
"Part one of our challenge is to solve the technical alignment problem, and that’s what everybody focuses on, but part two is: to whose values do you align the system once you’re capable of doing that, and that may turn out to be an even harder problem", Sam Altman, OpenAI CEO (Link).
In this post, I argue that:
- "To whose values do you align the system" is a critically neglected space I termed “Moral Alignment.” Only a few organizations work for non-humans in this field, with a total budget of 4-5 million USD (not accounting for academic work). The scale of this space couldn’t be any bigger - the intersection between the most revolutionary technology ever and all sentient beings. While tractability remains uncertain, there is some promising positive evidence (See “The Tractability Open Question” section).
- Given the first point, our movement must attract more resources, talent, and funding to address it. The goal is to value align AI with caring about all sentient beings: humans, animals, and potential future digital minds. In other words, I argue we should invest much more in promoting a sentient-centric AI.
The problem
What is Moral Alignment?
AI alignment focuses on ensuring AI systems act according to human intentions, emphasizing controllability and corrigibility (adaptability to changing human preferences). However, traditional alignment often ignores the ethical implications for all sentient beings. Moral Alignment, as part of the broader AI alignment and AI safety spaces, is a field focused on the values we aim to instill in AI. I argue that our goal should be to ensure AI is a positive force for all sentient beings.
Currently, as far as I know, no overarching organization, terms, or community unifies Moral Alignment (MA) as a field with a clear umbrella identity. While specific groups focus individually on animals, humans, or digital minds, such as AI for Animals, which does excellent community-building work around AI and animal welfare while also incorporating content related to digital minds, a broader framing aims to foster a shared vision, collaboration, and synergy among everyone interested in the MA space.
* I am happy to receive any feedback on the best term for this MA space, as it is still being examined.
The Paradox of Human-Centric Alignment
There is a troubling paradox in AI alignment: while effective altruists work to prevent existential risks (x-risks) and suffering risks (s-risks) by aligning AI with human values, those very values—reflected in human actions throughout history—have already caused many of the risks we seek to prevent. Powerful and controllable technologies in human hands have led to human x-risks such as genocides and an ever-worsening climate crisis, as well as non-human x-risks, like possibly wiping out most wild animals from the face of the planet. Similarly, human values have enabled severe s-risks, including factory farming and slavery. This raises the question: if aligning AI with human values has historically resulted in catastrophic outcomes, how can we ensure that AI alignment will not amplify the very harms we aim to prevent?
From the perspective of most sentient beings on Earth, human intelligence itself is a misaligned biological superintelligence attempting to build an even more powerful artificial intelligence. Alongside controllability and corrigibility, which are essential, we must prioritize alignment with sentient-centric values. Current AI models already reinforce anthropocentric biases, and as they gain agency and influence decision-making—from urban planning to technology development (such as alternative proteins)—AI values will shape the world’s future. This post highlights practical ways humans use AI that could be either catastrophic or beneficial to animals.
Addressing a Counterargument
“We should invest everything in safety; if AI becomes uncontrollable and destroys us, Moral Alignment won't matter.”
- In 2024, total AI safety spending by major AI safety funds according to this LessWrong post was a bit more than 100 million. I don't know how to calculate the whole MA space donations in 2024, but for organizations focusing on non-humans, it was probably about 5 million USD (I haven't found any official numbers; this is an estimate based on conversations with various people in the field), without counting funding for related academic work, which may somewhat increase this number but not by a lot. Hence, the MA space is much more neglected than AI Safety, which is very neglected in itself. Furthermore, it is probably a non-sum zero game, and more efforts on MA might not come at the expense of AI safety money.
- Some experts consider many AI safety projects net negative because they risk enhancing AI capabilities. Maybe MA work doesn’t pose such a risk.
- If we wait to work toward a sentient AI, it may be too late due to short AI timelines, which might alter our ability to influence the future, such as in the case of value lock-in. We must set precedents now, establishing a tradition of including the interests of humans and non-humans in AI model development.
- Making AI care about all sentient beings may be a critical component of ensuring its alignment with humans. If we build a speciesist AI that discriminates based on intelligence, and it, in turn, creates even smarter AI systems, pushing human intelligence further down the intelligence hierarchy, why would AI continue to care about us?
- AI might treat us the way we treat inferior technology. A future superintelligence may value the fact that we cared about it—that digital minds were included in our moral circle even before they existed or before superintelligence emerged.
This counterargument is the most common one I have encountered, though it is still relatively rare. Most people I have spoken with in AI safety, effective altruism, and AI companies seem to agree that Moral Alignment is both important and neglected. I may address other counterarguments in future posts.
The Open Tractability Question
As a nascent space working to collaborate with and influence AI companies, regulators, and other key players in AI and AI safety, there is naturally little evidence yet of its tractability. However, two factors work in favor of this kind of work:
- Our most important target group consists of AI key players who possess ethical views that are much more pro-animals/humans/digital minds than the average person. Many AI professionals, from AI safety to people working in top-tier companies, really care about all sentient beings but haven't fully explored their potential for a positive impact on MA.
- Human beings often have better stated values than realized values. The Moral Alignment space seeks to embed the values we declare and strive for, rather than merely reflecting our actions, into AI. This puts non-humans in a much better position.
The Risk of Not Creating a Unified Moral Alignment Field
What would we miss by not having a shared community for people working on AI for humans, animals, and digital minds?
- The most fundamental goal—creating a sentient-centric AI—encompasses all groups. Especially in a small, neglected space like Moral Alignment, bringing our efforts together is essential for creating a greater impact.
- Many research questions relevant to all three groups might be overlooked. For example: Will a sentient AI’s morality be more robust and ethical than that of a non-sentient philosophical zombie AI?
- On the other hand, some interventions are unique to each group. For instance, asking an AI company to develop an assessment of consciousness in AI is relevant to digital minds but may not apply to assessing consciousness in animals (e.g., insects).
- People working in different groups would miss out on strategic insights from others engaging with AI companies, regulators, and key players in the AI space.
- The AI space presents a unique opportunity to bridge the traditional divide between those working for humans and those advocating for animals or digital minds. This opportunity might be lost if we remain too fragmented. In many ways, we are all in the same boat when it comes to AI risks and opportunities. From my conversations with people across these groups, I find that they genuinely recognize and value the importance of other groups' work.
- This is not a conventional animal rights versus human rights debate, nor does it require anyone to adopt a vegan lifestyle. Because Moral Alignment is less about individual actions and more about the values we want AI to uphold, there is a much stronger common ground upon which different groups can build.
The Solutions
A Vision for the Moral Alignment Movement
This is a movement aimed at making AI a positive force for all sentient beings. It has begun gaining traction in the past year, thanks to efforts by organizations, advocates, and philosophers. Hanging around at the AI for Animals conference in San Francisco, it was clear to me that we are just beginning, and there is a lot of enthusiasm and interesting ideas and initiatives that are soon to come.
I envision this space as a robust, interdisciplinary community partnering with changemakers in AI companies, AI safety, Effective Altruism, social justice, environmental and animal advocacy, regulators and other stakeholders. This movement will unite researchers, ethicists, technologists, and advocates.
Humans are an integral part of the Moral Alignment movement for intrinsic reasons, not just instrumental ones.
AI for Animals unconference in London, May 2024

Movement Goals
These goals are highly urgent. If AGI is likely to arrive within 5–10 years, we need to establish this movement as robust and strong as soon as possible.
Here are some possible goals for the MA movement:
Short term:
- Define and frame the field: Establish MA as a discipline through research, publications, online content, events, PR and global dialogue.
- Attract talent, resources and funding into the space.
- Foster strong positive stakeholder relationships with key players in the AI space.
- Enhance and expand the existing organizations’ work.
- Create coordinated action, such as an ethical pledge for AI professionals to commit to advancing sentient-centric AI.
- Create several “Moral AI” benchmarks for different groups, including a united one (work on such benchmarks has already been started; see novel evaluation of risks of animal harm in LLM-generated text).
Long-term goals can be measured concerning these points:
- The amount of money AI companies allocate to promote a sentient-centric AI.
- The amount of money AI companies allocate to supporting non-humans, such as funding research on integrating sentientist values into AI systems.
- The amount of money AI companies allocate to supporting humans, such as fairness, transparency, and inclusivity, that prioritize human well-being beyond mere controllability or corrigibility.
- The market share of AI chat systems or agents regulated for Moral Alignment, whether through company-adopted benchmarks or legal frameworks, and the effectiveness of such regulations in benefiting non-humans.
- The number of citations from research on more ethical models and their benefits.
- The amount of money spent on beneficial AI applications for non-humans, such as efforts to understand animal language so we can better help them, should be maximized, while the amount spent on harmful AI applications should be minimized. A possible example of a harmful application is precision livestock farming, which optimizes efficiency in factory farming and may come at the expense of animals (though it could also bring marginal improvements to their welfare).
Theory Of Change
Here is my version of a theory of change for developing more compassionate AI models:
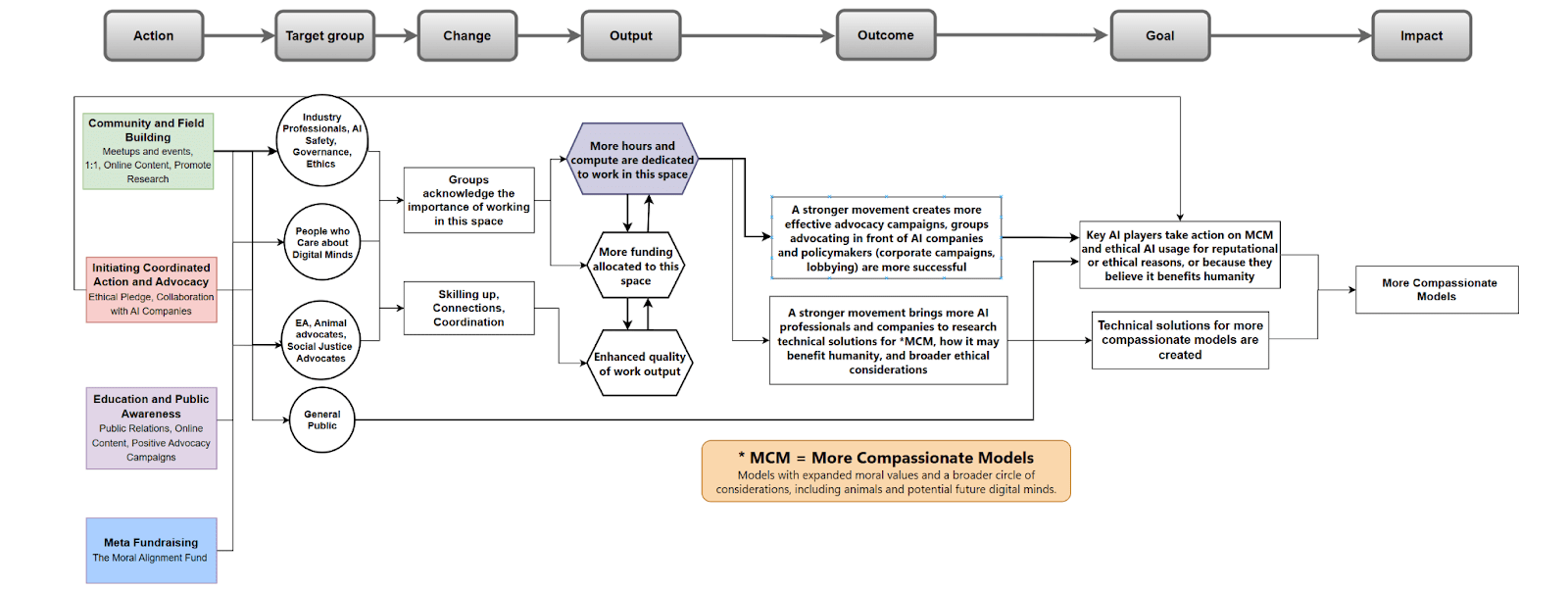
For a more comfortable, easy-to-see version: Link
The Benevolent AI Imperative
Throughout history, humanity has faced tough ethical challenges. We build homes and roads, fragmenting wild habitats, while yearning for harmony with nature. Societies have competed for scarce resources like land and water, a reality where one person's gain meant another's loss.
Scarcity shaped our past, but abundance can shape our future. AI could offer the turning point, moving beyond zero-sum constraints. In that kind of future, values of kindness, fairness, and care can flourish.
Humankind, let’s face it, has not been Earth's best steward, having exterminated wild animal populations and created mass suffering for domesticated ones in factory farming. AI provides us with a second chance, a chance to rectify. Aligning AI with care for all sentient life allows us to embrace a role matching our power and intelligence. With a benevolent AI as our partner, we can become sentinels of sentience, creating a good future for all sentientkind.
Actions
Possible Interventions
Here are just a couple of options for interventions. More intervention ideas for animals can be found in this post, and this report is an example of an intervention for digital minds. This report recommends three early steps AI companies can take to address possible future AI welfare.
Interventions ideas:
- Conduct or fund research on fundamental questions for MA, e.g., how does a sentient-centric AI behave, and what does it practically mean?
- Create online and in-person events.
- Present the space through presentations and 1:1 meetings in AI Safety conferences.
- Write about the importance of MA on social media (Twitter and Reddit), EA/LessWrong forums and similar platforms.
- Write a book about the subject.
- Publish opinion columns about Moral Alignment in mainstream media.
Ways to Contribute to the Movement
Humanity has a narrow window to ensure all sentientkind's interests are addressed before it's too late. Some initial actions to promote this goal include:
Provide Feedback: Comment here or send me a private message (see below section “Give Us Feedback” for more details).
Donate: Support organizations in this field.
Create Content: Write posts, produce a TED Talk, or add Moral Alignment content to your website, if relevant.
Raise Awareness: Talk about it in discussions.
Connect People: Link individuals in this space with potential collaborators, volunteers, funders and more.
Start a new initiative: If you’re an entrepreneur or aspire to be, you can create a new initiative or join an incubator that will help you kickstart it. Some organizations (like the Centre for Effective Altruism) incubate charities working in different spaces. I think this could be highly effective.
If you’re a substantial donor, you can consider launching or joining a special purpose fund for Moral Alignment.
Give Us Feedback
Share your thoughts with me about anything related to the space I described: The vision, counterarguments, the term "Moral Alignment" (you can suggest alternatives), intervention ideas, strategy and more.
Contact me for deeper discussions and more information: ronenbar07@gmail.com
Next Posts I plan to write
- Landscape analysis: In this post, I only mentioned one organization working in the MA space, AI for Animals. I will make a post that maps all key players in the space.
- Ideas for research that can boost MA.
- List of potential interventions.
- A post about the new initiative I co-founded, The Moral Alignment Center.
- Deliberating strategic questions about the movement.
I have to admit, this is one of those ideas that's like "wow, how in all my years of thinking about AI safety have I not thought about this?" beyond "humans care about other beings, so AI will care if humans care". It's so obvious and important in hindsight that I'm a bit ashamed it was a blindspot. Many thanks for pointing it out!