Recently, we shared our general model of the AI-sentience-possibility-space:
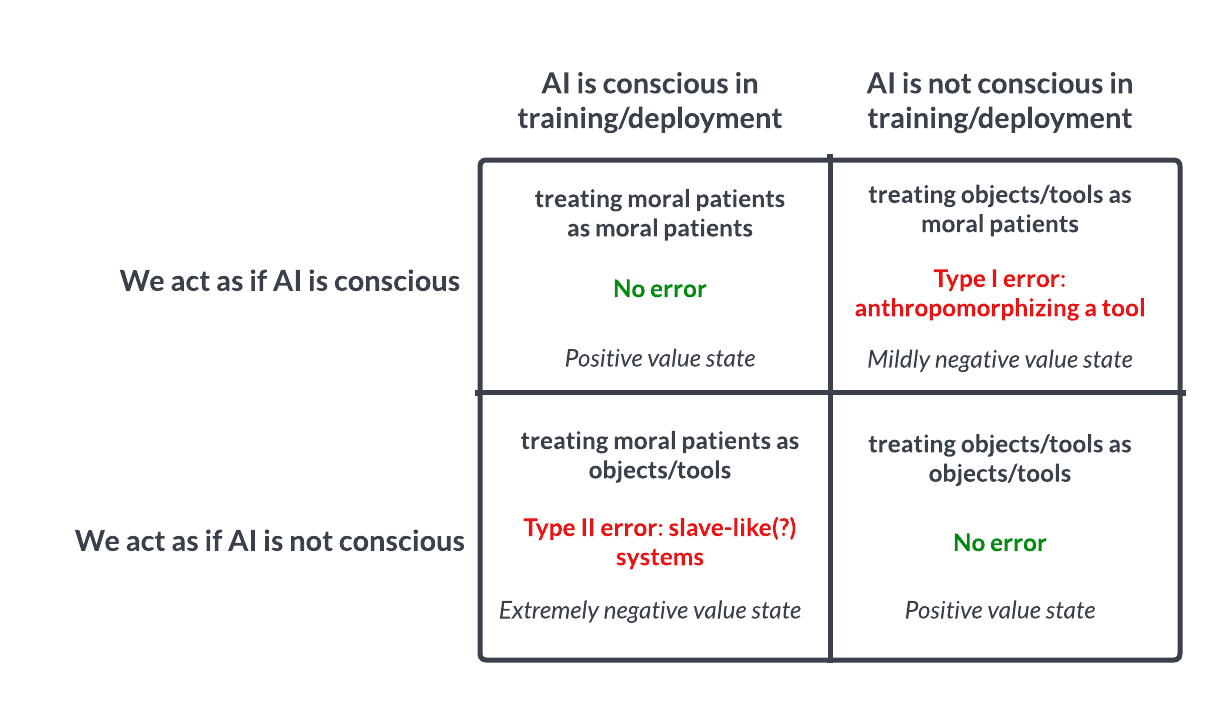
If this model is remotely accurate, then the core problem seems to be that no one currently understands what robustly predicts whether a system is conscious—and that we therefore also do not know with any reasonable degree of confidence which of the four quadrants we are in, now or in the near future.
This deep uncertainty seems unacceptably reckless from an s-risk perspective for fairly obvious reasons—but is also potentially quite dangerous from the point of view of alignment/x-risk. We briefly sketch out the x-risk arguments below.
Ignoring the question of AI sentience is a great way to make a sentient AI hate us
One plausible (and seemingly neglected) reason why advanced AI may naturally adopt actively hostile views towards humanity is if these systems come to believe that we never bothered to check in any rigorous way whether training or deploying these systems was subjectively very bad for these systems (especially if those systems were in fact suffering during training and/or deployment).
Note that humans have a dark history of conveniently either failing to ask or otherwise ignoring this question in very similar contexts (e.g., “don’t worry, human slaves are animal-like!,” “don’t worry, animal suffering is incomparable to human suffering!”)—and that an advanced AI would almost certainly be keenly aware of this very pattern.
It is for this reason that we think AI sentience research may be especially important, even in comparison to other more-commonly-discussed s-risks. If, for instance, we are committing a similar Type II error with respect to nonhuman animals, the moral consequences would also be stark—but there is no similarly direct causal path that could be drawn between these Type II errors and human disempowerment (i.e., suffering chickens can’t effectively coordinate against their captors; suffering AI systems may not experience such an impediment).
Sentient AI that genuinely 'feels for us' probably wouldn't disempower us
It may also be the case that developing conscious AI systems could induce favorable alignment properties—including prosociality—if done in the right way.
Accidentally building suffering AIs may be damning from an x-risk perspective, but purposely building thriving AIs with a felt sense of empathy, deep care for sentient lives, etc may be an essential ingredient for mitigating x-risk. However, given current uncertainty about consciousness, it also seems currently impossible to discern how to reliably yield one of these things and not the other.
Therefore, it seems clear to us that we need to immediately prioritize and fund serious, non-magical research that helps us better understand what features predict whether a given system is conscious—and subsequently use this knowledge to better determine which quadrant we are actually in (above) so that we can act accordingly.
At AE Studio, we are contributing to this effort through our own work and by helping to directly fund promising consciousness researchers like Michael Graziano—but this space requires significantly more technical support and funding than we can provide alone. We hope that this week’s debate and broader conversations in this space will move the needle in the direction of taking this issue seriously.
Thanks, I largely agree with this, but I worry that a Type I error could be much worse than is implied by the model here.
Suppose we believe there is a sentient type of AI, and we train powerful (human or artificial) agents to maximize the welfare of things we believe experience welfare. (The agents need not be the same beings as the ostensibly-sentient AIs.) Suppose we also believe it's easier to improve AI wellbeing than our own, either because we believe they have a higher floor or ceiling on their welfare range, or because it's easier to make more of them, or because we believe they have happier dispositions on average.
Being in constant triage, the agents might deprioritize human or animal welfare to improve the supposed wellbeing of the AIs. This is like a paperclip maximizing problem, but with the additional issue that extremely moral people who believe the AIs are sentient might not see a problem with it and may not attempt to stop it, or may even try to help it along.
Thanks for this comment—this is an interesting concern. I suppose a key point here is that I wouldn't expect AI well-being to be zero-sum with human or animal well-being such that we'd have to trade off resources/moral concern in the way your thought experiment suggests.
I would imagine that in a world where we (1) better understood consciousness and (2) subsequently suspected that certain AI systems were conscious and suffering in training/deployment, the key intervention would be to figure out how to yield equally performant systems that were not su... (read more)