuition - this clearly isn’t true. If we look at successful social movements, they consistently work through breaking problems down and taking them one at a time. This ends up looking like systems change eventually because it can lead to paradigm shifts, but these shifts only come later on as an accumulation of smaller wins (some examples would be the abolition of slavery, LGBT rights, universal suffrage in the UK). We can also point to plenty of folk talking about how everything is connected and getting no where at all. So the claim 'system change is not tractable' may not be correct, but it is clearly based on more than mere intuiton.
The idea that rivalry (caused by human nature) is a background assumption and not necessarily the case: the point here surely is that, yes of course humans can be more or less cooperative at times and given different cultural assumptions, but this kind of game theory describes dynamics that are independent of how most people behave. It only takes a small number of people to act in a rivalrous or antisocial manner for things to become bad, given we can't rule out that someone will behave in this way, we have to respond accordingly.
The argument that we ‘diefy’ technology and assume wealth is always good: this is almost straying into ‘degrowther’ territory. Technology is the primary driver of increased productivity and therefore a key part of driving growth. Growth has historically been the single biggest driver of human welbeing. While I’m in favour of redistribution, I think we have to be realistic that simply stopping growth and improving people’s lives soley through redistribution would be politically impossible. It also places a celling on possible human wellbeing and so is plausibly much much worse than a world of high, sustainable growth.
The idea that the notion of the perfect/wellfunctioning market is rarely questioned: obviously not true, this is a hugely contested idea
(This is a small one): Modernity has led to the mental health crisis: I’m just not sure this empyrically stacks up. It is really hard to measure mental health over time, given that its measurement is so culturally contingent (among other things)
The argument that we know eventually civilisation will collapse because all previous civilisations have collapsed: this feels like a very ‘cakeism’ style argument, you can’t have it both ways. Either it is the case that the history of all these very different societies shows the inevitability of our eventual destruction (in which case it seems that changing our culture isn’t going to help) or culture is the key to our doom (in which case all these other cultures being destroyed can't be evidence about our own culture because the key variable is different)
Tractability is surprisingly high: how can you possibly assess the tractability of this problem when - in your own words - you have no idea what the problem is? Compare this to wild animal suffering (as Diego does): in wild animal suffering we have a clearly defined problem: lots of animals suffer a lot and this is bad. We have some solutions that actually seem very good, like getting rid of screw worms. There are some empirical frameworks we can use to assess the problems and make decisions, and we can at least in some cases run experiments to gain a better understanding. This all seems like much more progress towards tractable solutions than this metacrisis thing
Cultural change is actually happening very fast: Diego is using culture in two almost entirely different ways. First that its about our underlying paradigm for seeing the world to argue that culture is this deep seated root problem (for most of the article) then in this thin way about changing cultural artefacts or taste to argue that it changes very quickly. These are obviously two different propositions and one can’t be used to argue the other.
I like the idea of doing more thinking through Socratic dialogues and there were a couple of jokes here which actually made me laugh out loud. But it has left me closer to thinking this integral/metacrisis thing is lacking in substance. Putting this author aside, it seems like many of the folk who talk about this stuff are merely engaging in self-absorbed obscurantism.
In my response to this, I really want to avoid this vibe of “you just don’t understand” or “you need to wake up” and all that kind of thing. I know how annoying and unproductive that kind of response can be. In what I write below I’m not trying to just assert that my position is obviously more right, if only you could see through the matrix. I’m interested in clarifying the metacrisis position/how metacrisis folk think, as maybe if it becomes clear enough it will no longer seem obviously stupid to you!
That being said, the standard metacrisis-y response to most of what you’ve said here would be to try and pick apart the (modernist-y) assumptions that might lie underneath it. Being contextualizing isn’t just about awareness of the context of the system you’re studying, but also the context of your own mind/rationality/beliefs – all the quite deep assumptions driving those beliefs that work well in a number of contexts (like building bridges, training LLMs, or saving kids from malaria) but might not generalize as well as you think to statements about a rapidly evolving and highly interconnected world.
I’ll pick out a couple of examples to pick on from your comment:
> Modernity has led to the mental health crisis: I’m just not sure this empirically stacks up. It is really hard to measure mental health over time, given that its measurement is so culturally contingent
I want to pick on this because I think it’s a good example of what the vibey crowd like to call “scientism”, which in my head means something like the view that “the only possible way to know something to be true is if it’s published in a peer-reviewed journal”. That is obviously one of the most reliable ways to know something is true, but it limits your toolkit for making sense of the world.
In the case of modernity leading to a mental health crisis: yes, you’re right that it’s a very hard thing to measure, and therefore no signal has been found by any study. But when you include lived experience… I don’t know man, it just feels so true, at least in some sense, from my own life and the lives of so many around me. For example, there’s no signal that shows that social media can mess up teenagers’ mental health, but this exchange we’re having in the comments of the EA forum is making my muscles tense and my mind race, and when I extrapolate this to being a teenager and dealing with high stakes things like how I look or who fancies me, this is some good evidence for that causation in my book.
Sometimes I think of EA as the “analytical philosophy of changemaking” while metacrisis is the “continental philosophy of changemaking”, since in analytical philosophy something is true because you can prove it to be true, while in continental philosophy something is true because it feels true. We need both.
> Growth has historically been the single biggest driver of human welbeing.
So… how are you defining human wellbeing here? In terms of stuff you can measure (life expectancy, economic prosperity, etc), yea there’s no argument, you’re right. But all the other things that contribute to a broader definition of wellbeing? Community, meaning, connection to nature, etc? Wellbeing is a complex beast. I don’t have the arguments or the data to say you’re wrong, but you’re saying it here without any argument as if this is obviously right.
You may well be right even in the broader sense of the word wellbeing, but a metacrisis person might also say that once you’ve optimised hard enough for economic growth, goodhart’s law bites you in the arse and growth starts to decorrelate from wellbeing. Some might argue that that is starting already (see, for example, Scandinavia scoring best on various happiness metrics while having a smaller economy than, say, the US).
To reiterate something I said in the post, I’m aware that if you’re constantly questioning everything and constantly having to keep all the mystery of the definitions of all your terms you’re using in your attention, you’ll never get anything done. Getting things done is good. But if you commit to some metric and then never revisit the assumptions behind it, you might find yourself getting the wrong things done when your optimisation pushes the world out of the regime in which your metric makes sense.
> The idea that rivalry (caused by human nature) is a background assumption and not necessarily the case: the point here surely is that, yes of course humans can be more or less cooperative at times and given different cultural assumptions, but this kind of game theory describes dynamics that are independent of how most people behave.
This feels like a statement about the strength & generality of game theory when applied to humans on various scales. The metacrisis nerds would probably try to poke at how much confidence you have in game theory to support the claim that rivalry will always arise. This kind of background acceptance in game theory has a modernist vibe.
Anyway, I don’t expect I’ve changed your mind on any of this, which is fine! Even if we don’t agree it’s good to more deeply understand each other’s position. Ok bye
Thanks for responding to my points! You didn't have to go through line by line, but its appreciated.
Obviously a line by line response to your line by line response to my line by line response to your article would be somewhat over the top. So I'll refrain!
The general point I'd make though is that this almost feels like an argument for something before you've decided what you want to argue for. There feels like a conceptual hole in the middle of this piece (as you say, people are still trying to work out what the problem is). But then you also respond to most of (not all) my points without actually giving a counter-argument, just claiming that I'm clearly mistaken. This makes it quite hard to actually engage with what you've written.
Maybe, as Alexander seems to think, I'm just a poor blinkered fool who can't understand other people's perspectives - but I am actually tryign to engage with what you've written here, not sh*t posting.
Obviously a line by line response to your line by line response to my line by line response to your article would be somewhat over the top. So I'll refrain!
Yes we could waste our lives falling down a hole here.
But then you also respond to most of (not all) my points without actually giving a counter-argument, just claiming that I'm clearly mistaken.
Huh. I must have messed up the tone of my last message because that wasn't the intention at all. For some of my responses I thought I was basically agreeing with you, and others I was clarifying what I (or rather Diego) was trying to say rather than saying you are wrong.
[This comment is no longer endorsed by its author]
> But it has left me closer to thinking this integral/metacrisis thing is lacking in substance. Putting this author aside, it seems like many of the folk who talk about this stuff are merely engaging in self-absorbed obscurantism.
I wonder if this statement might simply reflect your ability to understand and steelman other people's perspectives. Food for thought?!
Thanks for writing this! I'm broadly sympathetic to Thom's critique, but thought this was impressively well written and good at engagingly/non-annoyingly conveying a different perspective, so kudos. I would love to see more posts in that genre.
I think it did a good job of explaining why the metacrisis might be relevant from an EA standpoint (the dialogue format was a great choice!). I made a similar (but different) argument - that Less Wrong should be paying attention to the sensemaking space - back in 2021[1] and it may still be helpful for readers who want to get better sense of the scene[2].
Unfortunately, I'm with Amina. Short AI timelines are looking increasingly likely and culture change tends to take a long time, so the argument for prioritising this isn't looking as promising as it previously did[3]. It's a shame that some of these conversations didn't start happening a decade or two earlier than they did. Some of these conversations could have been great for preparing the (intellectual) soil and it could have provided motiviation for working on generally useful infrastructure at the point in time when it made sense to be doing that.
Another worry I have about the metacrisis framing is that it, by default, it seems to imply that we should think of all these threats as being on par, when that increasingly doesn't seem to actually be the case.
Amina: This all feels impenetrable to me. They use a bunch of jargon and a lot of it sounds floaty, vague or mental. Diego: Yea I get that too. It reminds me of how I felt the first time I encountered EA.
I felt this response leaned a bit popularist. I think it's pretty clear that conversation in sensemaking space is much less precise than EA/rationality on average. The flip side of the coin is that the sensemaking space is open to ideas that would be less likely to resonate in EA/rationality. Whether this trade-off is worth it comes down to factors like how valuable these ideas tend to be, how valuable it is to avoid incorrectly adopting confused beliefs vs. incorrectly rejecting fruitful ideas and the purpose of the movement.
FWIW, I was a lot more positive on the sensemaking space back in the day, now I'm a lot more uncertain. I think there's a lot of fruitful ideas there, but I'm not convinced that the scene has the tools that it needs to identify which ideas are or aren't fruitful.
This helped clarify things a bit, thanks -not the least because I've interacted with some of you lately.
I'm still mostly skeptical because of the amount of implicit conjunctions (a solution that solves A & B & C & D & E seems less plausible to exist than several specialised solutions), how common it is for extremely effective ideas to be specialised (rather than the knock-on result of a general idea) and the vague similarity with "Great Idea" death spiral traits. All of this said, I'm in favor of keeping the discussion open. Fox mindset rules.
For those who need clarification, I think I understand four non-exclusive example avenues of what "solving the metacrisis" looks like (all the names are 100% made-up but useful for me to think about it):
1-"Systemism" postulates the solution has to do with complex system stuff. You really want to solve AI X-risk ? Don’t try to build OpenAI, says the systemist, instead, do :
1.1-One gigabrained single intervention that truly addresses all the problems at the same time (maybe « Citizen Assemblies but better »)
1.2-A conjunction of interventions that mutually reinforces each other in a feedback loop (maybe « Citizen Assemblies » + « UBI » + « Empowerment in social help »)
Will this intervention solve one or all problems ? Again, opinions diverge :
1.3-Each intervention should solve one problem -a bigger one, and to a better extent, than conventional solutions.
1.4-This intervention should solve all the problems
1.5-The intervention should solve one problem, but you can « copy-paste » it, it has high transferrability.
2-"Introspectivism" postulates the solution has to do with changing the way we relate to ourselves and the rest of the world. You really want to solve AI X-risk ? Again, don’t build OpenAI, but go meditate, learn NVC, use Holacracy.
3-"Integralism" postulates the solution is to incorporate criticism of all different paradigms. You really want to solve AI X-risk ? Make your plans consistent with Marxism, Heidegerian Phenomenology and Buddhism, and you’ll get there.
4-"Culturalism" postulates that cultural artifacts (workshops, books, a social movement, and/or memes in general) will suceed to change how people act and coordinate, such that reducing X-risks becomes feasible. Don't try to build OpenAI, think about cultural artifacts -but not books about AI Risk, more like books about coordination and communication.
Separately, I think discussing disagreements around the meta-crisis is going to be hard.
Why? I think that there is a disparity in relevance heuristics among EA and... well, the rest of the world. EA has analytical and pragmatic relevance heuristics. "Meta-crisis people" have a social relevance heuristic, and some other streams of thoughts have a phenomenological relevance heuristic.
Think Cluster Headache. I think many people attempted to say that Cluster Headaches could matter a big deal. But they said stuff we (or at least, I) didn't necessarily understand, like "it's very intense. You become pain. You can't understand". Then decades later, someone says "maybe suffering is exponential, not linear, and CH is an intensity where this insight is very clear". And then (along with other numerate considerations) we progressively started caring (or at least, I started caring).
All these systems can communicate with EA if and only if they succeed to formalize / pragmaticize themselves to some degree, and I personally think this is what people like Jan Kulveit, Andres G. Emilsson, or Richard Ngo are (inadvertently ?) doing. I'd suggest doing this for meta-crisis (math > dialogues) otherwise people may backfire.
I'm coming in with a cleaner-adjacent perspective.
I have many friends who espouse many of these ideas. They talk about systems level change. They talk about the challenge of imagining anything outside of the current paradigm. They talk about non-zero sum approaches, they talk about moving beyond competition. They talk about economic growth being a poor measure of utility.
They don't call themselves "metacrisis" people, though, and they don't see their enemy as "modernity".
They call themselves anarchists and they see capitalism as the enemy.
That sounds like I'm putting your argument down - I'm not. Anarchism is poorly defined and so often misunderstood and I don't think it actually has the answers.
But I don't think the concept of the metacrisis is preparadigmatic - I think so many of concepts are there within the anarchists, anticapitalists, post modernists or critical theorists. And at the same time many of the concepts and the challenges are also there in the underpinnings of populism and authoritarianism.
As far as I can see, the metacrisis an issue of systems of power which do not deliver optimal outcomes. This is by no means a preparadigmatic problem. It's not a problem we've solved, but let's not pretend it's a new concept.
Thanks for sharing this! It's an entertaining read and a valuable reminder of the limits of our perspectives. I love how the cleaner shows up at the end. True koan vibes!
Executive summary: Through a fictional yet philosophically rich dialogue, the post explores the idea that existential risks like AI doom are not just technical challenges but symptoms of a deeper “metacrisis”—a mismatch between the accelerating power of our technologies and the immaturity of our cultural and societal systems—arguing that the Effective Altruism movement should include this systems-level lens in its epistemic toolkit, even if the path forward is speculative and the tractability uncertain.
Key points:
Hopelessness in AI safety stems from systemic issues, not just technical difficulty: The conversation between Amina and Diego illustrates that AI alignment efforts, while vital, may be insufficient due to external forces like corporate races, shareholder pressure, and political gridlock.
Effective Altruism’s “decoupled” problem-solving mindset may limit its scope: Diego critiques EA’s tendency to abstract and isolate problems from their broader social and cultural context, suggesting that this framing can miss key drivers of existential risk.
The “metacrisis” is proposed as a root cause of x-risk: Diego introduces the idea that existential risks arise from a deeper cultural mismatch—our technological powers have outpaced our society’s collective wisdom and coordination capacity.
A parallel movement focused on systems thinking is emerging: Diego highlights a loosely affiliated cluster (called the “metacrisis movement”) that values interconnectedness, culture, and paradigm-level change, distinguishing it from EA’s marginal and analytical focus.
The metacrisis may be a high-impact but low-tractability cause area: Using EA’s scale-neglectedness-tractability framework, the post argues the metacrisis is massive in scale and underexplored, though challenging to address—potentially justifying early investment in clarifying the problem.
Recommendation: broaden the EA epistemic toolkit: Rather than replacing existing EA priorities, the post suggests integrating metacrisis-informed perspectives as a complementary lens to diversify worldview assumptions and enhance decision-making across cause areas.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, and contact us if you have feedback.
I’ve developed what I call a “course” which in my humble opinion answers the questions posed in this article. It examines the root cause of the metacrisis and the race to the bottom, which is also referred to as the tragedy of the commons or “moloch”. My course offers up the best way in which we as a species should try to change our mindset in order to give ourselves the best chance at immediate, intermediate and long term survival. As alluded to in this article or story, from a philosophical standpoint, the same “teachings” and “understandings” which will be required for us to wrestle with, come to grips with and use to overcome the old school problems, or metacrisis, are the same as those which will be required to try to train AI so that it is aligned with that which is in the most beneficial long term interests of the human race as a species.
Because so far, all civilisations destroy themselves eventually. Human history is basically a story of civilisations forming, being stable for a short time, and collapsing. The Babylonians, the Romans, the Mongols, the Ottomans. They all fell.
The entities that collapsed would be more accurately described as states/dynasties, not civilisations. These were not human settlements that just vanished. Some fell to external pressures, or at least had their stresses exacerbated by them.
They all fell. But when they fell it wasn’t the end of humanity, because they were just local collapses.
It wasn't the end of humanity because they were replaced by their human local competitors/internal revolts. The collapse of Rome may have been followed by a sustained economic regression in the region but I don't think the same can be said of the others.
For any civilisation/state there are only two possible outcomes
Collapse before being integrated into the current modernist/globalist system
Survive long enough to be integrated into the globalist system
(Excluding the few states/civilisations that went about creating the current system)
There were states/civilisations that collapsed on contact with the globalist system which could be classified under 1 or 2(you could also classify integration as collapse).
tl;dr The assertion that 'all civilisations eventually destroy themselves' is very loadbearing and I think needs quite a bit more support, because
The examples you cite involve human states/dynasties being replaced by other human states/dynasties and not civilisational collapse
There are examples of states/dynasties that have survived to become a part of the modern interconnected civilisation, which is the only other possibility apart from collapse
In her office nestled in the corner of constellation, Amina is checking in with her employee Diego about his project – a new AI alignment technique. It’s 8pm and the setting sun is filling Amina’s office with a red glow. Diego is clearly running a sleep deficit, and 60% of Amina's mind is on a paper deadline next week.
1: Hopelessness
Diego: I’m feeling quite hopeless about the whole thing.
Amina: About the project? I think it’s going well, no?
Diego: No, I mean the whole thing. AI safety. It’s so hard for me to imagine the work I’m doing actually moving the p(doom) needle.
Amina: This happens to a lot of people in the bay. There are too many doomers around here! Personally I think the default outcome is that we won’t get paperclipped, we’re just addressing a tail risk.
Diego: That’s not really what I mean. It’s not about how likely doom is… I’m saying that I’m hopeless about some alignment technique actually leading to safe AGI. There are just so many forces fighting against us. The races, the e/accs, the OpenAI shareholders…
Amina: Oh man, sounds like you’re spending too much time on twitter. Maybe it’ll help for us to explicitly go through the path-to-impact of this work again?
Diego: Yea that would be helpful! Remind me what the point of all this is again.
Amina: So, first, we show that this alignment method works.
Diego: I still have this voice in the back of my head that alignment is impossible, but for the sake of argument let’s assume it works. Go on.
Amina: Maybe it’s impossible. But the stakes are too high, we have to try.
Diego: One of my housemates has that tattooed on her lower back.
Amina’s brain short-circuits for a moment, before she shakes her head and brings herself back into the room.
Amina: R-right… Anyway, if we can show that this alignment method works, Anthropic might use it in their next model. We have enough connections with them that we can make sure they know about it. If that next model happens to be one who can, say, make a million on the stock exchange or run a company, then we will have made it less likely that some agent based on that model is going to, like, kill everyone.
Diego: But what about the other models? Would GPT and Gemini and Grok and DeepSeek and HyperTalk and FizzTask and BloobCode use our alignment technique too?
Amina: Well…
Diego: And what about all the other open-source models that are inevitably going to crop up over the next couple of years?
Amina: Eeeh
Diego: In a world where our technique is needed to prevent an AI from killing everyone, even if we get our alignment technique into the first, second, or third AGI system, if the fourth doesn’t use our technique, it could kill everyone. Right?
Amina: You know it’s more complicated than that. If there are already a bunch of other more-or-equally powerful aligned agents roaming around, they will stop the first unaligned one from paperclipping everyone.
Diego: Sure, maybe if we align the first ten AGIs, they can all prevent the eleventh AGI from paperclipping everyone.
But can we really align the first handful of AGIs, given the way the world looks now? At first I had the impression that OpenAI cared about safety at least to an extent. But look at them now. They’ve been largely captured by the interests of their investors, and they’re being forced to race other companies and China. They aren’t just a bunch of idealistic nerds who can devote their energy to making AGI safe anymore.
Amina: We always knew race dynamics would become a thing.
Diego: And doing research on alignment doesn’t stop those dynamics.
Amina: Yes, alignment doesn’t solve anything. That’s why we have our friends in AI governance, right? If they can get legislation passed to prevent AI companies from deploying unaligned AGI, we’ll be in a much better position.
Diego: And how do you think that whole thing is going?
Amina: Oh cheer up. Just because SB 1047 failed doesn’t mean we should just give up and start building bunkers.
Diego: But don’t you get the feeling that the political system is just too slow, too stubborn, too fucked to deal with a problem as complex as making sure AI is safe? Don’t you get the feeling that we’re swimming against the tide in trying to regulate AI?
Amina: Sure. Maybe it’s impossible. But the stakes are too high, we have to try.
Diego: Oh, I also have another friend I met at burning man who has that tattooed on his chest.
Amina: You have a strange taste in friends…
Diego: Anyway, it all feels pretty impossible to me. And that’s even before we start thinking about China. And even if all AGI models end up aligned, can we really allow that much power to be in everybody’s hands? Are humans aligned?
Amina: That’s going to happen no matter what Diego. Technology will continue to improve, the power of the individual will continue to grow.
Diego gets up from his seat and stares out the window at the view over to San Francisco.
Diego: You know, when I first heard about the alignment problem I was so hyped. I’d been looking for some way to improve the world. But the world seemed so confusing, it was so hard for me to know what to do. But the argument for AI safety is so powerful, and the alignment problem is such a clean, clear technical problem to solve. It took me back to my undergrad days, when I could forget the complexity of the world and just sit and work through those maths problems. All I needed to know was there on the page, all the variables and all the equations. There wasn’t this anxious feeling of mystery, that there might be something else important to the problem that hasn’t been explicitly stated.
Amina: You need to state a problem clearly to have any chance of solving it. Decoupling a problem from its context is what has allowed science and engineering to make such huge progress. You can’t split the atom, go to the moon, or build the internet while you’re still thinking about the societal context of the atoms or rockets or wires.
Diego: Yea, I guess this is what originally attracted me to effective altruism. Approaching altruism like a science. Splitting altruism up into a list of problems and working out which are most important. We can’t fix the whole world, but we can work out what’s most important to fix…
But… is altruism really amenable to decoupling? Is it in the same class as building rockets and splitting atoms? I haven’t seen any principled argument about why we should expect this.
Amina: But this decouply engineering mindset has helped build a number of highly effective charities, like LEEP!
Diego: Ok, so it works for getting lead out of kid’s lungs, but does it work for, like, making singularity go well? It seems unclear to me.
I agree that the arguments for AI risk are strong. Maybe we’re all going to get paperclipped. But can we solve the problem by zooming in on AI development, or do we need to consider the bigger picture, the context?
Amina: AI development is what might kill us right, so it’s what we should be focusing on.
Diego: Well, is it the AI that’ll kill us, or the user, or the engineers, or the company, or the shareholders who pressured a faster release? The race dynamics themselves, or Moloch? There’s a long causal chain, and a number of places one could intervene to stop that chain.
Amina: But aligning the first AGI, with technical work and legislation, is where we can actually do something. We can’t fix the whole system. You can’t slay Moloch, Diego.
Diego raised his eyebrows and locked eyes with Amina
Amina: You can’t slay Moloch, Diego!
Diego: I thought you bay area people are meant to be ambitious!
Amina rolls her eyes
Diego: Perhaps we can come up with some alignment techniques that can align the first AGI. Maybe we can pass some laws that force companies to use these techniques, so that all AGIs are aligned and we don’t get paperclipped. But then technology is going to be moving very fast, and there are a whole bunch of other things that can go wrong.
Amina: What do you mean?
Diego: There will be other powerful technologies that bring new x-risks. When anyone can engineer a pandemic, will we have to intervene on that too? When anyone can detonate a nuclear bomb, will we be able to prevent everyone from doing it? I suppose we could avoid this with a world government who surveils everyone to prevent them detonating, but I don’t think I want to live in that world either.
Amina: We’ll just have to cross those bridges when we come to them.
Diego: Will we be able to keep up this whack-a-mole indefinitely? Can EA just keep solving these problems as they come up? If you roll the dice over and over again, eventually you’re going to lose, and we’re all going to die.
Amina: Oh, I guess you’re alluding to the vulnerable world hypothesis. Well, whether or not it’s true, this whack-a-mole is all we can do.
Diego: Is it though? Just continue treating the symptoms? Or can we try to treat the underlying cause. Wouldn’t that be more effective?
Amina: By slaying Moloch? Sure, it would be effective, if it’s possible.
Diego: I’m not interested in slaying Moloch.
Amina: Huh? Then what are you talking about?
Diego: I don’t think we can slay Moloch. But Moloch isn’t the underlying cause, so we don’t have to.
Amina: You’ve lost me now. What is this mysterious deeper cause underlying everything?
Diego: I’m glad you asked.
2: The metacrisis movement
Diego strokes his chin for a while and formulates a way to explain his recently updated worldview, gained from his new group of weird, non-EA friends.
Diego: I have a question for you. Are EAs and rationalists the only people who care about x-risk?
Amina: Uuh… maybe? We’re at least the ones who’ve thought most about it.
Diego: Unclear! There’s actually a different cluster of nerds, outside of EA, who care deeply about x-risk. I think of them a little bit like a parallel movement to EA, but they have quite different ways of making sense of the world, built upon a different language.
Amina: Do they have a name?
Diego: Well, not really. Their community isn’t as centralized as EA. Or maybe it’s actually a number of overlapping communities. I’ve heard them called the liminal, metamodern, game B, or integral movement. But I usually call them the metacrisis movement. There’s a handful of small orgs devoted to spreading the movement and making progress on what they see as the world’s most important problems - life itself, perspectiva, civilisation research institute, and others. I think of them as more pre-paradigmatic than EA, there’s less actually doing stuff and more clarifying of problems.
Amina searches some of the buzzwords Diego threw at her on her computer and scans a couple of pages. She sniggers a little, then sighs in frustration.
Amina: This all feels impenetrable to me. They use a bunch of jargon and a lot of it sounds floaty, vague or mental.
Diego: Yea I get that too. It reminds me of how I felt the first time I encountered EA.
Amina: Point taken. So I guess you can help me out in understanding what these weirdos are banging on about. How is – what’s the wording you used – how they make sense of the world – different to how EAs make sense of the world?
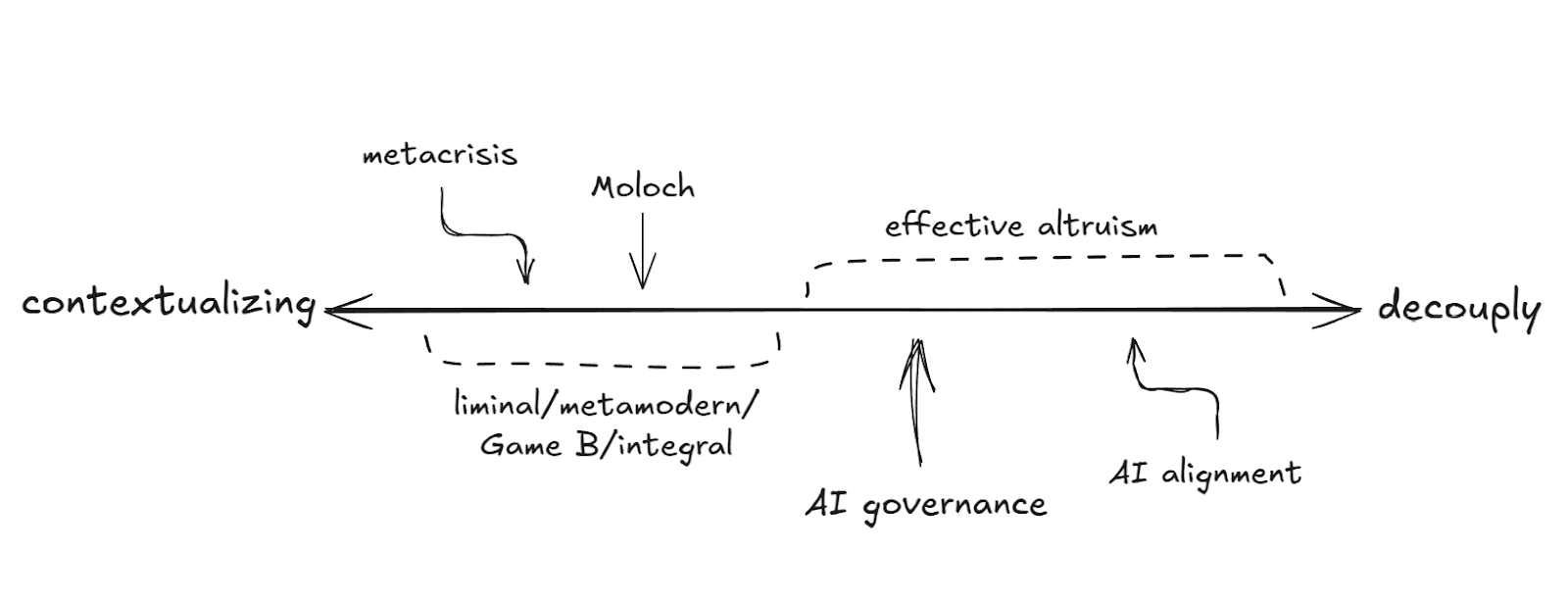
Diego: I see the main way the metacrisis folk are different is that they’re less decouply than EAs. While EAs like to decouple the problem they’re thinking about from its context, metacrisis people are more prone to emphasise the context the problem lives in – be that institutional, societal, cultural or whatever. They’re systems thinkers, they pay more attention to interconnectedness and complexity.
Amina: I’m feeling a bit tense about this going in some political direction. Societal context… are they just leftists? Is the metacrisis just “evil capitalism”?
Diego: Try to suspend judgement until you’ve engaged with the ideas!
Amina: Fair enough. Go on.
Diego: The metacrisis crowd take systems change seriously as a way to improve the world, unlike much of EA. EAs are marginal thinkers, metacrisis folk are systems thinkers.
Amina: Systems change… I can get behind some kinds of systems change, like getting laws passed. But if you’re talking about slaying Moloch, that’s more like changing the structure of governments, or the structure of the world. Deep systems change. That smells intractable to me.
Diego: Is it? Are there principled reasons to think that?
Amina: I did a fermi estimate some years ago…
Diego: And where did the numbers you plugged into that fermi estimate come from?
Amina looks sheepishly at her shoes
Diego: Did they come out of your ass?
Amina: …they came out of my ass. But I have a strong intuition against deep systems change!
Diego: That’s fair enough! EA tends to attract people who have the intuition that deep systems change is intractable. I can’t prove that intuition wrong. But the metacrisis people don’t share that intuition.
Amina: Hmm…
Diego: Look, I don’t want to talk you out of your EA ways. I obviously still have loads of respect for EA and it’s doing a lot right. All I’m asking is for you to entertain a different perspective.
Amina: Ok, that’s a reasonable request. Please continue. What is this metacrisis thing?
Diego: Ok, I’ll tell you. But to explain, let’s go back to the start of our conversation. If AI doom happens, what will cause it?
Amina sighs again and rings her hands in frustration.
Amina: It would be caused by an AI company deploying an unaligned AGI.
Diego: And what causes that?
Amina: Well, lots of things.
Diego: Let’s imagine it’s OpenAI, for example. What would cause OpenAI to deploy an unaligned AGI?
Amina: Race dynamics, I guess.
Diego: And what causes race dynamics?
Amina: I guess that’s a collective action problem. The competition to be the first to get to AGI means all the players need to sacrifice all other values, like not contributing to x-risk.
Diego: Right, Moloch. That’s part of the story for sure. But what causes Moloch?
Amina: Eh… nothing causes Moloch. It’s just game theory. It’s just human nature…
Diego: Is it though? The metacrisis people say that that is part of the problem - this view that rivalry is just human nature, that zero-sum games are the only possible games to play. Those beliefs help keep Moloch alive.
But anyway, Moloch isn’t the whole story. Moloch doesn’t explain why all these different parties want AGI so damn much.
Amina: …because it’s the ultimate technology right? Because it’ll bring whoever controls it almost infinite wealth, and accelerate technology leading to material wealth for all?
Deigo: That’s another part of the problem.
Amina: Huh?
Diego: This deification of technology, this assumption that better technology is always good. And this emphasis on growing material wealth, at the expense of everything else.
Amina: I guess the e/accs would say that only technologies that benefit us will be developed, because of the rational market.
Diego: There’s problem number three. A belief that the market will do what’s right, because humans are rational agents.
Amina: Well, I mean, it’s approximately true, right–
Diego: But not true all the time. Part of the problem is that faith in the market is a background assumption that’s rarely questioned.
Amina: Rarely questioned?
Diego: Ok, it's questioned by some groups. But does it get questioned where it matters, in silicon valley, or in the US government? Not really for the former and not at all for the latter.
Amina: Ok. So I’m hearing that there’s just a whole mess of things causing AI risk. Beliefs that human nature is fundamentally rivalrous, beliefs that technology and material wealth is always good, and belief that markets will solve everything. So the problem is everybody’s beliefs?
Diego: Kindof-but it’s deeper than beliefs. These are more like background assumptions that colour everyone’s perceptions. At least with explicitly stated beliefs we can examine their validity, but this is something deeper.
Amina: Right, so like not explicit beliefs but implicit ways we make sense of the world, or something like that?
Diego: Yea. I’d say the problem is the cultural paradigm we’re in. The set of implicit assumptions, the language, the shared symbols, society’s operating system.
Amina: Does this cultural paradigm have a name? I’ve not done my homework on cultural paradigms…
Diego: Yes, the cultural paradigm of today, basically, is modernity. We’ve been in modernity ever since the enlightenment. The enlightenment created a new emphasis on reason, individualism, scientific progress, and material wealth.
Amina: That all sounds pretty good to me. I guess these metacrisis dweebs think science, technology and the economy are the root of all evil, and that we should go back to being hunter-gatherers?
Diego: No, they don’t think that. They’re very aware that modernity has given us extraordinary growth, innovation and prosperity. Our current cultural paradigm, powered by science and economic growth, has globally doubled life expectancy, halved child mortality, and cut extreme poverty by an order of magnitude. Nobody can deny that these are all great things.
Amina: Ok, I wasn't expecting that. So what’s the problem with modernity? Why does the culture need to change?
Diego: The problem is that we’re racing towards fucking AI doom Amina!
Amina: Oh yea, that thing.
Diego: Modernity isn’t perfect. It’s given us loads of nice things, but at invisible costs.
All that nice prosperity has negative externalities that our culture ignores: climate change, ecological collapse, various mental health crises, and existential risk.
We need to move to the next cultural paradigm.
Amina: Wait, isn’t the next cultural paradigm postmodernity? I’m not into that. The postmodernists seem to think that there is no objective reality. They reject any idea of human progress. If the world goes postmodern, we’d all quit are jobs and just get high. That’s not going to solve anything.
Diego: Yea, I think postmodernism is an overcorrection to the problems of modernism. We need something that both sees the value in technological and material progress, but isn’t so manically attached to that progress that it’s willing to destroy the world to pursue it.
Amina: And what does that look like?
Diego: We don’t really know yet. Well, some people have some ideas. I can tell you about them if you want–
Amina: I have a call soon. And you still haven’t told me what the metacrisis is!
Diego: Oh, sure, sorry I keep going down tangents. I’ve teased you enough, let me tell you what the metacrisis is.
3: The root cause of existential risk
Diego leaps out of his chair and draws a causal diagram on a whiteboard.
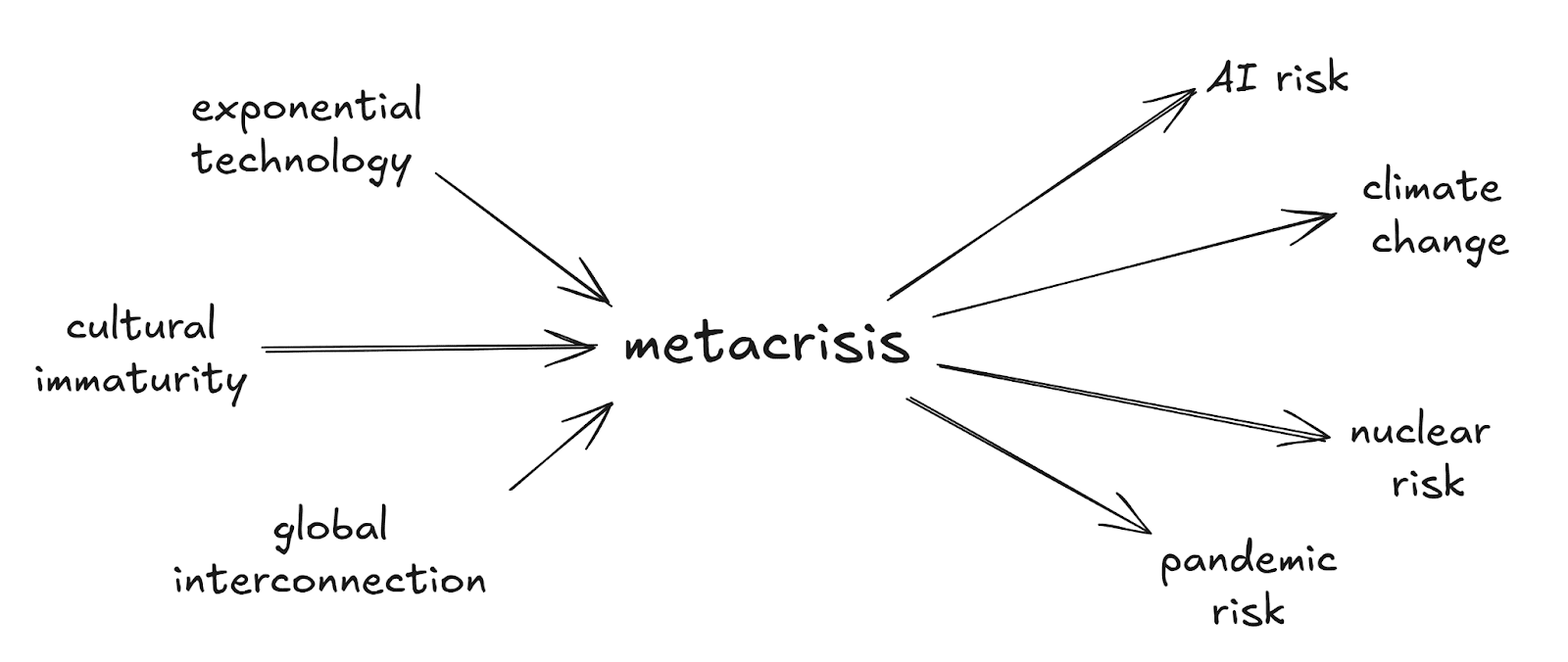
Diego: The metacrisis is the root cause of anthropogenic existential risk. It’s the fact that as technology becomes more powerful, and the world becomes more interconnected, it’s becoming easier and easier for us to destroy ourselves. But our culture, the implicit assumptions, symbols, sense-making tools and values of society, is not mature enough to steward this new-found power.
Amina: I’ve heard people say things like this before. But it’s very abstract…
Diego: Yea, it’s the most zoomed-out, big picture view of x-risk. It’s the reason we live in the hinge of history. We have the power to destroy ourselves, and our society might not be mature enough to steward that power. We can solve AI alignment, we can pass laws, we can prevent a nuclear war or the next pandemic. But technology is going to continue progressing exponentially, and if we continue playing the game we’re currently playing, we’ll find new ways to destroy ourselves.
Amina: But how do you know that we’ll always find a new way to destroy ourselves?
Diego: Because so far, all civilisations destroy themselves eventually. Human history is basically a story of civilisations forming, being stable for a short time, and collapsing. The Babylonians, the Romans, the Mongols, the Ottomans. They all fell. But when they fell it wasn’t the end of humanity, because they were just local collapses. Today, we’ve formed a global, highly interconnected and technologically advanced civilisation. In expectation, this one will fall too. And when this one falls, the whole world falls, and the fall could be the end of humanity.
Thunder claps and torrential rain starts to pour outside the office
Amina: Fucking hell. And people call us doomers. You guys need to cheer up.
Diego: We also believe we can fix it though!
Amina: Right. How? We can’t stop technological progress.
Diego: So you have to help catalyze the next cultural paradigm.
Amina: And how the hell do you do that?
Diego: Well, it’s not clear how yet. The metacrisis movement is in a pre-paradigmatic stage. They’re still trying to clarify the problem, get really clear on the shape of the metacrisis. Then it could become clear what we need to do.
Amina: I sense loads of ifs there. If a promising, talented person devoted their career to clarifying the metacrisis, that would feel like-
Diego: Like a big bet?
Amina: Yes.
Diego: You don’t like taking bets?
Amina: Fine, yes, god damn it, I love taking bets. Who am I kidding?
Diego: How about we throw the scale/neglectedness/tractability framework at this?
Amina: Yea let’s do that.
Diego draws three circles on the whiteboard, with “scale”, “neglectedness” and “tractability” in each circle. Diego points at the “scale” circle and stares intensely at Amina
Amina: Yes fine, the scale is big.
Diego: Bigger than any other problem EAs think about, arguably! Let’s give it 10/10 scale.
Amina: Fine, it scores well on scale. And for neglectedness…
Diego: Also scores well. Nobody’s ever even heard of the damn thing.
Amina: But you said there are these orgs that are working on it right?
Diego: They’re tiny. I haven’t run the numbers but I feel kinda confident that there’s 10x less people explicitly working on the metacrisis than AI alignment, for example.
Amina: Seems like a complicated claim, but fine, I’ll trust that you’re roughly right.
Diego: Let’s give it 9/10.
Amina: Fine, scores well on neglectedness. But tractability!
Diego: Yea, tractability it scores poorly on. Do you think it scores better or worse than wild animal suffering?
Amina: Oh, eh... Not sure actually.
Diego: I’m not sure either. But it’s more tractable than you might think at first glance. I don’t know if you’ve noticed, but there’s a big appetite for change in the air, in the west at least. The world might be at a tipping point, and at tipping points, small groups can have big effects by nudging things in the right direction.
Amina remained silently skeptical.
Diego: Let’s score it 2/10 on tractability.
Diego: I think if an intervention that “solves the metacrisis”, in other words, makes the world marginally less metacrisis-y, is possible, it would be a very effective intervention. Instead of having to repeatedly go against the tide of the system of incentives we currently live in to deal with x-risks one-by-one like whack-a-mole, we would be going straight to the root cause, solving all the x-risks at once. Solve the disease, not the symptoms.
Amina: That’s great and all Diego. I see where you’re coming from. But…
Amina grabs Diego by the shoulders and shakes him
Amina: WE DON’T HAVE TIME TO FIX SOCIETY, DIEGO! Didn’t you read AI 2027? AGI is coming in the next couple of years! And after AGI comes, everything will change. It’s all well-and-good treating the cause rather than the symptoms, but if someone comes into the hospital with a heart attack, do you put them on a low-fat diet, or do you just give them the fucking defibrillator?
Diego: Yea I get that. But I have three responses.
Amina: Ooo look at you. Three whole responses.
Diego: Yes, three responses. Firstly, I put a chunky credence on AGI taking way longer to come than all you bay area nerds think, so it makes sense for some people to be preparing for that scenario. Secondly, cultural change can happen faster than you think. It’s actually happening very fast right now. Do you understand skibidi toilet?
Amina: What the hell is skibidi toilet?
Diego: Exactly. And that brings me to my third point. Exponential technology can speed up cultural change. Hell, the internet might have created more culture, memes, and new languages, than the rest of history.
Amina looks skeptically at Diego
Diego: Ok, maybe I’m exaggerating, but you get my point. And AGI is going to keep making things change faster and faster. We could leverage AI to catalyse the kind of cultural evolution we need.
Amina: Ok fine. It doesn’t seem like a total waste of time for some people to be thinking about this.
Diego: That’s nice of you to say.
Amina: But I’m nowhere near convinced that the metacrisis is the most important problem to work on, or that I should quit my job doing AI safety to work on it.
Diego: I’m not trying to convince you to quit your job!
Amina: So what are you trying to convince me of?
Diego: Maybe I’m trying to convince you that the metacrisis frame should be a part of the EA portfolio. Some people in EA should be working on clarifying the metacrisis and understanding how to mitigate it. EAs and rationalists are the ones who take arguments seriously, right? Even if they’re weird or crazy-sounding? Well, I think EAs should take this argument seriously. I think the argument is strong enough that some promising EAs near the start of their careers could have a big impact making progress on the metacrisis.
Amina: Well, I don’t feel convinced of that yet, based on what you’ve said so far.
Diego: Yea, I’ve only really scratched the surface with what I’ve said so far. Maybe we’d need a longer conversation and get deeper into the nitty gritty of the metacrisis frame and how it fits into the EA frame.
Amina: Fair enough. But… There's something else that’s bothering me. It feels kinda strange to think about this metacrisis thing as a cause area in itself, since it lives on a different level of abstraction to the rest of the cause areas.
Diego pauses and thinks for a moment.
Diego: Yea… Maybe it isn’t that useful to view it as a cause area now that I come to think of it. Or, see it as a cause area in the same way as “global priorities research” is a cause area. Like, a meta cause area.
Hmm.. Maybe what I really want to argue is that EAs should be aware of the metacrisis framing and use it as a part of their epistemic toolkit. Maybe this means they can make better and wiser decisions. And maybe this will lead to some cause areas being de-prioritised and others being created.
Amina: And why should we include the metacrisis frame in the EA epistemic toolkit?
Diego: Because EA is decouply, so much so that there’s a chance they’re making a mistake by only prioritising problems that seem promising under a decouply world view. So, for a more robust portfolio, we should diversify how we make sense of the world.
Amina: Worldview diversification… I guess I’m generally pro-that.
Diego: Yea! Foxes are better forecasters than hedgehogs. Here, let me draw something else on the whiteboard.
Diego: When thinking about some problem, like AI safety, where should we draw the boundaries of the system we study? Should it just be around the walls of the OpenAI offices? Should it be AI development more broadly? Should it include the government, or the economy, or the cultural currents underneath? If you include too much, you might just get confused paralized by the complexity of it all. But if your view is too narrow, you might miss the points of highest leverage and ignore the effects you’re having on the rest of the system.
Amina: Hmm… yea, it doesn’t seem like there’s an obvious answer.
Diego: Exactly. To decouple or not decouple? We don’t know. So we should support people working on every point on this spectrum. The alignment people, the governance people, and the metacrisis people. Hedge hedge hedge.
Cleaner: Neither of you have a clue about anything.
Amina and Diego's heads turn to the open door of Amina’s office, to see the cleaner in the corridor who has been listening to the majority of their conversation.
Cleaner: you EA people and you metacrisis people think you've worked everything out, but you're both stuck in your own echo chambers, insulated from the real world.
I'm going to pre-register my prediction that you are both 99% wrong about everything.
Diego: But we're wrong in different ways right! So if we integrate our perspectives we'll only be 98% wrong?
Amina: That's not how it works-
Cleaner: Your wrongness is correlated.
Diego: Ok, 98.5% wrong then?
Amina closes the door as politely as possible.
Amina: Ok. Maybe the metacrisis is a useful frame. Maybe EAs should think more about it.
Amina stares out the window again. The rain has stopped, the clouds have cleared, and she can see the lights of the skyscrapers across the bay.
Amina: It still just feels so impossible to fix this metacrisis thing.
Diego: Maybe it's impossible. But the stakes are too high, we have to try.
Wanna read more about the metacrisis (and related ideas)?
AI Use Note: Main body text entirely human written. Claude (Opus 4.8) helped develop models of animal life histories in the appendix.
Cross-posted from Good Structures.
Executive Summary
* Animal advocates sometimes make claims like “there are X of this animal...
Adapted from my Substack, Funding Anthropalypse.
Short version: if you want a share of the coming Anthropic and OpenAI windfall - the $37bn+ that could be in play next year - the way in is to become 'legibly excellent', so the evaluators and donors that frontier lab staff already trust point them to yo...
Disclaimer: Although I work on the Groups Team at CEA, I’m writing this in a personal capacity, and this post does not constitute an endorsement by CEA.
Agency - the realisation that you really can just do things.
TL;DR
Biosecurity needs people (of any background) who are agentic and have a high execution velocity and track record....



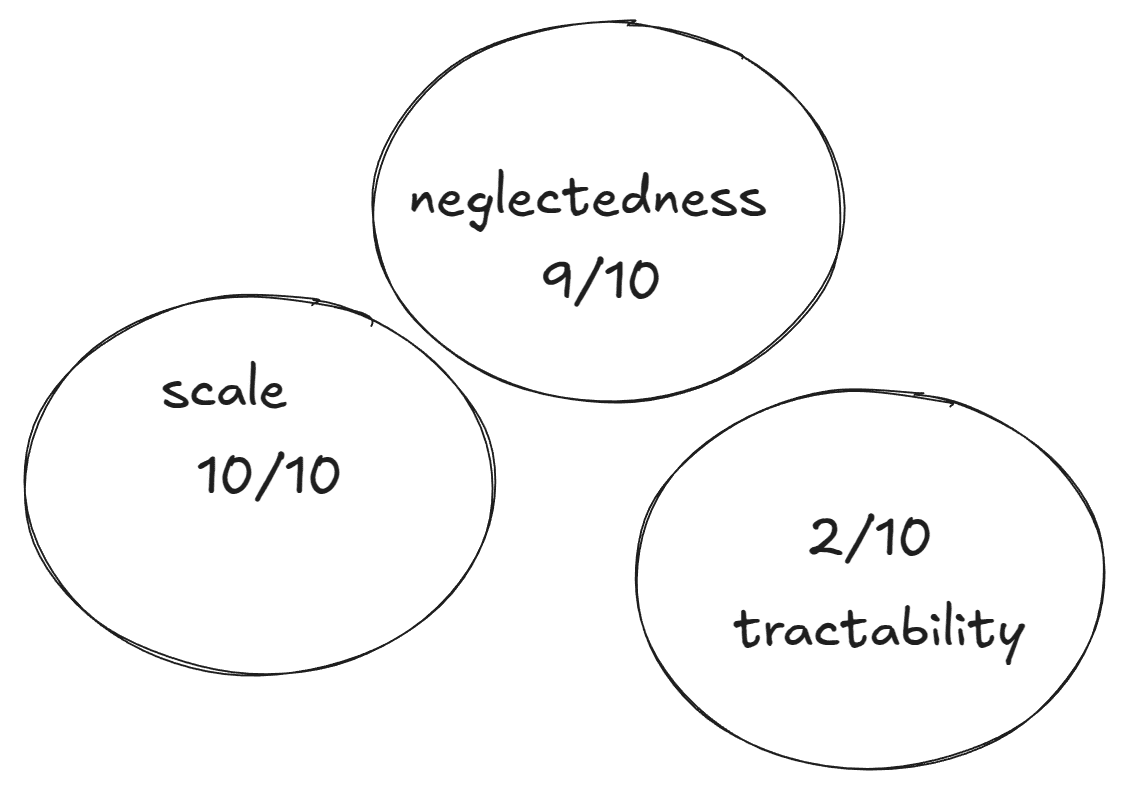


I was interested in this because I’m broadly sympathetic to the idea that we might not give enough attention to bigger systems. But for me, this post only really strengthened my EA tendencies.
So the core argument in favour of the metacrisis being ‘a thing’ (upon which the later arguments that we should take it seriously hang) seems to be:
a. Technology makes us more powerfu and the world is more interconnected
b. As a result, our capacity for self destruction has massively increased
c. Our ‘culture, the implicit assumptions, symobls, sense-making tools and values of society’ are not ‘mature’ enough to ensure this capacity is managed in a low risk manner
d. Therefore, some kind of existential risk is more likely
Propositions A and B seem basically correct to me. But I think proposition C is very weak. I have two main problems with it:
1) there is just so many different things inside of that grouping, the article only makes an argument as to why a set of implicit assumptions are a cause of the problem, then sneaks in all this other stuff in this one central paragraph. It seems highly likely to me that some things (like society's values) are more important to how well the world goes than others (like symbols)
2) I think C stands to be proved. While there are many problems with society and global coordination, it seems like often at the crunch global coordination pulls through (nuclear proliferation, chemical weapons and CFCs are examples). I think you can make an argument we don’t have the right tools, but I think equally you can make at least as strong an argument to say that we know exactly what the right tools are and we should be putting our efforts into strengthening global institutions of coordination.
I think the Diego character makes a number of other mistakes which I’m not sure are necessarily core to the argument, but certainly weaken my sense of its credibility for me:
I like the idea of doing more thinking through Socratic dialogues and there were a couple of jokes here which actually made me laugh out loud. But it has left me closer to thinking this integral/metacrisis thing is lacking in substance. Putting this author aside, it seems like many of the folk who talk about this stuff are merely engaging in self-absorbed obscurantism.
Thanks for your comment Thom.
In my response to this, I really want to avoid this vibe of “you just don’t understand” or “you need to wake up” and all that kind of thing. I know how annoying and unproductive that kind of response can be. In what I write below I’m not trying to just assert that my position is obviously more right, if only you could see through the matrix. I’m interested in clarifying the metacrisis position/how metacrisis folk think, as maybe if it becomes clear enough it will no longer seem obviously stupid to you!
That being said, the standard metacrisis-y response to most of what you’ve said here would be to try and pick apart the (modernist-y) assumptions that might lie underneath it. Being contextualizing isn’t just about awareness of the context of the system you’re studying, but also the context of your own mind/rationality/beliefs – all the quite deep assumptions driving those beliefs that work well in a number of contexts (like building bridges, training LLMs, or saving kids from malaria) but might not generalize as well as you think to statements about a rapidly evolving and highly interconnected world.
I’ll pick out a couple of examples to pick on from your comment:
> Modernity has led to the mental health crisis: I’m just not sure this empirically stacks up. It is really hard to measure mental health over time, given that its measurement is so culturally contingent
I want to pick on this because I think it’s a good example of what the vibey crowd like to call “scientism”, which in my head means something like the view that “the only possible way to know something to be true is if it’s published in a peer-reviewed journal”. That is obviously one of the most reliable ways to know something is true, but it limits your toolkit for making sense of the world.
In the case of modernity leading to a mental health crisis: yes, you’re right that it’s a very hard thing to measure, and therefore no signal has been found by any study. But when you include lived experience… I don’t know man, it just feels so true, at least in some sense, from my own life and the lives of so many around me. For example, there’s no signal that shows that social media can mess up teenagers’ mental health, but this exchange we’re having in the comments of the EA forum is making my muscles tense and my mind race, and when I extrapolate this to being a teenager and dealing with high stakes things like how I look or who fancies me, this is some good evidence for that causation in my book.
Sometimes I think of EA as the “analytical philosophy of changemaking” while metacrisis is the “continental philosophy of changemaking”, since in analytical philosophy something is true because you can prove it to be true, while in continental philosophy something is true because it feels true. We need both.
> Growth has historically been the single biggest driver of human welbeing.
So… how are you defining human wellbeing here? In terms of stuff you can measure (life expectancy, economic prosperity, etc), yea there’s no argument, you’re right. But all the other things that contribute to a broader definition of wellbeing? Community, meaning, connection to nature, etc? Wellbeing is a complex beast. I don’t have the arguments or the data to say you’re wrong, but you’re saying it here without any argument as if this is obviously right.
You may well be right even in the broader sense of the word wellbeing, but a metacrisis person might also say that once you’ve optimised hard enough for economic growth, goodhart’s law bites you in the arse and growth starts to decorrelate from wellbeing. Some might argue that that is starting already (see, for example, Scandinavia scoring best on various happiness metrics while having a smaller economy than, say, the US).
To reiterate something I said in the post, I’m aware that if you’re constantly questioning everything and constantly having to keep all the mystery of the definitions of all your terms you’re using in your attention, you’ll never get anything done. Getting things done is good. But if you commit to some metric and then never revisit the assumptions behind it, you might find yourself getting the wrong things done when your optimisation pushes the world out of the regime in which your metric makes sense.
> The idea that rivalry (caused by human nature) is a background assumption and not necessarily the case: the point here surely is that, yes of course humans can be more or less cooperative at times and given different cultural assumptions, but this kind of game theory describes dynamics that are independent of how most people behave.
This feels like a statement about the strength & generality of game theory when applied to humans on various scales. The metacrisis nerds would probably try to poke at how much confidence you have in game theory to support the claim that rivalry will always arise. This kind of background acceptance in game theory has a modernist vibe.
Anyway, I don’t expect I’ve changed your mind on any of this, which is fine! Even if we don’t agree it’s good to more deeply understand each other’s position. Ok bye
Thanks for responding to my points! You didn't have to go through line by line, but its appreciated.
Obviously a line by line response to your line by line response to my line by line response to your article would be somewhat over the top. So I'll refrain!
The general point I'd make though is that this almost feels like an argument for something before you've decided what you want to argue for. There feels like a conceptual hole in the middle of this piece (as you say, people are still trying to work out what the problem is). But then you also respond to most of (not all) my points without actually giving a counter-argument, just claiming that I'm clearly mistaken. This makes it quite hard to actually engage with what you've written.
Maybe, as Alexander seems to think, I'm just a poor blinkered fool who can't understand other people's perspectives - but I am actually tryign to engage with what you've written here, not sh*t posting.
Yes we could waste our lives falling down a hole here.
Huh. I must have messed up the tone of my last message because that wasn't the intention at all. For some of my responses I thought I was basically agreeing with you, and others I was clarifying what I (or rather Diego) was trying to say rather than saying you are wrong.
I liked this comment and thought it raised a bunch of interesting points, thanks for writing it.
> Putting this author aside, it seems like many of the folk who talk about this stuff are merely engaging in self-absorbed obscurantism.
I had a bit of a negative reaction to this comment - it seems a bit uncharitable to me
Thanks!
That's fair, I might have been a bit mean there!
I don't want to engage in a point by point rebuttal but just want to encourage you to engage more critically with the assumptions that you bottom out your argument with. All of these can and have been reasonably questioned. In particular, how to think about progress and its relationship to technology and the innocuousness of defining "problems" as decoupled from their particular contexts.
> But it has left me closer to thinking this integral/metacrisis thing is lacking in substance. Putting this author aside, it seems like many of the folk who talk about this stuff are merely engaging in self-absorbed obscurantism.
I wonder if this statement might simply reflect your ability to understand and steelman other people's perspectives. Food for thought?!
Now this is uncharitable
So, you do it on purpose, not out of inability? Thanks for clarifying.