This is a special post for quick takes by Clara Torres Latorre 🔶️. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Comment Permalink
Speaking from what I've personally seen, but it's reasonable to assume it generalizes.
There's an important pool of burned out knowledge workers, and one of the major causes is lack of value alignment, i.e. working for companies that only care about profits.
I think this cohort would be a good target for a campaign:
- Effective giving can provide meaning for the money they make
- Dedicating some time to take on voluntary challenges can help them with burnout (if it's due to meaninglessness)
Tentatively and naively, I think this is accurate.
I'm wondering if there would be any way to target/access this population? If this campaigns existed, what action would it take? Some groups of people are relatively easy to access/target due to physical location or habits (college-aged people often congregate at/around college, vegan people often frequent specific websites or stores, etc.).
I imagine that someone much more knowledgeable about advertising/marketing than I am would have better ideas. All I can come up with off the top of my head is targeted social media advertisements: people who work at one of these several companies and who have recently searched for one of these few terms, etc.
Question: how to reconcile the fact that expected value is linear with preferences being possibly nonlinear?
Example: people are tipically willing to pay more than expected value for a small chance of a big benefit (lottery), or to remove a small chance of a big loss (insurance).
This example could be rejected as a "mental bias" or "irrational". However, it is not obvious to me that linearity is a virtue, and even if it is, we are human and our subjective experience is not linear.
- Thank you for pointing out log utility, I am aware of this model (and also other utility functions). Any reasonable utility function is concave (diminishing returns), which can explain insurance to some extent but not lotteries.
- I could imagine that, for an altruistic actor, altruistic utility becomes "more linear" if it's a linear combination of the utility functions of the recipients of help. This might be defensible, but it is not obvious for me unless that actor is utilitarian, at least in their altruistic actions.
(just speculating, would like to have other inputs)
I get the impression that sexy ideas get disproportionate attention, and that this may be contributing to the focus on AGI risk at the expense of AI risks coming from narrow AI. Here I mean AGI x-risk/s-risk vs narrow AI (+ possibly malevolent actors or coordination issues) x-risk/s-risk.
I worry about prioritising AGI when doing outreach because it may make the public dismiss the whole thing as a pipe dream. This happened to me a while ago.
Ah I see what you're saying. I can't recall seeing much discussion on this. My guess is that it would be hard to develop a non-superintelligent AI that poses an extinction risk but I haven't really thought about it. It does sound like something that deserves some thought.
When people raise particular concerns about powerful AI, such as risks from synthetic biology, they often talk about them as risks from general AI, but they could come from narrow AI, too. For example some people have talked about the risk that narrow AI could be used by humans to develop dangerous engineered viruses.
My uninformed guess is that an automatic system doesn't need to be superintelligent to create trouble, it only needs some specific abilities (depending on the kind of trouble).
For example, the machine doesn't need to be agentic if there is a human agent deciding to make bad stuff happen.
So I think it would be an important point to discuss, and maybe someone has done it already.
Curated and popular this week
·
At the last EAG Bay Area, I gave a workshop on navigating a difficult job market, which I repeated days ago at EAG London. A few people have asked for my notes and slides, so I’ve decided to share them here.
This is the slide deck I used.
Below is a low-effort loose transcript, minus the interactive bits (you can see these on the slides in the form of reflection and discussion prompts with a timer). In my opinion, some interactive elements were rushed because I stubbornly wanted to pack too much into the session. If you’re going to re-use them, I recommend you allow for more time than I did if you can (and if you can’t, I empathise with the struggle of making difficult trade-offs due to time constraints).
One of the benefits of written communication over spoken communication is that you can be very precise and comprehensive. I’m sorry that those benefits are wasted on this post. Ideally, I’d have turned my speaker notes from the session into a more nuanced written post that would include a hundred extra points that I wanted to make and caveats that I wanted to add. Unfortunately, I’m a busy person, and I’ve come to accept that such a post will never exist. So I’m sharing this instead as a MVP that I believe can still be valuable –certainly more valuable than nothing!
Introduction
80,000 Hours’ whole thing is asking: Have you considered using your career to have an impact?
As an advisor, I now speak with lots of people who have indeed considered it and very much want it – they don't need persuading. What they need is help navigating a tough job market.
I want to use this session to spread some messages I keep repeating in these calls and create common knowledge about the job landscape.
But first, a couple of caveats:
1. Oh my, I wonder if volunteering to run this session was a terrible idea. Giving advice to one person is difficult; giving advice to many people simultaneously is impossible. You all have different skill sets, are at different points in
·
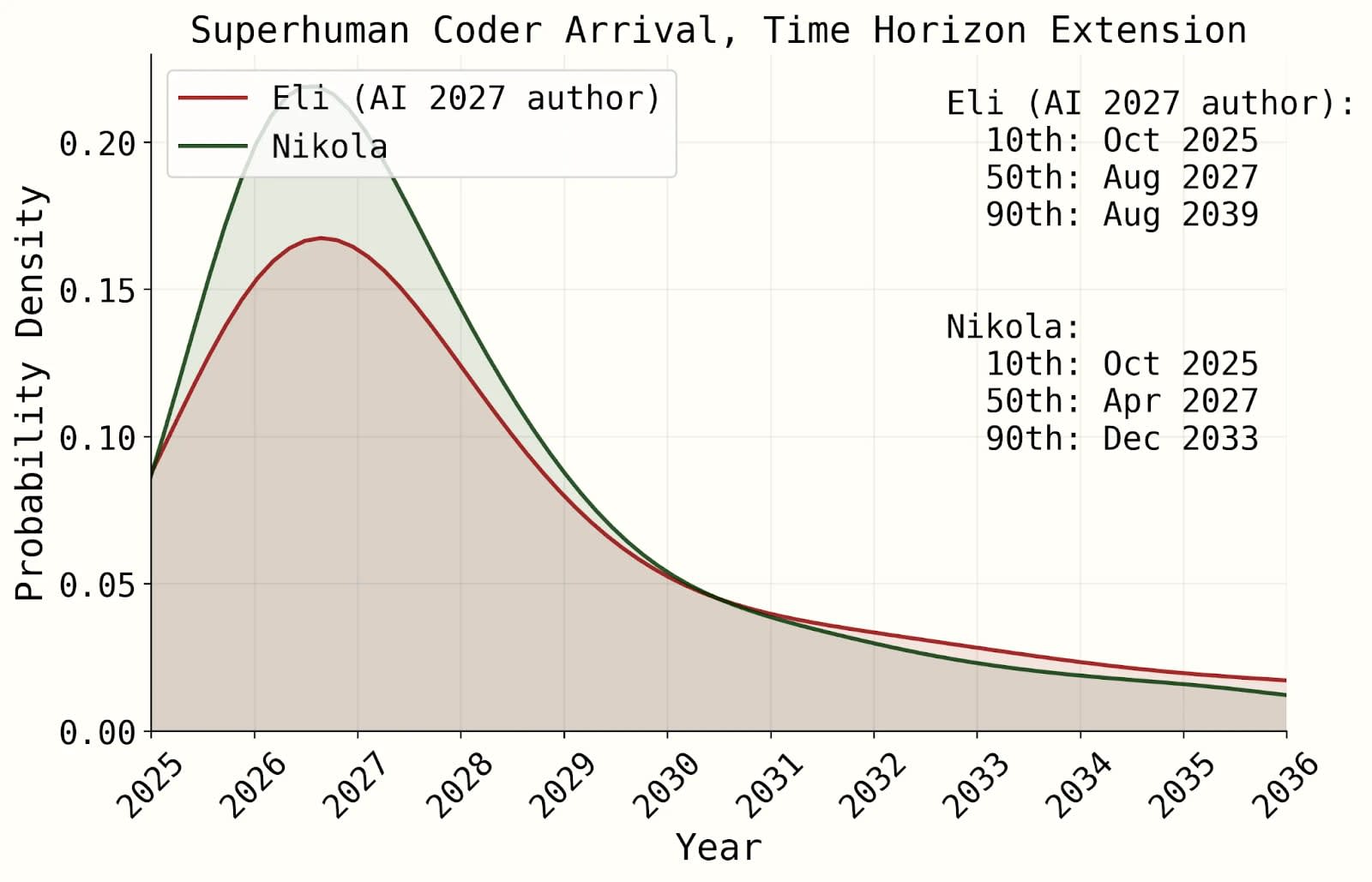
Thank you to Arepo and Eli Lifland for looking over this article for errors.
I am sorry that this article is so long. Every time I thought I was done with it I ran into more issues with the model, and I wanted to be as thorough as I could. I’m not going to blame anyone for skimming parts of this article.
Note that the majority of this article was written before Eli’s updated model was released (the site was updated june 8th). His new model improves on some of my objections, but the majority still stand.
Introduction:
AI 2027 is an article written by the “AI futures team”. The primary piece is a short story penned by Scott Alexander, depicting a month by month scenario of a near-future where AI becomes superintelligent in 2027,proceeding to automate the entire economy in only a year or two and then either kills us all or does not kill us all, depending on government policies.
What makes AI 2027 different from other similar short stories is that it is presented as a forecast based on rigorous modelling and data analysis from forecasting experts. It is accompanied by five appendices of “detailed research supporting these predictions” and a codebase for simulations. They state that “hundreds” of people reviewed the text, including AI expert Yoshua Bengio, although some of these reviewers only saw bits of it.
The scenario in the short story is not the median forecast for any AI futures author, and none of the AI2027 authors actually believe that 2027 is the median year for a singularity to happen. But the argument they make is that 2027 is a plausible year, and they back it up with images of sophisticated looking modelling like the following:
This combination of compelling short story and seemingly-rigorous research may have been the secret sauce that let the article to go viral and be treated as a serious project:To quote the authors themselves:
It’s been a crazy few weeks here at the AI Futures Project. Almost a million people visited our webpage; 166,00
·
Authors: Joel McGuire (analysis, drafts) and Lily Ottinger (editing)
Formosa: Fulcrum of the Future?
An invasion of Taiwan is uncomfortably likely and potentially catastrophic. We should research better ways to avoid it.
TLDR: I forecast that an invasion of Taiwan increases all the anthropogenic risks by ~1.5% (percentage points) of a catastrophe killing 10% or more of the population by 2100 (nuclear risk by 0.9%, AI + Biorisk by 0.6%). This would imply it constitutes a sizable share of the total catastrophic risk burden expected over the rest of this century by skilled and knowledgeable forecasters (8% of the total risk of 20% according to domain experts and 17% of the total risk of 9% according to superforecasters).
I think this means that we should research ways to cost-effectively decrease the likelihood that China invades Taiwan. This could mean exploring the prospect of advocating that Taiwan increase its deterrence by investing in cheap but lethal weapons platforms like mines, first-person view drones, or signaling that mobilized reserves would resist an invasion.
Disclaimer
I read about and forecast on topics related to conflict as a hobby (4th out of 3,909 on the Metaculus Ukraine conflict forecasting competition, 73 out of 42,326 in general on Metaculus), but I claim no expertise on the topic. I probably spent something like ~40 hours on this over the course of a few months.
Some of the numbers I use may be slightly outdated, but this is one of those things that if I kept fiddling with it I'd never publish it.
Acknowledgements: I heartily thank Lily Ottinger, Jeremy Garrison, Maggie Moss and my sister for providing valuable feedback on previous drafts.
Part 0: Background
The Chinese Civil War (1927–1949) ended with the victorious communists establishing the People's Republic of China (PRC) on the mainland. The defeated Kuomintang (KMT[1]) retreated to Taiwan in 1949 and formed the Republic of China (ROC). A dictatorship during the cold war, T

My uninformed guess is that an automatic system doesn't need to be superintelligent to create trouble, it only needs some specific abilities (depending on the kind of trouble).
For example, the machine doesn't need to be agentic if there is a human agent deciding to make bad stuff happen.
So I think it would be an important point to discuss, and maybe someone has done it already.