95% of the time, AI fails to generate significant revenue for businesses that adopt it
I think this is a misreading of the study, though the article you link seems to make the same mistake. Here's the relevant graph:
The finding is that 5% of all companies (not just those that have adopted AI) had an executive who reported "a marked and sustained productivity and/or P&L impact" of a task-specific GenAI.
I think a more accurate summary of the paper is something like "80% of LLM pilots are reported as successful by executives."[1]
Quote from the executive summary of the MIT Media Lab study, on page 3:
Despite $30–40 billion in enterprise investment into GenAI, this report uncovers a surprising result in that 95% of organizations are getting zero return. The outcomes are so starkly divided across both buyers (enterprises, mid-market, SMBs) and builders (startups, vendors, consultancies) that we call it the GenAI Divide. Just 5% of integrated AI pilots are extracting millions in value, while the vast majority remain stuck with no measurable P&L impact.
Quote from page 6:
The GenAI Divide is starkest in deployment rates, only 5% of custom enterprise
AI tools reach production. Chatbots succeed because they're easy to try and flexible, but fail
in critical workflows due to lack of memory and customization. This fundamental gap
explains why most organizations remain on the wrong side of the divide.
Page 7:
The 95% failure rate for enterprise AI solutions represents the clearest manifestation of the GenAI Divide.
I agree that the authors encourage this misreading of the data by eg saying "95% of organizations are getting zero return" and failing to note the caveats listed in my comment. If you believe that this statement is referencing a different data set than the one I was quoting which doesn't have those caveats, I'd be interested to hear it.
I'm saying that the authors summarized their findings without caveats, and that those caveats would dramatically change how most people interpret the results.
(Note that, despite the "MIT" name being attached, this isn't an academic paper, and doesn't seem to be trying to hold itself to those standards.)
I recommend emailing the authors and asking for clarification. I’ve done this more than once in the past when I’ve had thoughts about papers I’ve read and have gotten some extremely helpful, illuminating replies.
I always worry about bothering people, but I get the sense that, rather than being annoyed, people find it rewarding that anyone took an interest in their work, or at least don’t mind answering a quick email.
Executive summary: The author argues it is very likely the AI industry is in a bubble, citing rising “bubble” sentiment, circular financing, weak realized productivity and profitability gains, and technical limits that make it hard for capabilities or business models to catch up with valuations.
Key points:
The author proposes operational tests for an AI bubble, including sustained stock declines for firms like Nvidia/Microsoft/Google or consensus judgments from outlets (WSJ, FT, Bloomberg, Economist, NYT) or expert surveys.
Sentiment appears to be tipping toward “bubble,” with BofA’s fund-manager survey moving from 41% (Sep 2025) to 54% (Oct 2025) saying AI stocks are in a bubble, alongside public claims from Jared Bernstein, Jim Covello, Jeremy Grantham, and Michael Burry.
The author cites “circular financing” between AI labs and cloud providers (e.g., OpenAI receiving billions from Microsoft and spending most of it back on Microsoft cloud), as reported by the New York Times and Bloomberg.
Reported business impact is small: McKinsey finds ~80% of companies see no significant top- or bottom-line gains from genAI; MIT Media Lab and BCG each report about 5% of firms achieving real returns; S&P Global survey data show 42% of companies abandoned most AI pilots by end-2024.
Productivity results are mixed: a call-center RCT shows large gains for less-skilled agents (~30% more issues/hour) but little or negative effects for the most skilled; coding studies show a pooled 26.08% increase in completed tasks across three company RCTs, while a METR RCT finds AI tools increased completion time by 19% for experienced open-source developers.
The author argues capability scaling is running into limits: data exhaustion around 2028 (Epoch AI), Sutskever’s claim that pre-training gains have plateaued, Amodei’s shift toward RL “chain-of-thought” scaling, Toby Ord’s analysis that RL would require ~1,000,000× more compute for a GPT-level boost and is infeasible, inference scaling raises ongoing costs, and fundamental LLM limits (lack of continual learning, data inefficiency, poor generalization, scarce agentic data, unsolved video learning) make current valuations hard to justify without major breakthroughs.
This comment was auto-generated by the EA Forum Team. Feel free to point out issues with this summary by replying to the comment, andcontact us if you have feedback.
Are you interested in betting on these beliefs? I couldn't find a bet with Vasco but it seems more likely we could find one, because it seems like you're more confident
It seems a bit redundant to make a bet on the stock market, no? But, for the heck of it:
I’ll bet you a $10 donation to the charity of your/my choice that by January 1, 2031, at least four of the five following reputable news outlets declares the AI bubble has popped (or equivalent language that means the same thing):
The Wall Street Journal
The Financial Times
The Economist
Bloomberg
The New York Times
If there’s any doubt or disagreement about whether the resolution criteria have been met when the time comes, I’d be willing to put it to an EA Forum poll or appoint a judge.
If you want to counter-offer with a bet of your own devising, I’m all ears.
This post has two parts: first, a (non-exhaustive) survey of some indications that the AI industry might be in a financial bubble. Second, an analysis that combines these indications with technical considerations relevant to whether the AI industry is in a bubble.
An economic bubble (also called a speculative bubble or a financial bubble) is a period when current asset prices greatly exceed their intrinsic valuation, being the valuation that the underlying long-term fundamentals justify. Bubbles can be caused by overly optimistic projections about the scale and sustainability of growth (e.g. dot-com bubble), and/or by the belief that intrinsic valuation is no longer relevant when making an investment (e.g. Tulip mania).
If we were to operationalize the concept of an AI bubble and whether such a bubble has popped, we could look at several financial measures, including investment in datacentre construction. Probably the most straightforward operationalization would be say that the bubble has popped if the stock prices of a set of public companies, such as Nvidia, Microsoft, and Google, drop by at least a certain percentage for at least a certain amount of time.
We could also defer the question to judges and say that there is an AI bubble which has popped if the Wall Street Journal, the Financial Times, Bloomberg, the Economist, and the New York Times all say so. Or we could say that if a credible survey of people with relevant financial expertise finds that at least, say, 90% of respondents say a bubble has popped, a bubble has popped.
Opinions on a potential AI bubble
Among financial experts, opinion on whether AI is a bubble is still mixed (as, seemingly, it would have to be before a bubble has actually popped, given the nature of financial markets). My personal, subjective impression is that opinion has started to tip more toward thinking there's a bubble in recent months. There is some survey evidence for this, too.
Bank of America (BofA) conducted a survey of fund managers in October 2025:
A BofA Global Research's monthly fund manager survey revealed that 54% of investors said they thought that AI stocks were in a bubble compared with 38% who do not believe that a bubble exists.
In September 2025, just a month earlier, the same survey found that 41% of investors thought AI stocks were in a bubble.
What follows are the opinions of a few prominent individuals with relevant expertise.
Jared Bernstein, the chair of Joe Biden's Council of Economic Advisors and Barack Obama's chief economist, wrote an op-ed in the New York Times in October 2025 arguing the AI industry is in a bubble:
We believe it’s time to call the third bubble of our century: the A.I. bubble.
While no one can be certain, we believe this is more likely the case than not.
Jim Covello, Head of Global Equity Research at Goldman Sachs, had strong words about the current AI investment boom in June 2024 (emphasis added by me):
Many people seem to believe that AI will be the most important technological invention of their lifetime, but I don’t agree given the extent to which the internet, cell phones, and laptops have fundamentally transformed our daily lives, enabling us to do things never before possible, like make calls, compute and shop from anywhere. Currently, AI has shown the most promise in making existing processes—like coding—more efficient, although estimates of even these efficiency improvements have declined, and the cost of utilizing the technology to solve tasks is much higher than existing methods. For example, we’ve found that AI can update historical data in our company models more quickly than doing so manually, but at six times the cost.
More broadly, people generally substantially overestimate what the technology is capable of today. In our experience, even basic summarization tasks often yield illegible and nonsensical results. This is not a matter of just some tweaks being required here and there; despite its expensive price tag, the technology is nowhere near where it needs to be in order to be useful for even such basic tasks. This is not a matter of just some tweaks being required here and there; despite its expensive price tag, the technology is nowhere near where it needs to be in order to be useful for even such basic tasks. And I struggle to believe that the technology will ever achieve the cognitive reasoning required to substantially augment or replace human interactions. Humans add the most value to complex tasks by identifying and understanding outliers and nuance in a way that it is difficult to imagine a model trained on historical data would ever be able to do.
And:
The idea that the transformative potential of the internet and smartphones wasn’t understood early on is false. I was a semiconductor analyst when smartphones were first introduced and sat through literally hundreds of presentations in the early 2000s about the future of the smartphone and its functionality, with much of it playing out just as the industry had expected. One example was the integration of GPS into smartphones, which wasn’t yet ready for prime time but was predicted to replace the clunky GPS systems commonly found in rental cars at the time. The roadmap on what other technologies would eventually be able to do also existed at their inception. No comparable roadmap exists today. AI bulls seem to just trust that use cases will proliferate as the technology evolves. But eighteen months after the introduction of generative AI to the world, not one truly transformative—let alone cost-effective—application has been found.
And:
The big tech companies have no choice but to engage in the AI arms race right now given the hype around the space and FOMO, so the massive spend on the AI buildout will continue. This is not the first time a tech hype cycle has resulted in spending on technologies that don’t pan out in the end; virtual reality, the metaverse, and blockchain are prime examples of technologies that saw substantial spend but have few—if any—real world applications today. And companies outside of the tech sector also face intense investor pressure to pursue AI strategies even though these strategies have yet to yield results. Some investors have accepted that it may take time for these strategies to pay off, but others aren’t buying that argument. Case in point: Salesforce, where AI spend is substantial, recently suffered the biggest daily decline in its stock price since the mid-2000s after its Q2 results showed little revenue boost despite this spend.
And:
I place low odds on AI-related revenue expansion because I don't think the technology is, or will likely be, smart enough to make employees smarter. Even one of the most plausible use cases of AI, improving search functionality, is much more likely to enable employees to find information faster than enable them to find better information.
And:
Over-building things the world doesn’t have use for, or is not ready for, typically ends badly. The NASDAQ declined around 70% between the highs of the dot-com boom and the founding of Uber. The bursting of today’s AI bubble may not prove as problematic as the bursting of the dot-com bubble simply because many companies spending money today are better capitalized than the companies spending money back then. But if AI technology ends up having fewer use cases and lower adoption than consensus currently expects, it’s hard to imagine that won’t be problematic for many companies spending on the technology today.
And, finally:
How long investors will remain satisfied with the mantra that “if you build it, they will come” remains an open question. The more time that passes without significant AI applications, the more challenging the AI story will become. And my guess is that if important use cases don’t start to become more apparent in the next 12-18 months, investor enthusiasm may begin to fade. But the more important area to watch is corporate profitability. Sustained corporate profitability will allow sustained experimentation with negative ROI projects. As long as corporate profits remain robust, these experiments will keep running. So, I don’t expect companies to scale back spending on AI infrastructure and strategies until we enter a tougher part of the economic cycle, which we don’t expect anytime soon. That said, spending on these experiments will likely be the one of the first things to go if and when corporate profitability starts to decline.
Jeremy Grantham, a prominent asset manager who is known for publicly identifying past bubbles, said in March 2024 he thinks AI is in a bubble (and reiterated this opinion on a podcast in May 2025):
And many such revolutions are in the end often as transformative as those early investors could see and sometimes even more so – but only after a substantial period of disappointment during which the initial bubble bursts. Thus, as the most remarkable example of the tech bubble, Amazon led the speculative market, rising 21 times from the beginning of 1998 to its 1999 peak, only to decline by an almost inconceivable 92% from 2000 to 2002, before inheriting half the retail world!
So it is likely to be with the current AI bubble.
This month (November 2025), the hedge fund manager Michael Burry — who is known for predicting the subprime mortgage crisis, a story popularized in the book The Big Short and the subsequent film adaptation — called AI investment a "bubble" and harshly criticized the way Meta and Oracle are accounting for the depreciation of their GPUs and datacentres.
Suggestive evidence: circular financing
One piece of evidence for an AI bubble is the amount of circular financing that has occurred amongst the companies involved. Per the New York Times:
Many of the deals OpenAI has struck — with chipmakers, cloud computing companies and others — are strangely circular. OpenAI receives billions from tech companies before sending those billions back to the same companies to pay for computing power and other services.
For example:
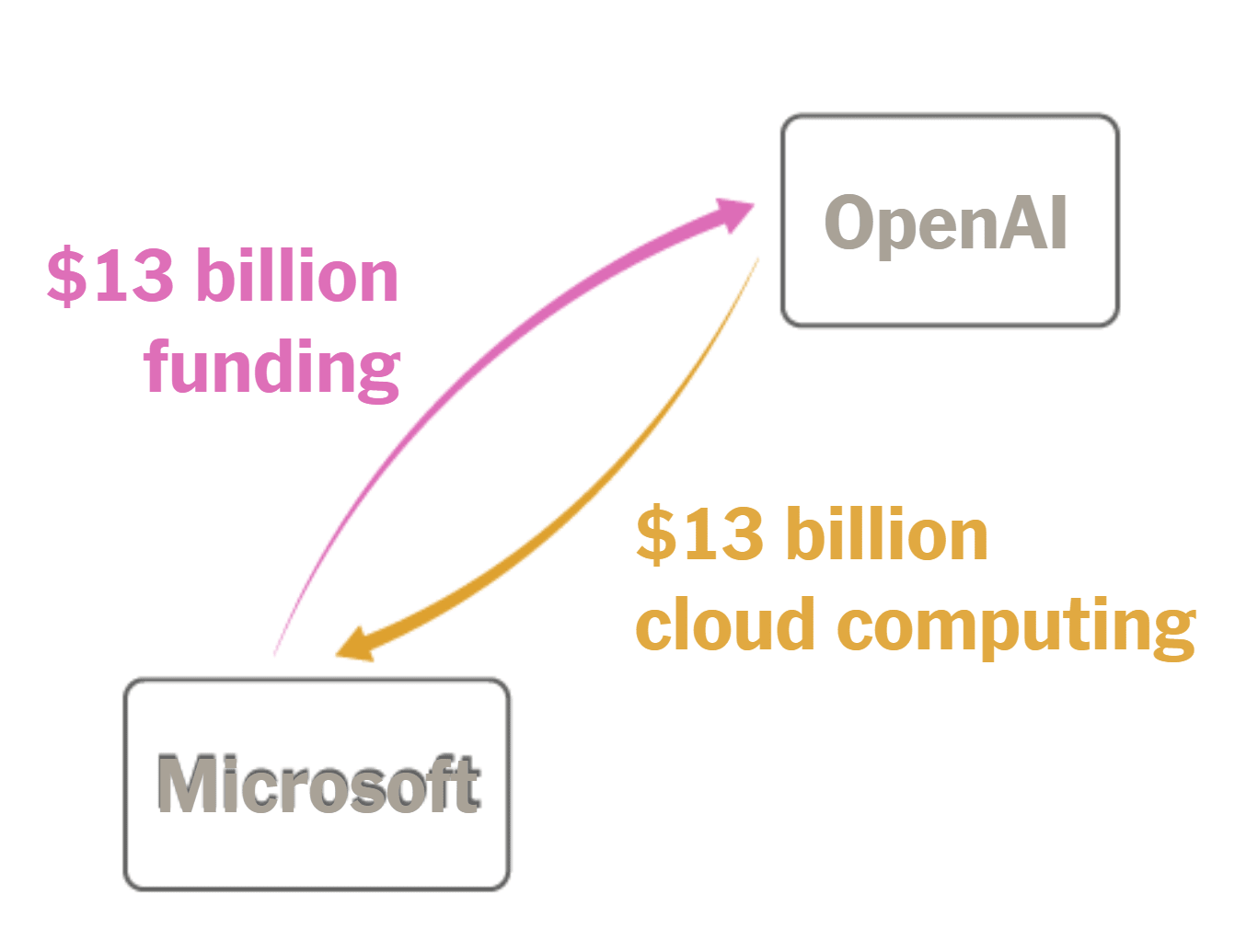
From 2019 through 2023, Microsoft was OpenAI’s primary investor. The tech giant pumped more than $13 billion into the start-up. Then OpenAI funneled most of those billions back into Microsoft, buying cloud computing power needed to fuel the development of new A.I. technologies.
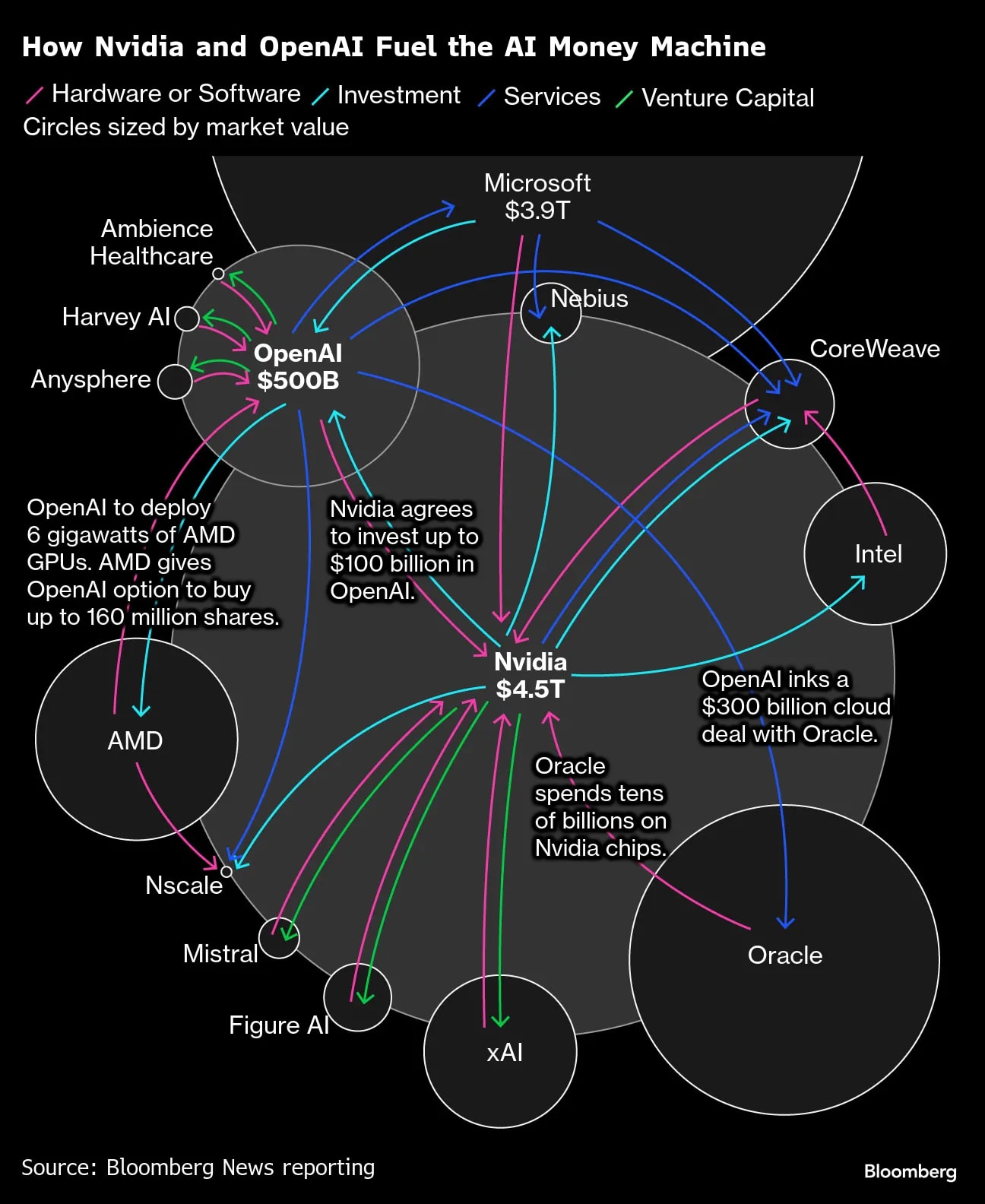
Bloomberg has also covered circular deals, which are often more complex than the above, as illustrated by this diagram:
Direct evidence: small effects on productivity and profitability
To me, what's more compelling is the evidence that the business customers of AI companies such as OpenAI, Anthropic, and Microsoft are not seeing much benefit from AI products in terms of employee productivity or financial outcomes such as profitability.
The consulting firm McKinsey has found that, as of 2025, the vast majority of companies have seen no significant increase in revenue or reduction in costs due to generative AI:
McKinsey research shows that while 80 percent of companies report using the latest generation of AI, the same percentage have seen no significant gains in topline or bottom-line performance. AI tools that help with general tasks can make employees more productive, but the small time savings they create often don't lead to noticeable financial benefits.
The MIT Media Lab released a report in August 2025 that found, 95% of the time, AI fails to generate significant revenue for businesses that adopt it:
Despite the rush to integrate powerful new models, about 5% of AI pilot programs achieve rapid revenue acceleration; the vast majority stall, delivering little to no measurable impact on P&L [profit and loss]. The research—based on 150 interviews with leaders, a survey of 350 employees, and an analysis of 300 public AI deployments—paints a clear divide between success stories and stalled projects.
An October 2025 report by the Boston Consulting Group found the same 5% success rate as the MIT Media Lab report (via Business Insider):
According to a new report from Boston Consulting Group, only 5% of companies in its2025 study of more than 1,250 global firms are seeing real returns on AI.
Meanwhile, 60% of companies have seen little to no benefit, reporting only minimal increases in revenue and cost savings despite making substantial investments.
Many businesses are giving up on using AI, as reported by the New York Times:
But the percentage of companies abandoning most of their A.I. pilot projects soared to 42 percent by the end of 2024, up from 17 percent the previous year, according to a survey of more than 1,000 technology and business managers by S&P Global, a data and analytics firm.
One of the few published scientific studies of the effect of generative AI on worker productivity in a real world context found mixed results. The study looked at the use of large language models (LLMs) at a call centre providing customer support. It found:
Second, the impact of AI assistance varies widely among agents. Less skilled and less experienced workers improve significantly across all productivity measures, including a 30% increase in the number of issues resolved per hour. The AI tool also helps newer agents to move more quickly down the experience curve: treated agents with two months of tenure perform just as well as untreated agents with more than six months of tenure. In contrast, AI has little effect on the productivity of higher-skilled or more experienced workers. Indeed, we find evidence that AI assistance leads to a small decrease in the quality of conversations conducted by the most skilled agents.
Coding stands out as one area where they may be more significant productivity gains. Here's the abstract of a paper published in August 2025:
This study evaluates the effect of generative AI on software developer productivity via randomized controlled trials at Microsoft, Accenture, and an anonymous Fortune 100 company. These field experiments, run by the companies as part of their ordinary course of business, provided a random subset of developers with access to an AI-based coding assistant suggesting intelligent code completions. Though each experiment is noisy and results vary across experiments, when data is combined across three experiments and 4,867 developers, our analysis reveals a 26.08% increase (SE: 10.3%) in completed tasks among developers using the AI tool. Notably, less experienced developers had higher adoption rates and greater productivity gains.
Interestingly, while that study found a positive impact on coding productivity from AI coding assistants, a study from the non-profit Model Evaluation & Threat Research (METR) found a negative impact on productivity. Here's that abstract:
Despite widespread adoption, the impact of AI tools on software development in the wild remains understudied. We conduct a randomized controlled trial (RCT) to understand how AI tools at the February–June 2025 frontier affect the productivity of experienced open-source developers. 16 developers with moderate AI experience complete 246 tasks in mature projects on which they have an average of 5 years of prior experience. Each task is randomly assigned to allow or disallow usage of early-2025 AI tools. When AI tools are allowed, developers primarily use Cursor Pro, a popular code editor, and Claude 3.5/3.7 Sonnet. Before starting tasks, developers forecast that allowing AI will reduce completion time by 24%. After completing the study, developers estimate that allowing AI reduced completion time by 20%. Surprisingly, we find that allowing AI actually increases completion time by 19%—AI tooling slowed developers down. This slowdown also contradicts predictions from experts in economics (39% shorter) and ML (38% shorter). To understand this result, we collect and evaluate evidence for 21 properties of our setting that a priori could contribute to the observed slowdown effect—for example, the size and quality standards of projects, or prior developer experience with AI tooling. Although the influence of experimental artifacts cannot be entirely ruled out, the robustness of the slowdown effect across our analyses suggests it is unlikely to primarily be a function of our experimental design.
Analysis: can AI companies catch up to expectations?
Financial expectations for AI companies are extremely high. Valuations implicitly assume a lot of growth. Current AI capabilities and applications do not support these valuations. To avoid a bubble popping, new capabilities will have to be developed to allow new applications or better performance on existing applications. Moreover, the new capabilities will have to be significant enough to generate significant financial results.
In theory, existing capabilities could find new applications. However, new applications in the absence of new capabilities seem unlikely to be significant enough. Many actors have been strongly incentivized to find applications for large language models (LLMs) for around three years.
A third option is for companies like OpenAI to introduce ads to monetize their free users, but given the costs of training and running AI models, and given the comparatively small amount of revenue per user generated by ad-based companies such as Facebook, this doesn't look like a way out of the bubble pop.
That leaves improvements in capabilities. The primary way that AI companies are counting on for capabilities to improve is scaling model training (which occurs before a model is released) and scaling the compute used for model inference (which occurs every time a model is used).
There are two forms of model training that can be scaled. The first is self-supervised pre-training. To scale self-supervised pre-training requires both an increase in compute and in data.
The non-profit Epoch AI predicts that LLMs will run out of data to train on in 2028. This would mean, unless something significant changes, the scaling of self-supervised pre-training would have to stop at that point.
In any case, there are already signs that self-supervised pre-training has hit a point of steeply diminishing returns. The highly respected machine learning researcher Ilya Sutskever, formerly the chief scientist at OpenAI, has made strong public statements about the effective end of self-supervised pre-training. Via Reuters:
Ilya Sutskever, co-founder of AI labs Safe Superintelligence (SSI) and OpenAI, told Reuters recently that results from scaling up pre-training - the phase of training an AI model that uses a vast amount of unlabeled data to understand language patterns and structures - have plateaued.
Sutskever is widely credited as an early advocate of achieving massive leaps in generative AI advancement through the use of more data and computing power in pre-training, which eventually created ChatGPT. Sutskever left OpenAI earlier this year to found SSI.
“The 2010s were the age of scaling, now we're back in the age of wonder and discovery once again. Everyone is looking for the next thing,” Sutskever said. “Scaling the right thing matters more now than ever.”
Sutskever declined to share more details on how his team is addressing the issue, other than saying SSI is working on an alternative approach to scaling up pre-training.
Reuters notes in the same article (from November 2024):
Behind the scenes, researchers at major AI labs have been running into delays and disappointing outcomes in the race to release a large language model that outperforms OpenAI’s GPT-4 model, which is nearly two years old, according to three sources familiar with private matters.
Anthropic's CEO Dario Amodei has also seemed to acknowledge an end to the era of scaling up self-supervised pre-training. In a January 2025 blog post, Amodei wrote:
Every once in a while, the underlying thing that is being scaled changes a bit, or a new type of scaling is added to the training process. From 2020-2023, the main thing being scaled was pretrained models: models trained on increasing amounts of internet text with a tiny bit of other training on top. In 2024, the idea of using reinforcement learning (RL) to train models to generate chains of thought has become a new focus of scaling.
That brings us to scaling up reinforcement learning to train LLMs. The problem with this approach is described by the philosopher (and co-founder of effective altruism) Toby Ord:
Jones (2021) and EpochAI both estimate that you need to scale-up inference by roughly 1,000x to reach the same capability you’d get from a 100x scale-up of training. And since the evidence from o1 and o3 suggests we need about twice as many orders of magnitude of RL-scaling compared with inference-scaling, this implies we need something like a 1,000,000x scale-up of total RL compute to give a boost similar to a GPT level.
This is breathtakingly inefficient scaling. But it fits with the extreme information inefficiency of RL training, which (compared to next-token-prediction) receives less than a ten-thousandth as much information to learn from per FLOP of training compute.
Yet despite the poor scaling behaviour, RL training has so far been a good deal. This is solely because the scaling of RL compute began from such a small base compared with the massive amount of pre-training compute invested in today’s models.
Ord explains why he sees a very limited amount of remaining runway for scaling reinforcement learning-based training of LLMs:
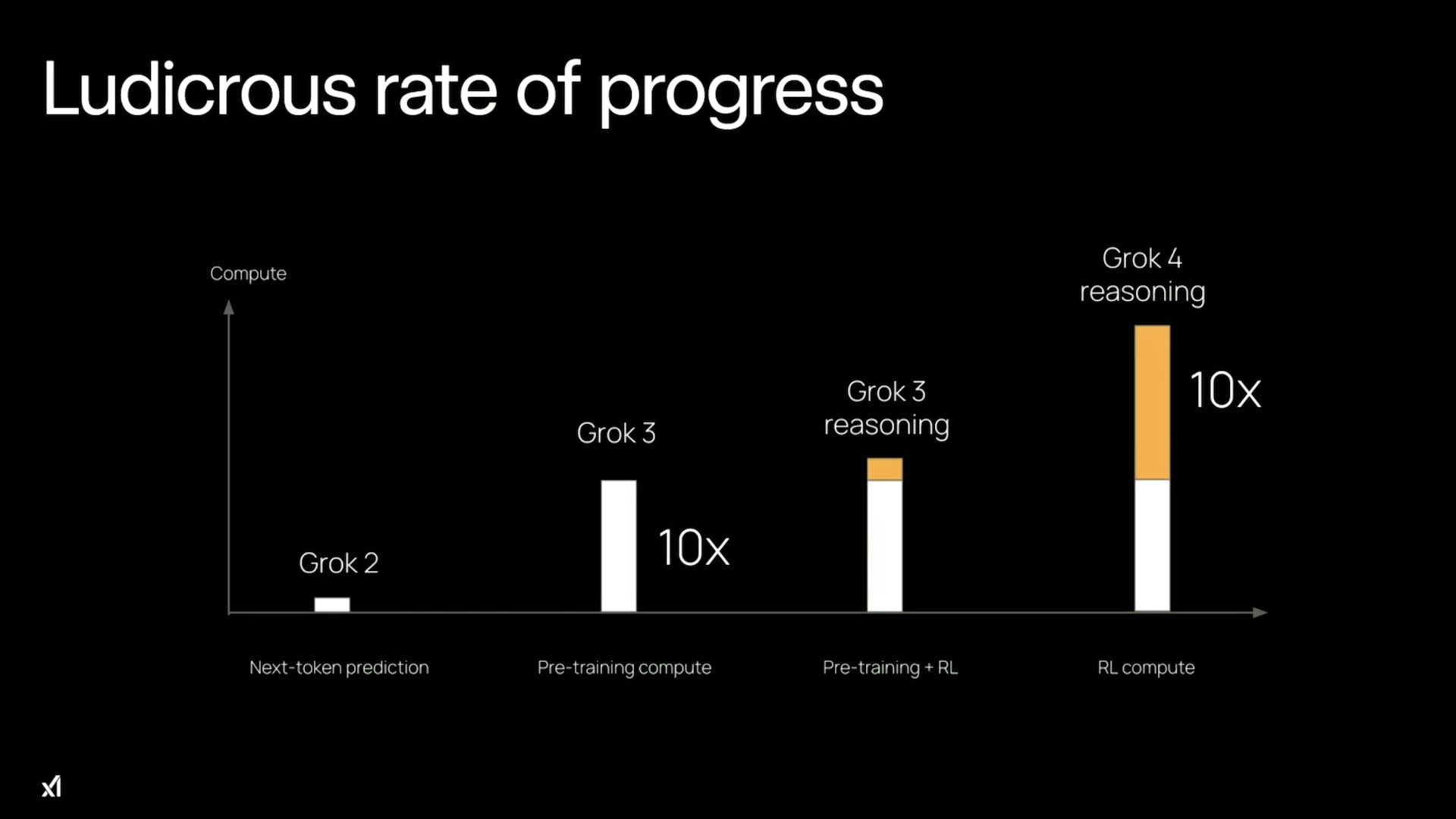
But this changes dramatically once RL-training reaches and then exceeds the size of the pre-training compute. In July 2025, xAI’s Grok 4 launch video included a chart suggesting that they had reached this level (where pre-training compute is shown in white and RL-training compute in orange):
Scaling RL by another 10x beyond this point increases the total training compute by 5.5x, and beyond that it is basically the full 10x increase to all training costs. So this is the point where the fact that they get much less for a 10x scale-up of RL compute compared with 10x scale-ups in pre-training or inference really bites. I estimate that at the time of writing (Oct 2025), we’ve already seen something like a 1,000,000x scale-up in RL training and it required ≤2x the total training cost. But the next 1,000,000x scale-up would require 1,000,000x the total training cost, which is not possible in the foreseeable future.
Grok 4 was trained on 200,000 GPUs located in xAI’s vast Colossus datacenter. To achieve the equivalent of a GPT-level jump through RL would (according to the rough scaling relationships above) require 1,000,000x the total training compute. To put that in perspective, it would require replacing every GPU in their datacenter with 5 entirely new datacenters of the same size, then using 5 years worth of the entire world’s electricity production to train the model. So it looks infeasible for further scaling of RL-training compute to give even a single GPT-level boost.
I don’t think OpenAI, Google, or Anthropic have quite reached the point where RL training compute matches the pre-training compute. But they are probably not far off. So while we may see another jump in reasoning ability beyond GPT-5 by scaling RL training a further 10x, I think that is the end of the line for cheap RL-scaling.
If self-supervised pre-training has reached its end and if reinforcement learning-based training is not far off from its own end, then all that's left is scaling inference. Ord notes the economic problem:
This leaves us with inference-scaling as the remaining form of compute-scaling. RL helped enable inference-scaling via longer chain of thought and, when it comes to LLMs, that may be its most important legacy. But inference-scaling has very different dynamics to scaling up the training compute. For one thing, it scales up the flow of ongoing costs instead of scaling the one-off training cost.
The fixed cost of training a model can be amortized over every single instance where that model is used. By contrast, scaling up inference increases the marginal cost of every LLM query. This raises obvious difficulties, especially given that inference is already quite expensive.
Finally, there is no guarantee that even if scaling could continue, it would make LLMs a profitable or productive enough technology to justify current valuations. Some problems with LLMs may be more fundamental and not solvable through scaling, such as:
A lack of continual learning or online learning, which would allow a model to learn new things over time, as humans do constantly, rather than only learning new things when the AI company does a new training run for a new version of the model
Extreme data inefficiency compared to humans, requiring perhaps as many as 1,000 examples to learn a concept that humans can learn with only one or two examples
Very poor generalization compared to humans, meaning the bounds of what LLMs can grasp do not extend far beyond what's in their training data
For tasks that rely on imitation learning from humans (which is the primary form of learning for LLMs), there may not be sufficient examples of humans performing a task for LLMs to effectively learn from (this is especially true for so-called "agentic" use cases that require computer use rather than just operating in the domain of text)
For computer vision tasks (perhaps including computer use), learning from video remains an open research problem with very little success to date, in contrast to LLMs learning from text data, which is a mature solution to an easier problem that benefits from the inherent structure in text
These are problems that can't be solved with scaling. Many human work tasks seem to require some combination of continual learning, human-like data efficiency, and much better generalization than LLMs have. Common complaints from users attempting to use LLMs for work tasks include hallucinations, basic mistakes in reasoning or understanding, and failure to follow instructions. These problems may be related to the fundamental limitations of LLMs just listed, or they may be more related to other limitations such as the architectures of current LLMs.
To summarize: capabilities must improve significantly to avoid a bubble. The prospects for improving capabilities much further through continued scaling seem very poor. Even if scaling could continue and keep delivering improvements, it is quite plausible this wouldn't be good enough, anyway, due to some of the more fundamental limitations with LLMs.
Conclusion
It seems very likely that the AI industry is in a bubble. Indeed, it is hard to imagine how AI could not be in a bubble.
This post is co-authored with Ben Garfinkel. It is cross-posted from the CEA blog. A PDF version can be found here.
Summary: Some strategic decisions available to the effective altruism m...
Disclaimer: Although I work on the Groups Team at CEA, I’m writing this in a personal capacity, and this post does not constitute an endorsement by CEA.
Agency - the realisation that you really can just do things.
TL;DR
Biosecurity needs people (of any background) who are agentic and have a high execution velocity and track record....
TL;DR: I'm releasing a website that ranks philanthropists according to EA principles and research, and allows users to re-rank the list using their own assumptions. I'd like feedback and help making it better. I'd especially like ideas for how to make the results more trustworthy. Funding may be available.
I recently built Impact List (impactlist.xyz), a site which ranks people by their positive impact via donations.
The goal is t...



I think this is a misreading of the study, though the article you link seems to make the same mistake. Here's the relevant graph:
The finding is that 5% of all companies (not just those that have adopted AI) had an executive who reported "a marked and sustained productivity and/or P&L impact" of a task-specific GenAI.
I think a more accurate summary of the paper is something like "80% of LLM pilots are reported as successful by executives."[1]
Assuming that all successful implementations were preceded by a pilot; the paper doesn't seem to say
Quote from the executive summary of the MIT Media Lab study, on page 3:
Quote from page 6:
Page 7:
I agree that the authors encourage this misreading of the data by eg saying "95% of organizations are getting zero return" and failing to note the caveats listed in my comment. If you believe that this statement is referencing a different data set than the one I was quoting which doesn't have those caveats, I'd be interested to hear it.
Are you saying the authors of the study are misreporting their own results?
6 months later, readers might be interested in this recent 80,000 Hours article about the 95% statistic.
I'm saying that the authors summarized their findings without caveats, and that those caveats would dramatically change how most people interpret the results.
(Note that, despite the "MIT" name being attached, this isn't an academic paper, and doesn't seem to be trying to hold itself to those standards.)
I recommend emailing the authors and asking for clarification. I’ve done this more than once in the past when I’ve had thoughts about papers I’ve read and have gotten some extremely helpful, illuminating replies.
I always worry about bothering people, but I get the sense that, rather than being annoyed, people find it rewarding that anyone took an interest in their work, or at least don’t mind answering a quick email.