tl;dr-tl;dr
You can summarise this whole post as ‘we shouldn’t confuse theoretical possibility of unfriendly AI with it being likely, let alone with it being a theoretical certainty’.
tl;dr
I’m concerned that EA AI-advocates tend to equivocate between two or even three different forms of the orthogonality thesis using a motte and bailey argument, and that this is encouraged by misleading language in the two seminal papers.
- The motte (the trivially defensible position) is the claim that it is theoretically possible to pair almost any motivation set with high intelligence and that AI will therefore not necessarily be benign or human-friendly.
- The inner bailey (a nontrivial but plausible position with which it’s equivocated) is the claim that there’s a substantial chance that AI will be unfriendly and non-benign, and that caution is wise until we can be very confident that it won't.
- The outer bailey (a still less defensible position with which both are also equivocated) is the claim that we should expect almost no relationship, if any, between intelligence and motivations, and therefore that AI alignment is extremely unlikely.
This switcheroo overemphasises the chance of hostile AI, and so might be causing us to overemphasise the priority of AI work.
Motte: the a priori theoretical possibility thesis
In the paper that introduced the term ‘orthogonality thesis’, Bostrom gave a handful of arguments against a very strong relationship between intelligence and motivation, e.g.
A member of an intelligent social species might also have motivations related to cooperation and competition: like us, it might show in-group loyalty, a resentment of free-riders, perhaps even a concern with reputation and appearance. By contrast, an artificial mind need not care intrinsically about any of those things, not even to the slightest degree.
This seems a reasonable way of disabusing the idea that AI is obviously guaranteed to behave in ‘moral’ ways: all of what we typically think of as intelligence has a common root (Earth-specific evolution), and thus could only be one branch of a much larger tree - of which we have a very biased view. This and arguments like it focus on theoretical possibility: they aim to establish the very weak thesis that almost no pairing of intelligence and motivation is logically inconsistent or ruled out by physics.
But coining this argument ‘orthogonality’ seems to have been a poor choice of name. ‘Orthogonality’ is not normally a statistical concept, so has no natural interpretation. But by far the most upvoted comments on these two stats.stackexchange threads explicitly understand it ‘not correlated’, an interpretation that would imply the much stronger outer bailey - that AI alignment is extremely unlikely.
This ambiguity continues in the other prominent paper on the subject, General Purpose Intelligence: Arguing the Orthogonality Thesis, in which Stuart Amstrong argues in more depth for ‘a narrower version of the [orthogonality] thesis’.
For example, Armstrong initially states that he’s arguing for the thesis that ‘high-intelligence agents can exist having more or less any final goals’ - ie theoretical possibility - but then adds that he will ‘be looking at proving the … still weaker thesis [that] the fact of being of high intelligence provides extremely little constraint on what final goals an agent could have’ - which I think Armstrong meant as ‘there are very few impossible pairings of high intelligence and motivation’, but which much more naturally reads to me as ‘high intelligence is almost equally as likely to be paired with any set of motivations as any other’.
He goes on to describe a purported counterthesis to ‘orthogonality’, which he labels ‘convergence’, but which I would call necessary strong convergence (see Appendix): ‘all human-designed superintelligences would have one of a small set of goals’, which he notes as a needlessly strong claim for contradicting orthogonality. He spends the rest of the paper arguing only against this overly strong claim. To quote his summary in full:
Denying the Orthogonality thesis thus requires that:
- There are goals G, such that an entity with goal G cannot
build a superintelligence with the same goal. This despite the fact that the
entity can build a superintelligence, and that a superintelligence with goal G
can exist.
- Goal G cannot arise accidentally from some other origin, and
errors and ambiguities do not significantly broaden the space of possible
goals.
- Oracles and general purpose planners cannot be built.
Superintelligent AIs cannot have their planning abilities repurposed.
- A superintelligence will always be able to trick its overseers, no
matter how careful and cunning they are.
- Though we can create an algorithm that does certain actions if it
was not to be turned off after, we cannot create an algorithm that does the
same thing if it was to be turned off after.
- An AI will always come to care intrinsically about things in the
real world.
- No tricks can be thought up to successfully constrain the AI’s
goals: superintelligent AIs simply cannot be controlled.
It’s not clear what proposition these points are supposed to establish. Most of them might be required to assert necessary strong convergence (some could be false in a world where creators could trick or blackmail their superintelligence into giving advice that they could use maliciously but where the intelligence itself was always benignly motivated); but it seems plausible that all of them are false and that we nonetheless live in a world where there will in expectation be moderate or even extremely strong correlation or convergence among superintelligent motivations, just as there is among human motivations.
And it’s still possible that all of them are true. The motte itself is ambiguous between two sub-sub-theses: 1) that we know of no mathematical proof or physical law necessitating a very strong relationship between intelligence and motivation, and 2) that is no such law. The first is so trivial as to not need any argument, so Armstrong and Bostrom’s arguments seem more relevant to building an intuition for the second. But it remains conceivable that we could discover some causal property of intelligence that, controlling for other factors, perfectly predicts some property of motivation. Any given physical law, such as the function of mass that outputs gravitational force, would have looked wildly improbable if similarly speculated on well before its discovery.
The paper’s conclusion has similar ambiguity:
It is not enough to know that an agent is intelligent (or superintelligent). If we want to know something about its final goals, about the actions it will be willing to undertake to achieve them, and hence its ultimate impact on the world, there are no shortcuts. We have to directly figure out what these goals are (or figure out a way of programming them in), and cannot rely on the agent being moral just because it is superintelligent/superefficient.
Few if any interactions in the real world ‘are known’ or ‘can be relied on’ with perfect certainty, and yet there are many phenomena we rely on to differing degrees - the sun rising and setting, economic and social patterns of humans, the laws of physics not radically changing from one moment to the next, etc. So, interpreted in what seems to me the natural way, this conclusion implies that AI risk is big enough to concern us in practice, rather than that the weaker thesis that the paper actually argued for, that it is conceivable that AI could have strange motivations. The latter thesis should still concern us, but neither of these papers give us any reason to think AI actually will be unsafe.
To be clear, I don’t think either paper was intended to mislead - I can just see reasons why their language would have done so, and I fear they have led many people in the EA community to an even stronger conclusion.
Outer bailey: the independence or almost-certain-misalignment thesis
Beyond theoretical possibility and likelihood lies the far more ambitious claim that intelligence and independence are almost entirely independent - in other words that learning something about an agent's intelligence gives you no information about its motivations. This, combined with the enormous size of motivation-space relative to the tiny sliver of that space that's compatible with human existence, leads to the claim that AI is almost certain to be human-incompatible (because a randomly sampled superintelligence from that space is very unlikely to be in the human-compatible band). This is the claim etymologically implied by the word ‘orthogonality’, which is perhaps how it’s become the claim that some EAs believe the orthogonality thesis makes.
Anecdotally, I was originally spurred to write this post after multiple conversations with EAs who responded to my expressions of scepticism about the level of risk from AI by paraphrasing Bostrom’s line that ‘Intelligence [in the sense of instrumental reasoning] and motivation can be thought of as a pair of orthogonal axes on a graph’. In the context of challenging my scepticism, this implies both that this way of thinking about it is actually an argument rather than an illustration of a conclusion, and that it’s an argument specifically against scepticism of necessitated misalignment, and therefore in favour of the independence thesis.
It was difficult to test the extent of this confusion without accidentally resolving it. I posted one poll asking ‘what the orthogonality thesis implies about [a relationship between] intelligence and terminal goals’, to which 14 of 16 respondents selected the option ‘there is no relationship or only an extremely weak relationship between intelligence and goals’, but someone pointed out that respondents might have interpreted ‘no relationship’ as ‘no strict logical implication from one to the other’. The other options hopefully gave context, but in a differently worded version of the poll 10 of 13 people picked options describing theoretical possibility. But early on someone commented on that poll asserting that ‘no statistical relationship is … clearly false’, which presumably discouraged people from choosing it.
Either way, this was a very small sample population. Nonetheless my best guess is that somewhere between a sizeable minority and a sizable majority of EAs familiar with the orthogonality thesis (20-80%) believe the ‘independence’ interpretation of what it states.
Given that ‘independent relationship’ is equivalent to the Stack Exchange-sanctioned ‘no correlation’ interpretation of ‘orthogonality’, this belief about what the thesis implies isn’t unreasonable among anyone who hasn’t carefully read the seminal papers. But it’s concerning that in 10 years of using this term our community has failed to disambiguate between the near-opposite meanings.
[Edit: three recent prominent EA sources seem to have interpreted the orthogonality thesis this way:
In David Denkenberger, Anders Sandberg, Ross John Tieman, and Joshua M. Pearce's paper Long term cost-effectiveness of resilient foods for global catastrophes compared to artificial general intelligence they say 'the goals of the intelligence are essentially arbitrary [48]', with the reference pointing to Bostrom's essay.
In Chapter 4 of What We Owe the Future, MacAskill describes 'The scenario most closely associated with [the book Superintelligence being] one in which a single AI agent designs better and better versions of itself, quickly developing abilities far greater than the abilities of all of humanity combined. Almost certainly, its aims would not be the same as humanity’s aims.' It's been a long time since I read Superintelligence, so I can't remember whether Bostrom does present this claim, or whether MacAskill has subsequently interpreted it that way. Either way, this seems like an importantly misleading claim from one of the most prominent members of the EA movement
In this comment, Robert Miles explicitly states that he understands the orthogonality thesis this way: 'Absent a specific reason to believe that we will be sampling from an extremely tiny section of an enormously broad space, why should we believe we will hit the target?']
Inner bailey: The evidential thesis against probable convergence or correlation
This is the claim that we should not in practice expect a strong relationship between intelligence of any level and terminal goals. It’s an empirical claim, and so must stand on its own, without support from arguments for theoretical possibility.
And perhaps it can - the point of this post is not to evaluate all evidential arguments, but to emphasise that arguments for theoretical possibility have virtually no bearing on the evidential thesis.
So by focusing on theoretical possibility, Bostrom’s and Armstrong’s papers show almost nothing about how likely or how strong a relationship actually is. The flipside of Bostrom’s observation of common roots being potentially biasing is that if some phenomenon has universally been observed with common cause, that seems like evidence both that 1) if it were produced by some other cause it might have different properties, which would support the case for a weaker relationship, and 2) that it can only be produced by the observed cause - or by sufficiently precise emulation of that cause as to share its properties, such as by simulating evolutionary processes digitally - which would support the case for a stronger relationship. In fact elsewhere in his paper Bostrom says ‘it would be easier to create an AI with simple goals like [maximising paperclips],’ actually asserting a fairly strong relationship, albeit one that may not comfort us.
Bostrom also invokes Hume’s is-ought cleft:
David Hume thought that beliefs alone (say, about what is a good thing to do) cannot motivate action: some desire is required. This would support the orthogonality thesis by undercutting one possible objection to it, namely, that sufficient intelligence might entail the acquisition of certain beliefs, and that these beliefs would necessarily produce certain motivations.
But Hume’s claim is far from settled. Since there’s a wide range of metaethical views among philosophers and EAs - i.e. many people believe their own intelligence has led them to specific moral beliefs - we shouldn’t assume the is-ought divide is necessarily insurmountable, or that this is an argument which EAs will necessarily find compelling.
Bostrom offers some further arguments for the evidential orthogonality thesis, but a) these all have the form ‘one could believe X, and X would imply noncorrelation’ where one might reasonably think X could be false or that the implication was weak (eg ‘it would suffice to assume, for example, that an agent—be it ever so intelligent—can be motivated to pursue any course of action if the agent happens to have certain standing desires of some sufficient, overriding strength.’), and b) anecdotally these nuances often don’t seem to carry over into typical EA conversations on the subject. In Robert Miles’ popular video for example, he describes belief in an (unspecified) relationship as a ‘mistake’, which can be redressed simply by stating the is-ought problem.
Some reasons to expect correlation
It’s extremely difficult to justify strong statements about likelihood of convergence or correlation. I assert no view on how likely they are or in what form, beyond that EAs should be more cautious about claiming they’re very unlikely. But in the interest of showing why I think it’s still an importantly open question, and to give an intuition as to how one could believe in strong convergence or correlation I’ll describe some scenarios under which they could look very likely:
- Developing AI with human-compatible motivations turns out to be approximately as easy as developing it with any other motivations, or at least not vastly harder (eg if some step turns out to involve training an AI that responds in a comprehensible way), and because the vast majority of AI developers want human-compatible motivations in their creation, in practice that’s what the majority of general AIs develop
- Evolution might have taken the easiest path: AI with wholly alien motivations could be possible in principle, but so difficult to create from first principles that whole brain emulation of evolved organisms/artificial evolution are the most practical paths to developing it - and these result in agents with similar motivations to the original brain/to other evolved organisms
- We might default to building AIs as bounded services rather than general optimisers
- Developing some key aspect of intelligence turns out to necessarily entail developing some motivation. For example, it turns out to be impossible or much harder to mentally model social behaviour without actually emulating some genuine sense of social responsibility (psychopaths aren’t a counterexample; social-moralistic instincts vary widely, but I know of no example of a human who has none whatsoever)
- Complex behavioural patterns turn out to be impossible/much harder to develop without involving consciousness - whatever that is - and consciousness turns out to have an inherent terminal drive toward positive utility (or toward some other common goal)
- Some version of pragmatism is right, such that values and facts turn out to be part of the same framework, and just as we apparently have universal epistemological axioms - despite them having no non-self-referential basis - it will turn out we have universal ‘moral axioms’
- There’s some other ‘correct’ way of reasoning about morality, such as a logical process of eliminating incoherent moralities, that sufficiently high intelligences tend to use to reach particular motivations
- There might be a non-motivating but relatively easy to define moral truth, such that we optionally can and actually do program AIs to care about it
- Some totally nonhumanlike set of motivations turns out to be much easier to develop (as Bostrom suggested), but these really are in some moral-realistic sense, better motivations than our own
Each of these seems plausible to me except 8 and 9, since I’m not a moral realist - but many smarter people than me are. The first is perhaps the most important, since the overwhelming desire among software engineers to not wipe out the world could outweigh even very high abstract theoretical difficulty in making safe AI. In scenarios 1, 2, and perhaps 3-5 there could be strong convergence in the short term and much less in the long run. But for practical purposes, this seems good enough - if benign or human-friendly AI has a decent first-mover advantage then paperclippers will have very little hope of conquering the universe.
Conclusion
Even if we think alignment is very likely, as long as there’s any uncertainty it makes sense to remain concerned about AI safety - but the higher credence we have in such alignment, the more we should prioritise competing concerns.
If you have arguments in favour of the evidential thesis, I’d encourage you to write them up as top level posts for the forum or as academic papers rather than (or as well as) posting them in response to this, since the subject seems too important for substantive cases to get lost in a comments section! Also, the arguments given for the orthogonality thesis may be useful for dislodging complacency about intelligent agents ‘obviously’ being moral.
But my primary claims have been:
- The ‘orthogonality thesis’ is a misleading name for those arguments
- Much of the language around those arguments is equivocal
- Understood properly the thesis describes a claim so weak it has almost no practical relevance
- That claim could nevertheless still be false
- It gives almost no information about the relevant and open questions around the probability of AI having any given motivations
- So we should refer to it sparingly if at all
Appendix: Terminology
As the main body shows, orthogonality discussions suffer from a lack of clarity around some key terms. Following Bostrom and Amstrong I use ‘morality’, ‘terminal goals’, and ‘motivations’ more or less interchangeably - I don’t think any confusion in this discussion lies there. 'Intelligence' is thornier, but I'm using it equivalently to Bostrom and Armstrong: 'something like instrumental rationality—skill at prediction, planning, and means-ends reasoning in general'. This is a shaky definition, since skill at these things may be hard to disentangle from the results you're trying to predict and plan, but again I don't think anything that issue affects any of the arguments in this essay.
But the statements about potential relationships between intelligence and motivation need to be clarified. Below I list some non-exhaustive classes of thesis one could plausibly hold about such a relationship:
Relationship type
Since there’s no natural ordering of motivations or even necessarily of intelligence - they may not even have discrete values - I don’t think there’s any natural definition of the following terms. In what follows I give my best effort at sufficiently precise definitions of what they intuitively mean to me, which I hope don’t wildly misrepresent what Armstrong and Bostrom had in mind.
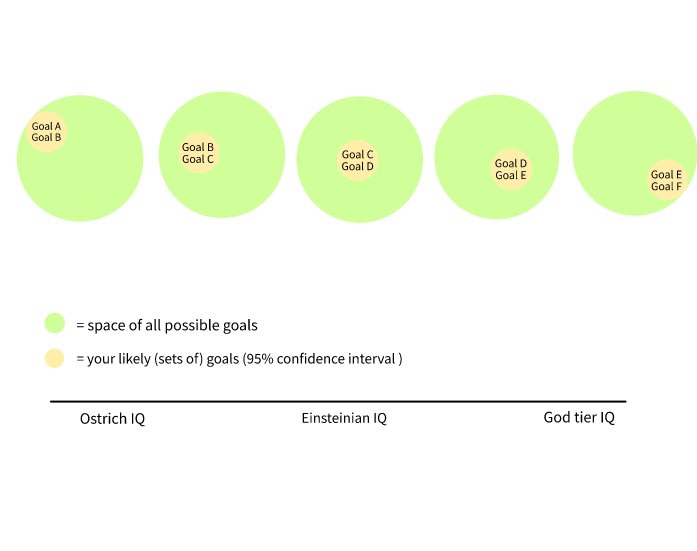 An example of ‘correlation’. There isn’t really any way to think of this as orthogonal axes on a two-dimensional graph. What would the y-axis represent? And I've snuck in 'IQ' as a quantifiable proxy for general intelligence in a way that could be problematic. That doesn’t mean that any particular interpretation of ‘orthogonality’ doesn’t hold (you could present it as multiple axes or on multiple graphs), but it highlights the awkwardness of the analogy
An example of ‘correlation’. There isn’t really any way to think of this as orthogonal axes on a two-dimensional graph. What would the y-axis represent? And I've snuck in 'IQ' as a quantifiable proxy for general intelligence in a way that could be problematic. That doesn’t mean that any particular interpretation of ‘orthogonality’ doesn’t hold (you could present it as multiple axes or on multiple graphs), but it highlights the awkwardness of the analogy
- Convergence: the higher an agent’s general intelligence, the more predictable its motivations are (we could state this in reverse, i.e. that lower intelligence could be more predictive, but that thesis doesn’t seem very relevant whether or not it’s true. Universally benevolent ostriches won’t help us much if superintelligences are vastly diverse in their goals).
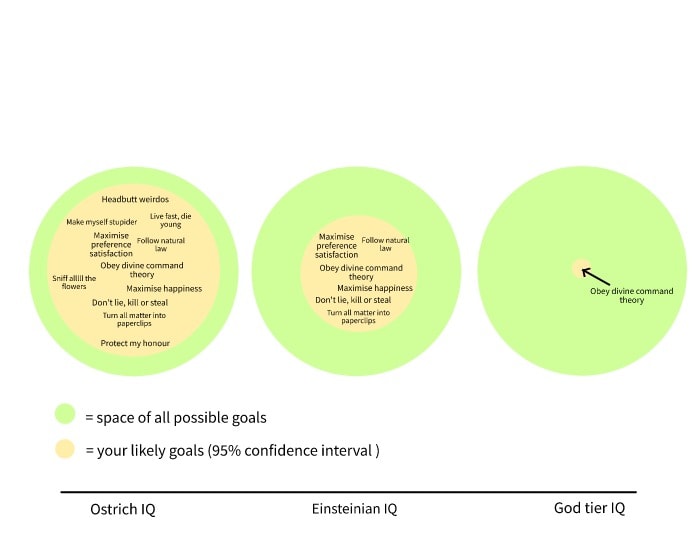 An example of ‘convergence’; again, this isn’t representable as axes on a two-dimensional graph
An example of ‘convergence’; again, this isn’t representable as axes on a two-dimensional graph
- Independence: there is no or very weak (see below) correlation, convergence, or any other relationship between an agent’s level of intelligence and its motivations.
For most purposes we don’t care that much about the difference between correlation and convergence towards greater intelligence, but it seems worth recognising them as distinct concepts. Non-convergent strong correlation might allow for superintelligence which seems neither benign nor human friendly, for example.
To present a more natural interpretation we need to have a much more tightly defined y-axis, specifically one with orderable elements. And this is likely to be most understandable in the real world if they have cardinality. As far as I can see, this forces you to explicitly treat one particular (necessarily orderable, preferably cardinal) axiology as the benchmark against which we can then track dis/conformity.
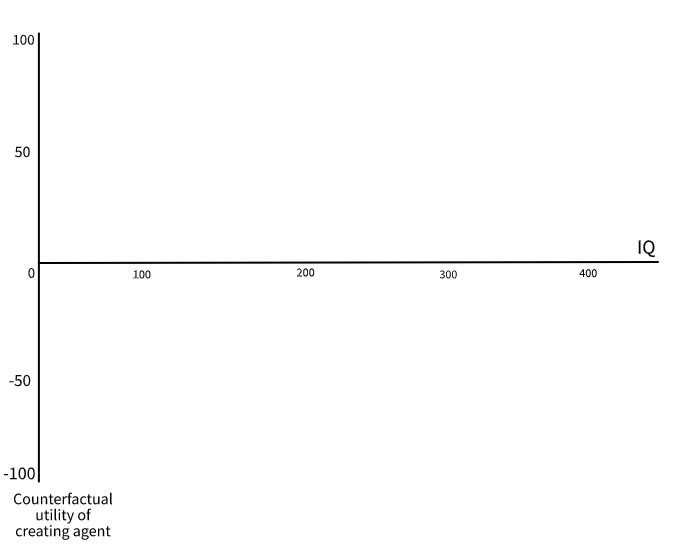 An example of a graph with orthogonal axes representing intelligence and (a much more specific subquestion about) motivation, which may or may not feature (here well-defined) correlation
An example of a graph with orthogonal axes representing intelligence and (a much more specific subquestion about) motivation, which may or may not feature (here well-defined) correlation
Relationship possibility
-
Theoretically possible: it’s not literally impossible for a particular relationship type to hold, or for an entity to exist with almost any given pairing of intelligence and motivation.
-
Necessitated or near-necessitated: it is guaranteed or almost guaranteed that a particular relationship type will hold.
-
Evidential (ie anything in between): some specific view on the probability of a particular relationship type holding (such views need substantially greater definition than the extreme cases, since one could make many unconnected statements for example about statistical significance, strength of effect, class of effect).
Relationship specificity
Behavioural Destinations
-
Human-friendly: high intelligences will tend towards human-friendly behaviour.
-
Benign: high intelligences will tend towards morally optimal behaviour, whatever - if anything - that turns out to be. Human friendliness is not guaranteed.
-
Aligned: this could either be synonymous with ‘human-friendly’, or mean ‘either human-friendly or benign’. Elsewhere this is obviously an important distinction which easily gets overlooked, but the distinction doesn’t matter much to this post. For what it’s worth, I think of it as more like the latter.
-
Other: Something that is neither benign nor human friendly. Further details are not particularly relevant...
‘The orthogonality thesis’ as explicitly argued for seems to be a claim of ‘non-necessary correlation and non-necessary convergence’ with no implication about specificity or destination, though Bostrom briefly asserts something like ‘probable convergent low specificity correlation towards non-human-friendly behaviour’ - and see main body for other interpretations people have held.
Acknowledgements
I owe a debt to Simon Marshall, Johan Lugthart, Siao Si Looi, David Kristoffersson, John Halstead, Emrik Garden for many helpful discussions and invaluable comments on this post. Mistakes, discrepancies and accidental insults of anyone's mother are all mine.

I'm a bit surprised not to see this post get more attention. My impression is that for a long time a lot of people put significant weight on the orthogonality argument. As Sasha argues, it is difficult to see why it should update us towards the view that AI alignment is difficult or an important problem to work on, let alone by far the most important problem in human history. I would be curious to hear its proponents explain what they think of Sasha's argument.
For example, in his response to bryan caplan on the scale of AI risk, Eliezer Yudkowsky makes the following argument:
"1. Orthogonality thesis – intelligence can be directed toward any compact goal; consequentialist means-end reasoning can be deployed to find means corresponding to a free choice of end; AIs are not
automatically nice; moral internalism is false.
2. Instrumental convergence – an AI doesn’t need to specifically hate you to hurt you; a
paperclip maximizer doesn’t hate you but you’re made out of atoms that it can use to make paperclips, so leaving you alive represents an opportunity cost and a number of foregone paperclips. Similarly,
paperclip maximizers want to self-improve, to perfect material technology, to gain control of resources, to persuade their programmers that they’re actually quite friendly, to hide their real thoughts from their programmers via cognitive steganography or similar strategies, to give no sign of value disalignment until they’ve achieved near-certainty of victory from the moment of their first overt strike, etcetera.
3. Rapid capability gain and large capability differences – under scenarios seeming more plausible than not, there’s the possibility of AIs gaining in capability very rapidly, achieving large absolute
differences of capability, or some mixture of the two. (We could try to keep that possibility non-actualized by a deliberate effort, and that effort might even be successful, but that’s not the same as the avenue
not existing.)
4. 1-3 in combination imply that Unfriendly AI is a critical Problem-to-be-solved, because AGI is not automatically nice, by default does things we regard as harmful, and will have avenues
leading up to great intelligence and power."
This argument does not work. This argument shows that AI systems will not necessarily be aligned. It tells us nothing about whether they are likely to be aligned or whether it will be easy to align AI systems. All of the above is completely compatible with the view that AI will be easy to align and we will obviously try and to align them eg since we don't all want to die. To borrow the example from ben garfinkel, cars could in principle be given any goals. This has next to no bearing on what goals they will have in the real world or the set of likely possible futures.
The quote above is an excerpt from here, and immediately after listing those four points, Eliezer says “But there are further reasons why the above problem might be difficult to solve, as opposed to being the sort of thing you can handle straightforwardly with a moderate effort…”.
ah i see i hadn't seen that
FWIW my impression is more like "I feel like I've heard the (valid) observation expressed in the OP many times before, even though I don't exactly remember where", and I think it's an instance of the unfortunate but common phenomenon where the state of the discussion among 'people in the field' is not well represented by public materials.
As far as I understand it, orthogonality and instrumental convergence together actually make a case for AI being by default not aligned. The quote from Eliezer here goes a bit beyond the post. For the orthogonality thesis by itself, I agree with you & the main theses of the post. I would interpret "not aligned by default" as something like a random AI is probably not aligned. So I tend to disagree also when just considering these two points. This is also the way I originally understood Bostrom in Superintelligence.
However, I agree that this doesn’t tell you whether aligning AI is hard, which is another question. For this, we at least have the empirical evidence of a lot of smart people banging their heads against it for years without coming up with detailed general solutions that we feel confident about. I think this is some evidence for it being hard.
(Epistemic status of this comment: much weaker than of the OP)
I am suspicious a) of a priori non-mathematical reasoning being used to generate empirical predictions on the outside view and b) of this particular a priori non-mathematical reasoning on the inside view. It doesn't look like AI algorithms have tended to get more resource grabby as they advance. AlphaZero will use all the processing power you throw at it, but it doesn't seek more. If you installed the necessary infrastructure (and, ok, upgraded the storage space), it could presumably run on a ZX Spectrum.
And very intelligent humans don't seem profoundly resource grabby, either. For every Jeff Bezos you have an Edward Witten, who obsessively dedicates dedicating his or her own time to some passion project but does very little to draw external resources towards it.
So based on existing intelligences, satisficing behaviour seems more like the expected default than maximising.
AlphaZero isn't smart enough (algorithmically speaking). From Human Compatible (p.207):
From wireheading, it might then go on to resource grab to maximise the probability that it gets a +1 or maximise the number of +1s it's getting (e.g. filling planet sized memory banks with 1s); although already it would have to have a lot of power over humans to be able to convince them to reprogram it by sending messages via the go board!
I don't think the examples of humans (Bezos/Witten) are that relevant, in as much as we are products of evolution, and are "adaption executors" rather than "fitness maximisers", are imperfectly rational, and tend to be (broadly speaking) aligned/human-compatible, by default.