Recently, many AI safety movement-building programs have been criticized for attempting to grow the field too rapidly and thus:
- Producing more aspiring alignment researchers than there are jobs or training pipelines;
- Driving the wheel of AI hype and progress by encouraging talent that ends up furthering capabilities;
- Unnecessarily diluting the field’s epistemics by introducing too many naive or overly deferent viewpoints.
At MATS, we think that these are real and important concerns and support mitigating efforts. Here’s how we address them currently.
Claim 1: There are not enough jobs/funding for all alumni to get hired/otherwise contribute to alignment
How we address this:
- Some of our alumni’s projects are attracting funding and hiring further researchers. Three of our alumni have started alignment teams/organizations that absorb talent (Vivek’s MIRI team, Leap Labs, Apollo Research), and more are planned (e.g., a Paris alignment hub).
- With the elevated interest in AI and alignment, we expect more organizations and funders to enter the ecosystem. We believe it is important to install competent, aligned safety researchers at new organizations early, and our program is positioned to help capture and upskill interested talent.
- Sometimes, it is hard to distinguish truly promising researchers in two months, hence our four-month extension program. We likely provide more benefits through accelerating researchers than can be seen in the immediate hiring of alumni.
- Alumni who return to academia or industry are still a success for the program if they do more alignment-relevant work or acquire skills for later hiring into alignment roles.
Claim 2: Our program gets more people working in AI/ML who would not otherwise be doing so, and this is bad as it furthers capabilities research and AI hype
How we address this:
- Considering that the median MATS scholar is a Ph.D./Masters student in ML, CS, maths, or physics and only 10% are undergrads, we believe most of our scholars would have ended up working in AI/ML regardless of their involvement with the program. In general, mentors select highly technically capable scholars who are already involved in AI/ML; others are outliers.
- Our outreach and selection processes are designed to attract applicants who are motivated by reducing global catastrophic risk from AI. We principally advertise via word-of-mouth, AI safety Slack workspaces, AGI Safety Fundamentals and 80,000 Hours job boards, and LessWrong/EA Forum. As seen in the figure below, our scholars generally come from AI safety and EA communities.
MATS Summer 2023 interest form: “How did you hear about us?” (381 responses)
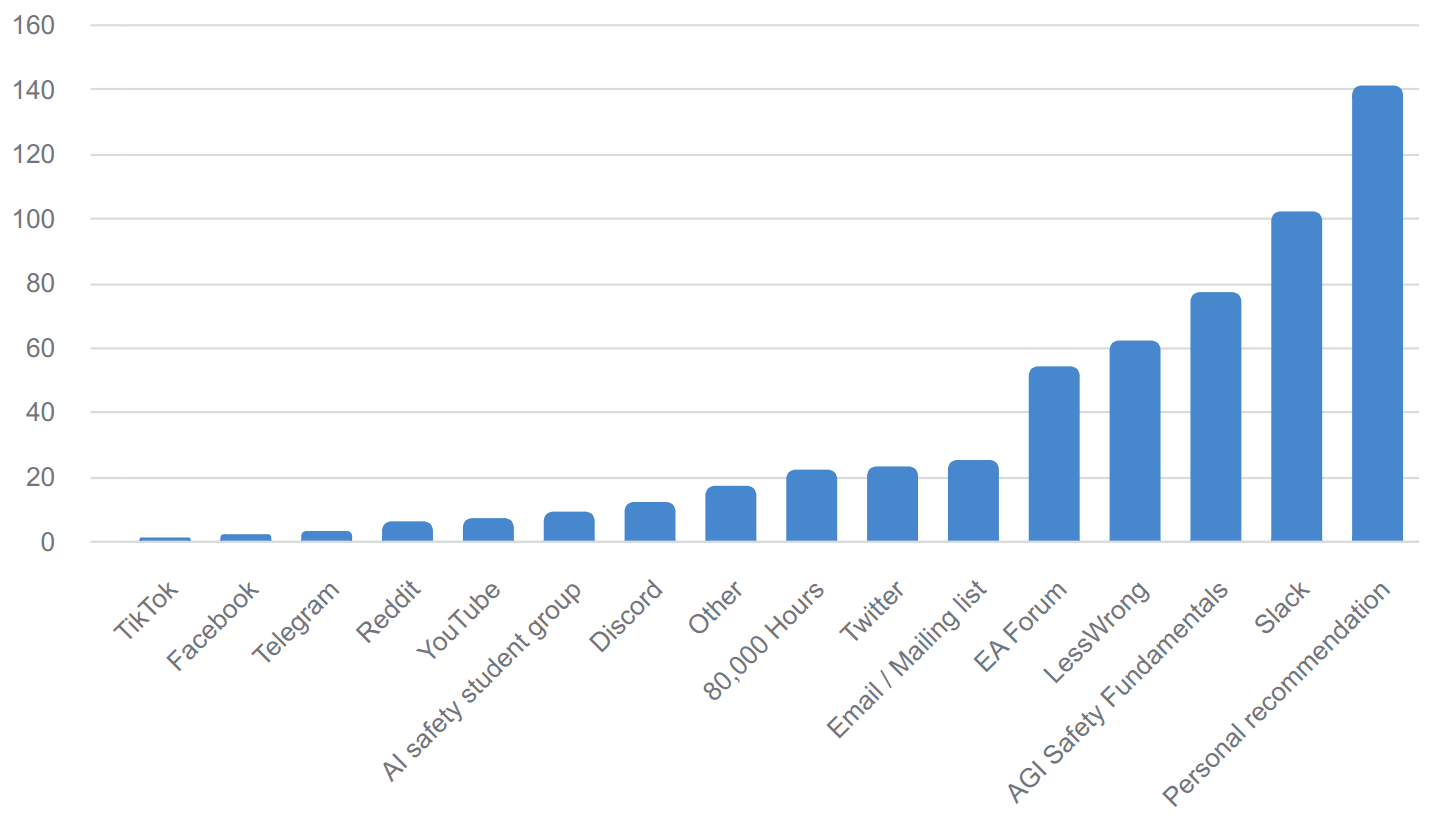
- We additionally make our program less attractive than comparable AI industry programs by introducing barriers to entry. Our grant amounts are significantly less than our median scholar could get from an industry internship (though substantially higher than comparable academic salaries), and the application process requires earnest engagement with complex AI safety questions. We additionally require scholars to have background knowledge at the level of AGI Safety Fundamentals, which is an additional barrier to entry that e.g. MLAB didn't require.
- We think that ~1 more median MATS scholar focused on AI safety is worth 5-10 more median capabilities researchers (because most do pointless stuff like image generation, and there is more low-hanging fruit in safety). Even if we do output 1-5 median capabilities researchers per cohort (which seems very unlikely), we likely produce far more benefit to alignment with the remaining scholars.
Claim 3: Scholars might defer to their mentors and fail to critically analyze important assumptions, decreasing the average epistemic integrity of the field
How we address this:
- Our scholars are encouraged to “own” their research project and not unnecessarily defer to their mentor or other “experts.” Scholars have far more contact with their peers than mentors, which encourages an atmosphere of examining assumptions and absorbing diverse models from divergent streams. Several scholars have switched mentors during the program when their research interests diverged.
- We require scholars to submit “Scholar Research Plans” one month into the in-person phase of the program, detailing a threat model they are targeting, their research project’s theory of change, and a concrete plan of action (including planned outputs and deadlines).
- We encourage an atmosphere of friendly disagreement, curiosity, and academic rigor at our office, seminars, workshops, and networking events. Including a diverse portfolio of alignment agendas and researchers from a variety of backgrounds allows for earnest disagreement among the cohort. We tell scholars to “download but don’t defer” in regard to their mentors’ models. Our seminar program includes diverse and opposing alignment viewpoints. While scholars generally share an office room with their research stream, we try and split streams up for accommodation and Alignment 201 discussion groups to encourage intermingling between streams.
We appreciate feedback on all of the above! MATS is committed to growing the alignment field in a safe and impactful way, and would generally love feedback on our methods. More posts are incoming!

